随
着人工智能的落地和大规模应用,AI芯片也成为了常见的芯片品类。
AI芯片相比传统芯片来说,主要的竞争优势就在于高算力和高能效比。
高算力是指能够比传统芯片更快地完成AI计算,而高能效比则是指能比传统芯片用更少的能量完成计算。
在AI芯片诞生的初期,AI芯片架构主要是针对计算并行性做优化,从而加强计算能力。然而,随着AI芯片竞争日益激烈,从并行性方面的潜力也已经被挖掘殆尽,这时候AI芯片的性能就遇到了“内存墙”这一瓶颈。
要理解内存墙,还需要从传统的冯诺伊曼架构说起。冯诺伊曼架构是计算机的经典体系结构,同时也是之前处理器芯片的主流架构。在冯诺伊曼架构中,计算与内存是分离的单元:计算单元根据从内存中读取数据,计算完成后存回内存。
冯诺伊曼架构在构建之初的假设就是处理器和内存的速度很接近。然而,随着摩尔定律的演进,这一假设早已不再成立。计算单元的性能随着摩尔定律高速发展,其性能随着晶体管特征尺寸的缩小而直接提升;另一方面,内存主要使用的是DRAM方案,而DRAM从摩尔定律晶体管尺寸缩小所获得的益处并不大。这也造成了DRAM的性能提升速度远远慢于处理器速度,目前DRAM的性能已经成为了整体计算机性能的一个重要瓶颈,即所谓阻碍性能提升的“内存墙”。
内存墙对于处理器的限制是多方面的,不仅仅是限制了其计算性能,同时也是能效比的瓶颈 。在AI芯片追求极致计算能效比的今天,内存墙对于AI芯片能效比的限制效应尤其显著。众所周知,人工智能中神经网络模型的一个重要特点就是计算量大,而且计算过程中涉及到的数据量也很大,使用传统冯诺伊曼架构会需要频繁读写内存。目前的DRAM一次读写32bit数据消耗的能量比起32bit数据计算消耗的能量要大两到三个数量级,因此成为了总体计算设备中的能效比瓶颈。如果想让人工智能应用也走入对于能效比有严格要求的移动端和嵌入式设备以实现“人工智能无处不在”,那么内存访问瓶颈就是一个不得不解决的问题。
内存墙之所以存在,从另一个角度看主要还是由于处理器/加速器芯片和主内存是两个独立的模块,或者换句话说,计算和内存之间距离太远,因此来回搬运数据代价太高,无论是吞吐量还是能效比方面这种数据搬运都成为了瓶颈。那么,如何让内存和计算离得更近一些呢?一个最简单有效的方法就是“存内计算”(in-memory computing)。
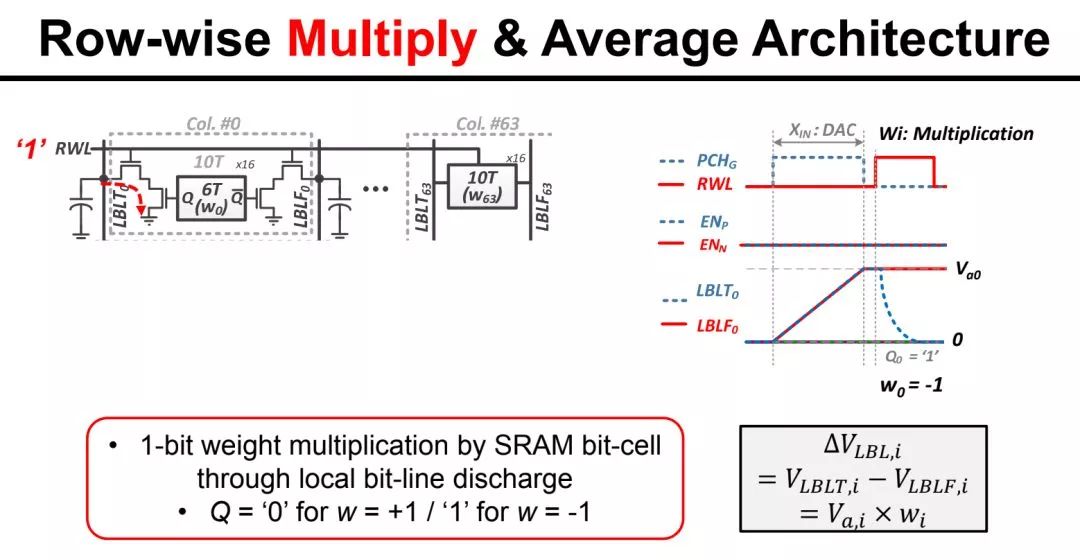
存内计算,顾名思义就是直接在存储内做计算。其具体实现方式有若干条技术路径。首先,最直接的就是在现有存储的基础上做一些电路上的改动。这类实现方法最简单,例如2018年MIT Chandrakasan研究组在ISSCC上发表的研究就是这类技术的例子。该研究中,存内计算的主要用途是加速卷积计算,而卷积计算从数学上可以展开成带权重的累加计算,或者说是多个数的加权平均。因此,存内计算的做法是把权重(1-bit)储存在SRAM中,输入数据经过DAC成为模拟信号,并根据SRAM中的对应权重相乘,然后在模拟域做平均,最后由ADC读出成为数字信号。这类存内计算往往只是修改现有存储的译码器/放大器模块,并不涉及存储器件的重新设计,优势是比较容易和现有工艺集成,但是缺点是能够带来的性能提升较为有限,尤其是基于SRAM的方案,一方面SRAM的集成度是有限的,另一方面单比特精度的权重也成为了其应用的限制。
另一种存内计算的技术路线是通过引入新的存储器件来完成存内计算。如果说前一种存内计算的概念是“在SoC里引入特殊的SRAM并在SRAM附近高效完成计算”,那么这一种存内计算就是直接“在存储阵列内完成计算”了。这种基于新存储器件的存内计算往往要利用新存储器件的一些特征,并且在一块特殊的存储阵列内集成计算功能,在要做计算的时候主处理模块只需要给存储阵列发送输入数据,过若干时钟周期之后存储阵列会把计算好的结果返回给主处理模块。与传统的冯诺伊曼架构相比,传统冯诺伊曼架构中处理器芯片给内存发请求,并读回数据;而在这类存内计算芯片的计算范式中,主处理模块给存储阵列发送请求和输入数据,而存储阵列则直接返回计算结果,这样就省去了计算过程中主处理器和内存之间的大量数据搬运。通常来说,存内计算在处理人工智能相关任务的时候,会把神经网络权重存储在阵列中,而主处理模块直接给存储阵列发去神经网络的输入即可开始计算。
近年来,存内计算已经逐渐成为业界和学界公认的趋势。拿半导体集成电路领域的“奥林匹克”——ISSCC为例,从2018年开始ISSCC开始设立与存内计算相关的专门session并收录五篇相关论文,此后存内计算在ISSCC上的相关论文录用势头一直不减,到2020年的ISSCC与存内计算相关的论文数量上升到了七篇。除此之外,半导体器件领域的顶级会议IEDM今年也给了存内计算足够重视,有三个专门的session共二十多篇相关论文。有趣的是,ISSCC和IEDM上相关存内计算的论文正好对应了前文所说的存内计算的两种技术路线——ISSCC对应从电路侧做技术革新,而IEDM则主要对应器件方向的技术更新换代,通过引入新的存储器件并基于其新特性来开发高性能的存内计算。其中,IEDM中显示的范式转换更引人关注。今年,IEDM的一大看点就是对于摩尔定律到头之后下一步方向的预测,有一个专门的panel session更是直接以“摩尔定律已死,但是AI永生”为名字,可见业界对于后摩尔定律时代的发展,最看好的是基于AI的新器件。而在AI相关的新器件/新范式中,存内计算可谓是最有希望的一种,由此可见今年IEDM的关于后摩尔定律的主题和录用数十篇存内计算相关的论文之间存在着紧密的联系。
目前,全球存内计算有不少玩家。例如,半导体巨头TSMC正在推广其基于ReRAM的存内计算方案,而IBM基于其独特的相变存储的存内计算也已经有了数年的历史。初创公司中,Mythic基于Flash的方案也获得了软银的首肯并获取了其资金支持。然而,传统存内计算有一个主要问题,就是计算精度和应用场景之间的矛盾。ReRAM通常只能做到2至3-bit,这即使对于终端用的神经网络来说也不太够。Mythic的产品针对服务器市场,然而服务器市场对于计算精度的要求却相比终端更高,这也成为了困扰存内计算的一个问题。
IEDM上的来自中国的论文可能成为解决存内计算瓶颈的关键
如上文所述,存内计算的一个关键瓶颈是精度和应用之间的矛盾。如果要解决这个矛盾,我们希望能有一款针对移动端的低功耗存内计算产品,且其计算精度能达到移动端神经网络的计算需求(>4bit)。
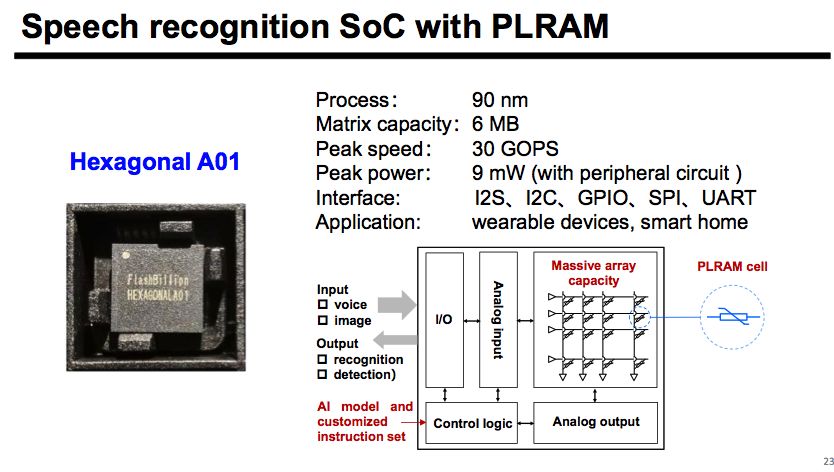
在今年的IEDM上,我们就看到了这样的技术突破。一家初创公司闪亿半导体,与浙江大学、北京大学、华虹宏力合作发表的论文《Programmable Linear RAM: A New Flash Memory-based Memristor for Artificial Synapses and Its Application to Speech Recognition System》恰恰解决了这个矛盾。该论文巧妙地利用晶体管在线性区的特性制备了新型存储器PLRAM,并成功地设计出了一款可以用在移动终端的超低功耗存内计算芯片,并实现了8-bit精度操作。
当计算精度高于4-bit时,我们认为就可以执行一些神经网络计算,而该论文中的8-bit精度更是可以保证大多数神经网络计算可以高精度完成,而不会损失性能。该论文把相关器件应用到了语音识别中并且完成了芯片流片和测试,测试结果显示该芯片可以以超低功耗(峰值9mW)执行语音识别相关的操作(MFCC特征提取和深度神经网络前馈运算),峰值算力可达30GOPS,足够IoT和可穿戴设备相关的应用。相比而言,Mythic等国外初创存内计算公司仅能实现低精度计算且难以克服成本的门槛(因此Mythic选择了对于成本不敏感的服务器市场),闪亿通过最新的器件技术突破实现的8-bit计算精度和较低的成本则是成功地撬动了体量更大的IoT市场。
除了器件上的突破之外,闪亿在电路以及更高的指令集领域都有深厚的技术积累。如前所述,存内计算是横跨器件和电路两个领域的技术,通常的存内计算与数字电路之间的接口需要大量数字-模拟转换和信号驱动,而这些接口事实上需要大量的电路优化工作,否则容易成为整体性能的瓶颈。为了解决这个效率瓶颈,闪亿开发了大规模阻性存储阵列驱动技术,能实现高效率的存内计算电路接口;同时,也为存内计算的规模化铺平了道路。在电路之上的架构层级,闪亿也有自己独特的指令集技术。事实上,编译器和指令集一直是困扰所有人工智能芯片设计的重要问题,AI芯片无法在实际应用中真正发挥全部算力的主要问题就在于指令集和编译器设计不过关,导致芯片只能在demo中有高算力,而到了用户提供的实际模型运行中就效率大幅下降。为此,闪亿开发了一套存内计算的专用指令集,可望解决这个困扰AI芯片行业的通病。
该研究让我们看到了中国半导体行业的崛起,因为在IEDM这样强手如林的顶尖半导体器件会议上发表文章本身就是对相关技术的肯定。更可喜的是,该研究已经在闪亿进行商业化,我们认为闪亿拥有的技术首先能克服存内计算的计算精度和应用场景之间的矛盾,可以把存内计算低功耗的优势发挥到极致,而同时其高精度计算又保证了可以兼容大多数神经网络。同时,闪亿选择的IoT和可穿戴式市场也是一个正在蓬勃发展的市场,这些市场非常适合用全球领先的新技术去撬动新的应用,从而让存内计算真正落地走向千家万户。我们希望能看到更多像闪亿这样的高精尖半导体技术商业化的案例,而当市场上出现众多这样的充满活力的高新技术半导体公司时,中国半导体的春天也就到了。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2167期内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|AI|台积电
|封测
|
亚马逊
|
RISC-V|思科|存储
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!
=