来源:本文由公众号半导体行业观察(ID:icbank)翻译自「
anandtech
」,
作者:Andrei Frumusanu
,谢谢。
今年,知名硬件网站anandtech发布了对苹果iPhone 11系列和苹果A13芯片深入解读。
在芯片环节,他们通过对苹果这颗芯片的深入分析。
并得出一个结论:
与所有的安卓系芯片相比,苹果A13拥有最佳的性能表现。
首先在制造工艺方面,
根据anandtech的分析,苹果A13使用的是N7节点的性能调整型工艺,而不是基于EUV生产的N7 +节点。
他们进一步指出,他们这边还没披露这颗芯片的具体尺寸,但从TechInsights的数据显示,苹果新芯片的尺寸为98.48mm²,比去年的A12大18.3%。
而在内核性能方面,
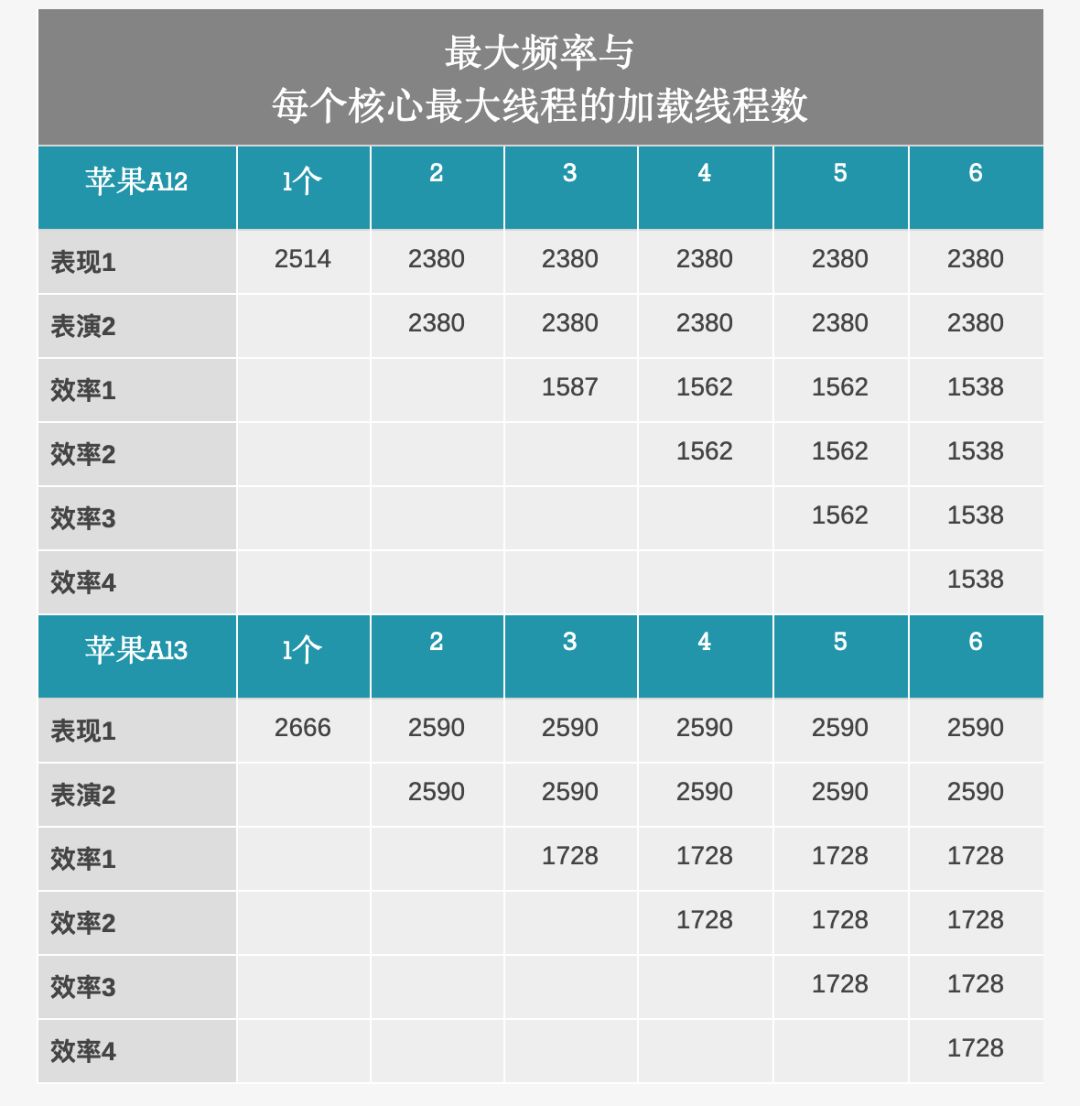
anandtech表示,A13同样采用“2+4”的设计,其大型性能内核的时钟速度与前一代相比,大约提高了6%,使其达到2666MHz左右。
但根据去年的经年,当时A12大内核的时钟频率约为2500MHz,但在性能计数器测得的准确数字似乎是2514MHz。
同样,A13的大核心时钟应比其估计的2666MHz时钟高几个MHz。
小型效率内核的时钟频率提高了8.8 – 12.3%,使其最高频率达到了约1728MHz。
这是一个很好的提升,但是重要的是,当有更多的小核处于活动状态时,它们现在不会降低时钟频率。
anandtech进一步指出,这一代的大型内核称为“Lightning”,是去年Vortex微体系结构的直接后继产品。
在他们看来,新的内核在核心设计方面,至少在通常的执行单元方面,与去年的核心之间没有太大差异。
微体系结构的核心仍然是7宽(wide)的解码前端,与非常宽的执行后端配对,该后端具有6个ALU和3个FP /矢量流水线。
因为Lightning和Vortex两者在很大程度上相似,所以anandtech认为Apple尚未对执行后端进行任何实质性更改,但值得注意的是其复杂的整数管道,在这上面确实看到了改进。
在这里,两个乘法器单元可以减少一个周期的延迟,从4个周期减少到3个周期。
整数吞吐量也得到了很大的提升,因为吞吐量现在已经加倍,并且延迟/最小周期数从8个减少到8个。
7个周期。
在缓存方面,
苹果似乎保留了A12的Vortex内核中的缓存结构。
这意味着我们具有8路关联的128KB L1指令和数据缓存。
数据高速缓存保持非常快的速度,并具有3个周期的加载使用延迟。
内核之间共享的L2高速缓存继续保持8MB的大小,但是Apple已将延迟从16个周期减少到14个周期,
在发布会的时候,我们记得苹果介绍芯片的时候提到,CPU内核的一个重大变化是Apple将“机器学习加速器”集成到微体系结构中。
从本质上讲,它们似乎是矩阵乘法单元,并带有类似DSP的指令,Apple将其性能提高到了1太字节操作(TOP)吞吐量,声称比常规矢量流水线提高了6倍。
根据anandtech的分析,该AMX指令集似乎是在CPU内核上运行的ARM ISA的超集。
关于这意味着什么一直有很多困惑,因为直到现在还不广为人知,允许Arm体系结构的被许可人使用自定义指令扩展其ISA。
我们无法从Apple或Arm那里得到任何确认,但是,很明显的一件事是Apple并未向开发人员公开公开这些新指令,并且它们也未包含在Apple的公共编译器中。
但是,我们确实知道,Apple内部确实有可用的编译器,并且Acclerate.framework之类的库似乎能够利用AMX。
rm最近透露了将定制指令提供给供应商以实施和集成到Arm内核中的证据,这显然足以证明体系结构被许可人可以自由地做自己想做的事情–苹果选择隐藏AMX指令至少可以解决对可能的ISA的担忧软件方面的碎片化。

CPU内核:重大升级
苹果公司的小型效率内核非常有趣,因为与Arm的典型小型内核(例如Cortex-A55)相比,它们并没有那么小。
去年,A12中的Tempest效率核心基于一个3幅乱序的微体系结构,该体系结构具有两个主要执行管道,与L / S单元一起工作,我们假设这是一个专用的单元。
今年的Thunder微体系结构似乎对效率CPU内核进行了重大更改,因为我们看到了新内核的执行功能的实质性升级。
就整数ALU而言,我们似乎仍在查看两个单元,但是Apple已将能够进行标志设置操作的单元数量从1倍增加到2倍。
MUL吞吐量在每个周期保持1条指令,而除法单元也是貌似不变。
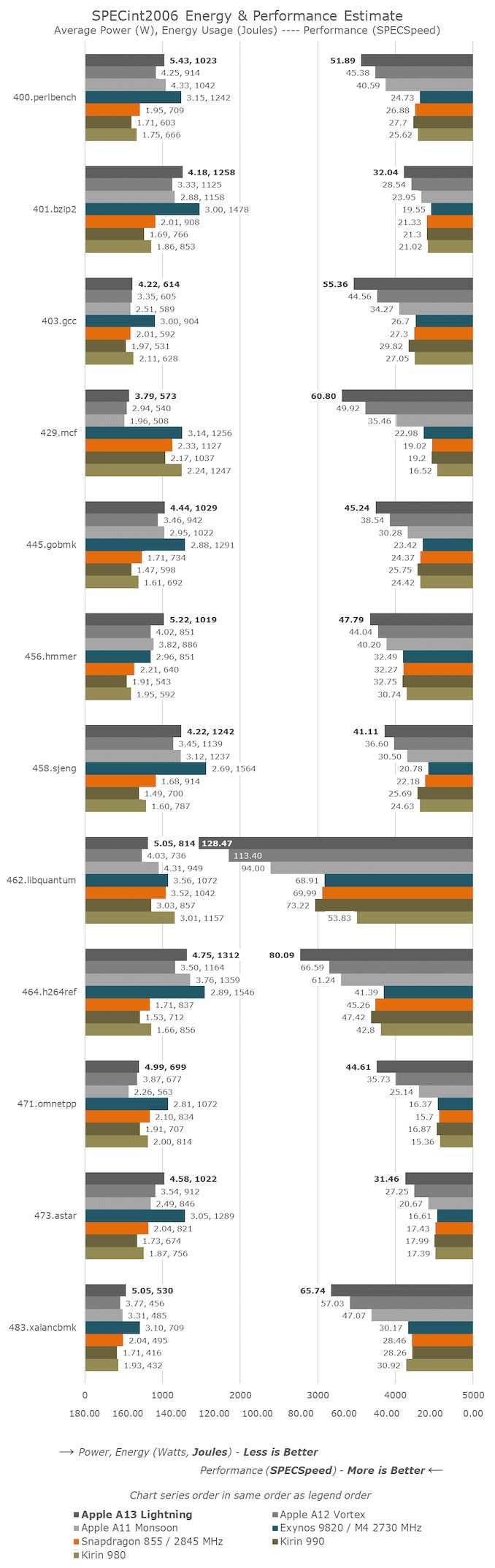
从新的A13 Thunder内核的性能来看,我们看到新的微体系结构已大大提高了IPC,SPECint的增益从403.gcc的19%提高到400.perlbench的38%,而浮点性能在非内存绑定的SPECfp工作负载中,性能也同样提高了34-38%。
在其他方面,我们看到一些性能下降,这是因为Apple更改了内存子系统的DVFS策略,导致效率核心无法触发某些内存控制器的更高频率性能状态。
这导致我们看到一些奇怪的结果,例如470.lbm。
新内核的电源效率也明显更高。
当然,其中一些改进将归因于系统内存运行速度不快,但考虑到内核仍可在SPEC套件中提供10%到23%的平均性能,仍然给人留下深刻的印象,即能耗降低了25%平均而言,也指向主要的效率提升。
面对Lightning核心(除AMX之外)相对保守的变化,新的Thunder核心对于A13来说似乎是彻底的巨大变化,并且与Apple过去的效率核心微体系结构存在重大分歧。
在与诸如Snapdragon 855的Cortex-A55实施方案进行对抗时,新的Thunder内核表现出2.5-3倍的性能领先优势,而能耗却不到一半。
SPEC2006性能:台式机水平
鉴于我们没有看到大型Lightning CPU内核的微体系结构有太多重大变化,因此我们不会期望其较之A12,性能会有特别大的提高。
但是,由于内存子系统和核心前端的改进,时钟频率增加了6%,而IPC却提高了几个百分点,因此可以,而且确实会带来大约20%的性能提升,这与实际情况是一致的。
苹果在做广告。
我暂时仍要回到SPEC2006,因为我还没有时间移植和测试2017年的移动设备。
在SPECint2006中,性能的改进相对平均地分布。
平均而言,我们看到性能提高了17%。
最大的收益来自受延迟限制的471.omnetpp和403.gcc,这给缓存带来了更大的压力。
这些测试分别增加了25%和24%,这是非常显着的。
尽管性能数据非常简单明了,而且没有任何令人惊讶的地方,但另一方面,功率和效率数据却极其出乎意料。
在几乎所有的SPECint2006测试中,Apple都采用了A13 SoC并提高了峰值功耗。
因此,在许多情况下,我们比A12高出近1W。
在这里,在性能达到峰值时,功率增加似乎大于性能增加,这就是为什么在几乎所有工作负载中,A13的效率都低于A12的原因。
总体而言,就性能而言,A13和Lightning内核非常快。
在移动领域,实际上没有竞争,因为A13的性能几乎是次佳的非Apple SoC的两倍。
在浮点套件中,两者的差异要小一些,但同样,我们至少要再等待2-3年,才能期待任何适当的竞争,而且Apple也不会停滞不前。
去年,我注意到A12与最好的台式机CPU内核相比差强人意。
今年,A13至少在SPECint2006上与AMD和Intel所能提供的最佳匹配。
在SPECfp2006中,A13仍落后约15%。
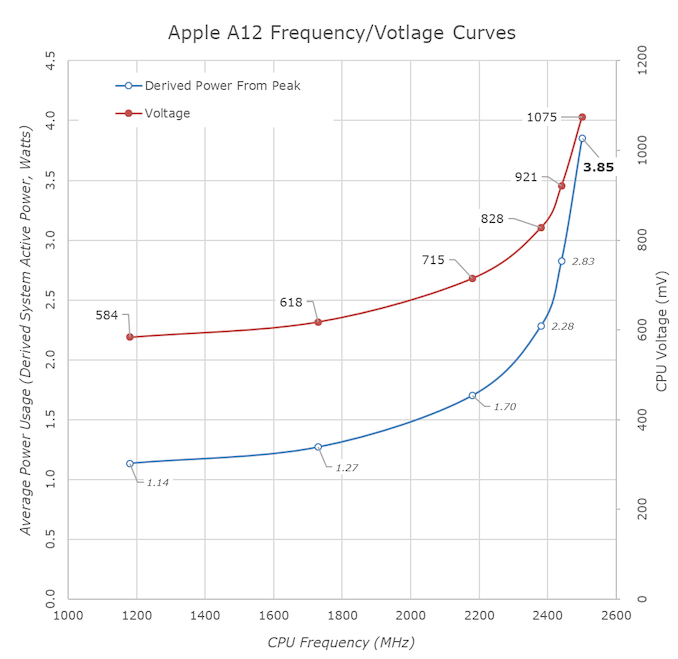
令人震惊的功率数字的一种可能解释是,对于A13,苹果公司在新的Lightning核心的峰值频率处处于频率/电压曲线的远端。
在上图中,我们估算了去年A12的功率曲线–在这里,我们可以看到Apple非常保守,其电压直到最后几百MHz。
对于A13而言,苹果在随后的频率状态下可能更激进。
关于这种假设的好消息是,平均而言,在日常工作量中,A13应该在效率更高的运行点上运行。
苹果公司的营销材料将A13的速度提高了20%,同时还指出其耗电量比A12少30%,不幸的是,这种说法具有欺骗性(或至少不清楚)。
尽管我们怀疑很多人会把它解释为意味着A13速度提高了20%,而同时使用的功率却减少了30%,但这实际上是其中之一。
实际上,这意味着在相当于A12峰值性能的性能点上,A13的能耗将减少30%。
考虑到苹果功率曲线的陡峭性,我可以轻易地想象出这是准确的。
系统和ML性能
在研究了新A13的CPU性能之后,是时候看看它在某些系统级测试中的性能了。
不幸的是,仍然缺少针对iOS的适当的系统测试,这尤其令人沮丧,尤其是涉及PCMark之类的测试时,它们可以更准确地表示应用程序用例。
取而代之的是,我们必须退回到基于浏览器的基准测试。
浏览器性能仍然是设备性能的一个重要方面,因为它仍然是主要工作负载之一,它在显示性能延迟(例如响应时间)等性能特征时,给CPU带来了很大压力。
与往常一样,以下基准测试不仅表示硬件功能,还表示手机的软件优化。
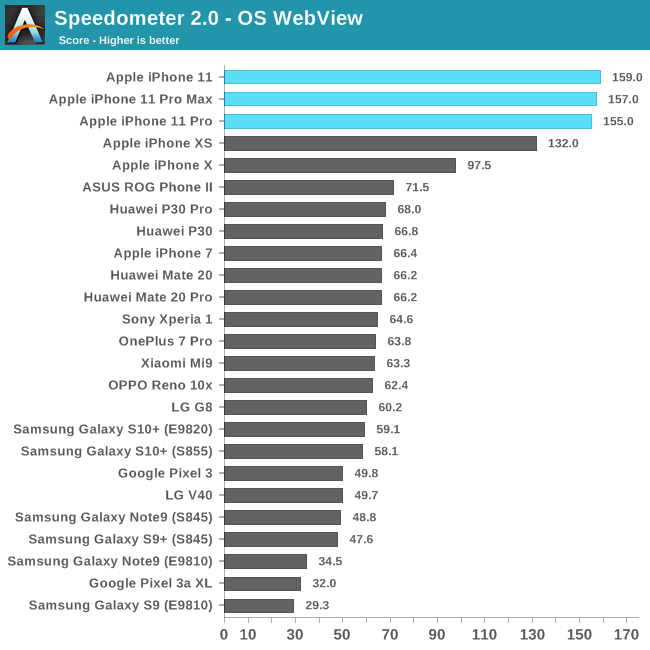
在我们的测试中,iOS13再次将基于浏览器的基准性能提高了约10%。
我们已经进行了更新,并以iOS13上的新分数更新了上一代iPhone的性能数据,以对新iPhone 11进行正确的Apple-Apple比较。
在Speedometer 2.0中,我们看到新的基于A13的手机与上一代iPhone XS和A12相比,性能提高了19-20%。
这一增长与苹果的性能要求保持一致。
今年的增长比我们去年使用A12看到的要小,因为去年得分的主要提升似乎是升级到128KB L1I缓存。
与A12相比,A13在达到大型Lightning内核的最大时钟速度所需的时间方面并没有太大变化,而CPU内核在超过100ms的时间内达到了峰值。
真正改变的是工作负载驻留在较小的Thunder效率内核上的时间。
在A13上,小核心的爬坡速度比在A12上要快得多。
调度程序行为以及工作负载从小型内核迁移到大型内核时,也都发生了重大变化。
现在,在A13上,这种情况大约在30毫秒后发生,而在A12上,这可能需要54毫秒。
由于小型内核不再能够独自请求更高的内存控制器性能状态,因此在工作负载要求更高的情况下,现在应该尽快迁移到大型内核。
A13的Lightning内核以910MHz左右的基本频率启动,这比A12及其1180MHz的基本频率低了一点。
这意味着Apple已将A13中大型内核的动态范围扩展到了更高的性能以及更低,更有效的频率。
机器学习推理性能
苹果还声称已经提高了A13中神经处理器IP模块的性能。
要使用此单元,您必须使用CoreML框架。
不幸的是,到目前为止,我们还没有一个自定义工具来测试它,因此我们不得不依靠一种罕见的外部应用程序为它提供基准,那就是鲁大师的AIMark。
像网络浏览器的工作负载一样,iOS13也为过去的设备带来了性能改进,因此我们重新运行了iPhone X和XS评分,以便与新iPhone 11进行适当比较。
iPhone 11和新款A13的改进取决于型号和工作负载。
对于InceptionV3和ResNet34等经典模型,我们发现推理率提高了23-29%。
MobileNet-SSD的增长幅度有限,仅为17%,而DeepLabV3的增长幅度则为48%。
通常,运行机器学习基准测试的问题是它贯穿抽象层(在本例中为CoreML)运行。
我们无法保证NPU与CPU和GPU上实际运行了多少模型,因为根据设备的ML驱动程序,它们之间可能会有很大差异。
不过,这里的A13和iPhone 11很有竞争力,并且为这一代人提供了良好的迭代性能。
总体而言,iPhone 11s的性能非常出色,因为我们已经一次又一次地期望苹果公司。
话虽如此,我不能说我在日常使用中与iPhone XS的区别太大。
因此,尽管A13提供了一流的性能,但对于来自去年A12设备的用户而言,它可能不会非常引人注目。
老式设备将带来更大的影响。
否则,凭借如此强大的功能,我觉得用户体验将从加速应用程序和系统动画的选项中受益匪浅,或者甚至完全关闭它们以真正感受到硬件的顺畅性。
GPU性能和功耗
我们详细介绍了A13的CPU,GPU也是不可忽视的一部分。
苹果今年在对这个单元的性能表现更为保守,该公司承诺,在与A12相同的性能下,GPU性能提高20%或功率降低40%。
除了芯片组和GPU的原始性能外,游戏的重要意义在于实际设备的热特性以及如何消散和维持SoC的高热量。
对于A12,我确实批评苹果,因为它在允许手机开始使用3D工作负载的峰值功率方面表现得非常激进。
这导致电话在降低速度之前并不能真正保持这些性能水平超过2-3分钟。
今年,苹果公司已经宣布,他们已经提高了设备的SoC冷却能力,能够更好地将热量从SoC散布到手机主体,从而使芯片保持更高的性能状态。
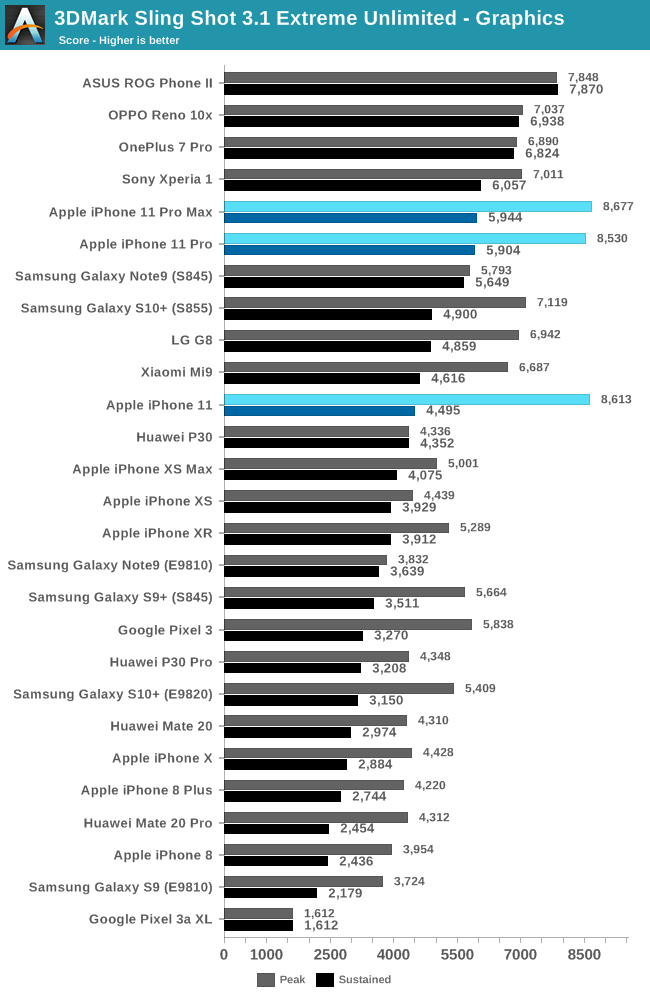
从3DMark中的物理测试开始,实际上,在GPU工作负载期间受功率限制时,这实际上更多地是CPU工作负载。
在这种情况下,与去年的iPhone相比,iPhone 11在峰值性能方面的表现要好一些,但是它们并不能完全保持与A12 iPhone相同的持续性能。
切换到对GPU施加最大压力的图形工作负载,我们现在在这里看到分数和排名的重大变化。
首先,与去年的A12设备相比,新的iPhone 11s和A13现在显示出显着的性能提升。
我注意到,当我们分析该芯片时,苹果在3DMark方面表现异常差强人意,并且看来苹果能够解决这一代的任何瓶颈,性能提高了38%。
实际上,我已经回过头来,迅速对iOS13上的iPhone XS进行了测试,与我们在此图中看到的相比,确实看到了20%的性能提升。
新的iPhone得分不及某些Snapdragon 855(+)设备,但这是因为Apple不允许iPhone的发热量几乎与其他某些设备一样高。
我无法在任何新iPhone上测量高于41°C的场景。
通过测量功耗,我们再次看到A13设备的峰值功率极激进,超过6.2W。
有趣的是,即使在这种耗电的峰值性能状态下,A13的效率也比A12高,并且比竞争对手的效率高得多。
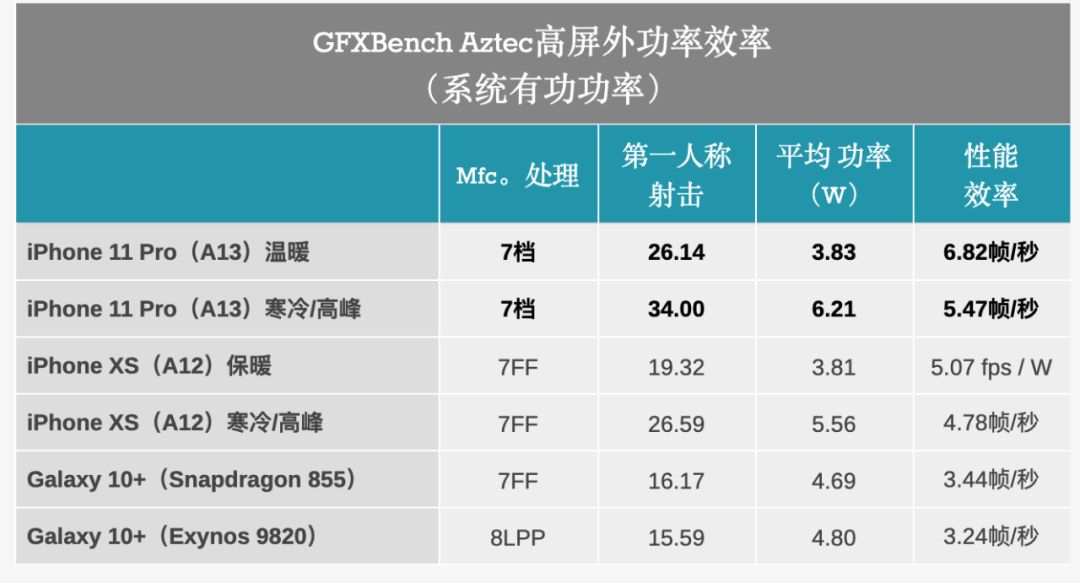
通过一系列的测试,anandteh指出,去年,A13的GPU性能是同类产品中最佳。
他们表示,去年A12在GPU方面进行了令人印象深刻的改进,这是苹果第一次在性能和效率方面能够非常明显地领先于高通。
首先,A13的峰值性能确实提高了约20%。
但是,这不是人们应该最关注的指标。
与去年的iPhone相比,苹果的持续性能得分提高更为显着,达到50%至60%。
看起来,苹果声称改善了SoC散热性能的说法非常好。
最重要的是,苹果在A13上的新型GPU微体系结构令人印象深刻。
鉴于流程节点的发展微不足道,我没想到该公司能够推动如此大的性能和功率效率提升。
我们需要从竞争对手中看到一些重大的模式转变,以使它们能够赶上下一代设备。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2100期内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
AI|
射频
|
EDA|晶圆|CMOS
|DRAM
|
集成电路
|
英特尔
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!