一窥Habana的推理和训练神经处理器
2019-12-16
14:00:12
来源: 半导体行业观察
来源:内容由半导体行业观察(icbank)编译自「
wikichip
」,作者:David Schor,谢谢
。
Habana Labs是市面上为数不多的,有产品出货的独立AI初创公司之一。
这家以色列初创公司成立于2016年,已获得7500万美元的A和B轮融资。
Habana Labs主要专注于数据中心,边缘和工作站市场。
在不到三年的时间里,该公司已经将产品交付市场,并进行了第二代产品送样以及下一代产品的预研。
Habana的分叉产品线采用了两种独立的芯片设计–一种用于推理,另一种用于训练。
我们已经看到英特尔Nervana NNP等其他公司使用了这种方法。
这使他们可以针对每种工作负载类型更好地进行优化。
但是,Habana则宣称,他们依靠相同的基础架构进行训练和推理,但是针对稍有不同的工作负载优化了这两种设计。
但如英特尔等其他公司都依靠两种截然不同的芯片设计。
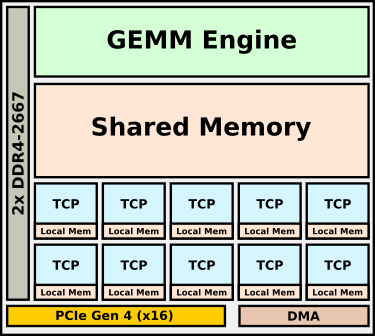
Goya是Habana的微体系结构,用于加速推理。
Goya采用台积电(TSMC)16纳米工艺制造,而这个产品实际上是Gaudi的简化版本。
芯片的两个主要组件是TPC(Tensor Processor Core:
张量处理器内核)和GEMM(通用矩阵乘法:
general matrix multiply)引擎。
TPC是该公司基于VLIW SIMD的CPU / DSP设计。
这些内核基于自定义的VLIW ISA,该功能具有专门的AI SIMD矢量指令。
Habana试水TPC的目的之一就是提高灵活性。
这些内核是完全C可编程的,它们可以实现任何必要的AI功能,并且支持包括8位,16位和32位整数和浮点运算在内的整个混合精度数据类型。
使用Habana的软件堆栈,提供粗粒度(coarse-grained)和细粒度(fine-grained)控制旋钮(control knobs),以将硬件的精度控制到张量级别。
这对于某些您希望降低性能但又会获得更好的精度的领域非常重要(This is important for certain fields where you’d rather take a small performance hit but get slightly better accuracy)。
完整的Goya芯片具有一个集群中的八个TPC。
该芯片与TPC集群一起集成了强大的GEMM(通用矩阵乘法)引擎。
芯片的另一个有趣方面是TPC没有本地缓存。
相反,它们具有本地暂存器块以及GEMM引擎和TPC共享的大型共享内存。
缓存可以由软件管理,以便针对较低的数据移动进行优化。
这使他们能够更轻松地从大型缓存池中传输数据,并改善TPC的确定性。
Habana表示,大多数模型应适合高速缓存并完全包含在芯片上。
对于更大的内存池,为芯片提供两个通道的DDR4内存,总容量为16 GiB。
Goya推理芯片HL-1000被封装在PCIe Gen 4加速卡中。
提供了两个SKU、所提供的冷却类型有被动和主动、卡存储容量之间的差异在4到16 GiB之间。
Habana说,卡的最大TDP为200 W,但我们可以预期典型功耗通常仅为该值的一半。
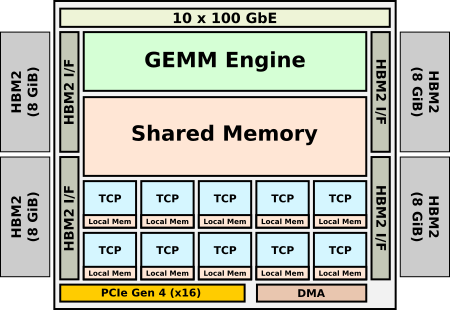
Gaudi是Habana用于加速训练的微体系结构。
与Goya一样,它也是用TSMC 16纳米工艺设计,并具有非常相似的架构。
该芯片将八个TCP与GEMM引擎集成在一个集群中。
由于Gaudi是根据Goya设计的,因此Habana确实设法植入了一些新功能。
就支持的数据类型而言,随着行业将bfloat16作为训练的首选数据类型,Habana在Gaudi中增加了对其的支持。
Habana说,在TPC和GEMM引擎中,它添加了ISA的一些新功能和硬件功能,以帮助加速某些较新的算法。
但是,存在许多关键差异。
高迪旨在允许大规模训练。
Habana说,在设计芯片时,关键的要求之一就是在小batch size时实现高吞吐量。
另一个要求是使用标准以太网作为通信介质。
这与专有接口(例如英特尔的ICL链接或用于其NPU和GPU的Nvidia Nvlink)完全不同。
Habana希望为客户提供使用现有硬件的自由,并利用标准以太网交换机进行扩展,而不是将其引入并锁定在其他专有接口中。
为此,Gaudi集成了10个100 Gb以太网端口以及RoCE RDMA。
此外,由于训练需要更高的带宽和更大的存储容量。
因此这个双通东的DDR4接口被四个HBM2代替,且拥有32 GiB的内存。
Habana提供两种尺寸的HL-2000 Gaudi芯片:
OCP加速器模块和标准PCIe卡。
两种尺寸都包含32 GiB的HBM2存储器,总带宽为1 TB / s。
与Goya一样,PCIe卡也有许多散热选项。
Habana还提供了一个参考平台,以允许不想打扰自己盒子设计的客户使用。
HL-1包含八张Gaudi HL-205 OAM卡。
HLS-1的独特之处在于他们没有CPU。
Habana安装了八块高Gaudi芯片,并将它们互连在一起,然后简单地将连接性暴露给外界。
公开了4个PCIe端口和6个QSFP-DD端口。
客户可以自由选择最适合其工作负载的CPU类型和比率,并使用四个Mini-SAS HD端口进行连接。
Goya HL-1000推理芯片已经交付了将近一年。
目前,Gaudi HL-2000训练芯片正在提供样品。
Habana已经在着手开发其下一代推理和训练芯片,该芯片将转移到7纳米工艺进行。
*点击文末阅读原文,可阅读
英文
原文。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2160期内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|AI
|台积电
|封测
|
亚马逊
|
RISC-V|思科|存储
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!
责任编辑:Sophie