
[原创] 被三星抛弃的自研CPU核:M5表现究竟如何?


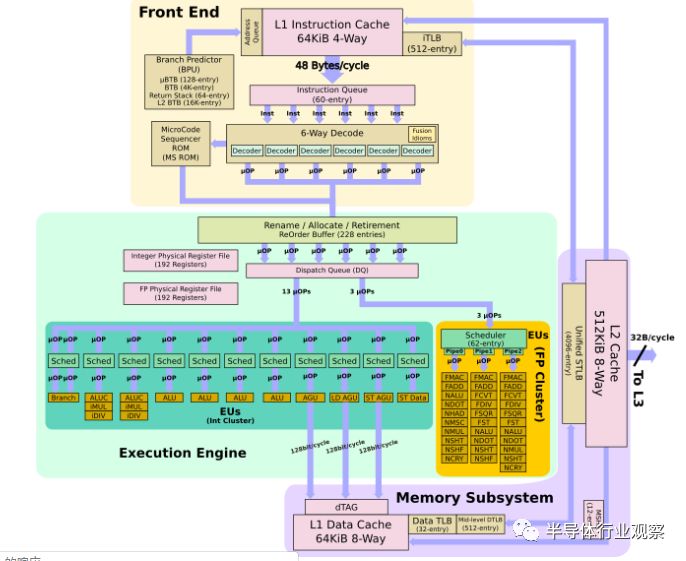
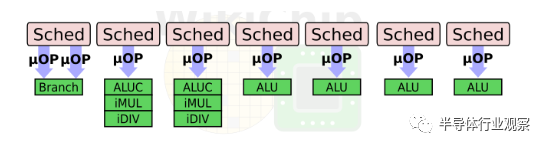
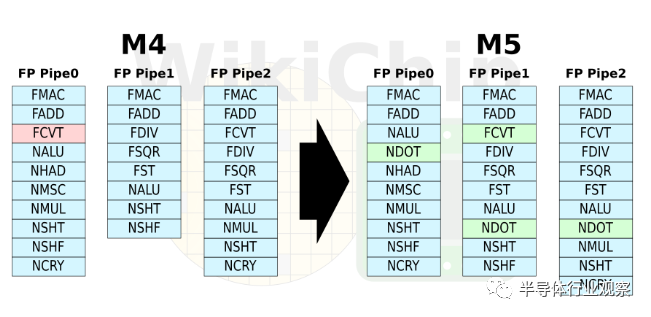
*点击文末阅读原文,可阅读 英文 原文。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2136期内容,欢迎关注。
推荐阅读
半导体行业观察

『 半导体第一垂直媒体 』
实时 专业 原创 深度
识别二维码 ,回复下方关键词,阅读更多
FPGA |苹果 |台积电 |射频 | ASML | 集成电路 | 存储|晶圆
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复 搜索 ,还能轻松找到其他你感兴趣的文章!
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 上海泰矽微宣布完成新一轮战略融资,博奥集团战略入股
- 2 三方联合,上海国际汽车电子与半导体应用展览会将于明年4月在上海举办
- 3 6月5-7日,南京见!2024南京国际半导体博览会邀您共赴盛会
- 4 电源管理芯片市场的一匹黑马
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号