
通用型AI芯片突破“内存墙”瓶颈指日可待
2020-09-19
19:07:12
来源: 畅秋
点击
当下,人工智能(AI)产业正处于从起步向成熟阶段的过渡时期,相关应用也处于探索阶段,因此,各种专用的AI芯片层出不穷。然而,如果要针对某一个应用场景做ASIC化的产品,可能做出来的瞬间就已经落后了。另外,因应用所处环节不同,ASIC化并非完全不可行,例如在端侧的一个固定应用场景中,场景很明确就可通过ASIC的方式来做产品,但是,越靠近云端,应用变化越大,在这样的变化下很难部署某一ASIC化的处理器。无论是云端还是云边端,或者企业应用市场,都对算力要求非常高,因此,通用AI处理器就成为了更加合理的选择。
与专用AI芯片相比,通用型AI处理器的应用范围更加广阔,更代表着AI硬件的发展方向,在这一领域,当下最为流行的便是GPU和CPU了。
随着应用需求向更广和更深层面拓展,GPU在AI领域的应用遇到了越来越明显的瓶颈,首先,GPU和CPU属于传统处理器,并不是为AI计算专门设计的,在AI发展的初期阶段,它们能够胜任,但在接下来的第二、第三……发展阶段,在更为复杂的模型和技术面前,其计算架构局限性开始逐步体现出来。
正是在这种背景下,IPU出现了。该处理器是由英国初创企业Graphcore发明的,旨在支持机器智能的新计算需求。其第一代IPU中的1200多个处理器内核可以分别处理完全独立的任务,并且能够彼此通信以支持完整的多指令多数据并行操作。而这些正是下一代机器智能的基本要求。
日前在中关村论坛上,Graphcore联合创始人兼首席执行官Nigel Toon和Graphcore高级副总裁兼中国区总经理卢涛受邀出席,并分别在中关村论坛云上论坛和全球科技青年论坛上发表演讲。
据Graphcore联合创始人兼首席执行官Nigel Toon介绍,IPU在训练和部署中都可以支持具备高效稀疏计算的大型模型。IPU不仅可以推动创新开发,还可以有效部署这些新模型,更高效的计算可以降低系统总成本。用户可以在训练和推理中使用相同的IPU硬件,并且可以灵活更改每个CPU所调用的IPU数量。

图:Nigel Toon,Graphcore联合创始人兼首席执行官
总体来看,Graphcore的业务主要分为三部分:一,专为AI从零设计的IPU处理器;二 Poplar SDK和开发工具;三,IPU平台,例如IPU-Machine、可以通过浪潮和戴尔购买的IPU服务器,以及可大规模横向扩展的IPU-Pod64。
今年7月,Graphcore发布了第二代 IPU(Mk2 IPU),Mk2 IPU是一个基于台积电7nm制程技术的AI处理器,在823平方毫米的芯片上集成了594亿个晶体管。Mk2 IPU拥有250 TFLOPS的AI算力,以及900MB的处理器内存储容量。这样一个处理器里具有1472个独立的处理器核心以及将近9000个独立的并行处理器线程,相对于第一代IPU(Mk1 IPU),系统级性能提高了8倍以上。
该公司还新推出了IPU-Machine: M2000(IPU-M2000),这是一款纤巧的数据中心刀片,能够提供1 PFLOP的AI计算能力,并通过专用IPU内置了AI横向扩展网络架构IPU-Fabric。无论您是仅需要一台IPU-M2000的初创公司,还是希望将数千台IPU-M2000连接在一起的云公司,IPU-Machine:M2000(IPU-M2000)都可以满足您的需求。
技术亮点
与竞品相比,IPU在存储、通用性、软件支持和生态方面有诸多亮点。
在存储方面,GPU在进行AI计算时,使用的是HBM,它能够实现每秒1.6 TB的带宽和40 GB的容量。Graphcore则提出了一个创新的概念:IPU Exchange Memory。据Graphcore高级副总裁兼中国区总经理卢涛(Jason Lu)介绍:IPU Exchange Memory包含了片上存储和流存储,一个IPU-Machine:M2000的系统能提供每秒180 TB的带宽以及450 GB的容量,与GPU相比,在带宽和容量上都有非常大的提升。

图:卢涛(Jason Lu),Graphcore高级副总裁兼中国区总经理
具体来看,Graphcore提出的IPU Exchange Memory由两种存储构成,一种是处理器内存储(In-Processor Memory),就是片上存储,另外一种是流存储(Streaming Memory)。Mk2 IPU集成了900 MB的片上存储,而主流CPU的每个芯片上存储可能只有几十M。
与DDR或HBM相比,充足的片上存储能够提供50~100倍的带宽提升和时延的降低,Mk2 IPU中,存储和计算之间的距离大大缩短了。900 MB的片上存储和流存储使得大规模扩展成为可能。
CPU系统里面有一个MMU(内存管理单元,Memory Management Unit),其中有一个很重要的单位是TLB,TLB和外存之间能够进行Pageant操作。因为Mk2 IPU拥有900 MB的片上存储,可以通过远端的流存储来扩展几百GB的存储空间。而不需要像GPU或CPU那样,32 MB或者64 MB的片上存储需要不停地跟DDR,HBM做数据交互。
通过Mk2 IPU内片上存储和流存储技术相结合,IPU-M2000可获得总共450 GB的容量,片上存储带宽也获得了较大的提升。
对于与竞品的对比,卢涛提到了一个IPU的亮点,他表示:“NVIDIA声称他们构建的新数据格式TF32可以提高FP32算力。我们则认为,最标准的事情是最开放的,例如FP32是IEEE规定的数据格式,开发者能够基于FP32用GPU、IPU、CPU来进行计算,但如果开发者使用NVIDIA的TF32数据格式,就把自己困住了。”

在性价比比方面,IPU也有优势。卢涛用EfficientNet-B4的训练做了一个对比,如希望达到EfficientNet-B4在8个IPU-M2000的训练吞吐量,需要投资16个DGX A100,也就是超过300万美金的费用,外加相应的电费等其它花费。也就是说,如果使用DGX A100,为获取8个IPU-M2000的EfficientNet-B4计算性能,需要投入10倍以上的花费。
在软件和开发环境支持方面,Graphcore从零设计了以计算图(Graph)为核心的Poplar SDK,能够方便用户不论是使用单个IPU-M2000,还是单张PCIe卡,乃至1000个,甚至上万个IPU,都能获得完全一致的用户体验。Poplar SDK向上对接TensorFlow、PyTorch、ONNX、PaddlePaddle等行业标准机器学习框架。
今年7月,Graphcore开放了PopLibs源代码。卢涛表示:“Graphcore精神的一部分是将权力交给AI开发人员,方便他们自己进行修改、优化、创新。同时,Graphcore也在大力发展IPU开发者社区,其中很重要的一部分是已经在中国上线的IPU开发者云,可提供浪潮IPU服务器NF5568M5、戴尔IPU服务器DSS8440、以及IPU-Pod64等不同机型。IPU开发者云目前已经开放申请使用了。
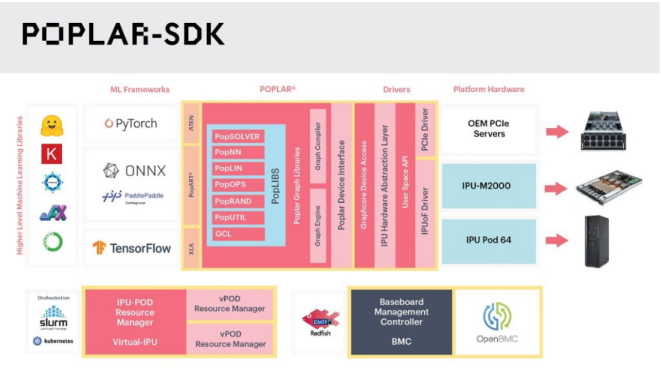
开发者能够非常便捷地获取IPU,主要有两种方式:一是通过云,目前可以通过微软Azure和金山云来获取IPU;二是通过戴尔或浪潮的IPU服务器构建用户自己的私有云或自己预置的计算资源。
谈到开放性和创新性,卢涛表示:“Graphcore的IPU平台,无论IPU-M2000还是IPU-Pod64,在设计过程中都考虑到了芯片、系统、集群及软硬件结合的问题。Graphcore致力于赋能AI创新者进行新突破,如果仅仅沿着GPU的路线走,只能通过有限的方式来进行一些尝试。所以,为创新者、开发者、研究者提供支持是Graphcore研发的重要动力。如果是由于硬件桎梏导致您的优秀作品无法达到理想性能,Graphcore欢迎开发者在IPU上进行探索和尝试。”
客户
谈到IPU的应用,卢涛表示,目前,IPU在超大规模数据中心与互联网、高校及研究机构、医疗及生命科学、金融、汽车这五大领域中发展较快,也受到了很多关注。到目前为止,Graphcore共发货IPU处理器超过一万颗,服务全球100多家不同机构。
“我们的一位早期客户,Carmot Capital在使用我们的产品训练其金融市场预测模型时,性能提升了26倍。”卢涛说,”微软在使用IPU帮助诊断肺炎和COVID-19的胸部X光影像时,速度提高了10倍,且准确性大大超过GPU。“

微软是Graphcore的早期的合作者,他们不仅将IPU技术用于其内部AI工作负载,还在2019年11月将IPU提供给其Azure云计算平台的用户使用,从而加速了AI创新者的工作。
另外,微软、宝马、博世、戴尔和三星等许多了解创新与应用之间关系的公司,都对Graphcore进行了投资。
中国业务
对于中国市场,Nigel Toon直言:“新技术的最直接需求就在中国。中国在人工智能领域处于领先地位,中国认识到,人工智能创新与长远经济发展密不可分。目前,Graphcore的技术已经开始为一些非常成功的中国公司提供支持,并将助力推动中国那些发展最快、最具创新性的AI初创企业。不久以后,我们将能够更多地谈论一些Graphcore在中国的合作伙伴,并分享我们合作的细节。“
Graphcore的中文名定为“拟未”,该公司正在壮大中国团队,以便为客户提供完全本地化的响应和支持。Nigel Toon表示:“我们的目标是将拟未打造成一家重要的中国公司。”
中国高校合作方面,在IPU开发者云上线之后,Graphcore大概收到了三、四十所高校的顶尖AI实验室和研究机构的使用申请。Graphcore已开始与一部分机构探讨合作,有一些机构已在IPU开发者云上开展工作。
应用场景方面,卢涛认为中国市场在自然语言处理相关的应用方面发展非常迅速,且潜力巨大,对训练的算力要求也非常高,这对IPU而言非常重要。
责任编辑:sophie





-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 新品首秀 | Bosch Sensortec 携两款最新传感器解决方案亮相Sensor Shenzhen
- 2 创新·互联·芯生态 | 2024半导体产业发展趋势大会暨颁奖盛典圆满举办
- 3 华强电子网携手腾讯企点重磅发布电子行业解决方案——芯采通
- 4 持续赋能专用计算,芯易荟EDA技术市场双突破
- 5 SEMI-e深圳国际半导体展6月袭来 规模再升级 参展企业超800家
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号