英伟达发布TensorRT 8,将BERT-Large推理缩短到毫秒级别
2021-07-21
21:39:25
来源: 杜芹
点击
如今,人工智能模型复杂程度正在呈指数级增长,与此同时,全球对使用人工智能的实时应用程序的需求也在激增,这使得企业必须部署最先进的推理解决方案。根据 O'Reilly 最近的一项调查,86.7% 的组织现在正在考虑、评估或投入生产 AI 产品。Deloitte报告称,53%采用人工智能的企业在 2019 年和 2020 年在技术和人才上的支出超过 2000 万美元。
而在AI推理方面,英伟达的TensorRT正是用于高性能深度学习推理的软件开发工具包 (SDK),它专为专为人工智能和机器学习推理而设计。此SDK包含深度学习推理优化器和运行时环境,可为深度学习推理应用提供低延迟和高吞吐量。
最新款TensorRT 8 ,BERT-Large推理仅需1.2毫秒
近日,英伟达发布了第8代人工智能软件TensorRT™8,据悉,该软件将语言查询的推理时间缩短了一半,专为部署可以为搜索引擎、广告推荐、聊天机器人等提供支持的 AI 模型而构建。

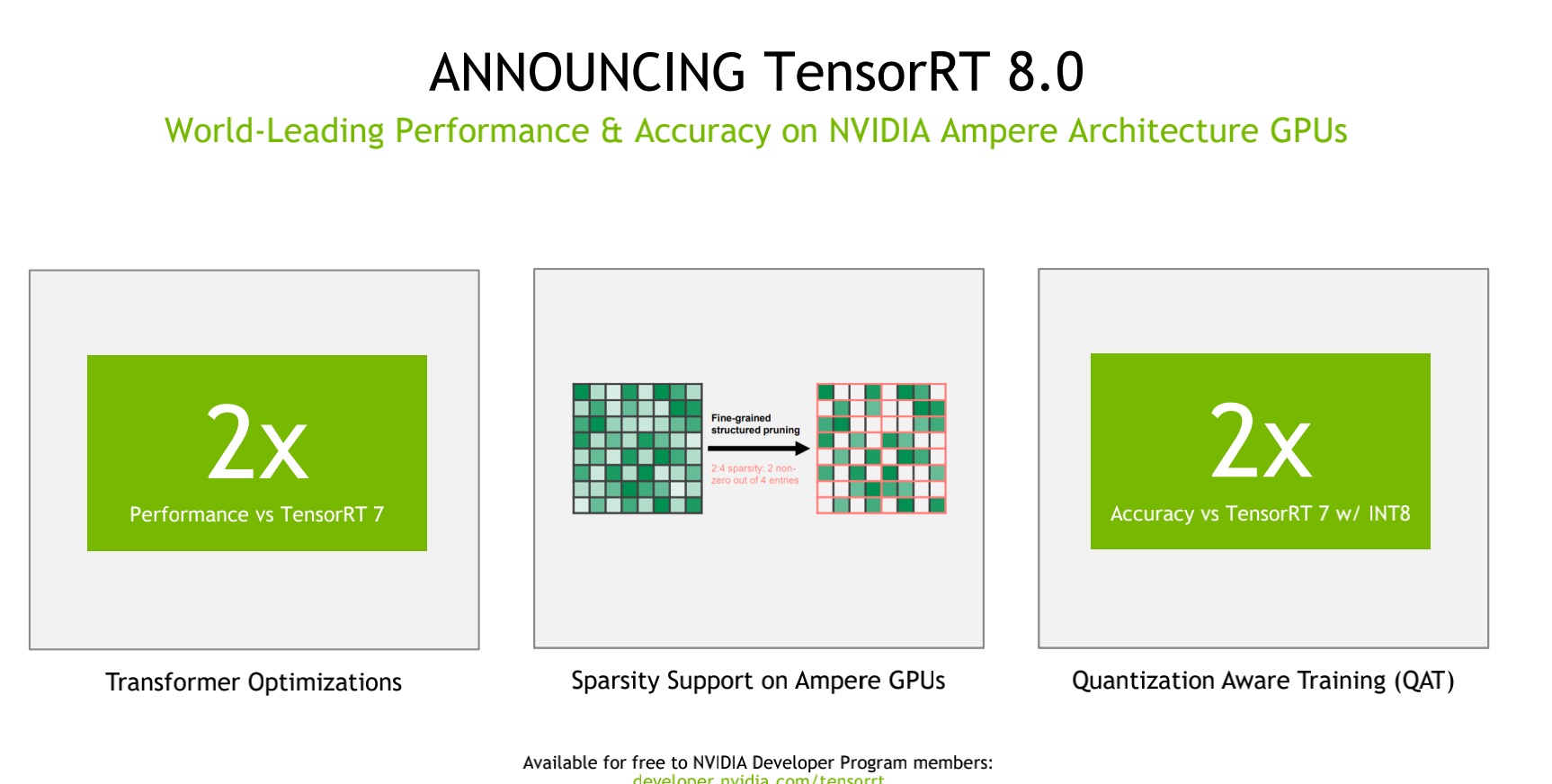
而且,TensorRT 8 特定的优化语言允许 BERT-Large在 1.2 毫秒内运行,BERT-Large是最受欢迎的基于Transformer的模型之一。TensorRT 本质上是将模型的数学坐标拨到最小模型尺寸与它将运行的系统的最高精度之间的平衡。要知道,在过去,公司只有缩小模型的尺寸才行,这样导致结果的准确性大大降低。而TensorRT 8则可以实现将模型尺寸增加1-2倍,精度也显著提高。

NVIDIA开发程序副总裁Greg Estes说。“最新版本的TensorRT引入了新功能,使企业能够以前所未有的质量和响应能力,向客户提供对话AI应用程序。”
这是如何做到的?按照英伟达的说法,除了变压器优化,TensorRT 8在人工智能推理方面的突破是通过另外两个关键特性实现的。一个是稀疏性技术,另一个是量化感知训练。
稀疏性是NVIDIA Ampere架构GPU中的一项新的性能技术,它可以提高效率,允许开发者通过减少计算操作来加速他们的神经网络。而量化感知训练使开发人员能够使用经过训练的模型在INT8精度中运行推理而不丢失准确性。这大大减少了张量核高效推理的计算和存储开销。
TensorRT的行业地位:250万次的下载量
五年来,包括医疗、汽车、金融和零售等多个领域的27500家公司的逾35万名开发者下载了近250万次TensorRT。TensorRT应用可以部署在超大规模的数据中心、嵌入式或汽车产品平台上。

这些足以见得TensorRT的应用度广泛以及行业的支持。开源人工智能厂商Hugging Face正在与Nvidia合作推出AI文本分析、神经搜索和对话式AI服务。Hugging Face的产品总监Jeff Boudier说。“借助 TensorRT 8,Hugging Face 在 BERT上实现了1毫秒的推理延迟,我们很高兴在今年晚些时候为我们的客户提供这种性能。”
而在医疗领域的GE Healthcare则利用SDK来支持其超声波计算机视觉系统,提高其心脏视图检测算法的性能。超声波是疾病早期检测的关键工具。这使临床医生能够通过其智能医疗保健解决方案提供最高质量的医疗服务。
TensorRT 8现在对NVIDIA开发者计划的成员普遍免费提供。最新版本的插件、解析器和示例也可以从TensorRT GitHub库中获得。
而在AI推理方面,英伟达的TensorRT正是用于高性能深度学习推理的软件开发工具包 (SDK),它专为专为人工智能和机器学习推理而设计。此SDK包含深度学习推理优化器和运行时环境,可为深度学习推理应用提供低延迟和高吞吐量。
最新款TensorRT 8 ,BERT-Large推理仅需1.2毫秒
近日,英伟达发布了第8代人工智能软件TensorRT™8,据悉,该软件将语言查询的推理时间缩短了一半,专为部署可以为搜索引擎、广告推荐、聊天机器人等提供支持的 AI 模型而构建。
而且,TensorRT 8 特定的优化语言允许 BERT-Large在 1.2 毫秒内运行,BERT-Large是最受欢迎的基于Transformer的模型之一。TensorRT 本质上是将模型的数学坐标拨到最小模型尺寸与它将运行的系统的最高精度之间的平衡。要知道,在过去,公司只有缩小模型的尺寸才行,这样导致结果的准确性大大降低。而TensorRT 8则可以实现将模型尺寸增加1-2倍,精度也显著提高。
NVIDIA开发程序副总裁Greg Estes说。“最新版本的TensorRT引入了新功能,使企业能够以前所未有的质量和响应能力,向客户提供对话AI应用程序。”
这是如何做到的?按照英伟达的说法,除了变压器优化,TensorRT 8在人工智能推理方面的突破是通过另外两个关键特性实现的。一个是稀疏性技术,另一个是量化感知训练。
稀疏性是NVIDIA Ampere架构GPU中的一项新的性能技术,它可以提高效率,允许开发者通过减少计算操作来加速他们的神经网络。而量化感知训练使开发人员能够使用经过训练的模型在INT8精度中运行推理而不丢失准确性。这大大减少了张量核高效推理的计算和存储开销。
TensorRT的行业地位:250万次的下载量
五年来,包括医疗、汽车、金融和零售等多个领域的27500家公司的逾35万名开发者下载了近250万次TensorRT。TensorRT应用可以部署在超大规模的数据中心、嵌入式或汽车产品平台上。
这些足以见得TensorRT的应用度广泛以及行业的支持。开源人工智能厂商Hugging Face正在与Nvidia合作推出AI文本分析、神经搜索和对话式AI服务。Hugging Face的产品总监Jeff Boudier说。“借助 TensorRT 8,Hugging Face 在 BERT上实现了1毫秒的推理延迟,我们很高兴在今年晚些时候为我们的客户提供这种性能。”
而在医疗领域的GE Healthcare则利用SDK来支持其超声波计算机视觉系统,提高其心脏视图检测算法的性能。超声波是疾病早期检测的关键工具。这使临床医生能够通过其智能医疗保健解决方案提供最高质量的医疗服务。
TensorRT 8现在对NVIDIA开发者计划的成员普遍免费提供。最新版本的插件、解析器和示例也可以从TensorRT GitHub库中获得。
责任编辑:sophie
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号