来源:内容由半导体行业观察(icbank)
编译自「
technews
」,
谢谢。
2015 年俄罗斯的MCST(Moscow Center for SPARC Technologies)发表四核心国产处理器Elbrus-4C,其中两个核心转译x86 指令集,两个核心当一般用途,后来有人发表在Elbrus 处理器平台,执行2002 年游戏《上古卷轴III:魔卷晨风》的画面。
目前Elbrus 产品线已发展到16 核、主频2GHz 的Elbrus-16S。前苏联与俄罗斯体系的高效能处理器是非常值得特别介绍的精彩主题,之后有机会再与读者分享。
扣除标题(Header),Elbrus E2K 的单一指令最多可包含1~15 个指令,指令编码长度介于64 到512 位元(一般RISC 都固定32 位元),说这个不叫「超长指令」,那还真的很难找出更长的例子了。
由「苏联的超级电脑之父」Boris Babaian 领衔开发的Elbrus 系列处理器,技术基础E2K 早在1999 年就揭露技术细节(虽然那时只是处于Verilog 硬体描述语言阶段,尚无实品),Elbrus E2K 也是采用超长指令集架构(Very Long Instruction Word,VLIW)的处理器。
如同1990 年代VLIW 曾风行一阵的趋势,从数字讯号处理器到泛用处理器,从Philips 的TriMedia、斯洛伐克的新创公司DanSoft、ADI / Lucent / Motorola / TI 的诸多数字讯号处理器(DSP)、英特尔i860、Fujitsu FR-V、Linus Torvalds 曾参过的Transmeta Crusoe、Sun 的MAJC、与英特尔Itanium 等族繁不及备载的案例。
特别一提,1980 年代的VLIW 先驱者:Multiflow(Trace 7/300)与Cydrome(Cydra 5),先后被惠普(HP)购并,催生了VLIW 化的PA-RISC 处理器计画,演变成后人熟知的IA-64 指令集与英特尔Itanium 处理器。
究竟VLIW 有什么神奇的魅力,吸引这么多厂商共襄盛举?为何又在今日主流泛用处理器几乎消失无踪?让我们继续看下去。
1980年代末期,随着超管线(Superpipeline)、超纯量(Superscalar)、非循序指令执行(Out-Of-Order Execution)、与预测执行(Speculative Execution)的普及化,激增了处理器同时执行的指令数,电路复杂度也随之水涨船高。
超纯量架构每个主频周期需撷取(Fetch)、解码(Decode)、执行(Execute)并写回(Write Back)两个以上指令,势必带来资源冲突的状况,像资料相依性(某个指令需要后面指令的资料)、控制相依性(指令需等待条件判断的结果)、结构相依性(两个指令同时使用某个执行单元或暂存器档案),为了处理这些问题,处理器微架构只会更精密复杂,也增加产品跑出臭虫的机率。
RISC 指令集崛起固然纾解这方面的困难,但仍难斩草除根,为了持续提高效能以因应商业竞争,近代高效能RISC 处理器还是稳定恐龙化,更不用讲CISC 的x86 体系了。
当年英特尔Pentium 的浮点除法臭虫事件,就告诉世人残酷的真相:如同软件,处理器也是会出问题的(尤其偏偏又是难搞的x86 指令集),今日常见的主流处理器,「Errata Sheets 」无不是长长一串,还不少是永远不会修正的陈年宿疾。
但已生产出货的硬体,出了问题难以修正是一回事,假如我们将处理器的复杂度「转嫁」到软件呢?甚至将指令平行化「绑定」在指令集架构呢?这就是VLIW 会在1990 年代短暂流行的时代背景了。
VLIW 的概念起源非常古老,早在1946 年,伟大的计算机科学与人工智慧之父Alan Turing(艾伦‧图灵,电影《模仿游戏》的主角)就已经提出水平式微码(Horizontal Microcode,每个栏位水平对应电路动作,相对于还需要额外解码的垂直式微码)的想法,细节由微码一词的创造者Maurice Wilkes 补完,在首创「计算机结构(象征可回溯相容的指令集架构) 」的IBM S/360 大型主机(Mainframe)诞生过程中,发挥了关键性影响力。
在IBM 的S/360 问世前,每台电脑的指令集都是针对特殊应用量身订做,互不相容,这对今天习惯同时在英特尔AMD VIA 的x86 处理器,执行相同作业系统与应用程式的我们来说,的确是很难想像的场景。
当然微码不等于指令,只是用来实做指令的某种手段,如透过微码组成的微程式产生控制讯号。但之后1970 年代,某些使用水平式微码实作控制单元的特殊应用电脑,如Floating Point Systems 的产品,就导入了可写入(不再唯读)的微码记忆体,使其摇身一变,成为可程式化的VLIW 电脑,接着就是1980 年代,像Multiflow、Cydrome 和Culler 这些规模较小的电脑公司,企图打造泛用VLIW 架构迷你超级电脑的故事了。
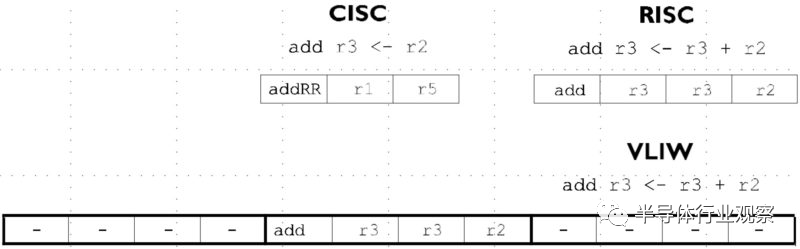
VLIW 的核心精神就在于「将指令平行化直接绑在指令集架构内」,一个指令就「包」了一堆不同性质的运算,一次喂给处理器。以一个简单的双运算元加法为例,CISC、RISC 和VLIW 的样貌就如下图,相当简单易懂。
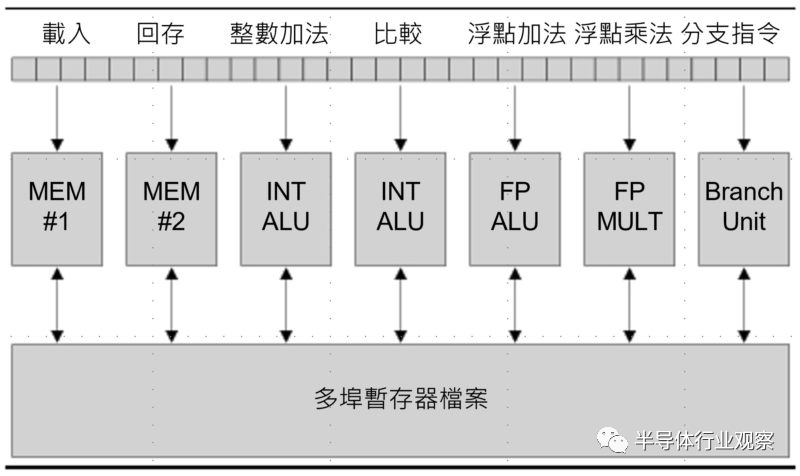
最理想化的VLIW,就是「一个萝卜一个坑」,每个不同运算性质的指令栏位直接对应专属的执行单元,无需硬体进行指令排程与分配,统统软件搞定。这也意味着编译器(Compiler)产出的二进位执行码,能否「塞好塞满」的最佳化排程指令,将决定VLIW 的实用性。如果最佳化程度不足,只会代表指令内充满了大量什么都不做的NOP(No Operation),不仅浪费执行单元,并伤害执行效能。
程式码过肥是VLIW 的首要麻烦。同样出自英特尔之手,VLIW 的IA-64,程式码体积高达x86 的3.7~4.8 倍,这冲击充分反映在更大型化的快取记忆体容量与更高效率的记忆体子系统。
二进位执行码相容性也是VLIW 的主要限制,如未来处理器增加更多执行单元,降低了执行指令的时间延迟,就必须修改指令集格式与指令排程,也意味着不同版本的程式码,造成在「不同世代或不同指令派发宽度」的VLIW 处理器之间移植程式,会比硬体分派指令的超纯量架构困难许多。
虽然这并不代表超纯量架构不需要软件最佳化(像英特尔自家编译器就有对应自家x86 处理器的参数,如QxP 就专属于90 奈米Pentium 4「Prescott」并尽量使用新增的SSE3 指令,以此类推),但起码确保相容于过去的程式码,却是无法否认的重大优势,这也是今日超纯量架构依旧是高效能泛用处理器主流的关键因素。
企图让VLIW 通用化的最后努力:英特尔IA-64
但VLIW 也并非铁板一块、非得「遵循古法」不可,英特尔和惠普(HP)合作的IA-64 指令集就企图打造更有弹性、不将指令格式跟执行管线绑死的VLIW 指令集。
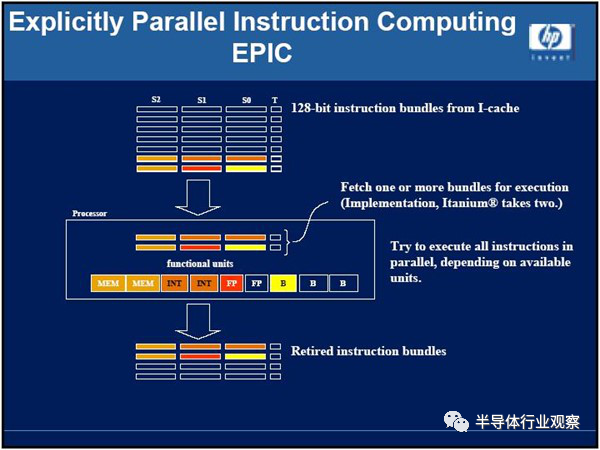
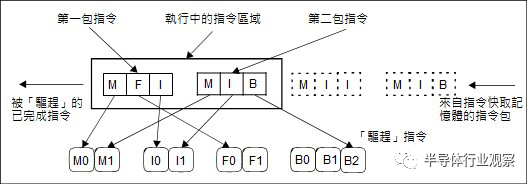
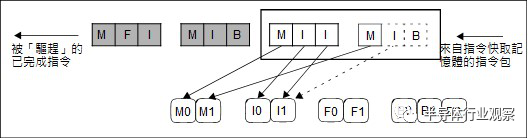
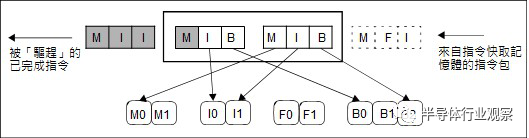
IA-64 将3 个41 位元长的指令,与标定内部指令顺序的样板位元(Template),包成一个128 位元长的指令包。当指令包送进处理器内部的执行单元前,只要藉由读取样板位元,即可事先得知「后面该做什么事」,分配需要的执行单元,指令就「顺顺的」被循序执行,整个指令包被处理完毕后再退返(Retire),依然享有VLIW 的大部分优点,只是硬体就可能比纯VLIW 稍微复杂一些。
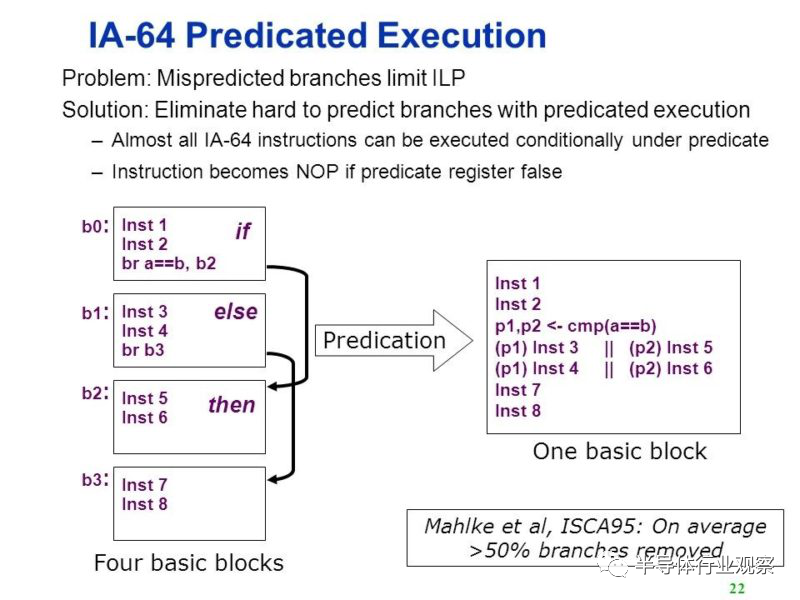
不过绑了一堆运算的VLIW,会对条件判断流程引发的管线停滞(Stall)特别的感冒,从指令集层面设法减少分支指令,也是IA-64(与众多VLIW 指令集)的努力方向。
IA-64 配置了64 个由软件控制的引述码(Predication)暂存器,经由引述码来控制指令执行流程,取代大多数简单的条件判断,不必去赌分支预测的结果,如处理器的运算资源极度充裕,更可「奢侈的两边一起执行,只保留需要的结果」(笔者很好奇现实Itanium 应用程式是不是真的这样做)。讲玄一点,引述执行(Predicated Execution)将「控制流」转换成「资料流」,换一个说法则是「控制相依性」转化成「资料相依性」。
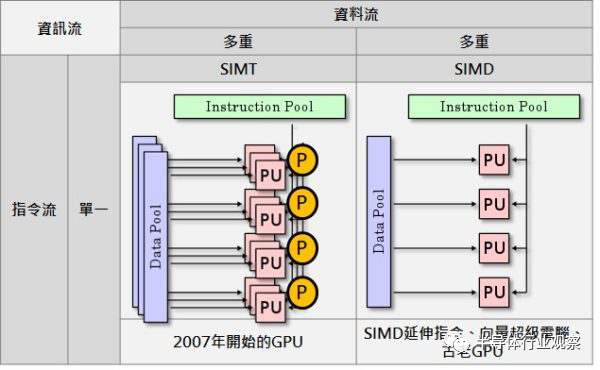
谈到引述执行,顺便一提,其实以nVidia G80(Tesla)为首的GPGPU,SIMT(单指令多执行绪)架构也是靠这一千零一招,控制庞大执行绪的执行流程,这也是和SIMD (单指令多重资料)最大的不同点。
结束「泛用VLIW」的Itanium 9500「Poulson」
现在看似「泛用VLIW」IA-64 如此美好,兼顾VLIW 的简洁性与超纯量的相容性,但天底下没有白吃的午餐。英特尔前三个世代的Itanium 核心(Merced、McKinley、Tukwila),都是简单的静态指令排程,单执行绪最多同时执行两个指令包(6 条指令),为了尽快「完成指令并驱赶之」 ,必须准备足够的内部资源,以匹配6 个指令的组合,固然简化了处理器内部的资料路径,但却也浪费了庞大的内部执行单元,导致Itanium 核心肥大化,并且让Itanium 的单执行绪效能追不上同期的x86 处理器。
日后由DEC Alpha 团队操刀的Itanium 9500「Poulson」,走上一条彻底否定VLIW 核心价值的回头路,直接做成类似超纯量的动态指令排程,管线前端就拆光指令包,不同类型的指令有专属的指令排程伫列,并将同时可发派的指令包倍增成4 个,实现更高的处理器利用率,相较前代激增25%~40% 效能。
但这也变相宣布「General Purpose VLIW is Dead」。
2000 年,当英特尔和惠普意气风发发表Itanium 处理器与IA-64 指令集,并宣称「非循序指令执行已经过时了」(Out-Of-Order is Out-Of-Date),时任IBM 院士、曾为RISC 早期研究案IBM 801 计画设计者的Martin Hopkins,对英特尔和惠普发动的反击与批评,以及两位RISC 大师合着的教科书,将Itanium 描述为「平庸的整数运算处理器」,事后看来统统一语成谶,令人不胜唏嘘。
CISC 的出现,RISC 的反动,到x86 至今仍稳坐伺服器和个人电脑的主流地位,我们可清楚理解一个简单的事实:在不同的时代背景,基于不同的技术限制和应用考量,哪些工作该让硬体处理,哪些事该丢给软件搞定,这条软件和硬体之间的界线,从来就不是固定的,也没有绝对标准。但从1964 年IBM S/360 大型主机建立的回溯相容性观念,重要性却深植人心,仍为重中之重,更是VLIW 迟迟难以跨越的门槛。
在超纯量动态排程处理器仍为主流的当下,自从英特尔Itanium 后,除了GPU(AMD 第三代绘图架构TeraScale)、嵌入式应用或数字讯号处理(DSP),几乎不见VLIW 在泛用处理器的身影,俄系血统且身为x86 相容处理器的Elbrus,变成濒临绝种的珍奇异兽,这也是笔者下一篇专文介绍的主角,敬请拭目以待。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2271期内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
存储|射频|CMOS|
设备
|FPGA
|晶圆|苹果|海思|半导体股价
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!