
[原创] 详解Arm的Cortex-A77 微架构:不断提升的性能

对于Arm自己的CPU设计而言,2018年是激动人心的一年。去年5月,我们看到了Cortex-A76的推出,以及随后产生的麒麟980以及Snapdragon 855 SoC形式的芯片。我们对IP印象非常深刻,Arm成功地兑现了其所有性能、效率和面积承诺,从而为2019年的大多数旗舰设备提供了一些出色的SoC和器件。
今年,我们跟进了TechDay的另一个新闻,这一次我们报道了Arm针对Cortex-A76的后续行动:新的Cortex-A77。新一代A77是去年推出的主要架构的直接演变,代表了Arm的全新Austin核心家族的第二个实例。今天,我们将分析Arm如何推动其新微架构的IPC,以及这将如何转化为即将到来的2019年末/2020年初的SoC和器件的实际性能。
Deimos转向Cortex-A77
鉴于Arm仍旧保持着每年发布IP的节奏,Cortex-A77的发布并不让人意外。事实上,今天并不是Arm第一次谈论A77:去年8月,Arm在发布2020年前的性能路线图时调侃了CPU核心:
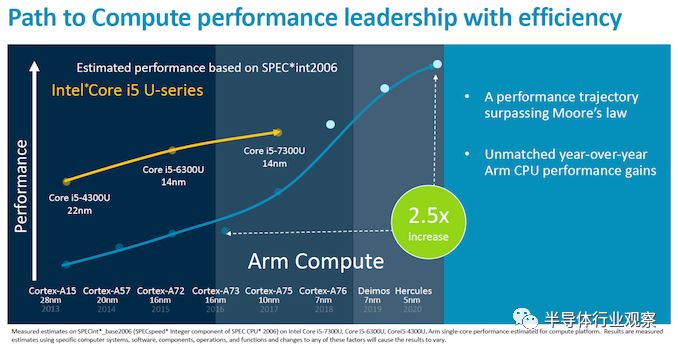
代号为“Deimos”的新款Cortex-A77继承了Cortex-A76的设计,并遵循Arm的发展轨迹,每一代Arm的Austin系列CPU都将带来持续稳定的20-25%的性能提升。
在我们讨论新的Cortex-A77之前,我们应该回顾一下Arm的A76性能是如何演变的:
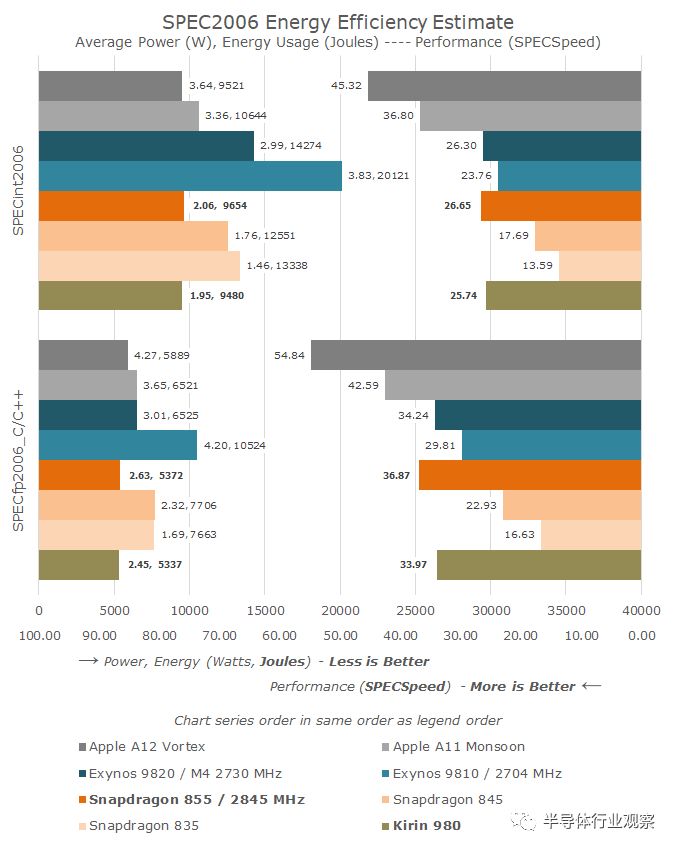
对于Arm及其授权商来说,A76无疑是一个非常成功的核心。全新的微架构与台积电7nm工艺节点的重大改进相结合,带来了业界有史以来最大的性能和效率飞跃。
其结果是,麒麟980以及Snapdragon 855都比各自的前代产品有了较大的飞跃。高通称,与上一代配备Cortex-A75核心的Snapdragon 855相比,CPU性能提高了45%,这是有史以来最大的代际飞跃。
虽然性能显著提高,但我们看到这一代产品的能效提升更令人印象深刻,并直接导致使用新麒麟和Snapdragon SoC的设备的电池寿命得到提高。
虽然A76表现很好,但我们应该记住,它确实有竞争对手。三星今年推出的M4微架构缩小了性能/效率差距,但Exynos CPU在很大程度上仍然落后了一代,尽管今年的工艺节点差异(8nm vs 7nm)加大了这一差距。Arm真正的竞争对手是苹果的CPU设计团队:目前A11和A12仍然保持着巨大的性能和效率领先优势,领先优势大约相当于两代微架构。

芯片照片来源:ChipRebel 标注:AnandTech
然而,ARM的强项之一仍然是提供业内最好的PPA。尽管A76的性能无法匹敌苹果的性能,但它以极小的芯片面积尺寸实现了出色的效率。事实上,这是Arm有意识的设计决策,因为电源效率和面积效率是Arm授权商的首要任务之一。
Cortex-A77:顶层概览
Cortex-A77是A76的直接微架构继承者,这意味着新核心在很大程度上保持了前代的特性。Arm指出,构建核心时,供应商可以简单地升级SoC IP,无需付出太多工作。
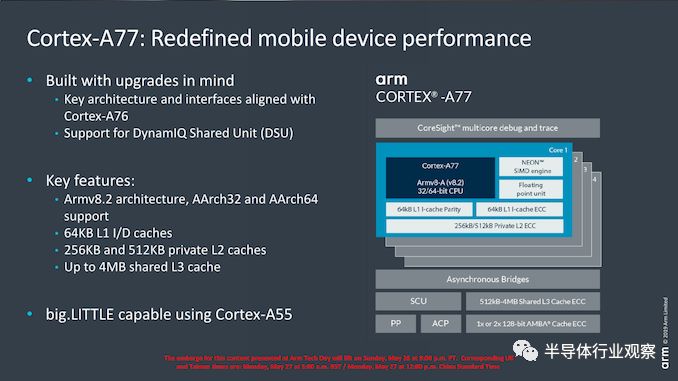
实际上,这意味着A77在架构上与A76保持一致,仍然是ARMv8.2 CPU核心,旨在与DynamIQ共享单元(DSU)集群内的Cortex-A55小CPU配对。
与前代相比,基本配置特性(如A77的缓存大小)也没有变化:我们仍然看到64KB L1指令和数据缓存,以及256或512KB L2缓存。有趣的是,Arm确实为基础设施Neoverse N1 CPU核心设计了1MB L2缓存选项(它本身来自A76),但选择保留客户端(手机)CPU IP上的较小配置选项。
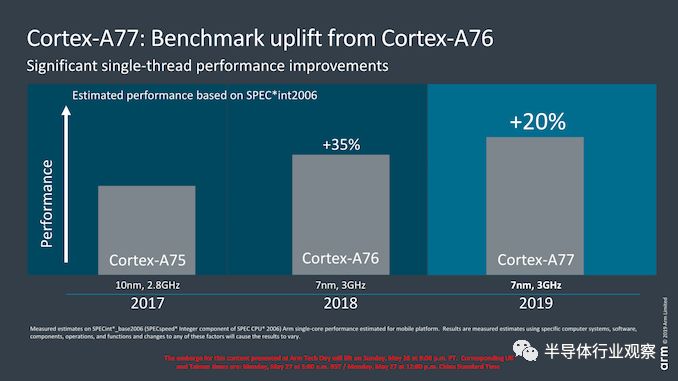
作为A76的演进,A77的性能提升并不会像预期的那样令人印象深刻,无论是从微架构的角度看,还是从绝对性能的角度看都是如此,因为我们无法期望即将到来新一代SoC有很大的工艺节点改进。
此处,对于大多数客户而言,A77的产品预计仍在7nm工艺节点上,Arm也宣称了与前代类似的3GHz峰值目标频率。当然,由于频率预计不会有太大的变化,这意味着核心+20%的性能提升可以完全归功于IP的微架构变化。
为了实现IPC(每时钟周期指令数)的提升,Arm对微架构进行了重新设计,并引入了一些巧妙的新特性,这通常会增强CPU IP,从而实现更广泛、更高性能的设计。
Cortex-A77巡礼:迈向6-Wide前端
Cortex-A76在微架构方面代表了一种全新的设计,Arm从头开始实现了多年CPU设计的知识和经验。这使得Arm能够设计出一种在微架构方面具有前瞻性思维的新核心。A76旨在作为Austin系列接下来两代设计的基准,即今天的新款Cortex-A77以及明年的“Hercules”设计。

A77推出了新功能,其主要目标是提升微架构的IPC。Arm这一代的目标是继续专注于提供业界最好的PPA,这意味着设计师的目标是提高核心的性能,同时保持A76核心卓越的能源效率和面积特性。
在频率方面,新核心保持在与A76相同的频率范围内,Arm在最佳实现中以3 GHz峰值频率为目标。
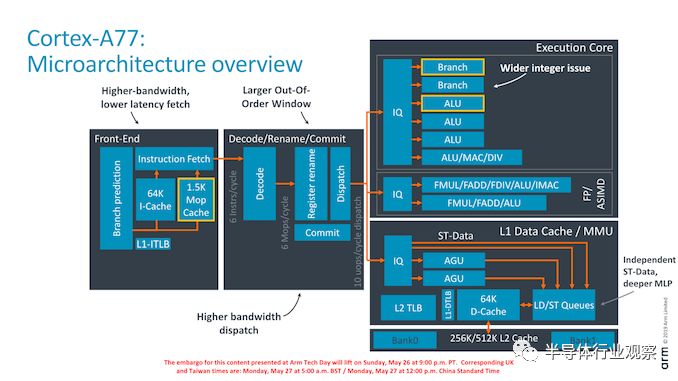
作为对微架构变化的概述,Arm几乎触及了核心的每个部分。从前端开始,我们看到了更高的读取带宽,它的分支预测能力翻了一番,新的macro-OP运算缓存结构充当了L0指令缓存,它有更宽的中央核心,解码器宽度了增加50%,新的整数ALU流水线以及改进的加载/存储队列和发布能力。
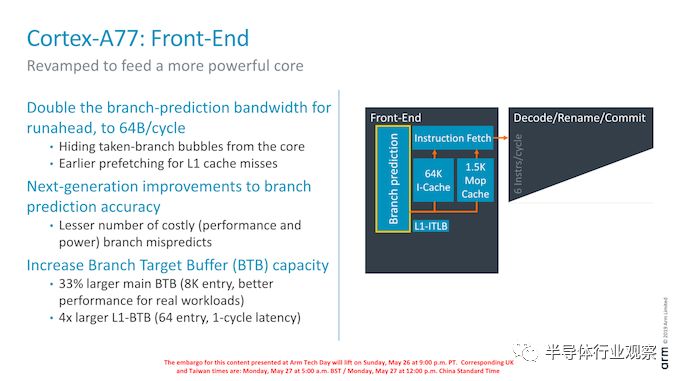
深入到前端,分支预测器的一个重大变化是其超前带宽从32B/周期翻倍到64B/周期。这一增长的原因通常是前端更宽、功能更强,而分支预测器的速度需要提高,才能充分馈送中央核心。Arm指令的宽度是32位(Thumb为16位),因此这意味着分支预测器每个周期最多可以获取16个指令。这比中央核心的解码器带宽高2.6倍,造成这种不平衡的原因是,每当核心中有分支时,就允许前端尽可能快地赶上。
分支预测器的设计也发生了变化,降低了分支的误判,提高了预测精度。尽管A76已经具有非常大的分支目标缓冲容量(6K entry),但ARM在新一代设计中再次将其提高了33%,达到8 Kentry。看起来ARM已经放弃了BTB的层次结构:A76有16-entry nanoBTB和64-entry microBTB,而在A77上,这似乎已经被64-entry L1 BTB所取代,后者的延迟为1个周期。

新前端的另一个主要特性是引入了Macro-Op缓存结构。对于熟悉AMD和英特尔的x86处理器核心的读者来说,这可能听起来很熟悉,并且类似于这些核心中的Lotusop/MOP缓存结构,实际上,假设它们具有类似的功能是正确的。
实际上,新的Macro-OP缓存充当L0指令缓存,其中包含已解码和融合的指令(macro-op)。在A77中,架构是1.5K entry,假设macro-op具有与Arm指令类似的32位密度,则相当于48KB左右。
Arm实现缓存的特点是与中央核心深度集成。在指令融合和优化之后,缓存在解码阶段之后(以一种解耦的方式)被填充。在缓存命中的情况下,前端直接从macro-op缓存馈送到中央核心的重命名阶段,从而削减核心的有效流水线深度的周期。这意味着核心的分支错误预测延迟已从11个周期减少到10个周期,即使它具有13个周期设计的频率能力(+1解码,+1 branch/fetch overlap,+1dispatch/issue overlap)。虽然我们目前没有新核心的最新数据,但Arm的数据非常好,因为其他核心的误判率明显更差(三星M3、Zen1、Skylake:约16个周期)。
Arm使用1.5K entry缓存的理由是,他们的目标是在测试套件工作负载中达到85%的命中率。容量越小,命中率就越低,而缓存越大,回报就越低。相对于64KB L1缓存,1.5K MOP缓存的大小约为面积的一半。
MOP缓存还允许向中央核心提供更高的带宽。该结构能够以64B/周期的速度馈送重命名阶段,同样显著高于核心的重命名/分派能力,而且这种不平衡加上更“胖”的前端带宽允许核心隐藏分支和流水线刷新。
Arm谈到了一些“动态代码优化”:此处,核心将重新安排操作,以更好地适应后端执行流水线。需要注意的是,这里的“动态”并不意味着它实际上是可编程的(类似于英伟达的 Denver代码翻译),逻辑被固定在核心的设计上。
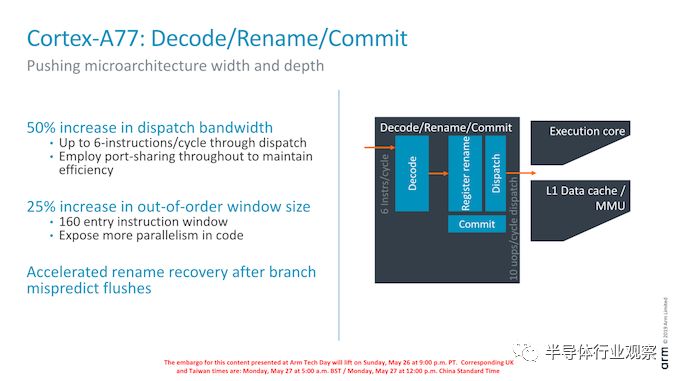
最后谈到中央核心,我们看到核心的带宽有了很大的提升。Arm将解码器的宽度从 4-wide增加到6-wide。增加的宽度也使得核心的重排序缓冲区从128个entry增加到160个entry。值得注意的是,高通公司的Cortex-A76已经出现了这种变化,尽管我们无法确认所采用的确切尺寸。由于Arm仍然负责RTL的更改,所以如果是完全相同的160 entry ROB,我也不会感到惊讶。
同样,当有MOP缓存命中时,中央核心可以绕过它的解码阶段,从而削减一个周期。
Cortex-A77巡礼:添加ALU和更好的加载/存储
在介绍了前端和中央核心之后,我们转到Cortex-A77的后端,研究Arm对执行单元和数据流水线做了哪些更改。
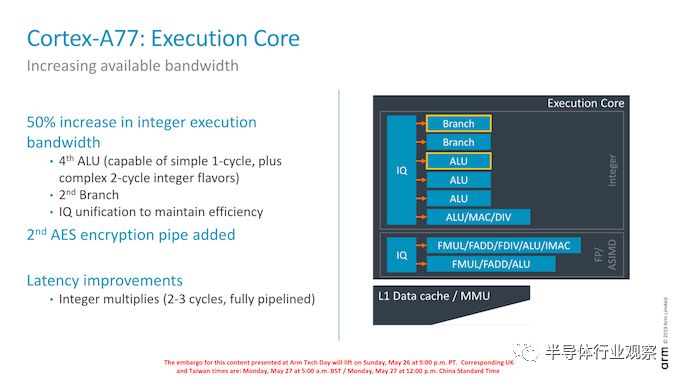
在核心的整数执行端,我们看到增加了第二个分支端口,这与前端的分支预测器带宽加倍一致。
我们还看到它添加了额外的整数ALU。这种新的单元介于简单的单周期ALU和现有的复杂ALU流水线之间:它自然仍具有单周期ALU操作的能力,但也能够支持更复杂的2周期操作(一些移位组合指令、逻辑指令、移动指令、测试/比较指令)。Arm表示,新流水线的添加带来了惊人的性能提升:随着核心变得越来越宽,后端可能会成为瓶颈,这就是执行单元需要与核心的其余部分一起增加的情况。
执行核心的一个更大的变化是统一了问题队列。Arm解释说,这样做是为了通过添加执行端口来保持核心的效率。
最后,现有的执行流水线没有发生太多变化。一个延迟改进是复杂ALU上的整数乘法单元的流水线操作,这使得它可以实现2-3个周期的乘法,而不是4个周期。
奇怪的是,Arm没有过多提及Cortex-A77的浮点/ ASIMD流水线。此处,A76“最先进”的设计似乎足以让他们把精力集中在这一代核心上。

在加载/存储单元中,我们仍然可以找到两个单元,但是Arm在单元中添加了两个额外的专用存储端口,这实际上使问题带宽增加了一倍。实际上,这意味着L/S单元是4-wide,具有2个地址生成µOps和2个存储数据µOps。
问题队列自身再次统一,Arm将容量增加了25%,以暴露更多的内存级并行。

为了隐藏系统的内存延迟,数据预取非常重要:通过避免等待数据来缩短周期可以极大地提高性能。在我们对Galaxy S10的评测中,我试图介绍Cortex-A76的新型预取器,并将其与业内其他CPU进行对比。Arm的突出之处在于A76的新型预取器性能出众,能够处理一些非常复杂的模式。事实上,A76做得比其他被测试的微架构都要好得多,这是一个相当了不起的成就。
对于A77,Arm改进了预取器,并添加了新的额外预取引擎来进一步改进这一点。Arm对这里的细节守口如瓶,但Arm承诺增加模式覆盖范围和更好的预取准确性。其中一个变化被称为“增加的最大距离”,这意味着预取程序将在更大的虚拟内存距离上识别重复的访问模式。
A77中新增的一个功能称为“系统感知预取”(system-aware prefetching)。Arm试图解决在不同系统的加载中必须使用单个IP的问题;某些系统可能具有比其他系统更好或更差的内存特性,比如延迟。为了处理内存子系统之间的这种差异,新的预取器将根据当前系统的运行状况改变运行状况。
我的想法是,在某些DVFS条件下,这可能意味着一些有趣的性能改进:预取程序将根据当前的内存频率改变它们的运行状况和侵略性。
这种新系统感知的另一个方面是更多地了解DSU的L3缓存的缓存压力。如果其他CPU核心非常活跃,核心的预取程序就会看到这一点,并降低其侵略性,以避免不必要地冲击共享缓存,从而提高整体系统性能。
性能目标:IPC提升20~35%
Cortex-A77看到了一些有趣的微架构变化,这些变化有望提高性能。现在的问题仍然是,目标性能提高的最终结果是什么?
在公布的性能改进方面,Arm选择保留SPEC2006、2017、GeekBench4和LMBench内存带宽。我们这里的重点将放在SPEC2006上,因为它仍然是移动设备中最相关的基准。
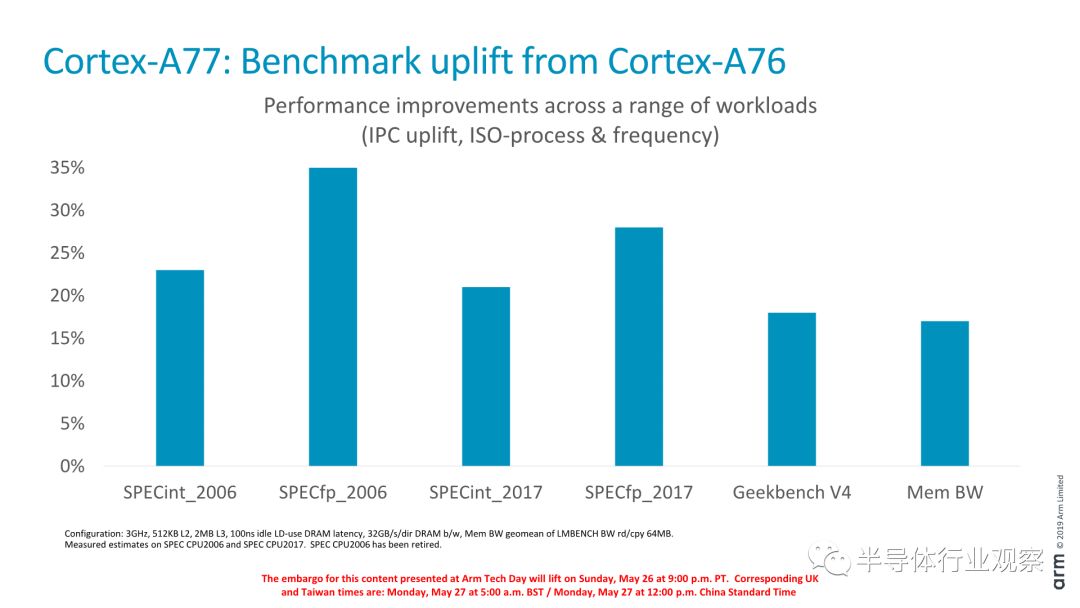
在SPECint2006上,A77承诺IPC将提升23%左右,而SPECfp2006则宣称将提升35%。整数工作负载的23%的增长与我们对CPU核心的预期基本一致,但是我必须承认,FP工作负载的30-35%的增长是相当令人惊讶的,特别是因为我们还没有看到核心的FP执行单元有任何重大的变化。这里的一种解释是,SPEC的FP测试套件比整数套件占用更多内存,Cortex-A77的各种微架构改进在这些工作负载中更明显。
去年,我对A76在两个频率点的性能和效率进行了预测,结果非常接近麒麟980和Snapdragon 855的实际位置。对于Cortex-A77则应该更加直观,因为我们不会在下一代7nm SoC中看到主要的工艺节点变化。
基于麒麟980目前的结果,我简单地基于已发布的2.6 GHz Cortex-A77 SoC的IPC提升来推断性能。值得注意的是,虽然Arm今年再次谈到了A77的3 GHz目标频率,但我并不看好供应商在即将到来的SoC中达到这个频率,因此我的预测是2.6 GHz。
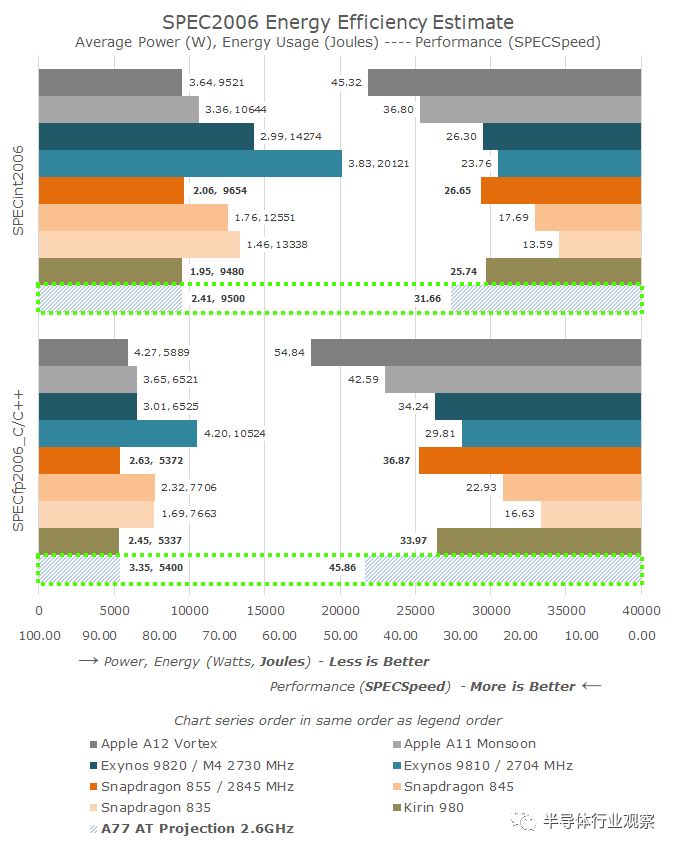
就性能而言,整数套件会有一些明显的改进,但是浮点结果要有趣得多。果真如此的话,那么A77将超过苹果的A11的FP性能,即使我们不期望工艺节点有大的改进,这也将是相当大的代际推动力。不过值得注意的是,今年晚些时候,A77将不得不与苹果的A13以及三星的下一代M5核心展开竞争。
Arm承诺,A77的能效将与现有的A76 SoC保持一致。因此,在峰值性能时,两个CPU核心将使用相同的能量来完成设置的工作负载。然而,A77性能的提高有一个缺点:功耗的增加,它与性能数字的增加成线性关系。后者增加的功耗似乎会达到峰值频率运行两个以上核心的水平,这在移动SoC中会有更大的问题。幸运的是,大多数供应商已经从4个全速的大核心转向2+2或3+1设计,其中只有一个或两个高功率大核心。
值得注意的是,虽然我们在这里谈论的是大核心,但A77据说只比A76大17%,仍然比竞争对手的下一代最好的微架构小得多。
结束语
总体而言,Cortex-A77今天宣称的变化并不像我们去年在A76上看到的那样大,也不像今天新发布的Arm新ValHall GPU架构和G77 GPU IP那样大。
然而,Arm通过A77成功实现的是继续执行他们的路线图,这在竞争环境中是非常重要的。A76实现了Arm的所有承诺,最终成为一个性能极佳的核心,同时保持了惊人的效率,并在密度上明显领先于竞争对手。在这方面,Arm的主要客户仍然非常注重在他们的产品中拥有最好的PPA,而Arm也在这方面提供服务。
A77的一大惊喜是,它的浮点性能提升了30~35%,比我对核心的预期要高得多,而在移动领域,网页浏览是恰巧是考验浮点运算的杀手级应用,所以我期待着未来拥有A77的SoC会有怎样的表现。
但即使是在整数工作负载中,20~25%的IPC提升也绝对是了不起的改进,我们相信ARM能够保持A76的能效。功耗将略有上升,但我认为业界已经表明,今天的移动设备可以正确处理至少两个更高功率的核心,因此未来的SoC应该继续使用大+中+小CPU配置。
来自供应商的A77 SoC预计仍将是7nm工艺——高通和海思显然是采用该核心技术的两家领先客户,我预计其时间框架与上一代芯片组类似。目前,Arm正在实现他们承诺的每年20~25%的CAGR,我们相信,这将在可预见的未来几代产品中继续下去。





-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号