来源:内容由半导体行业观察(ID:icbank)编译自「
thenextplatform
」,谢谢。
如果您想摆脱Intel Xeon SP处理器在数据中心的控制,可以采用多种方法。您可以领先英特尔进入其核心市场,就像AMD在Epyc系列处理器上所做的那样,充分利用其设计和代工伙伴。另一种方法是完全改变游戏的性质。这就是Marvell想要做的事情。
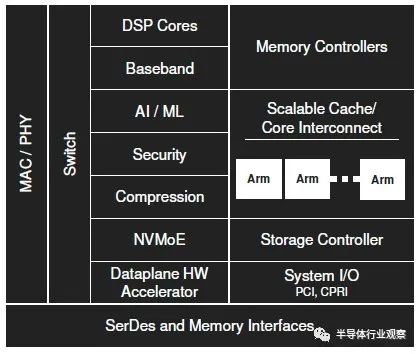
Marvell是一家成立于二十五年半前的芯片企业,目前该公司拥有5,000多名员工,在截至2月的2020财年中,公司收入达到27亿美元。Marvell采取的是略有不同的方法,他们不是为每个客户打造可能需要的SKU,并尝试从中获得收益。而是凭借数十年的制造存储控制器,网络处理器和其他网络芯片的经验,加上公司于2017年11月收购了Cavium,并涉足Arm服务器处理器(ThunderX),交换ASIC(XPliant和Prestera)和其他设备。
近年来购买了一大堆资产的Marvell,现在正着手进行大规模定制芯片。
从本质上讲,它的所有知识产权(在过去的二十年中已积累了10,000多项专利)及其在设计芯片,封装并通过非英特尔代工厂(台积电,GlobalFoundries和三星)获得的所有技能,能帮助他们打造出很好的成品。
在多个代工厂之间进行合作非常重要,因为在推进先进工艺方面,不仅仅是英特尔遇到了麻烦。GlobalFoundries在7纳米也失败了——这大约相当于使英特尔非常痛苦的10纳米工艺,而前者在两年多以前就放弃了7nm。三星凭借其在内存和闪存业务以及用于消费类设备的Arm芯片上的耕耘,是的公司在先进的工艺技术方面毫不逊色。
三星是先进工艺市场位数不多的竞争者,同时还是IBM Power10和z16服务器芯片的代工合作伙伴。蓝色巨头希望凭借其技能从边缘迁移回核心数据中心。
Marvell不能凭自己的能力成为一家晶圆代工厂,因为考虑到如今建造晶圆厂的成本(远超过100亿美元),还有他们也不具备如此庞大的产能。但它可以将自己定位为三个独立晶圆厂的专家。而且,在Marvell以6.5亿美元的价格收购Avera Semiconductor,一家源自于IBM Microelectronics和GlobalFoundries的芯片设计团队。
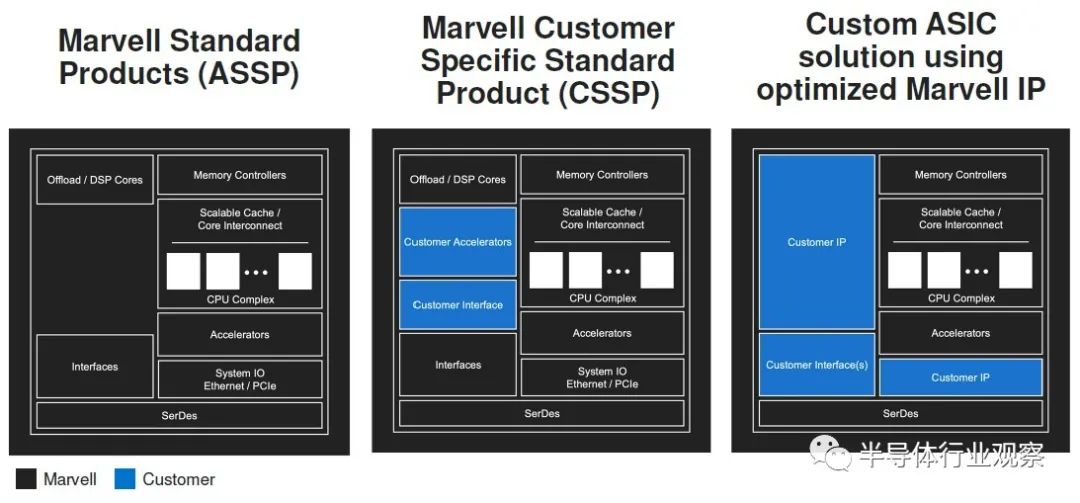
现在的Marvell拥有的芯片产品组合可以授权给客户,并且他们还有能力帮助其他将自己的芯片从白板转移到系统中的。
成立于1995年Marvell位于Intel圣塔克拉拉(Santa Clara)的沿途,在相对较短的时间内取得了长足的发展,成为数据中心和边缘市场的参与者。在网络泡沫最严重的时期,Marvell上市并筹集了9000万美元,其股票在2000年秋季过高,以至于可以交易其中的27亿美元收购Galileo Technology,并进入以太网交换机和嵌入式控制器市场。
从那时起,Marvell在其某些芯片设计中就包含了CPU,并在2003年收购了Asica,后者基于Arm架构创建自己的芯片,并获得Arm Holdings的架构许可,这意味着它可以调整核心设计,只要不破坏与Arm指令集的兼容性。Marvell设计了整个2000年代的几代Arm芯片,用于各种嵌入式和消费类设备,甚至在2006年7月以6亿美元的价格收购了Intel的XScale Arm芯片业务。
1990年代后期。这两条生产线是Armada Arm芯片生产线的基础,Armada生产线偶尔会用于各种设备,包括服务器。在2018年7月,它在2011年9月以37亿美元收购的NetLogic多核MIPS芯片。有趣的是,ThunderX2与NetLogic基础的共同点比与Octeon基础的共同点更多,但它们的根源也相似。
所有的这些都证明Marvell在创建适用于数据中心和边缘的芯片方面拥有广泛而深刻的经验。Marvell ASIC业务部门的首席技术官Igor Arsovski也告诉The Next Platform,该公司的设计团队(其中包括来自原始Marvell的人员以及来自Cavium,GlobalFoundries和IBM的人员)仅在企业和网络领域就流片超过2,000款芯片。(自1994年以来一直销售定制ASIC的IBM Microelectronics是这种经验的重要组成部分。)这是一个非常深厚的基础,这也是AI芯片初创公司Groq在其新推出的Tensor流处理器( TSP100)上与Marvell合作的原因。
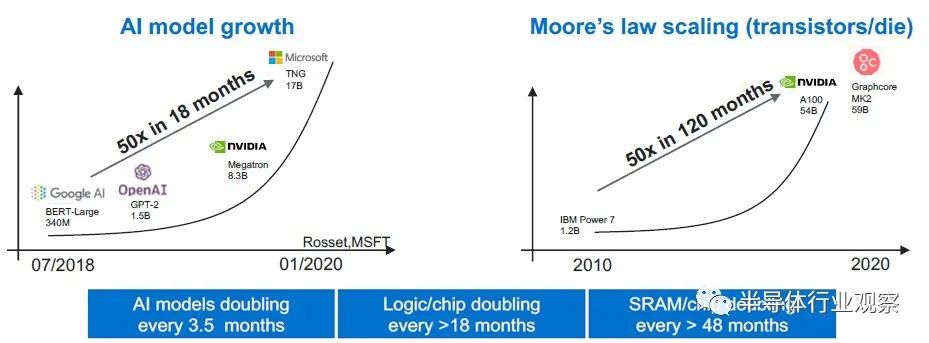
Arsovski为我们提供了一个水平,可以确切地说明世界上AI芯片制造商所面临的挑战。看一看:
简而言之,这些图表说明了为什么对于像计算机学习训练这样的计算和内存带宽密集型的应用程序都必须使用加速器。
“客制化芯片的这种趋势正在增长,推动其发展的是模型的复杂性,” Arsovski解释说。“在过去的18个月中,AI模型的复杂度实际上增加了50倍,如果您查看实现50倍晶体管缩放所需的时间,那么您所花的时间约为120个月或10年。这接近7倍的差距。如果您看一下Dennard标度和摩尔定律的辉煌年代,我们每18个月就会翻一番,但现在我们放慢了更多。”
事实证明,当谈到SRAM片上存储器时,这种减慢尤其严重,它被用作高速缓存,有时还用作设备中的主存储器(例如在许多AI加速器中)。设计来自IBM的SRAM。如果您停留在高级制程节点上,则大约需要五年时间才能使每平方毫米的SRAM数量增加一倍。几乎所有不基于GPU设计的AI加速器旁边都有巨大的SRAM块以及矩阵和矢量数学单元,或者它们现在或将来都可能具有某种高带宽内存。基于虚拟计算引擎本质上的叠加层的FPGA AI加速器设计使用与计算紧邻的逻辑实现的Block RAM(BRAM),其方式几乎相同。
鉴于上述Arsovski所说的以及摩尔定律的总体放缓,每个人都将寻找某种GDDR或HBM或HMC存储器来封装其未来的AI计算设备,因为没有办法实现SRAM规模不论节点如何,其运行速度与任何设备上的计算速度相同。
实际上,我们认为计算有很大机会保留在多芯片模块的更高良率部分上,并且将使用最先进的节点来蚀刻SRAM存储器,但前提是两者之间的连接可以实现非常低的延迟和非常高的带宽。正如Arsovski所提醒我们的那样,从任何die到memory,带宽会下降大约两个数量级。话虽如此,Marvell已与美光科技合作,将其Hybrid Memory Cube存储器与TSV集成在一起,以3D堆叠式封装进行计算。当SRAM密度开始耗尽时,这是AI加速器设计的一条可能途径。
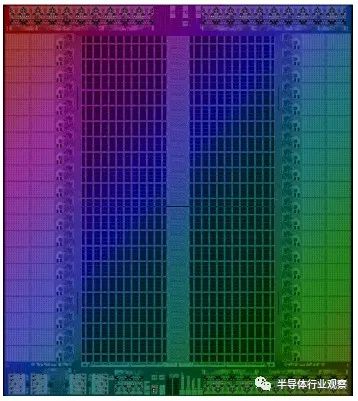
根据Arsovski的说法,Groq选择Marvell作为其TSP加速器的设计合作伙伴是有原因的,而SRAM是这一原因的重要组成部分。Groq希望使用成熟的14纳米或16纳米工艺来提高产量并降低其首个芯片的风险,并且IBM拥有在GlobalFoundries设计14纳米工艺的Power9服务器CPU的经验,因此非常适合,因为它在整个芯片上具有220 MB的SRAM:
TSP 100芯片的面积超过700平方毫米,如您所见,它以中心的巨大SRAM块为主导。有一个“东岸”和“西岸”,每个都有44个独立的存储区,该SRAM上的组合带宽惊人,高达27.5 TB /秒。Nvidia“ Ampere” A100 GPU加速器上的HBM2带宽为1.55 TB /秒,并且该内存与GPU内核之间存在延迟,正如Arsovski指出的那样,比片上SRAM延迟大几个数量级。
Arsovski表示,得益于Avera的收购,Marvell可以为Groq带来的SRAM比其他使用14纳米或同等16纳米技术的设计师所能提供的SRAM密度高10%到15%(每平方毫米11兆位)。而且,Groq TSP 100中的SRAM是两个以1.2 GHz运行的端口,因此它的带宽是单端口SRAM实现的两倍,因此带宽比其他设计要大得多。
Marvell和Groq之间的伙伴关系不仅与SRAM有关。Marvell还拥有高速SerDes以及Groq可以利用的交钥匙式的PCI-Express和芯片到芯片互连(chip-to-chip:C2)子系统,最重要的是,Marvell拥有专业知识,可以提供良率高、效率高的芯片。这是Groq本身并没有的经验。
当然,硬件将更像软件,这一直是梦想。但这不一定意味着是因为可编程逻辑。我们相信,随着时间的推移,计算引擎将在socket level 变得更加昂贵,因为它们将不得不包含小芯片架构,并且由于摩尔定律的放慢,它们有时会部署reticle-busting方法。而且由于计算引擎将针对工作负载进行非常专门的调整,因此有必要在较小的运行中对其进行蚀刻,并在它们从铸造厂出来时进行封装,这也增加了成本。
但我们也相信,暗硅将很少,并且它们将以高利用率运行,因此,器件的实际价格/性能仍将遵循大致近似于摩尔定律的曲线。使用所有可用的工具和技术对计算引擎进行快速迭代将使进度不断发展。那些无法快速迭代并找到并保持客户移动的人将被甩在后面。
这就是Marvell的赌注,实际上也是Intel和TSMC,GlobalFoundries和Samsung的赌注。
人们有时会忘记并非世界上的每个设备都必须使用最先进的节点。公平地讲,许多最酷的设备都用最小的晶体管,但这并不是当今世界中价格/性能最重要且共同设计的硬件和软件允许每个晶体管做有用的事情的先决条件。
为了更好地处理Marvell为芯片设计人员准备的大规模定制业务,该业务将其全部知识产权以及硬件工程师的全部资产供他们使用,我们与Marvell ASIC业务的总经理Kevin O'Buckley进行了交谈。和Arsovski一样,他是一位IBM老员工,在蓝色巨人将其芯片业务出售给前AMD芯片代工厂之后,他在GlobalFoundries任职。O'Buckley在IBM Microelectronics中名列前茅,在网络泡沫时代和萧条时期致力于铜缆和SOI流程,然后在90年代领导开发用于游戏机和超级计算机的Cell混合CPU-GPU处理器。随后,O'Buckley也负责了22nm和14nm工艺,甚至7nm工艺的开发。
如果有一个人能理解芯片设计师对代工厂的依赖,而又想打破这种依赖以降低将芯片推向市场的风险,那这个人就是O'Buckley。这就是为什么Marvell组成了一个团队,他们了解GlobalFoundries的22纳米,14纳米和12纳米工艺,TSMC 7纳米和5纳米工艺。看到三星7纳米和5纳米工艺方面的一些专业知识也涌现,我们并不感到惊讶。
除非英特尔将其代工厂商放在一起,否则我们不会在这里进行太多合作,如果有的话,看到英特尔尝试收购Marvell将会很有趣。(但这又是一个疯狂的想法……)
正如我们在上面指出的那样,Marvell积累了大量的产品线和技术。
Marvell所不拥有的产品线是FPGA。这可以通过收购Achronix或Lattice Semiconductor来实现,以充实自己的产品组合。但他们更有可能的做法似乎是与这两家公司和Xilinx合作,将FPGA功能纳入其堆栈。
O'Buckley表示,Marvell实际上正在与客户讨论包含FPGA元件的定制芯片,像我们一样,他相信未来将更加重视FPGA,因为必须通过多种方式对软件和硬件进行严格调整ASIC并不总是答案。
现在,Marvell不仅收购了Avera,而且还收购了Aquantia,以充实其汽车网络实力,这是它可以为客户提供的定制范围,从Marvell完全设计的标准产品(例如Octeon或ThunderX芯片,到使用Marvell IP的半定制芯片。
这种定制不适用于当今的所有人,Marvell知道这一点。“从收入的角度来看,可能有20%或更多的市场需要某种定制的芯片” O'Buckley告诉我们,当提出一个预想的数字时。“半导体行业购买的大多数产品将继续购买标准产品。这实际上是规模和金钱的问题。即使是最低限度的定制,您也要在这些产品上投资数百万美元。”
举个例子,IBM有100多名工程师致力于为游戏机定制Cell处理器。这并不便宜,但是微软,索尼和任天堂从IBM那里获得了他们需要的东西,就像今天从AMD获得一样。也许将来他们将依赖于Marvell。
有趣的是,Marvell正在服用一些自己的“半定制药”。在其“ Triton” ThunderX3处理器上,Marvell不会进行完整的SKU堆栈和大规模发布。而是,鉴于尚未有更广泛的Arm处理器企业用户市场出现,而且相对而言(数量,而不是支出)超级扩展程序,云生成器和HPC客户相对较少,他们希望进行独特的自定义,因此Marvell会处理ThunderX3作为半定制芯片,可以直接通过合作销售。
但是不要误解,Marvell绝对相信,未来将有更广阔的Arm服务器芯片市场,只是今天还没有。
也许,服务器计算的未来将比今天的英特尔至强SP服务器芯片业务更像游戏主机芯片定制业务。那是我们的赌注。在那个世界上,英伟达购买Arm Holdings毫无疑问是很有意义的。
★
点击文末【阅读原文】,可查看
本文原链接
。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2448期内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|IP
|
SiC|并购|射频|台积电|Nvidia|苹果
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!