[原创] AI芯片市场,必有Graphcore的一席之地
2020-06-18
14:00:22
来源: 半导体行业观察
过去几年,人工智能应用的大流行推动了整个AI处理器市场的蓬勃发展。
根据Global Market Insights的数据预测,在2019年,全球的AI芯片组市场规模超过了80亿美元。而预计到2026年,这个数字将飙升至700亿美元,年复合增长率高达35%。在此期间,GPU将会占领主导位置,FPGA同样也会扮演重要角色。数据显示,2019年,GPU在AI芯片市场的份额高达45%,而FPGA在未来几年的年复合增长率也会达到25%。
除了这两者以外,以Intel X86处理器为代表的CPU和以谷歌TPU为代表的ASIC也是AI芯片市场的重要构成。这四种产品也因为各自的性能特点,在AI芯片市场拥有各自的位置。这也是一般行业分析师对AI芯片的分类。
但在AI芯片初创公司Graphcore的CEO Nigel Toon看来,
现在的AI硬件有三类解决方案:
第一类是一些非常简单的小型化加速产品
,应用于手机、传感器或摄像头中。在他看来,这类产品对厂商有较大挑战,算法也在演进。因此不断会有新的问题产生。
第二类是ASIC,
这是一些超大规模的公司为解决超大规模的问题而研发出的产品,比如谷歌的TPU就属这类。这些产品旨在用数学加速器解决问题。
第三类是可编程的处理器(Program Processor)。
在Nigel Toon看来,这类市场目前还是GPU的天下。“但我认为Graphcore也隶属这类市场,未来Graphcore在这个市场会产生非常多的应用场景,通过不断创新赢得更多市场份额。”Nigel Toon进一步指出,Graphcore要做的是一个非常灵活的处理器,一个从零开始专门针对AI而生的处理器架构——这就是他们的IPU。
所谓IPU,就是Intelligence Processing Unit,这是英国AI芯片初创公司Graphcore专门为机器智能设计的完全不同的处理器架构。
据Graphcore高级副总裁兼中国区总经理卢涛介绍,IPU是一个完全不同于GPU或其他处理器的产品。数据显示,IPU在自然语言处理方面的速度能够提升20%到50%;在图像分类方面也有6倍的吞吐量提升且具有更低的时延;在一些金融模型方面,IPU的训练速度更是能提高26倍以上。
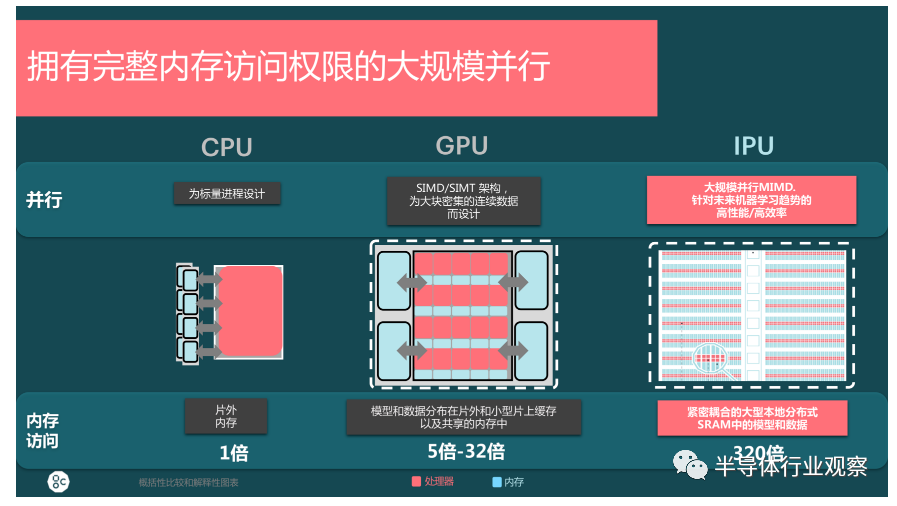
卢涛表示,与传统的CPU和GPU不同,IPU应用了一个大规模并行MIMD的处理器核。相对CPU的DDR2的子系统或者是GPU的GDDR、HBM,IPU的这个设计能够实现10到320倍的性能提升。而从时延的角度看,与访问外存相比较,时延基本上为1%、几乎可以忽略不计。
基于这种设计,IPU不单能够解决AI作为一种全新应用带来的不同架构要求,同时也能满足AI算力日益增加的需求。更重要的是,IPU这个全新架构绕开了大家对AI所熟悉的“冯诺依曼瓶颈”。基于这样的领先概念,Graphcore推出了他们的第一款IPU处理器GC2。
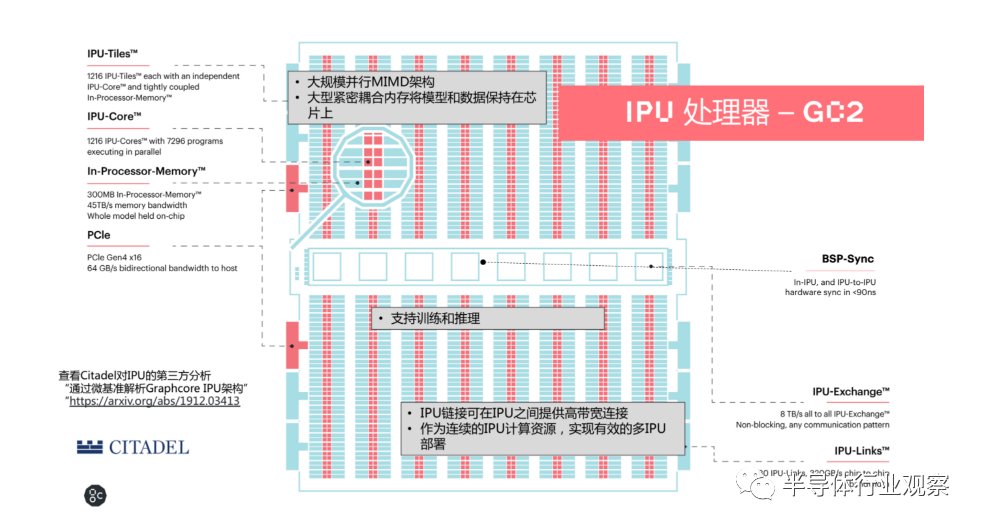
据了解,GC2是一个使用台积电16nm工艺打造的处理器,片内拥有1216个IPU-Tiles,而每个Tile有独立的IPU核作为计算以及In-Processor-Memory(处理器之内的内存)。换而言之,整个GC2总共有7296个线程,能够支持7296个程序同时运行。而In-Processor-Memory也达到了300 MB,因此可以完成将所有模型在片内处理的目标。
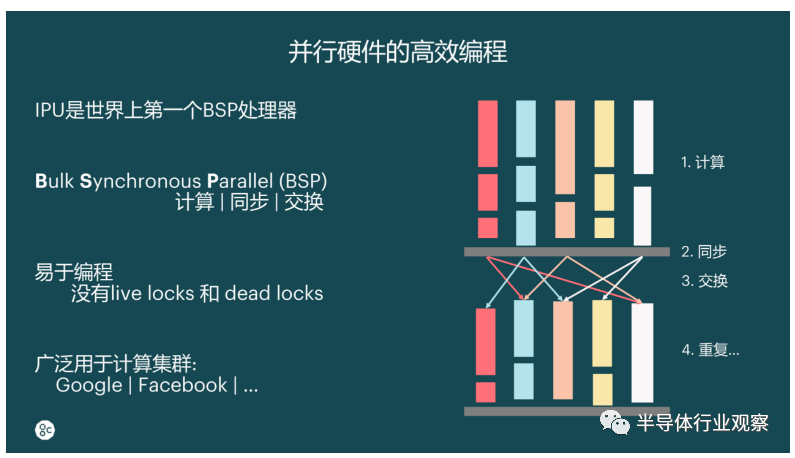
对于这种设计,读者也许会疑惑,产品如何保证IPU内核心之间的通信。从卢涛的介绍中我们得知,Bulk Synchronous Parallel(BSP)同步就是他们的解决方法。
“在各个核心之间我们进行BSP同步,以此支持同一个IPU处理器内1216个核心之间的通信,以及跨不同IPU之间的通信。这些都是通过BSP的同步协议即接口来实现的,中间有一个非常高速的IPU exchange的8TB/s多对多交换总线。” 卢涛解释称。据悉,IPU是全球第一款BSP处理器,通过硬件支持BSP协议,并通过BSP协议把整个计算逻辑分成了计算、同步、交换。因为无需处理locks这个概念,IPU对软件工程师或开发者而言非常易于编程。而用户也无需操心这里面是1216个核心(Tile)还是7000多个线程、任务具体在哪个核上执行,因此IPU是一个非常用户友好型的创新。
“另外,在IPU和IPU之间,我们有80个IPU-Links,总共有320GB/s的芯片与芯片间的带宽。所以一个处理器就可同时支持训练和推理。”卢涛补充说。
总体看来,IPU GC2是世界上非常复杂的拥有236亿个晶体管的芯片处理器,在120瓦的功耗下有125TFlops的混合精度、1216个独立的处理器核心(Tile)、300 M的SRAM能够把完整的模型放在片内。另外在带宽上,内存可以达到45 TB/s、片上交换为8 TB/s,片间的IPU-Links也能达到2.5 TB/s。
如前所述,Graphcore的IPU实力毋庸置疑,但这仅仅是他们面向AI市场推出的一个硬件产品。作为一家以AI为己任的企业,Graphcore还提供了软件和系统解决方案。正是在这三者的共同推进下,Graphcore才能够让开发者更好地拥抱这个面向未来的AI生态。当中的Poplar软件栈,更是Graphcore芯片落地的重要一环。这也是他们领先于大部分AI芯片初创企业的因素之一。
“不管芯片架构如何,能真真正正让用户获得体验感的还是SDK,包括可用性、用户和研究者能否方便地在系统上进行开发、移植和优化。”卢涛指出,“而Poplar正是这样的一个SDK。”
Poplar是软件栈的名称、是一个架构在机器学习的框架软件(比如TensorFlow、ONNX、PyTorch和PaddlePaddle)和硬件之间的基于计算图的整套工具链和库。Graphcore迄今为止已经提供了750个高性能计算元素的50多种优化功能,支持如TensorFlow 1、2,ONNX和PyTorch等标准机器学习框架。值得一提的是,Graphcore将会很快支持百度开发的PaddlePaddle。
在部署方面,Graphcore的Poplar现在可以提供容器化部署支持,能够快速启动并且运行。在标准生态方面,Poplar能够支持Docker、Kubernetes以及微软的Hyper-v等虚拟化技术和安全技术。在操作系统方面,Graphcore支持广泛应用的三个Linux发行版:ubuntu、RedHat Enterprise Linux和CentOS。
除此之外,Graphcore还推出了一个名为PopVision™ Graph Analyser的分析工具。开发者、研究者在使用IPU进行编程时,可以通过PopVision这个可视化的图形展示工具来分析软件运行、效率调试调优等情况。“从推出到现在,内外部开发者对PopVision的评价反馈极佳。”卢涛补充说。
为了进一步帮助开发者在IPU上实现AI落地,Graphcore在今年五月还上线了Poplar开发者文档和社区,由此为开发者提供大量的Poplar user guide、文档以及如何在TensorFlow进行IPU开发、如何把TensorFlow模型移植到IPU和TensorFlow模型如何并行发展等参考资料。
在卢涛看来,作为一个针对性开发的SDK,Poplar能够帮助开发者轻松地从零开始设计那些以支持在Graphcore IPU上构建和执行应用程序的框架和标准库。卢涛指出,AI的开发者有三类。第一类是基于TensorFlow和PyTorch框架的开发者,他们主要使用的开发语言为Python;第二类是基于NVIDIA cuDNN的开发者;第三类是CUDA级别的开发者。在这之中,第一类开发者的占比为90%,第二类开发者的占比为9%,最后一类开发者的占比为1%。面向这三类开发者,Poplar都能提供简明的迁移方案。
“如果您是一个TensorFlow或PyTorch的开发者,那您转移到IPU平台上的开发代码的迁移成本非常低,因为我们也在使用Python进行开发,同样的API意味着非常低的成本;如果是第二种开发者,我们会提供和cuDNN类似的用户体验,而实践也证明我们在这方面表现不错;至于第三类,也是挑战最大的一类,因为这相当于一个重新实现的过程。但从国内部分用户的反馈来看,Poplar的易用性比CUDA还好。”卢涛强调。
在这些软硬件生态的推动下,基于IPU的应用已经覆盖了包括自然语言处理、图像/视频处理、时序分析、推荐/排名及概率模型在内的多个领域。从实际的应用效果来看,IPU获得了比竞争对手更好的表现。
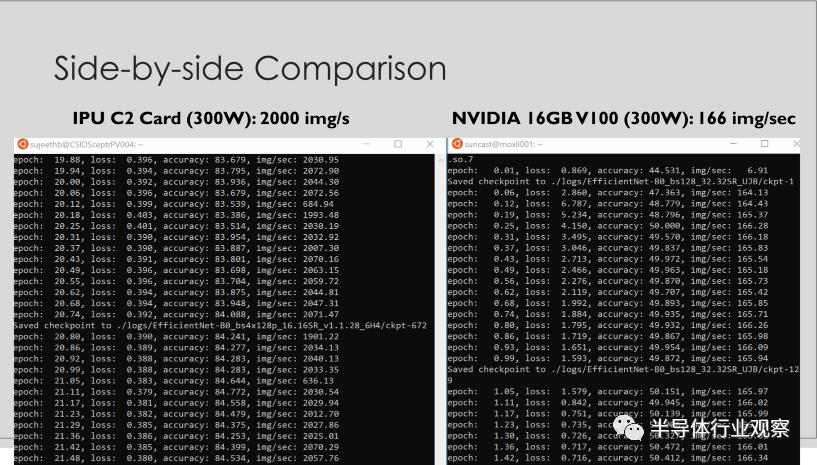
以BERT的训练为例,NVLink-enabled的平台大概需要50多个小时才能做到一定精度,而基于IPU的戴尔DSS-8440服务器只需36.3小时,训练时间提高了25%。以BERT的推理来看,在同样时延的情况下,IPU能够获得比当前最好的GPU高一倍的吞吐量。
Graphcore中国销售总监朱江介绍称,该公司的产品已经在多个应用市场获得客户认可。当中最值得一提的是微软使用了IPU训练CXR(胸部X光射线样片),从而帮助医学研究人员进行新冠肺炎的快速准确诊断。
朱江表示,微软发布的方案展现了IPU在微软自己专门创新的SONIC CV模型里,通过30分钟的时间就能够完成传统GPU需要5个小时才能完成训练的工作量。“微软方案中用到了两个不同的模型,第一个模型较传统、最近一两年出来的、他们做的EfficientNet-B0版本的模型。这个模型的模型尺寸比较小,只有540万参数,但能获得比更为传统和主流的ResNet更高的精度。”朱江补充说。
微软案例体现出IPU在医疗和生命科学领域的优势。除此之外,IPU还能在金融、电信、机器人、云和数据中心以及互联网等多个领域发挥巨大作用。这些领域的开发者也正在从与Graphcore的合作中受益。
在中国,Graphcore正在和包括阿里巴巴和百度在内的AI先行者建立密切的合作,推动IPU迅速融入本地AI生态系统。
朱江告诉记者,在今年五月举办的OCP Summit上,阿里巴巴集团异构计算首席科学家张伟丰博士宣布了Graphcore支持ODLA(Open Deep Learning API)硬件标准。通过这种结构,阿里巴巴试图为底层的架构设计出一个统一的API接口,而Graphcore已经能够支持ODLA。
此外,百度近日发布了国内一个重要的深度学习开源框架“飞桨”,在其上面也拥有非常广大的生态系统,包括百万以上的开发者和几十万的模型。鉴于该生态带来的市场影响力,Graphcore也已加入百度飞桨生态系统,会和百度飞桨一起帮助开发者进行突破性创新、加速AI模型部署及进入市场。
卢涛表示:“长期来说,我们对中国市场的期望颇高,希望中国市场能为Graphcore贡献40%甚至50%的营收。为了达成这个目标,我们正在‘练内功、打基础、共同建设’,不断攻克技术上的难题。”
而为了更好拥抱中国市场,Graphcore还有针对性地部署本地化产品和服务。在服务方面,Graphcore在国内目前有两支技术团队,一支是以定制开发为主要任务的工程技术团队,另一支是以用户技术服务为主的现场应用团队。具体而言,工程技术团队主要承担两方面的工作:一是根据中国本地的AI应用特点和需求,把AI算法模型在IPU上进行落地;二是根据中国本地用户对AI稳定性学习框架平台软件方面的需求,进行功能性的开发。现场应用团队则是帮助用户进行现场技术支持。
在与Graphcore交流的过程中,卢涛多次强调AI芯片从做出来到商用落地,中间存在非常大的鸿沟。如果AI芯片公司意识不到这个问题,未来面临的挑战就会非常大。他进一步指出,
衡量AI芯片真正商业化的标准主要为:
第一,是否具有支持AI继续学习的平台软件、支持效果如何;
第二,大规模部署的软件对Docker、虚拟化的支持如何。如果这两方面支持得比较好,那算法应用就能真正落地;
而Graphcore已经跨过了这些鸿沟,成为了“幸存者”。但我们同时也应该看到,过去一年多以来,无论是Intel Nervana项目的事实上宣告失败,还是Wave Computing的破产,都似乎透露出AI行业并没有想象中的那么简单,有些人甚至认为AI的低潮期已经到来。
针对这个问题,卢涛认为:“其实整个AI行业并没有走向低潮。相反,今年会有很大发展。因为自然语言处理相关应用的崛起会催生大量的、各种各样的应用,以及在算力方面有很大提升。”
“现在一般的CV类模型为几兆、几百万或几千万的参数,而大一些的NLP模型可以达到一亿、十亿、一百亿。这些模型对算力的要求均为指数级,所以我们认为AI行业并没有遇到寒冬。”卢涛说。
在谈到未来发展目标时,卢涛表示,现在的独立AI供应商市场在计算方面会有两个主要来源,分别是CPU和GPU,而这两个领域也在不断更新和发展,因为它们在不少应用场景上有相当大的优势。而IPU的目标则是成为CPU和GPU外的第三大来源。
“IPU旨在帮助用户应对当前在GPU、CPU上表现不太好的、或者说是阻碍大家创新的场景。”卢涛补充道。而今年下半年的新一代IPU是他们继续角逐这个市场的“资本”。
卢涛告诉记者,AI在未来会有更强的算力需求,持续推出性能强劲的处理器是必然的发展方向。而英伟达最新推出的A100在表现上相当惊艳。但他强调,Graphcore即将推出的使用7nm工艺打造的新一代IPU在性能上并不会输给英伟达的A100。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2344期内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
半导体股价|台积电|
NAND Flash
|晶体管
|
AI
|EDA
|中美|封装|射频
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!
责任编辑:Sophie