来源:内容由半导体行业观察(ID:icbank)编译自「
wikichip
」,作者:Bryon
David Schor
,谢谢。
每年,数百家世界领先的供应商,大学和研究机构齐聚一堂,参加年度超级计算大会。
多年来,我们也已经习惯了对所有展位进行详尽的访问,尤其是不知名的小展位。
今年,在展示厅较偏僻的角落之一的特别小的摊位上漫步时,我们遇到了Preferred Networks(PFN)摊位。
在仅几平方英尺的展位中,我们发现了整个会议中最有趣的海报之一– PFN定制MN-Core AI训练芯片的详细信息。
这家总部位于日本东京的初创公司成立于2014年,已筹集了约1.3亿美元,其中包括来自Toyota的 9,660万美元。
该公司主要致力于利用深度学习技术为边缘和物联网提供大量计算。
在展位上,我们会见了东京大学名誉教授平崎启(Kei Hiraki)。
Hiraki教授一直参与PFN的MN-Core的开发。
Hiraki解释说,PFN已经开发了一系列私有超级计算机,以加速其自己的应用程序的研发,这些应用程序使用大量的计算能力来进行深度学习。
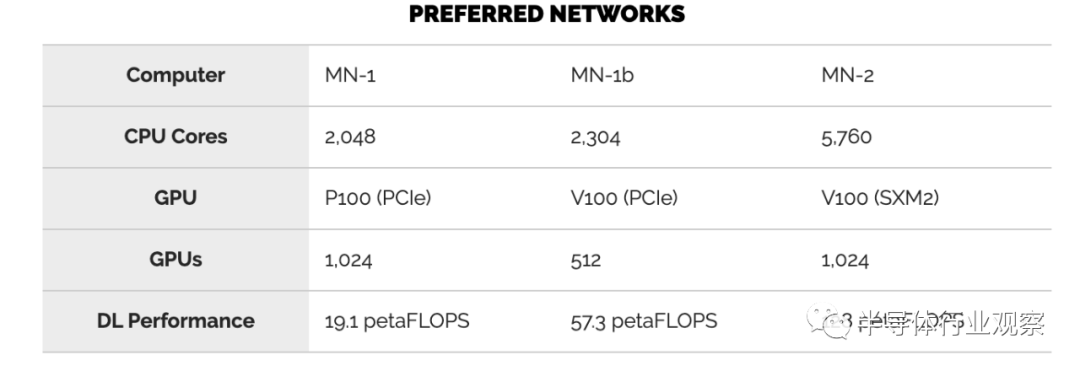
该公司于2017年推出了首个AI超级计算机MN-1。
该系统具有1,024个Nvidia Tesla P100 GPU,可从GPU上获得1.39 petaFLOPS和9.3 petaFLOPS的峰值计算量。
当时,MN-1在工业超级计算机的TOP500上在日本排名第一,在世界排名第十二。
在2018年7月,PFN通过添加512个额外的Tesla V100 GPU增强了MN-1。
较新的系统MN-1b将深度学习(张量)的计算能力提高到56 petaFLOPS。
今年早些时候,PFN推出了迄今为止最大的超级计算机MN-2。
该系统于2019年7月投入运行,该系统使V100 GPU的数量增加了一倍,并从PCIe卡切换为SXM2模块。
 PFN MN-2超级计算机
PFN MN-2超级计算机
PFN下一代超级计算机更加有趣。
Hiraki教授解释说,PFN决定开发自己的专有深度学习加速器,以实现更高的性能,更重要的是实现更高的电源效率。
他们设计的是500瓦芯片,Hiraki表示这是在可能的冷却极限内进行的。
该芯片本身在一个多芯片封装中包含四个die。
芯片是公司自己的设计,然后用台积电12纳米工艺制造的。
在上面的芯片照片中,在芯片上刻有单词“ GRAPE-PFN2”。
尽管尚不清楚雕刻的原因,但似乎有些体系结构源自GRAPE-DR。
还需要指出的是,Preferred Networks团队的成员以前曾在GRAPE-DR物理协处理器上工作,包括Hiraki教授。
封装本身很大,尺寸为85毫米乘85毫米。
die也非常大,达到756.7mm²。
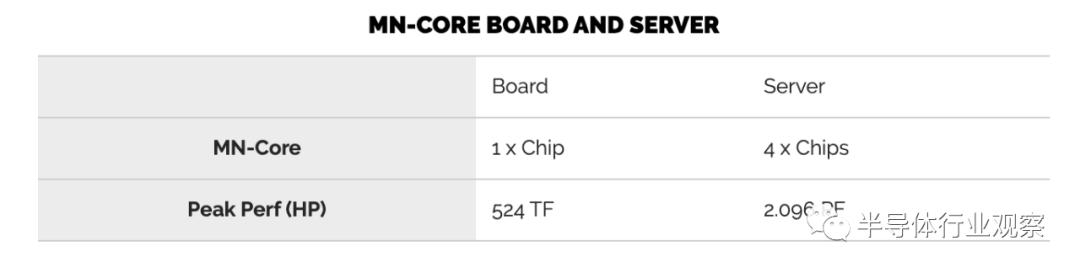
在500 W时,该芯片的计算性能为524 teraFLOPS(半精度)。
这为他们提供了1.05 TFLOPS / W的计算功率效率,这正是他们的目标。
该体系结构类似于GRAPE协处理器的体系结构。
尽管对各个块进行了调整以进行训练,但各个块的名称甚至都相似,并且总体操作非常相似。
有DRAM I / F,PICe I / F和四个2级广播块(L2B)。
每个L2B中有八个L1B和一个块存储器。
level-1 block包括16个矩阵算术块(MAB)以及其自己的块存储器。
矩阵算术单元和四个处理元件(PE)组成一个MAB。
每个die总共有512个MAB。
各个处理元件将数据传递给MAU。
这些PE包含一个ALU并实现了PFN专门使用的许多自定义DL功能,因此它比大多数其他NPU更专业。
基本数据类型操作是16位浮点数。
通过组合多个PE可以支持更高精度的操作。
芯片本身位于MN-Core板上,后者是一种基于PCIe的定制加速器板PFN设计。
Hiraki教授表示,功耗为500瓦,电压为0.55 V,那就意味着几乎有1,000 A电流流经电路板,这就给封装对设计构成了重大挑战。
该板本身是x16 PCIe Gen 3.0卡,其中集成了MN-Core芯片,32 GiB内存以及定制设计的散热器和风扇。
PFN估计该卡的功耗约为600瓦。
在MN-Core服务器(一个7U机架式机箱)上安装了四个MN-Core板。
每个服务器中都有一个双插槽CPU。
四个板使它们每秒可以达到2 petaFLOPS的半精度浮点运算。
PFN计划在每个机架上堆叠其中四台服务器。
首选网络的下一代超级计算机MN-3将基于MN-Core。
PFN和其他公司一样,也没有出售这种芯片的计划。
他们公开谈论此问题的决定意味着我们对通常看不到的半导体行业有独特的了解。
PFN MN-Core芯片和超级计算机将专门用于其自己的研发。
PFN预计MN-3拥有约300个机架,可用于4800个MN-Core板。
这相当于每秒2 exaFLOPS的半精度浮点运算。
在功率方面,我们估计该机器的功率为3.36 MW,对于这种性能而言这是非常低的。
例如,13兆瓦的峰会达到了1.88 exaOPS。
MN-3计划于2020年投入运营。
我们已经看到Google和Amazon等超大规模开发者为自己的云服务器开发了自定义神经处理器。
类似的趋势也正在行业中出现,诸如Preferred Networks之类的公司设计了自己的NPU。
共同的主题保持不变——能够开发自己的硬件的公司正在设计自己的芯片,以便拥有独特的,与众不同的技术优势。
目前,只有少数几家AI硬件初创公司在交付推理芯片,而没有一家初创公司在交付训练芯片。
缺少商品专业训练芯片,可以超越当前顶级训练GPU的性能和能效,为公司带来独特的机会。
随着更多的商品训练芯片开始进入市场,情况可能会发生变化。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2139期内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
ICCAD
|AI|台积电
|封测
|
ASML
|华为|
EDA|晶圆
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!