
台积电5nm SRAM技术细节
半导体技术的发展一直由应用领域推动,如图1所示,当下的在高性能计算(HPC),人工智能(AI)和5G通信,都要求在有限的功耗下实现最高性能。
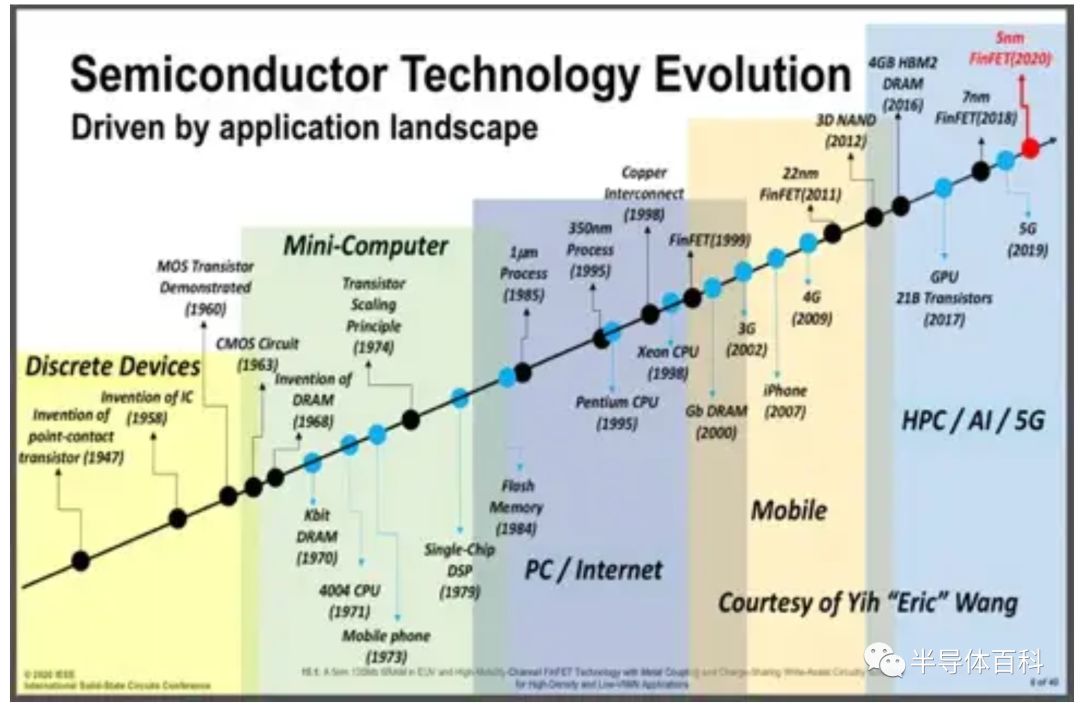
图1.半导体技术应用的演进。
台积电在IEDM 2019上发布了其5nm工艺,他们在5nm工艺中使用了十几张极紫外(EUV)掩模,每张EUV代替三个或多个浸没掩模以及采用高迁移率沟道(HMC)的以获得更高性能。其5nm工艺自2019年4月起投入风险量产,并于2020年第一季度实现全面量产。
Jonathan Chang等人在ISSCC 2020上展示了用于开发高性能SRAM单元和阵列的技术方案。
FinFET晶体管尺寸的量化一直是主要挑战,并迫使高密度6T SRAM单元中的所有晶体管仅能使用一个Fin。通过设计工艺协同优化(DTCO)对设计进行了优化,以提供高性能和高密度以及高产量和可靠性。图2展示了2011年至2019年的SRAM单元面积的微缩历程。
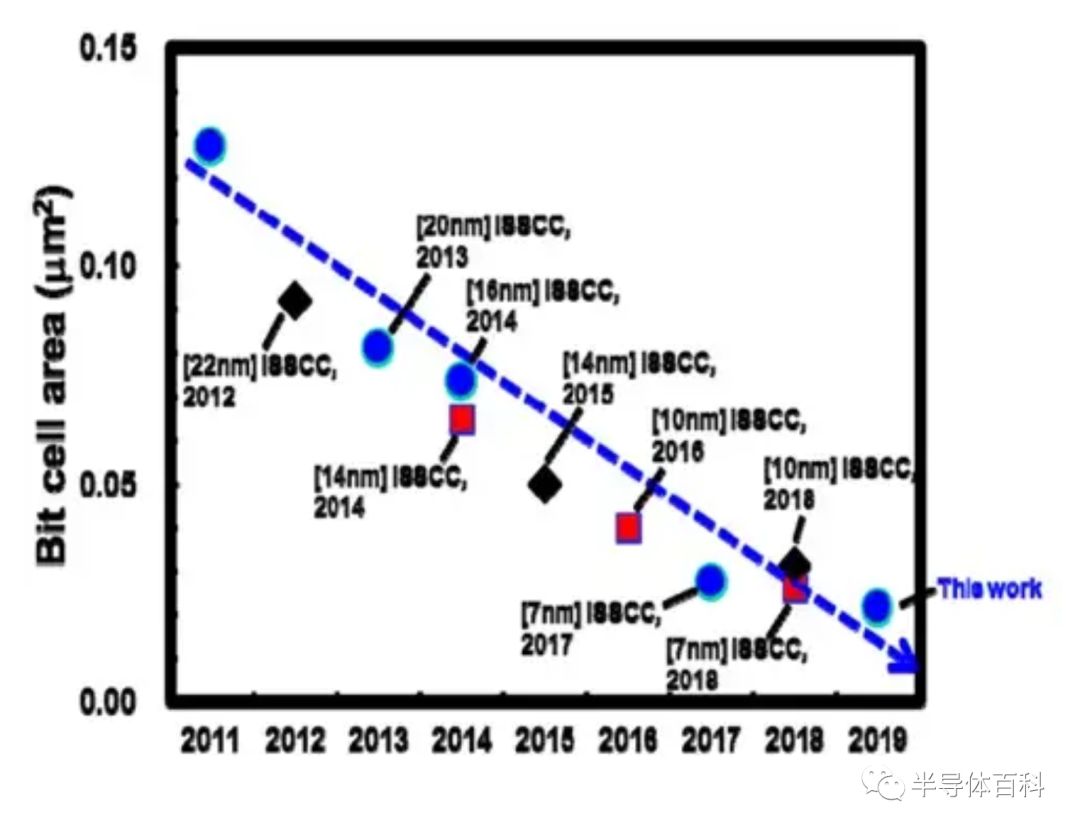
图2.展示了2011年至2019年的SRAM单元面积微缩历程。
但值得注意的是,2017年至2019年的SRAM单元面积缩小速度远慢于2011年至2017年的速度,这表明SRAM单元的微缩速度没有跟上逻辑区域的部分。在IEDM 2019上,5nm工艺的逻辑密度提高了1.84倍,而SRAM密度仅提高了1.35倍。台积电利用飞行位线(FBL,Flying Bit Line)架构进一步减少了面积,从而节省了5%的面积。5nm SRAM 单元的版图示意图如图3所示。
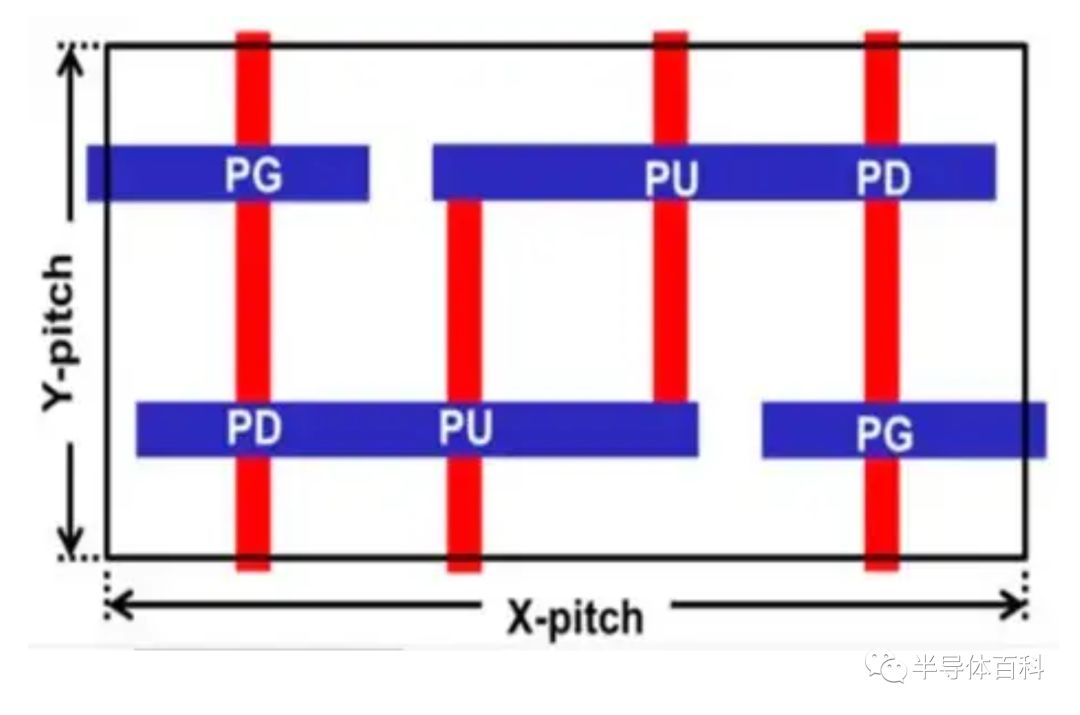
图3.高密度6T SRAM单元的版图。
为了降低功耗,一种关键方法是降低SRAM阵列的最小工作电压Vmin。5nm工艺中增加的随机阈值电压变化限制了Vmin,进而限制了功耗的降低。SRAM电压减小趋势如图4所示,其中蓝线表示没有写辅助的Vmin,红线表示有写辅助的Vmin,显示了每一代写辅助的巨大好处。可以看出,从7nm到5nm的Vmin几乎没有改善,表明必须通过改善写入辅助电路来进一步降低功耗。本文主要介绍两种写辅助方,以实现较低的Vmin工作电压:负位线(NBL,Negative Bit Line)和降低单元VDD(LCV,Lower Cell VDD)。
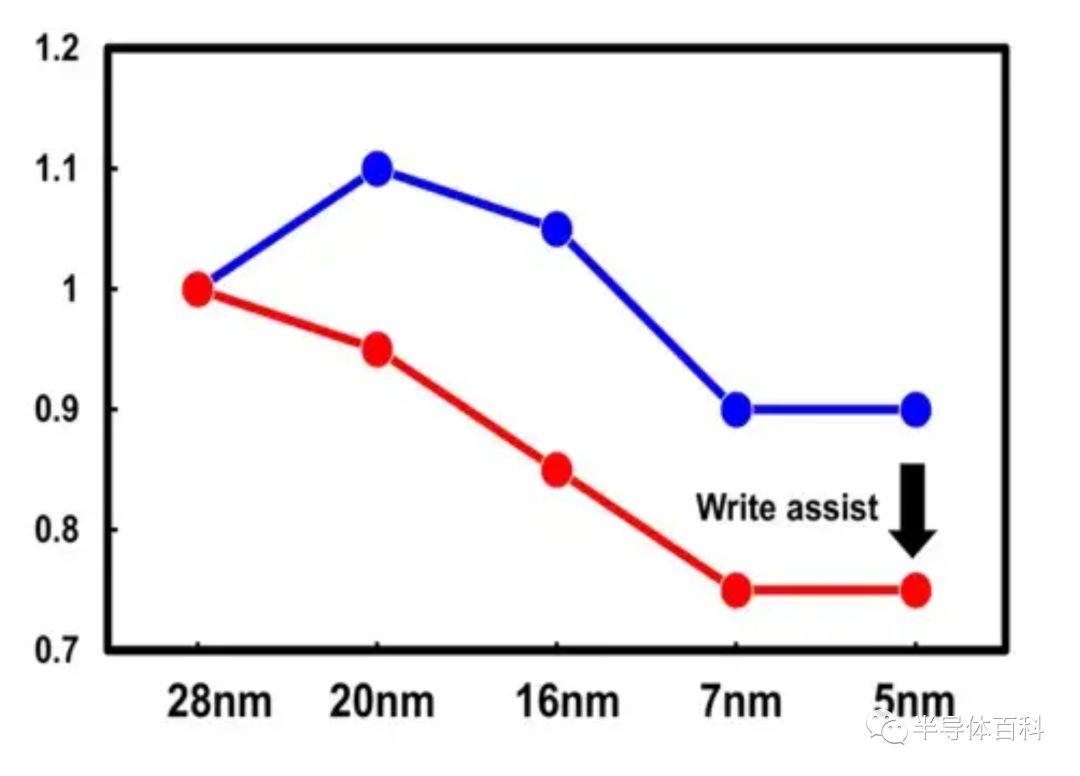
图4.没有写辅助(蓝线)和有写辅助(红线)的SRAM工作电压随节点变化图。
SRAM单元示意图如图5所示,显示了PU与传输门晶体管PG之间在写入操作期间的竞争。采用较强的PU晶体管可以获得较高的读取稳定性,但会显着降低写入容限,并导致写入Vmin问题。
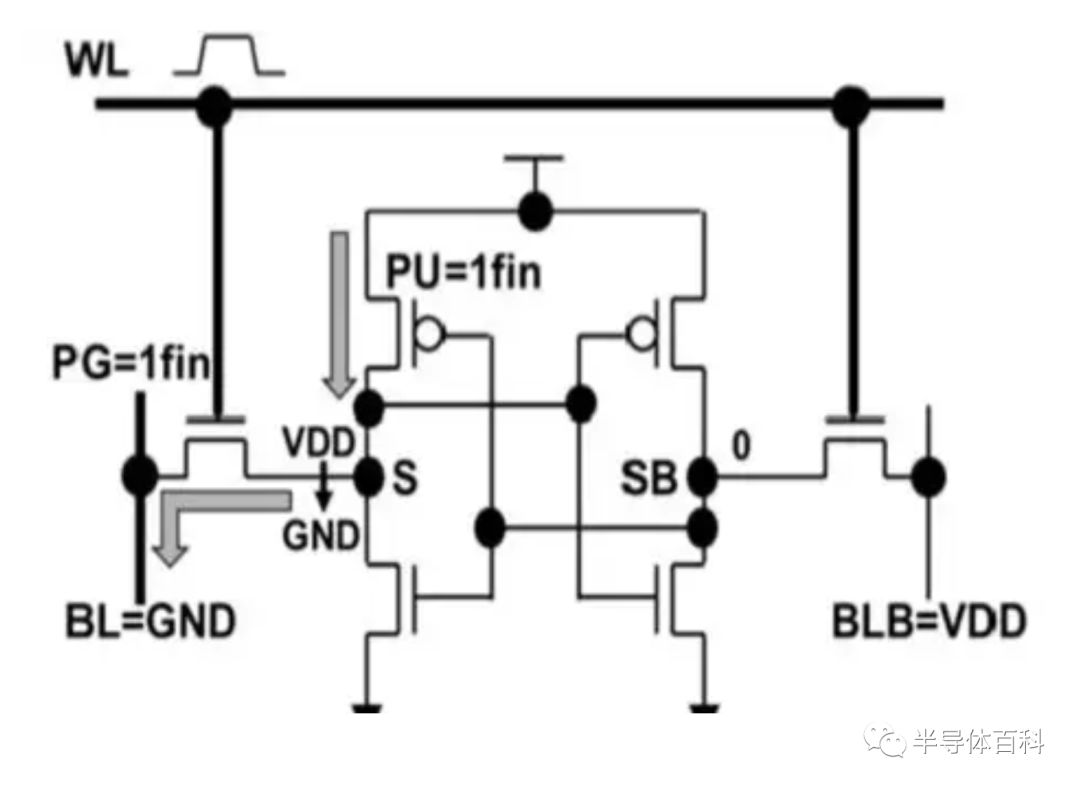
图5. SRAM单元示意图,显示了PU和PG 之间在写入过程中的竞争。
改善写入Vmin的第一种方法是降低写入期间的位线电压,称为负位线电压(NBL)。这种方法业界已经使用了几年,使用MOS电容器在位线上产生负偏置信号,但是这种写辅助电路会导致芯片面积增大。此外,固定数量的MOS电容会在短BL配置中引起过高的NBL电平,并可能导致短位线上的动态功耗过大,如图6所示。

图6.固定数量的MOS电容会在短BL配置中引起过高的NBL电平,并可能导致过高的动态功耗,金属电容器NBL可以避免该问题。
通过基于SRAM阵列上方金属线的耦合金属电容器方案,可以避免过压和MOS电容器面积问题。为避免补偿过量,可以使用SRAM阵列位线长度来调节金属电容器的长度,从而节省动态功耗。此外,还可以调节NBL电平,以补偿远侧存储单元上的由于字线IR下降引起的写入能力的损失。
图7中的NBL使能信号(NBLEN)驱动金属电容器C1的一侧为负,该电容在虚拟电容C1处耦合一个负偏置信号。然后接地节点NVSS,通过写驱动器WD和列多路复用器连到选定的位线。
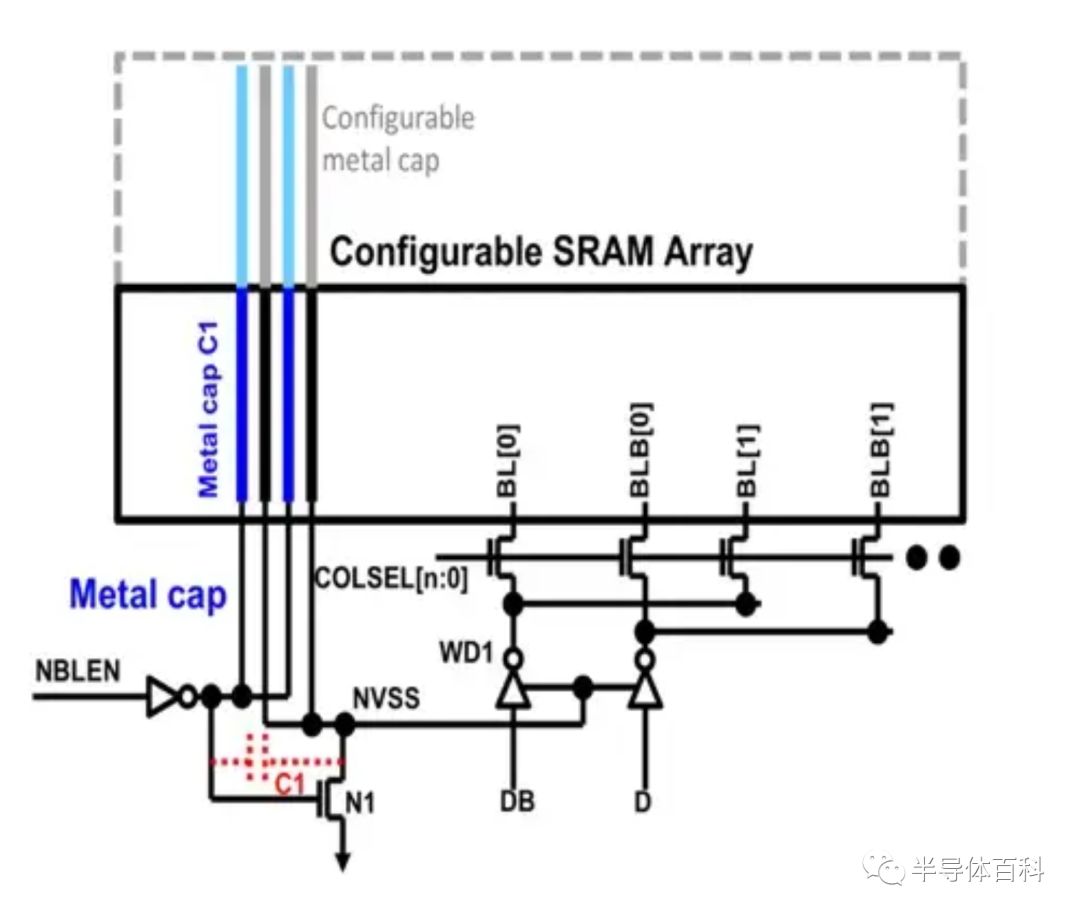
图7. NBLEN将可配置的金属电容器C1 耦合到NVSS。
图8显示了具有不同位线配置的NBL耦合电平,表明可配置金属电容器C1可以随位线长度调节,从而可以减轻具有不同位线长度的耦合NBL电平的变化。
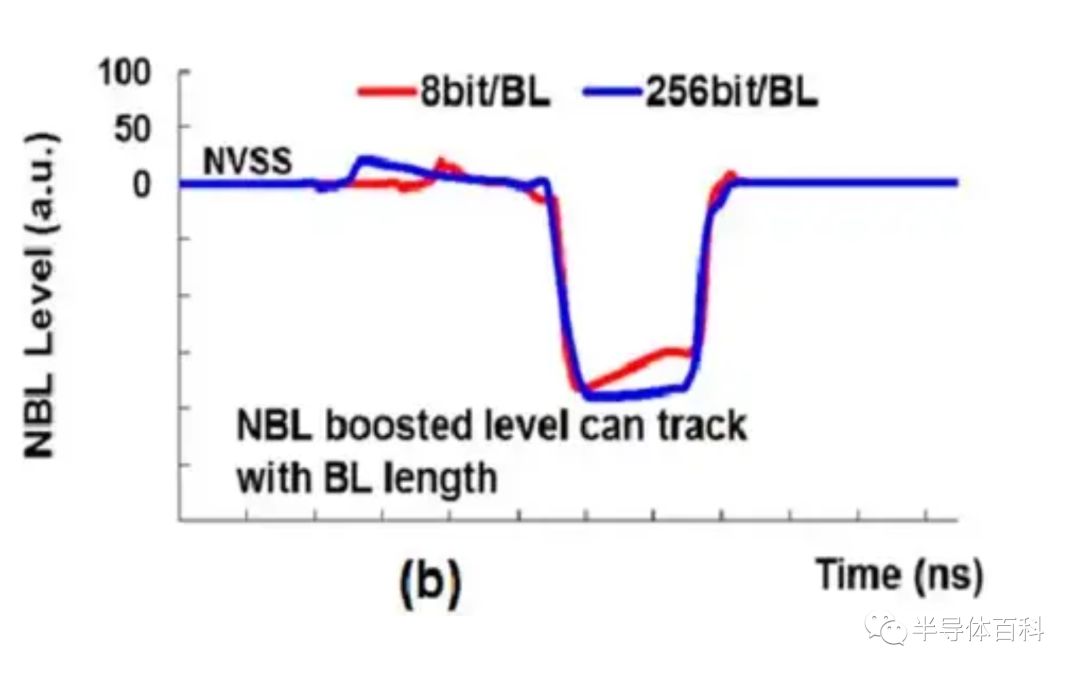
图8.具有不同位线配置的NBL耦合电平。
写入辅助的第二种方法是降低单元VDD(LCV)。LCV的常规技术需要强偏置或有源分压器才能在写操作期间调整列式存储单元的电源电压,但是这些技术在整个工作时间内会消耗大量的有功功率。脉冲下拉(PP,Pluse Pull-down)和电荷共享(CS,Charge Sharing)技术是两种替代解决方案,但PP难以精确计时。因此,如图9所示,台积电提出了使用阵列顶部的金属线作为电荷共享电容器来实现CS方案。
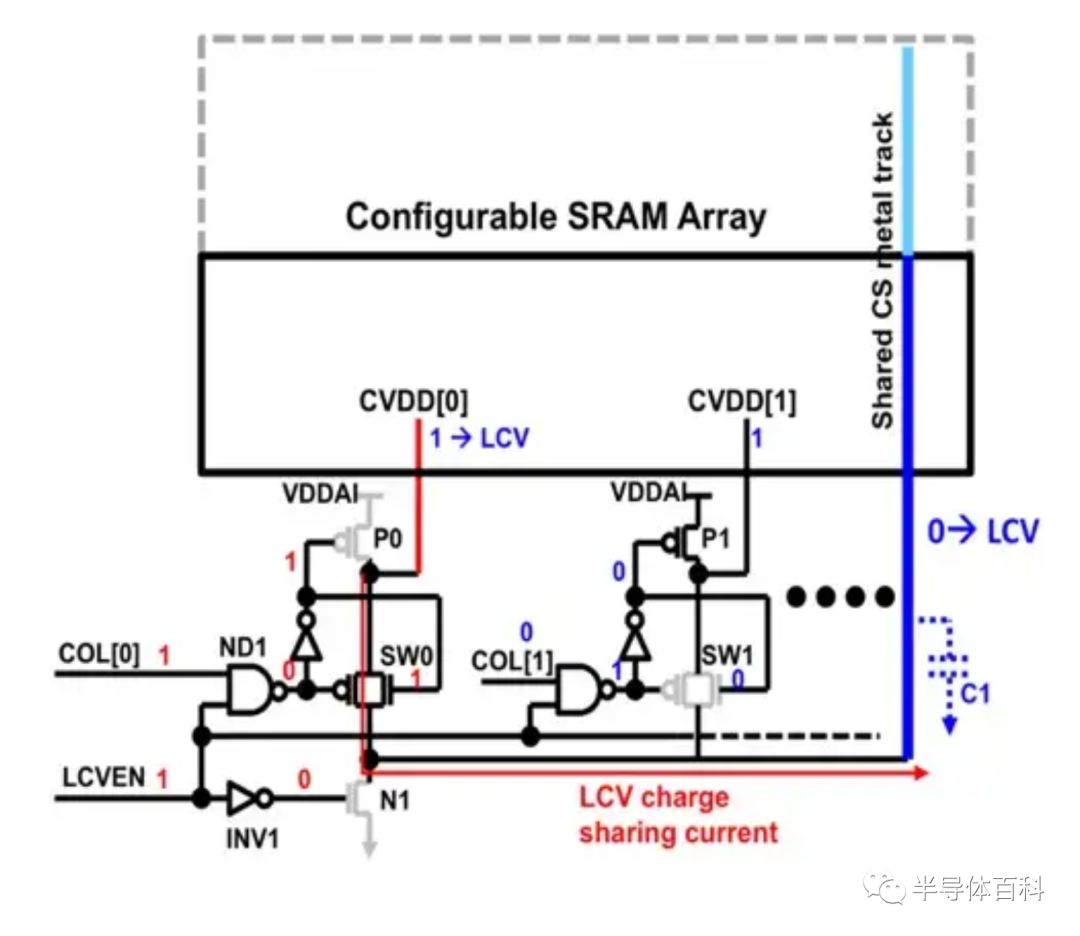
图9.使用SRAM阵列顶部的CS金属走线实现LCV的电荷共享,以实现写辅助。
在写操作中,LCV使能信号(LCVEN)变为高电平,它关闭下拉NMOS(N1),以将电荷共享电容器C1与地断开。COL [n:0]选择一列以关闭P0,并将阵列虚拟电源轨CVDD [0]与真实电源VDDAI断开。由于金属线电容随存储单元阵列的缩小而缩小,因此它也有利于SRAM编译器设计,并在变化的BL配置下提供了相对恒定的电荷共享电压电平。电荷共享水平由CVDD的金属电容比和电荷共享金属走线决定。图10显示了三个LCV-VDD比率分别为6%,12%和24%。

图10.三种LCV-VDD比率分别为6%,12%和24%。
关闭写辅助功能后,Vmin会受到写失败的限制。
图11中使用Write Assist的测量结果显示NBL将Vmin提高了300mV,而24% LCV则将Vmin提高了300mV以上。
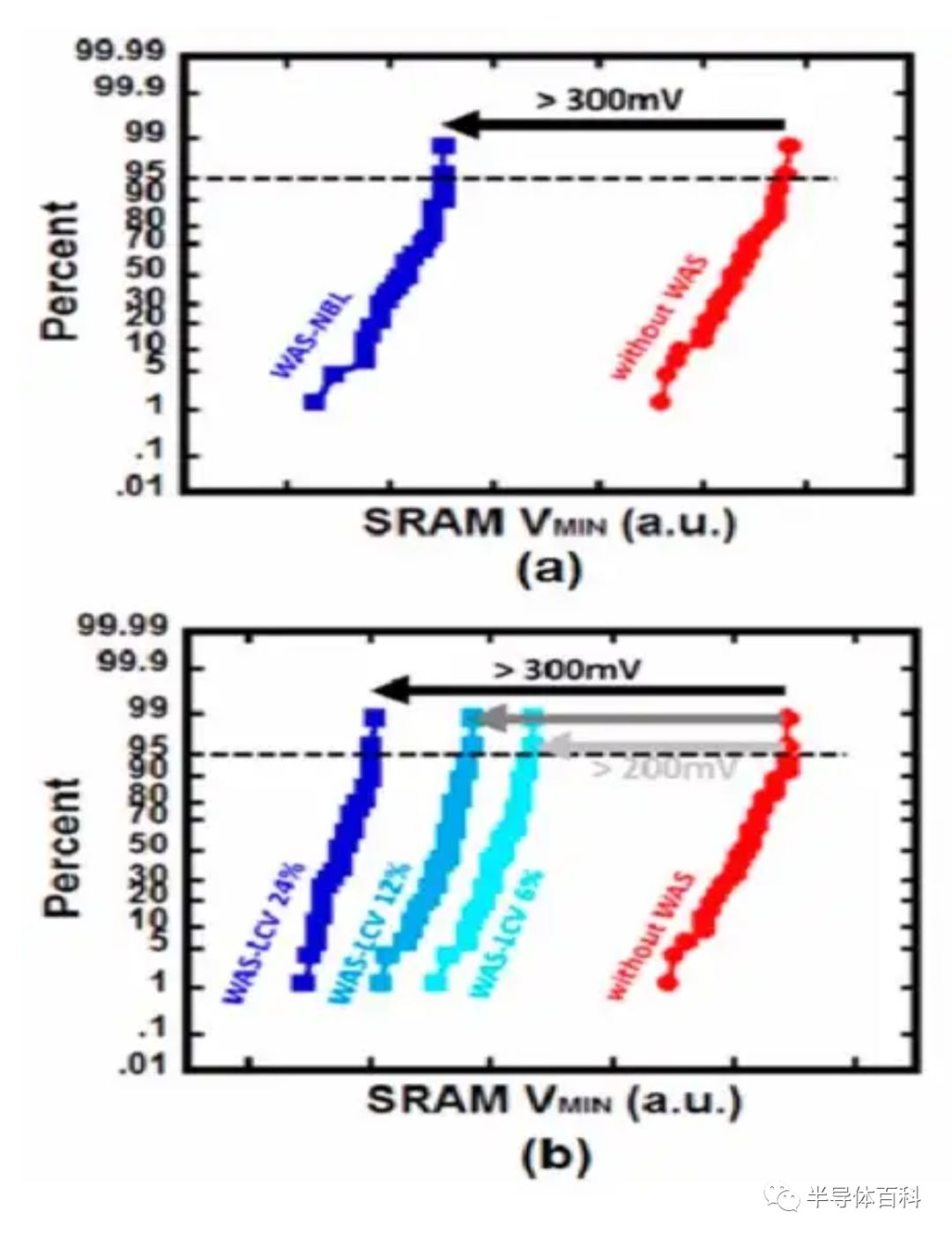
图11.(a)金属电容器增强的写辅助WAS-NBL方案和(b)金属电荷共享电容器WAS-LCV方案的测量结果。
高迁移率通道通过约18%的驱动电流增益提高了5nm工艺的性能,如图12所示。该技术已在IEDM 2019上进行了详细描述。
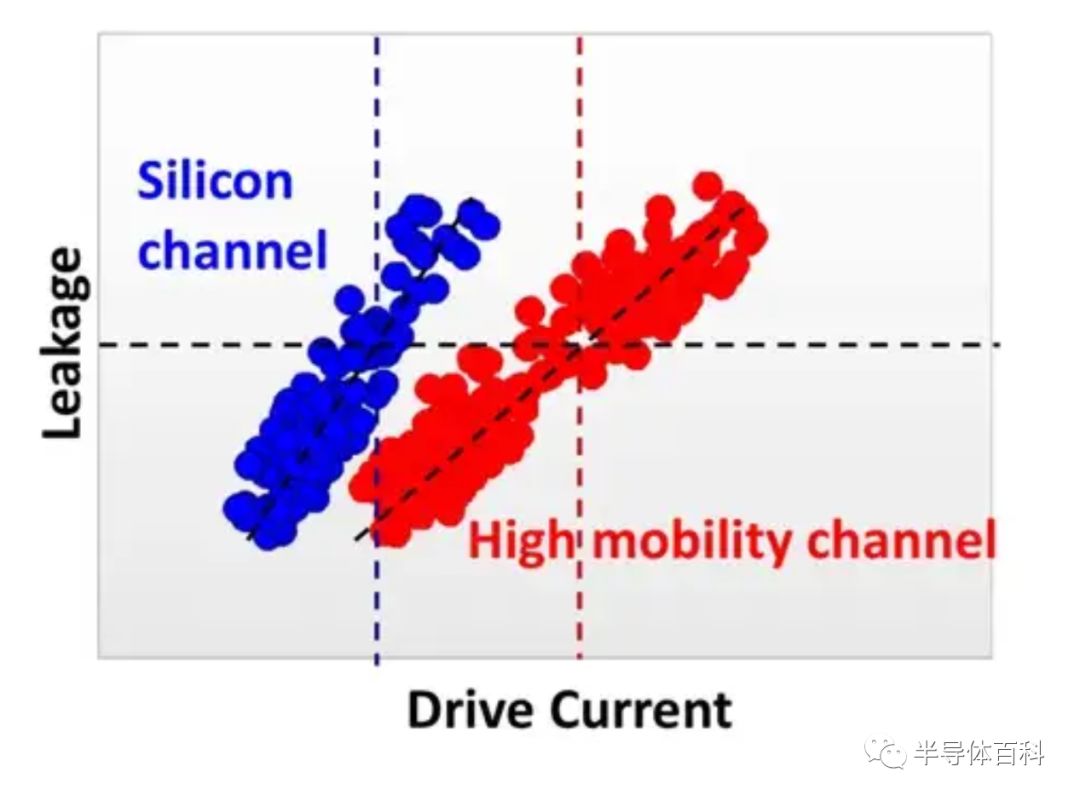
图12.高迁移率沟道(HMC)性能提升约18%。
这种性能提升的例子是用于L1高速缓存应用的高速SRAM阵列在0.85V电压下达到了4.1GHz,如图13 的shmoo图所示。
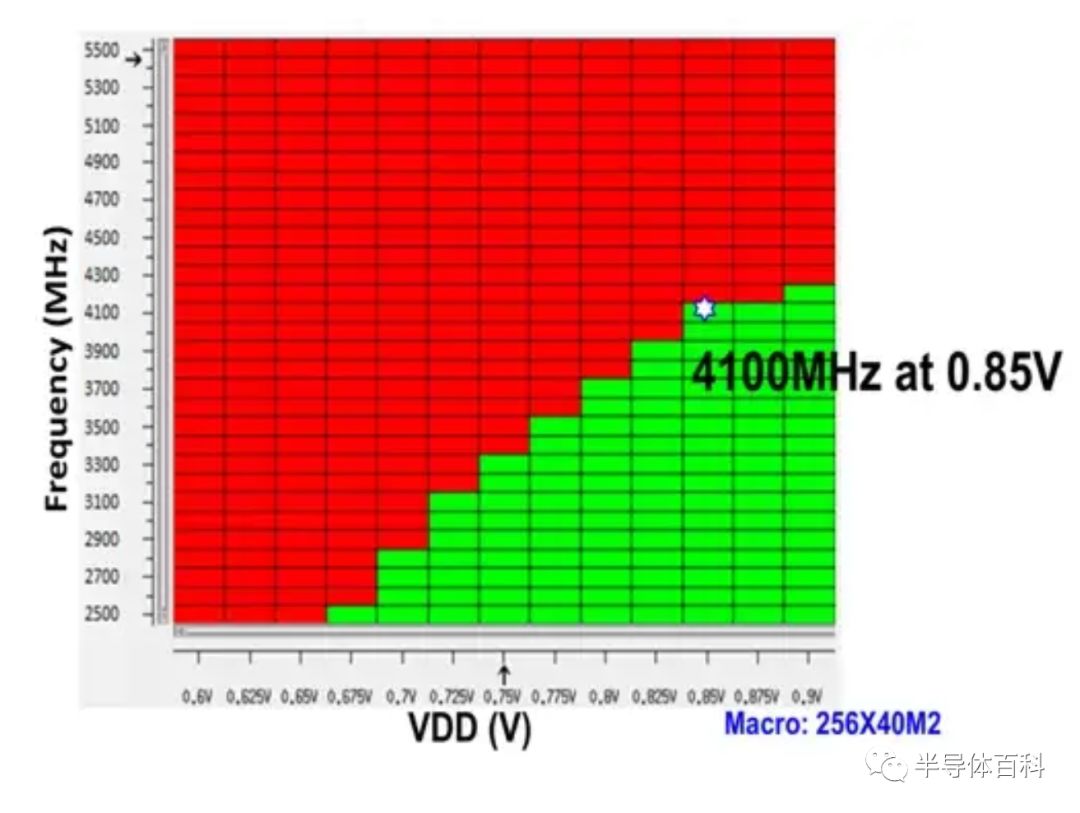
图13.用作高性能L1 HD SRAM阵列的Shmoo图
在0.85V时显示4.1 GHz。
测量结果基于图14所示的135 Mb测试芯片。

图14. 台积电5 nm 工艺135 Mb SRAM测试芯片。
总而言之,此处描述的详细电路设计技术使产品开发人员能够从这项领先技术中获得最大的优势。这也体现了产品/电路设计人员与负责产品良率和可靠性的工艺开发人员之间进行设计工艺协同优化(DTCO)的重要性。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2242期内容,欢迎关注。
推荐阅读
半导体行业观察

『 半导体第一垂直媒体 』
实时 专业 原创 深度
识别二维码 ,回复下方关键词,阅读更多
“芯”系疫情 |ISSCC 2020 |日韩芯片 |华为 | 存储 | 氮化镓|高通|康佳
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复 搜索 ,还能轻松找到其他你感兴趣的文章!

-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号