来源:内容由半导体行业观察(ID:icbank)编译自「
Tomshardware
」,谢谢。
去年,英特尔宣布了Xe Graphics,同时英特尔表示将重新进入独立GPU市场,这是自1998年i740以来吗,我们首次看到专用的英特尔GPU。现在,最好的显卡之间的竞争非常激烈 ,但英特尔当前的集成显卡解决方案其实在GPU市场排不上号(它们甚至是Nvidia GT 1030等低端卡的性能的约1/3)。低性能集成GPU的供应商英特尔(“世界上最受欢迎的GPU”)是否可以成为这个市场的有力竞争者?
我们必须看到,今年在PCGraphics卡市场,将进行大规模的改革。AMD正在开发Big Navi / RDNA 2,Nvidia的RTX 3080 / Ampere GPU即将面世,与英特尔的Xe Graphics同期,有传闻将有第四家公司可能进入PC GPU市场,那就是华为。据报道,华为正在进入数据中心GPU市场,因此,可以想象在某个时候制造消费类产品并不是一个巨大的飞跃。
英特尔的Xe Graphics计划在2018年成为热点话题,当时他们从AMD 聘请了Raja Koduri,此外还有芯片架构师Jim Keller和Graphics市场营销商Chris Hook。其中Raja是AMD在2015年11月成立的AMD Radeon Technologies Group以及Vega和Navi架构的重要推动者。英特尔招聘他是希望通他能领导Intel的GPU部门进入新的领域。并不是说英特尔以前没有尝试过。其实除了i740之外,英特尔在2009年推出Larrabee和Xeon Phi也是他们的一次尝试,尽管GPU方面从未真正实现过。但他们现在来到了第三次。
当然,构建一个好的 GPU不仅是说说而已,当中有很多东西需要解决,同时英特尔还有很多要证明的事情。在本文中中,我们将介绍Intel Xe Graphics的所有信息,包括发布日期,规格,性能预期和价格。
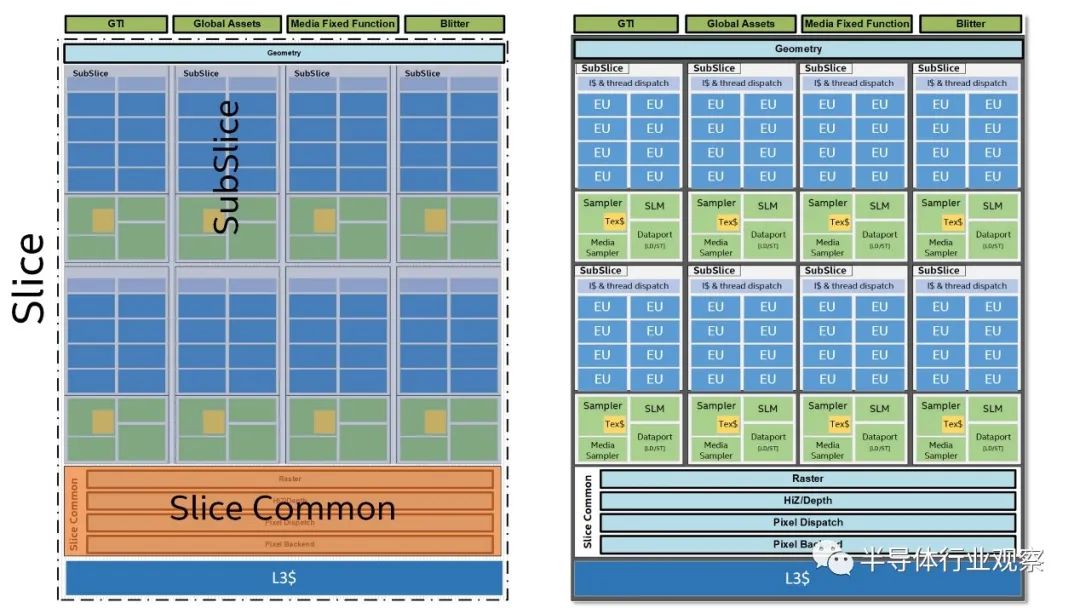
英特尔的Gen11 Graphics在高层似乎与Xe Graphics非常相似。(图片来源:英特尔)
尽管英特尔可能是专用显卡市场的新来者,但制造GPU对他们来说绝不是新事物。例如当前的Intel Ice Lake CPU使用了Gen11 Graphics架构,顾名思义,它是第11代Intel GPU。顺便说一句,第一代英特尔GPU出现在其最后一个独立显卡i740中(大约在1998-2000年间,以及用于370奔腾III和赛扬CPU的英特尔810/815芯片组)。
Xe Graphics在Intel GPU架构上已进入第12代,换句话说,在过去十年中,Gen5至Gen11已集成到Intel CPU中。请注意,Gen10 Graphics从来没有看到过“光明”,因为它是Cannon Lake CPU系列中止的一部分。
尽管每代GPU都基于以前的架构是很普遍的现象,但在升级过程中,也增加了各种改进和增强功能,但据报道,英特尔现在正在使用Xe Graphics进行重大更改。其中一些更改着重于实现GPU内核的扩展,另一些更改着眼于专用VRAM的需求,还有一些更改着重于提高每核性能和IPC。
最近的英特尔GPU已分为多个“切片”(slices)和“子切片”(sub-slices),这些子切片在某种程度上类似于AMD的CU和Nvidia的SM。Gen9 Graphics的子切片大小为8个EU,每个EU具有两个128位浮点单元(FPU)。对于FP32计算,每个EU每个时钟最多可以执行8条指令,而FMA(fused multiply add:融合乘法加法)指令计为两个FP操作,从而使每个时钟的最大吞吐量达到16个FP操作。因此:EUs * 8 * 2 *时钟速度= GFLOPS。从这个意义上讲,与AMD和Nvidia GPU相比,EU算作8个GPU内核,而8个EU等于AMD CU或Nvidia SM。
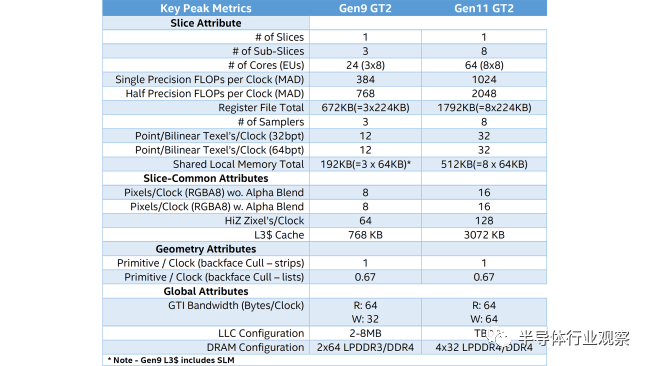
跨出一个级别,以前的Intel Graphics中的切片已分类为GT1,GT2,GT3和GT4(Ice Lake / Gen11添加了GT1.5选项)。对于Gen9,GT2模型具有三个子切片,每个子切片具有八个EU,GT1模型具有两个子切片,每个子切片都具有六个EU,而GT3模型具有六个子切片和每个八个EU。Gen11更改为每个切片具有八个EU的四个子切片,因此Ice Lake GT2具有64个EU和512个GPU内核。对于Xe Graphics,英特尔将寻求更高的EU数量和更大的GPU尺寸。
第11代与第9代相比有了很大的进步,Xe Graphics可以扩展到八个或更多片。 (图片来源:英特尔)
当前的迹象表明,Xe Graphics的基本“切片”大小将启用多达64个EU,而不同的配置具有不同数量的切片和子切片,可以根据需要部分禁用这些切片和子切片。Xe Graphics的基本构建块最终与Gen11 Graphics基本相同,至少在第一次迭代中是如此。重大变化将涉及为专用VRAM添加所有逻辑,并扩展到更大的内核数量和多芯片支持,以及尚未揭示的任何其他体系结构变化。Xe Graphics将完全支持DX12和Vulkan,但除此之外一无所知。
英特尔已经讨论了Xe Graphics的三大分类:用于低功耗/低性能设备的Xe LP,用于高性能解决方案的Xe HP和用于数据中心应用程序的Xe HPC。据我们所知,Xe LP主要用于集成Graphics解决方案,可能只有一个切片,在某些情况下可能是两个。我们知道Xe LP将在即将面世的Tiger Lake CPU中使用,并且已在Xe Graphics DG1开发人员卡中使用过。换句话说,它将是英特尔处理器Graphics的下一个版本。
另一方面,Xe HPC和Intel Exascale是英特尔对超级计算机的雄心壮志的图像和详细信息,正如您可能想像的那样,这意味着功能强大且昂贵的芯片。我们认为Xe HPC GPU很长一段时间都不会在消费卡中出现。从我们的角度来看,最有趣的芯片将落在Xe HP的,这些芯片应会出现在各种消费类Graphics卡中。
但我们尚不清楚的是第一批Xe Graphics解决方案是否将支持硬件光线跟踪。英特尔曾表示将支持光线追踪,但并未具体说明它是否将在最初版本的Xe Graphics架构中实现。光线追踪似乎更可能出现在第二代Xe Graphics——7nm Ponte Vecchio和相关芯片中。也许光纤追踪支持将仅出现在第一代产品的有限子集中,例如高端Xe HP或HPC,但不包括Xe LP。但具体情况我们还不知道,不给如果英特尔在AMD的光线跟踪解决方案推出之前,就实现完整的光线跟踪,这将是非常令人惊讶的。
这些架构更新至关重要,因为就游戏性能而言,当前的Intel GPU充其量是能用。以UHD Graphics 630为例:在Core i9-9900K中,在1.2 GHz下的24个EU(192个内核)在理论上可以提供460.8 GFLOPS或在时钟频率稍低的(1.1 GHz)Core i3-9100中提供422.4 GFLOPS。相比之下,AMD Ryzen 5 3400G具有11个CU,704个GPU内核和1.4 GHz时钟速度,理论性能为1971.2 GFLOPS。那就意味着AMD的Vega 11 Graphics速度大约是Intel UHD Graphics 630的三倍,甚至可以更高,但是两种集成显卡解决方案至少在一定程度上受到系统内存带宽的限制。
英特尔的Ice Lake处理器具有64 EU GPU,可提供有关Xe Graphics如何扩展的线索。 (图片来源:英特尔)
除了大部分未公开的体系结构更改之外,Xe Graphics上还有一些其他有趣的花絮值得讨论。例如,我们可以很好地了解有关尺寸和晶体管数量的期望。首先,看一下英特尔的Ice Lake先,看看64 EUGPU在英特尔的10纳米节点上有多大。分析die shot,看起来有64个带有Gen11的EU占据了大约40-45平方毫米的die空间。这实际上很小,这意味着英特尔可以扩展到更大的 GPU。
即使我们采用该估计值的上限(4平方5毫米),然后假设Xe Graphics架构将使尺寸增加近50%(对于它应该带来的所有增强和IPC更改),我们仍然只有每64 EU切片需要65平方毫米的空间。与显示输出,视频编解码器相关的逻辑很多,在大型GPU上不需要复制的逻辑更多,但我们的目标是更高的。
将其加倍到130芳芳毫米将为Intel提供128 EU芯片,260平方毫米将是256 EUs,而520平方毫米将产生512 EUs。同样,实际的芯片尺寸可能要小得多,因为最初的大50%的估计可能会过高。如果英特尔对消费卡采用multi-chiplet方法,则可以只使用一个基本芯片,然后将多个芯片链接在一起。另外,如果英特尔采用定制的硅片路线,则128 EU GPU可能约为150平方毫米,而256 EU可以容纳约250平方毫米,而大型512 EU芯片可能只需要450平方毫米。这样的尺寸绝对是GPU可以达到的,而我们已经看到AMD和Nvidia通常会变得更大。
单个芯片中有512个EU将意味着相当于4096个GPU内核,这将是非常令人印象深刻的。相比之下,AMD的RX 5700 XT具有2560个GPU内核,而英伟达的RTX 2080 Ti具有4352个GPU内核。我们不是说AMD,英特尔和Nvidia的 GPU都等效,但这至少是衡量潜在性能的基准。512 EU芯片的理论计算量实际上可能会超过当前台式机Graphics卡领域的王者。这听起来像是幻想吗?让我们查看2020年2月在Twitter上发布的Xe Graphics die shot Raja Koduri。
我们分析了这张照片,大概是第一代10nm + Xe HPC GPU。坦白说,die似乎是巨大的!我们还看到了其他分析结果,但是我们自己的估计是该芯片上的GPU裸片正接近最大标线片尺寸——大约800平方毫米。这也与英特尔公开声明的有关其第二代Ponte Vecchio架构的说法相吻合,该架构将移至7nm节点。
Ponte Vecchio将包括英特尔的芯片堆叠技术Foveros,英特尔在2019年的投资者会议上提到,采用当前以PC为中心的方法,产品尺寸“受到标线的限制”。换句话说,芯片的最大尺寸是基于制造机械的硬限制。这适用于所有微处理器,并且限制大约在850平方毫米左右。英特尔未来的计划将转向以数据为中心的模型,该模型将允许通过裸片堆叠进行进一步扩展,但不适用于10nm + Xe HPC GPU。
因此Xe HPC也许将使用上述的GPU die,这看起来接近最大标线片尺寸。同样,这将不会在消费产品中使用,但是鉴于我们对英特尔Gen11 Graphics的了解,这样的GPU可能等效于具有1024个EU和8192个GPU核心。英特尔还谈到了未来的GPU将迁移到“数千个EU”,这意味着多个Ponte Vecchio芯片将加入HMB2e内存,添加INT8和FP64支持,数据中心应该开始运行。
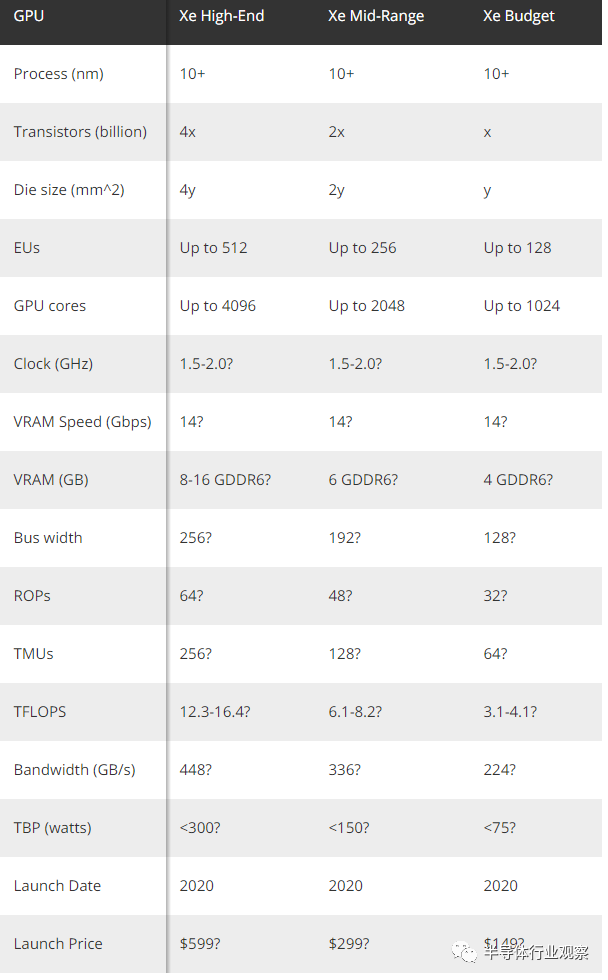
现在将其缩小到更易于管理的尺寸,您就会得到以消费者为中心的Xe HP。一个在2019年6月意外从英特尔Graphics驱动程序发布中看到的。除了Xe LP型号(最有可能限于64个EU)之外,英特尔还计划生产128 EU,256 EU和512 EU Xe HP Graphics卡。这也与英特尔关于Xe LP从5W扩展到20W设计的陈述相吻。-不需要带有20W TDP GPU的专用Graphics卡。这使我们了解了实际的Xe Graphics规范。
英特尔的Xe Graphics DG1开发板,在2020年国际消费电子展上展示。 (图片来源:英特尔)
关于Intel Xe Graphics的泄漏和谣言各有各的,每一个都变得更加可信。英特尔还在2020年国际消费电子展上展示了Xe Graphics DG1开发板。尽管英特尔坚持认为该板不是面向消费者的最终设计,但将来看到类似的产品交付给我们也不会感到惊讶。
但是,Xe Graphics DG1还使用Xe LP芯片,这意味着它是仅用于测试目的的低功耗专用GPU。英特尔还透露,Xe Graphics有三个品牌,从超级移动设备到游戏台式机,再到工作站和数据中心应用程序,均可扩展。鉴于以上所述,英特尔计划发布一套XeGraphics卡,大概使用Xe HP芯片,以下是我们期望看到的配置:
根据芯片截图和其他信息,我们期望Xe HP GPU将成为消费Xe Graphics卡的基本构建块。英特尔的EMIB(嵌入式多管芯互连桥)可以亮相,支持多芯片GPU配置,但没有AMD CrossFire或Nvidia SLI复杂。就像AMD在Ryzen CPU上使用小芯片方法一样,只是应用于Graphics。这就是上表假设的。
EMIB可以有效地使两个或四个芯片或多或少地充当一个芯片,共同承担渲染任务和内存。具有讽刺意味的是,当英特尔最初与Ryzen一起取笑AMD的“粘合”芯片时,我们可以看到结果:在AMD与Intel CPU的对比中,Ryzen已迅速扩展到英特尔提供更高的内核数量和性能目前无法匹配。但是英特尔足够聪明,可以认识到这种方法的优势,并且将其应用于GPU很有道理。
或者,可能仅针对Xe HPC数据中心模型计划EMIB。然后,英特尔将采用与AMD和Nvidia相似的方法,并制造多个GPU变体,其规格仍应与上表中列出的规格相近。EMIB和多芯片方法的优势在于,它可以使英特尔专注于两个主要GPU:Xe HP和Xe HPC(将Xe LP集成到Tiger Lake和其他CPU中)。
考虑到英特尔将不得不与其CPU系列共享Xe Graphics的10nm以上制造工艺,因此简化设计数量会有所帮助。由于英特尔尚未使用其10nm工艺发布具有四个以上CPU内核的CPU,因此还存在关于Intel在10nm以上的良率和缺陷数量的疑问。采用较小的裸片和EMIB可以显着提高Xe HP的良率。这就是为什么我们的主要猜测是第一代Xe Graphics将使用EMIB工艺的原因。
每个Xe HP GPU 128个EU将意味着相当于1024个GPU内核,并且如上所述,应以各种尚未公开的方式改进内核的基础架构。根据英特尔所做的事情,最终可能会获得与AMD和Nvidia GPU内核更接近平价的GPU内核,这是最理想的情况,而我们希望发生这种情况。有关于2芯片和4芯片Xe Graphics配置的可信谣言,这将使基本Xe HP设计的理论性能提高两倍和四倍。
添加更多的GPU内核,切片,EU或任何您想称呼它们的东西都会对英特尔有很大帮助。考虑到Nvidia已经提供了多达4608核(Titan RTX)的GPU,AMD提供了多达4096核(RX Vega 64)的GPU ,而AMD和Nvidia都提供了支持,那么128个EUs / 1024核并不能完全吸引我们。而推出的Big Navi和Ampere架构可能会变得更高。到今年年底,我们可以看到AMD和Nvidia GPU具有5120至8192个GPU内核。
英特尔在消费领域的表现似乎并不高,但是我们希望看到Xe Graphics的型号可以容纳96个EU,最高可达512个EU,介于两者之间。结合1.5-2.0 GHz的时钟速度,考虑到先前的设计以及向10nm +的迁移,这似乎是合理的,英特尔可能会在512 EU四芯片配置上将12-16 TFLOPS的计算能力推向高潮。再加上8GB的GDDR6内存(或者可能是16GB的两倍),英特尔最高性能的Xe Graphics卡可能是AMD和Nvidia GPU的有力竞争者。至少这是理论,尽管我们仍然不知道是否会出现光线追踪支持。
下降到较小的GPU或双芯片配置,我们将获得中等的中端性能。一半的EU和GPU内核,一半的原始计算,但降至6GB VRAM并保留六个内存通道— 2020年没有至少6GB VRAM的中档GPU根本无法实现。6-8 TFLOPS的理论性能将使该中级Xe Graphics解决方案与Nvidia的RTX 2060和AMD的RX 5600 XT处于同一水平,尽管当然驱动程序和其他因素仍需要测试。
最后,我们预测了Xe HP配置。这将具有单个GPU小芯片(或最小的Xe Graphics专用GPU),4GB的VRAM和大约中端型号的一半性能。具有128个EU,即1024个内核和潜在的3-4 TFLOPS计算能力,这具体取决于时钟速度。可能会有更高和更低的型号,一个型号具有96个EU,而无需PCIe电源连接,另一个型号是具有128个EU和6针电源连接器的高性能预算卡。
值得注意的是,英特尔确实在CES演讲中曾说过Xe Graphics的速度是Gen9 Graphics的四倍。以上配置肯定会达到甚至超过该标准。但是,我们不知道英特尔是否只是简单地从架构上说了四次,即何时使时钟速度和EU计数相等,或者说总体速度是四倍。与集成的GT2 UHD Graphics 630配置相比,Xe LP集成解决方案似乎已经将目标提高了4倍。一块128 EU专用的XeGraphics卡应该不会超过英特尔以前提供的所有功能。
英特尔Xe Graphics的这种概念渲染可能是对较大卡的外观的合理猜测。 (图片来源:英特尔)
毫无疑问现在,AMD和Nvidia已经走在最前面了,英特尔是否会成为第三者杀入这个市场,这尚未可知,但我们可以看到半导体巨头的雄心。
★
点击文末【阅读原文】,可查看
本文原链接
。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2294期内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
中国半导体|苹果
|封测
|
蓝牙
|设备
|晶圆|英伟达|射频|台积电
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!