
[原创] Arm为服务器芯片放了个大招
在过去的十年中,我们记录了ARM处理器在数据中心(特别是通用服务器)的崛起。这是充满希望和失望的十年。但是数据中心正在发生变化,计算、存储和网络必然被推到网络的边缘,更接近终端用户,因为许多现代应用的延迟要求较低,而且集中移动和存储数据的巨大成本可能只是临时使用。因此,ARM今天的机会或许比10年前开始这一征程时要好。
ARM Holdings是软银集团的一个部门,拥有ARM架构并将其授权给无数芯片开发商用于各种设备,ARM Holdings已经在智能手机领域占据主导地位,在平板电脑领域占有相当大的份额。在数据中心和边缘的各种辅助计算设备(如4G蜂窝网络)领域,ARM Holdings在所有芯片制造商中(包括英特尔的X86)占据最大份额。
随着5G网络的出现,数据中心将变得更加前沿,因为5G最终将提供只有光纤有线网络才能提供的带宽和延迟。但在短期内,5G带宽的增长仍将相当可观,峰值下载速度可能达到20 GB/秒,而4G的峰值速度为1 GB/秒;理论上,上载速度通常是下载速度的一半。5G网络的实际性能将取决于蜂窝无线网络中使用频谱的哪一部分,以及蜂窝设备所在的地形(包括建筑物)。重点是,网络性能提高20倍,延迟降低60到120倍,这将极大地改变世界使用蜂窝网络的方式。
毫无疑问,蜂窝运营商和为这些设备创建应用的用户将使用这些带宽,他们将需要在5G基站和各种边缘位置进行足够的网络化、存储和计算,从而实现传统有线电信接入点的前端(最终网络必须在某个地方通过线路进行通信)或提供缓存服务来加速应用程序。如果网络本身是快速的,那么缓存就变得不那么必要了,网络不仅仅是传递数据,而是能够进行计算和操作。
ARM知道这波浪潮即将到来,于是在去年年底发布了它的Neoverse架构,以更好地满足数据中心的需求和计算方面的优势。ARM的授权商一直难以在数据中心处理器领域取得不错的销售业绩。Marvell的ThunderX2绝对是可以基于概念证明的,Ampere(它从AppliedMicro购买了X-Gene芯片)有希望,亚马逊似乎对它自己开发的“Graviton”ARM服务器芯片非常认真,即使AMD、高通和Broadcom退出了,Calxeda还没有真正开始,三星也停止了。然而,在边缘,ARM集体面临来自英特尔和AMD的激烈竞争,它们都拥有各自的Xeon和Epyc平台,但ARM是老牌厂商,它们是后起新贵。
通过这种方式,“Helios”Neoverse E1处理器瞄准了边缘,这是本周在巴塞罗那举行的世界移动大会(现在被称为MWC,这很愚蠢)的一个热门话题,对于ARM在服务器计算方面的愿景而言,这可能比一周前公布的“Ares”Neoverse N1处理器更重要。非常清楚的是,N1处理器将会有边缘变体,如果客户想要它们,可能会有E1处理器的数据中心版本,这实际上取决于ARM的合作伙伴。Helios E1芯片非常有趣,我们认为它将会出现在内核数据中心和边缘设备中。重要的是,ARM已经推出了一款低功耗设备,其目标是更全面的计算——也就是E1——以及一个更强大、更传统的CPU,可以在其家庭数据中心领域与Xeon竞争,ARM的芯片合作伙伴可以向上或向下扩展每个设计,以填补细分市场的空白。他们并不需要做很多工作,而过去并非如此,希望这将帮助ARM的合作伙伴更及时地将产品推向市场。英特尔10纳米的制造停滞不会永远持续下去。
增强竞争优势
从概念上讲,Neoverse E1芯片与N1芯片的关系就像英特尔的Atom芯片与Xeon芯片的关系一样。当然,这个类比并不完美。Atom芯片具有超线程,也就是英特尔的同步多线程实现,即SMT,它虚拟化了芯片指令流水线,使其在操作系统中看起来像两个线程,而不是一个物理线程。(其他供应商可以做四路甚至八路SMT,但英特尔一直选择双向SMT。)Atom芯片有顺序执行,这牺牲了20年前在RISC/Unix平台上首次出现的无序执行所能获得的一些性能,这是Xeon系列的一部分,也是数据中心中几乎所有其他处理器的一部分。
Neoverse N1和E1处理器都支持其流水线上的无序执行,但ARM首次在其ARMv8架构上用Helios E1芯片实现了SMT。直到最近,ARMv8体系结构的被授权方才将无序执行和SMT添加到他们创建的内核中,但是现在ARM正在做这项繁重的工作。Cortex-A57芯片针对的是平板电脑和具有适度计算需求的设备,具有乱序执行,后续的Cortex-A73和Cortex-A75处理器也是如此。但是这些都不像Helios E1那样有SMT。
这种SMT以及ARM在单个芯片上创建的将内核结合在一起的网状互连,将是提高边缘设备性能的重要因素,例如5G基站中的25瓦至35瓦处理器,位于数据中心的其他类型的协处理器和加速器,如SmartNIC,以及数据传输设备,如内核路由器,它们的计算中有多个100 Gb/秒的端口。
ARM基础设施业务营销副总裁Mohamed Awad表示,这些都是Helios E1处理器目标市场的一部分。他最近在奥斯汀举行的ARM技术日(ARM Tech Day)上谈到了潜在的使用案例。
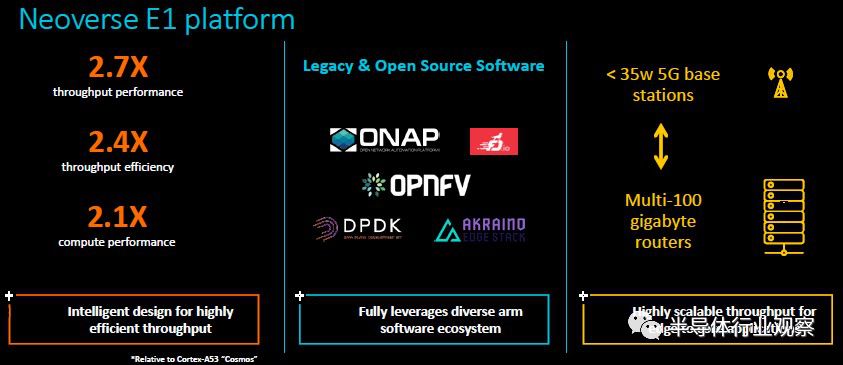
“E1将支持bot旧式软件和开源软件,因此它可以快速插入并执行OPNFV和ONAP,并支持DPDK。”Awad解释说。他使用开放式网络功能虚拟化平台(电信公司和服务提供商创建并使用的参考平台)和开放式网络自动化平台的字母组合,顾名思义,它是一个用于运行的编排和自动化框架,在其中运行网络功能,这些功能过去被硬化到无数供应商的非常昂贵的设备中。DPDK是Data Plane Development Kit的缩写,Data Plane Development Kit是英特尔创建的数据包处理引擎,已开源并交给Linux Foundation管理,现在支持X86、Power和ARM架构。“如果你考虑一下从边缘到内核的基础设施,就会看到有很多设备和软件都与之相关,我们推出的Neoverse E1平台可以支持该旧式软件,但可以过渡到此开源软件。”
Helios芯片的可扩展性将取决于有多少E1内核被网格化,以及Helios内核相对于“Cosmos”系列的前身Cortex-A53的固有性能,后者广泛用于各种网络、安全、存储适配器,以及家电。如果你把边缘和数据中心使用的所有处理器(包括4G基站)加上数据中心的服务器、存储和网络,再加上分布在数据中心和边缘的所有安全和网络设备,那么在2011年,ARM占有大约5%的份额。而2018年,当3亿个芯片出货到IT的这个领域时,ARM占有27%的份额,而且这一份额仍在增长。(因此,我们假设这些是收入份额,但考虑到有许多不同类别的机器,看看收入份额会很有趣。总之,钱才是最重要的。)这些芯片不包括WiFi路由器或任何距离家庭或办公室最后一英里的设备——这是计算和存储的优势。并且,也许最重要的是,这使得ARM架构在所有芯片制造商中处于领先地位,比英特尔还大,但我们不知道有多少,因为ARM没有共享这些数据。
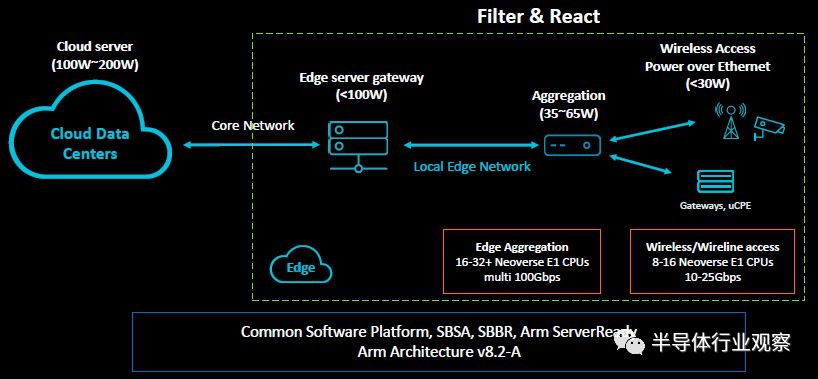
你可能想知道为什么ARM不能只用一个降速的N1芯片来完成所有这些边缘工作。从某种意义上说,确实如此,但它需要更多的架构调整,而不仅仅是减少内核和缓存,从而减少插槽和功率。ARM架构和技术团队的系统架构师和杰出工程师Rob Dimond表示,用于处理数据传输工作负载的计算需要能够在未来十年内处理10倍的增长系数。如果你计算一下,这意味着吞吐量类型的处理器每年大约增长60%,这意味着那些面向线程密集的软件和相对低功耗的处理器,而不是面向具有更快时钟和大量缓存的大型内核,这两种处理器都会产生大量热量。
正如我们去年秋天解释的那样,Neoverse N1系列的承诺是每年在套接字级别上提高30%的性能。没错,ARM正在证明,与早期的Cosmos Cortex-A73处理器相比,在64核Ares芯片上运行的各种工作负载可以在1.7X和2.5X之间进行,因此它的增长率远远超过了60%。与此类似,Helios芯片的内核运行速度比Cortex-A53参考架构快2.1倍,整个速度比后者高出2.7倍,但这一最初的提升可能并非每一代都能持续下去。尤其是如果ARM试图坚持为E1设计提供年度升级节奏,正如它对N1设计所承诺的那样。
深入研究HELIOS E1
虽然Ares N1处理器将支持32位ARMv7和64位ARMv8指令,但为了节省Helios E1处理器的功耗和芯片面积并为SMT腾出空间,32位处理和内存寻址能力被放弃。以下是ARM为E1开发的SMT模型的细节:

随着时间的推移,ARM将SMT增加一倍到4个线程,然后再增加到8个线程,以达到每个套接字60%的性能提升目标,这并不是没有道理的。SMT8在销售Sun Microsystems的T系列芯片时确实发挥了作用,对于IBM的Power8、Power9和Power10处理器来说,SMT8仍然非常有用,可以提高线程之类工作负载的吞吐量。同样,在以后的几年里,最终看到SMT出现在Neoverse N2或N3或N4处理器中也就不足为奇了。
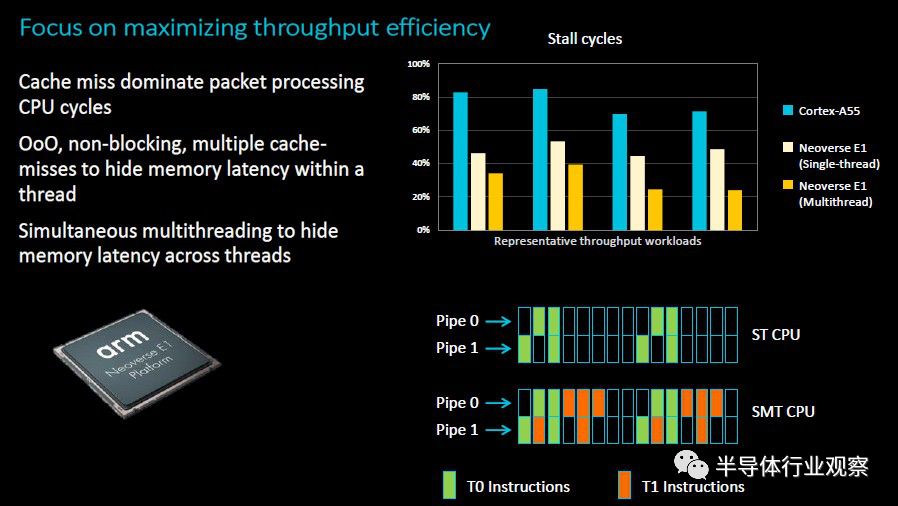
顺便说一句,E1芯片上的SMT可以通过软件切换来打开和关闭,因此对于那些在每个内核单个线程以更高的时钟速度运行时可以做得更好的工作负载而言,可以切换模式。
整个E1设计侧重于平衡套接字中的吞吐量和内核中的原始计算,并最大限度地提高边缘工作负载、数据中心数据平面和控制平面,以及具有网络、存储和安全功能的服务器加速器的每瓦吞吐量。
E1内核有32 KB或64 KB的L1缓存(带奇偶校验)和32 KB到64 KB的L1数据缓存(其中有ECC擦除)。每个内核还可以拥有64 KB到256 KB的L2缓存,前端是L1缓存,也有ECC擦除。内核还可以包含加密引擎和NEON AdvSIMD浮点单元,如下所示:
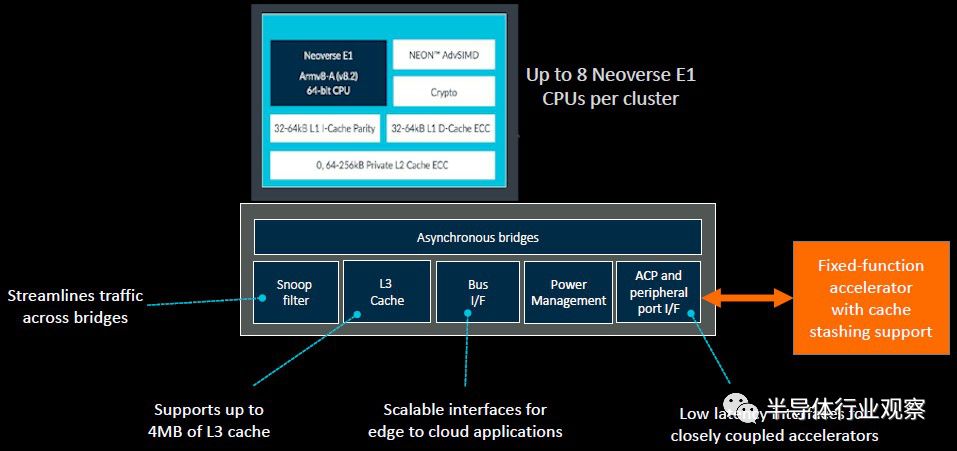
Helios的E1集群上最多可以有八个内核,绕内核的电路具有异步桥接,可连接高达4 MB的L3高速缓存,以及用于外围设备的各种总线接口,包括上述用于固定功能加速器的接口。你可以在E1芯片上有多个集群,cookie将它们切割到网格互连上。据推测,客户可以抓取内核并在E1内核之间进行网状互连,就像N1设计中所做的那样,而不是对它们进行集群,或者将集群拆分成chiplet,并使用CCIX端口将chiplet连接在一起,N1芯片也会是这样。(我们必须要看看ARM的合作伙伴如何利用所有这些好处。)
如果您想研究内核流水线,并将其与Neoverse中的Ares N1芯片进行比较和对比,请参见下面的框图:
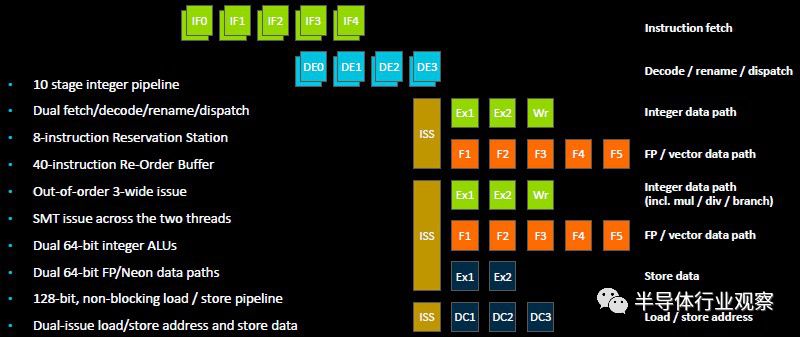
N1和E1有很多不同之处,最大的区别在于N1有一个固定的10级整数流水线,而不是可以从11级扩展到9级的可变的“手风琴”流水线。你可以看到三个宽流水线和两个SMT流,它们使用一对匹配的64位浮点单元实现两个64位整数单元。
这对浮点数单位在E1上的数量是在N1上的一半。考虑到每个人都期望在边缘进行大量推理,因此,对于与机器学习推理相关的混合精度数学,更精简的E1数学单元可能仍然有用。浮点数单元可以在每个周期中一起执行8个FP16操作,或者4个FP32操作,或者16个INT8格式的“点积”指令。(最后一点就是推理最有可能发挥作用的地方。)如果你看看Helios E1芯片的原始整数性能,它是关闭线程时Cortex-A53的1.4倍,打开SMT2时的1.8倍。使用浮点时,在激活SMT2的情况下,Cortex-A53和2.4X之间的性能提升为2倍。
总而言之,台积电在7nm制程中采用的裸片尺寸为0.46 mm2,2.5 GHz的频率,功率为183毫瓦。ARM为被授权方提供的参考设计芯片上有一对八核集群,由CMN-600网格互连和挂在网格上的两个DDR4内存控制器连接。这些内核的功耗预算低于4瓦,整个片上系统的功耗低于15瓦,SPECint_rate2006为153,可以25 Gb/秒的速度发送数据,这就是目前超大规模数据中心服务器端口所做的工作。在一个小型5G基站部署中,一个E1集群用于控制平面,另一个用于数据平面,无线电和安全电路将被添加到其中。在该小型5G蜂窝基站上运行OpenSSL和DPDK的E1参考平台,其性能将是基于Cortex-A53芯片的同类平台的2.7倍,每瓦功率性能提高2.4倍。
这些都是相当不错的比较,但真正的考验是它们如何堆叠到真正的芯片,特别是嵌入式芯片,英特尔和AMD正在向市场推出嵌入式芯片,以处理相同的边缘工作负载。到目前为止,我们还没有看到这样的比较基准。
以下是另一个示例,说明如何在软件定义的网络设备上使用在3×5网格上实施的E1和N1处理器组合,来创建在E1上运行的高吞吐量数据平面,以及在N1上运行的强大控制平面,从而能够以100 Gb/秒的线速执行数据包处理:
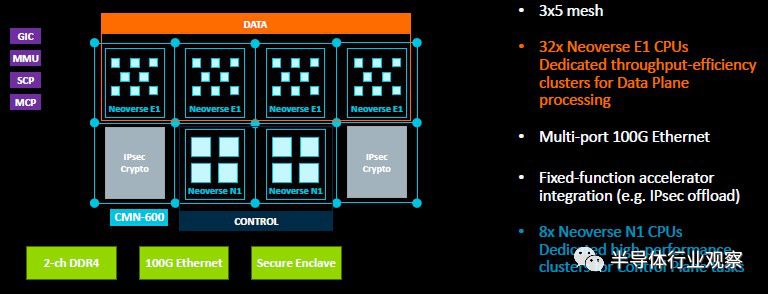
我们可以想象E1和N1芯片的各种用途和各种配置。和ARM团队一样,现在的问题是:ARM的哪些合作伙伴要做什么才能将基于这一创新技术的芯片推向市场?此外,他们会有多大的冲动去小题大做呢?希望能有更多的合作伙伴,并少些麻烦。时间是很宝贵的。





-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 荣芯半导体:专注成熟工艺
- 2 破除AI落地难题!英特尔全新软硬件平台,助力企业AI创新
- 3 面板行业专题报告之一:OLED的美好时代
- 4 发布新CPU,Imagination进军RISC-V,信心十足
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号