
AI芯片0.5与2.0
我从2017年的ISSCC开始写AI硬件相关的文章,到现在刚好两年了。在刚刚过去的ISSCC2019上,AI芯片仍然是一个热点,有几个session都和AI硬件相关。同时,CGO19会议的Compilers for Machine Learning Workshop,各种ML编译器纷纷出场。从大环境来看,第一代AI芯片软硬件技术基本成熟,产业格局逐渐稳定,已经为规模应用做好了准备,可称之为AI芯片0.5版本。而在ISSCC会议上,大神Yann LeCun在讲演中提出了对未来AI芯片的需求[1],开启了我们对新的架构(AI芯片2.0)的思考。
ISSCC2019
两年前,我在公众号发文分析了ISSCC2017 Deep-Learning Processors Session 中的7篇文章。到今天,不仅AI芯片技术取得了长足的进步,大家写文章的热情也越来越高,相信后面会看到各种对ISSCC2019论文进行分析的文章。所以,我就不再单独讨论具体的论文了,只谈一些综合的感受。
这次我看到论文摘要的时候,首先是还是看Session 7和14的Machine Learning部分。而我最关注的是三星的论文“ An 11.5TOPS/W 1024-MAC Butterfly Structure Dual-Core Sparsity-Aware Neural Processing Unit in 8nm Flagship Mobile SoC ”。大家知道,三星在手机芯片中加入NPU是相对较晚的,应该说在设计中吸收了学界和业界这几年AI芯片研发的经验。另外,这也是业界首次公开在规模量产芯片(旗舰手机芯片)中的NPU细节,一方面反映了“真实”和“实用”(不追求指标惊人,而是有更明确的优化目标)的结果,另一方面也标志着整个产业对NPU设计的认识已经比较成熟。
另外一个重要看点当然是Yann LeCun教授的演讲。ISSCC本来是半导体产业中的“电路(circuit)”会议,这几年越来越多的加入架构层面的内容。这次请AI大神做Keynote就更有意思了。大神在ISSCC讲演的几天之内还做了一波PR,也有宣传Facebook自研芯片的意思。当然,大神的演讲还是非常棒的,特别是对新架构的分析。这几天已经有很多文章介绍这个研究,我这里只贴一下他分享的的AI硬件相关的经验教训以及对未来的展望。




source:ISSCC2019
前两个部分反映了上世纪90年底开始到今天的AI热潮中AI硬件的尝试以及整个AI发展中我们学习到的经验和教训。第三部分是对新架构的预测,这个我将在本文第三部分重点讨论。第四部分主要讲一些算法的趋势,特别是Self-Supervised Learning(蛋糕上的樱桃)。
最后,他还分享了一下自己的一些其它思考,特别是对于SNN的质疑。这部分内容这两天也引起很大争议。SNN现在确实面临实用性的问题,Neuromorphic的初衷是模仿人脑,但由于我们现在使用的模型太简单,这种模型和算法是否是正确路径确实还有疑问。第二部分,他对模拟计算也有一些疑问,看起来也都是老问题。我自己没有参会,所以不太清楚他具体的讲法是什么。不过我个人觉得模拟计算还是很有前途的(或者说是不得不走的路)。

source:ISSCC2019
如果说Yann LeCun教授对AI芯片的新架构提出了需求,那么 另外一个推动AI芯片技术进步的要素将是底层半导体技术的进步 ,这也正是ISSCC的重点。从这次会议来看,存储技术(包括存内计算),模拟计算,硅光技术等等,在AI,5G等需求的驱动下都非常活跃。这些技术和AI芯片的关系之前都有介绍,本文就不赘述了。
Compilers for Machine Learning
就在ISSCC的同时,“The International Symposium on Code Generation and Optimization (CGO)”上的“Compilers for Machine Learning” workshop[2]也相当热闹。我们不妨先看看讨论的内容:

会议除了目前三大AI/ML编译器XLA(Tensorflow),TVM,Glow(Pytorch)之外;还有Intel的nGraph,PlaidML;Nvidia的TensorRT;Xilinx用于ACAP的编译器。另外还有大神Chris的talk和其它来自学界的讲演。会议大部分Slides在网上都可以看到,这里就不具体介绍了。我在一年前写过一篇文章“ Deep Learning的IR“之争 ” ” ,主要讨论IR的问题,和编译器也是密切相关的。到今天,这个领域确实也是现在大家竞争的一个焦点。
XLA是比较早提编译器概念的,但到现在主要还是针对Google的TPU进行优化。TVM相当活跃,前一段时间还搞了TVM conference,除了Amazon之外,华为,Intel,Xilinx,甚至“竞争对手” Facebook都有参加。TVM的“野心”也很大,从最早的编译器已经发展到了TVM Stack(如下图,和我之前文章里贴的图已经有了很大的变化),从新的IR(Relay),到自动编译优化的AutoTVM,到开源AI硬件加速器(VTA),开了很多有意思的话题。
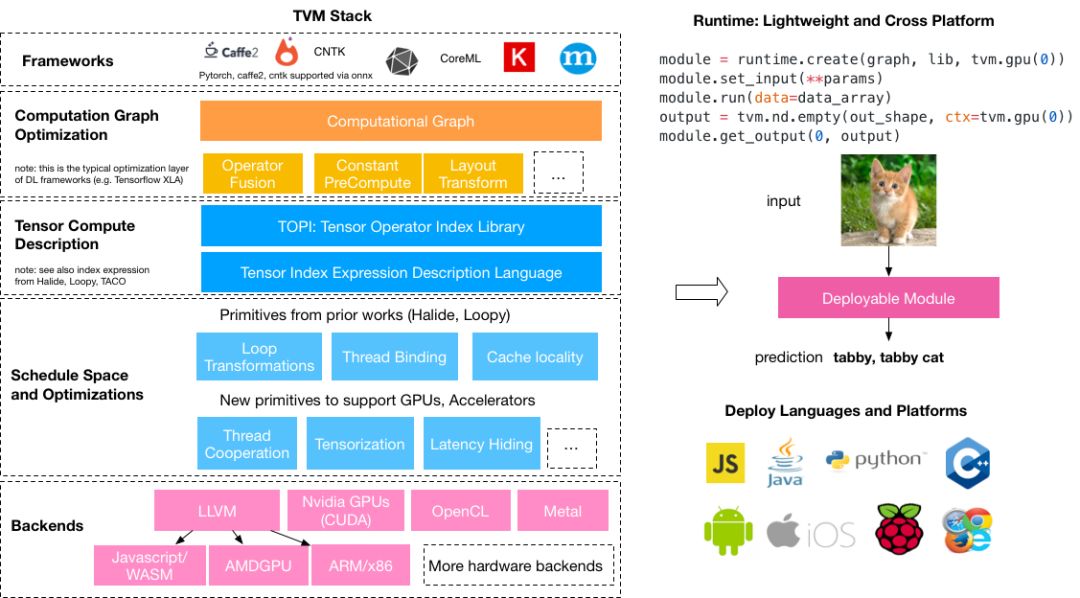
source:tvm.ai
Glow是Pytorch的一部分,在AI编译器里算后起之秀,吸收了XLA和TVM的经验,有自己的特色,目前已经有一些厂商站台,也比较活跃。
这三个编译器的背后分别是Google,Amazon和Facebook三巨头的支撑和相应Learning Framework的生态,应该是未来AI编译器的主要玩家。而这些开源的编译器项目,也为各个做AI芯片的厂商提供了编译器框架的基础,大大降低了大家自研编译器的门槛。另一类编译器是针对专门硬件的,主要是芯片大厂的自研编译器,比如Nvidia的TensorRT,以及Intel,Xilinx的编译器。虽然,目前手工优化库也还是重要的优化方式,在一些架构上还是比编译器的结果好很多,但总的来说, 编译器项目的繁荣,也是AI芯片产业逐渐成熟的表现 。
AI芯片2.0
最后,我们详细看看Yann LeCun教授对未来AI硬件的预测。他的思考主要是从算法演进的需求出发,几个重点包括:
Dynamic Networks ,简单来说就是神经网络的结构和数据相关,会根据输入数据(或者中间结果)选择不同的分支和操作。而目前AI加速,特别是对于Inference的加速,其高效执行的一个前提就是网络的确定性(静态性),其控制流和数据流是可以预先安排和优化好的。动态网络相当于把这个前提打破了,对架构的灵活性有更高的要求,需要在灵活性和高效性之间得找到新的平衡点。
Neural Network on Graphs 。目前的神经网络处理的基本数据主要是张量tensor,相应的,目前的AI硬件的基本要求是对tensor运算的加速。而对于图网络来说,数据变成了以tensor为节点和边的图。如果图网络成为主流,则又改变了AI硬件设计的一个前提。专门用于图计算的芯片已经是一个重要的研究方向,落地的速度估计还得看算法演讲的速度有多快。
Memory-Augmented Networks 。这个主要是对存储架构的新需求,特别是对长期记忆的模拟(在大量存储中实现Attention机制,我在之前的文章里也讨论过)。未来我们可能需要在大量memory中快速找到关注的内容,这要求存储器不只像目前一样实现简单的存取功能,还需要具备查询和运算能力,比如根据输入向量找到一组值;或者一次读取多个值,然后和一个输入向量做运算并输出结果。
Complex Inference and Search 。这个问题简单来说就是在做inference的时候可能也需要支持反向传播计算,这当然会影响目前的单向inference运算加速的架构。
Sparse Activations 。这个预测是说未来的神经网络可能是一个功能非常强大的巨型网络,但针对一个任务只需要激活极少一部分(之前Jeff Dean也做过类似预测)。这个问题涉及两个方面,一是如何利用稀疏性(比如像大脑一样只有2%激活);另一个问题在于这个巨型网络的存储和运算。目前我们还不知道在这个方向上未来会发展到什么程度,不过这个趋势可能导致我们必须应对整个神经网络的存储和运算架构中出现的新的瓶颈问题。
当然,上述一些算法发展的趋势是Yann LeCun教授的看法,未来我们还可能看到其它算法上的演进甚至变革。芯片设计,特别是Domain-specific架构的芯片是由该领域的算法驱动的。 算法的改变会影响我们的优化策略和trade off的sweet spot 。正如Yann LeCun教授所说“ New architectural concepts such as dynamic networks, graph data, associative-memory structures, and inference-through-minimization procedures are likely to affect the type of hardware architectures that will be required in the future. ”。
第一代AI芯片从2016年开始爆发,到目前在架构设计上已经比较稳定,相关的编译器的技术越来越成熟,整个产业格局基本成型。可以说,目前的AI芯片软硬件技术已经为规模商用做好了准备(AI芯片0.5)。未来的一到三年中,我们应该可以看到“无芯片不AI”的景象(AI芯片1.0)。再看更远的未来,随着算法演进,应用落地,会不断给芯片提出新的要求,加上底层半导体技术的进步,我们可以期待在3到5年内看到第二次AI芯片技术创新的高潮(AI芯片2.0)。
Reference :
[1]. Yann LeCun, “Deep Learning Hardware: Past, Present, and Future”, ISSCC2019
[2]. "C4ML workshop at CGO 2019", https://www.c4ml.org/
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号