
Chiplet的现状与挑战
来源:作者:Tao Li, Jie Hou, Jinli Yan, Rulin Liu, Hui Yang, Zhigang Sun,谢谢。
Chiplet异构集成技术通过利用先进封装技术将多个异构芯片裸片(Die)整合集成为特定功能的系统芯片,试图缓解摩尔定律和登纳德缩放定律所面临的的失效问题。
作为一种芯片级IP整合重用技术,Chiplet技术近年来受到广泛的关注。与传统的单芯片(Monolithic ASICs)集成方式相比,Chiplet异构集成技术在芯片性能功耗优化、成本以及商业模式多方面具有优势和潜力,为CPU、FPGA以及网络芯片等多领域芯片的研制提供了一种高效能、低成本的实现方式。
Chiplet技术涉及的互连、封装以及EDA等关键技术和标准逐渐成为学术界和工业界的研究热点。本文对Chiplet异构集成技术的概念与原理、技术优势以及挑战进行了详细的总结和对比,并对其应用与未来发展趋势进行了讨论。
引言
超大规模集成电路生产制造技术经过几十年的迅猛发展,已经成为支撑信息化社会不断发展演进的支柱。在信息系统中广泛应用的各类芯片常依赖于IC工艺制程的升级以实现其性能提升和功耗优化。目前,IC制造可量产工艺已达到7nm,并向5nm及3nm推进。然而,随着IC工艺制程的复杂度急剧攀升,相应的流片成本也在急剧增加,7nm工艺单次全掩模流片甚至超过10亿元人民币,对多领域芯片的设计实现带来巨大挑战。
此外,摩尔定律和登纳德缩放定律的放缓和停滞更加剧了这一问题。摩尔定律在2000年后呈现出放缓的迹象,到2018年,摩尔定律预测与芯片实际能力的差距大约是15倍。登纳德缩放比例定律在2007年开始显著放缓,到2012年几乎失效,通过IC工艺制程升级带来芯片性能及功耗提升的性价比越来越低。工业界及学术界普遍认为“超摩尔时代”和“后摩尔时代”将很快来临。
在上述背景下,Chiplet(又称小芯片或芯粒)异构集成技术作为可能破解上述问题的关键技术获得广泛关注。Chiplet技术,试图通过将多个可模块化芯片(主要形态为裸片(Die))通过内部互联技术集成在一个封装内,构成专用功能异构芯片,从而解决芯片研制涉及的规模、研制成本以及周期等方面的问题。通过采用2.5D、3D等高级封装技术,Chiplet可以实现高性能多芯片片上互连,提高芯片系统的集成度,扩展其性能、功耗优化空间。此外,模块化集成方式可以有效提高芯片的研发速度,降低研发成本和芯片研制门槛,可以使得芯片研发聚焦于算法和核心技术,提高行业整体创新水平和能力。
与传统的单芯片集成方式相比,Chiplet异构集成技术在多方面具有优势和潜力,但其发展成熟和广泛应用也面临诸多挑战。异构集成系统需要统一的接口和标准,而多样化异构芯片的互连接口及标准的制定不仅仅在技术方面会面临性能和灵活性平衡的困难,在市场生态方面也面临主导权竞争等多方面的不利因素。此外,Chiplet异构集成技术所依赖的封装技术也面临在性能、功耗以及成本等方面的要求和挑战。支持Chiplet芯片设计、实现的全套EDA工具链以及生态是否完善,是否可持续发展,也是Chiplet技术成功所需要面临解决的关键问题。
目前,Chiplet异构集成技术在工业界,尤其是具有较高技术水平和研发实力的公司,已有部分成功应用。HBM存储器是Chiplet技术早期成功应用的典型代表。此后,在FPGA领域,英特尔公司推出了基于Chiplet技术的Agilex FPGA家族产品,利用3D封装技术实现异构芯片集成。在高性能CPU芯片领域,AMD推出了其Zen 2架构,该架构将IO部件和处理器核心分离成多个不同工艺(7nm和14nm等)小芯片,以按需组合集成。在网络领域,英特尔公司 (原Barefoot)Tofino 2 12.8T的交换芯片采用交换逻辑芯片与高速Serdes接口模块芯片组合的Chiplet方式实现。在学术界,美国加州大学、乔治亚理工大学以及欧洲的研究机构近年也逐渐开始针对Chiplet技术涉及到的互连接口、封装以及应用等问题开始展开研究。
值得注意的是,上述研究更多集中在独立产品或局部技术上,而美国国防部高级研究计划局(DARPA)2017年推出的CHIPS战略计划(通用异构集成和IP重用战略)则试图将Chiplet技术推上战略统一和生态构建的层面。DARPA瞄准Chiplet这一技术趋势,试图构建围绕和利用Chiplet技术的一系列生态及应用,从而将Chiplet技术推到了另一高度。
Chiplet异构集成技术受到的关注度与日剧增,但Chiplet技术相关的综述性文章较为缺乏。本文试图针对Chiplet技术已有的研究和应用成果进行梳理分析并对Chiplet技术未来发展趋势提出展望,从而为从事研究下一代芯片研究和设计的学者及工业界人士提供借鉴和参考。
Chiplet技术概述
传统上,芯片的迭代开发通常有两种方式,主流方式是直接利用新一代IC工艺制程开发新的芯片,实现处理能力、带宽、主频等性能提升和新功能的集成;为了降低开发成本和周期,也可利用原有工艺节点实现新增功能,并在下一代工艺上将原有芯片和新功能芯片整合到单片实现。在摩尔定律和登纳德缩放定律有效的早期,上述方式不仅可以获得频率的提升,还可以通过高级工艺制程更小的特征尺寸实现功耗、面积等方面的优化。
然而,随着芯片制程的演进,由于设计实现难度更高,流程更加复杂,芯片全流程设计成本大幅增加。根据国际商务战略公司(IBS)调查数据显示,22nm制程之后每代技术设计成本(包括EDA、设计验证、IP核、流片等)增加均超过50%,7nm总设计成本约3亿美元,预计3nm工艺成本将增加5倍,达到15亿美元。这使得基于工艺改进实现高性能芯片的升级换代战略的难度不断增大,性价比不断降低。此外,良率、光刻机光罩尺寸等方面的技术限制,也使得在新工艺节点实现功能性能持续升级扩展的单片集成方式,也逐渐变得不可持续。
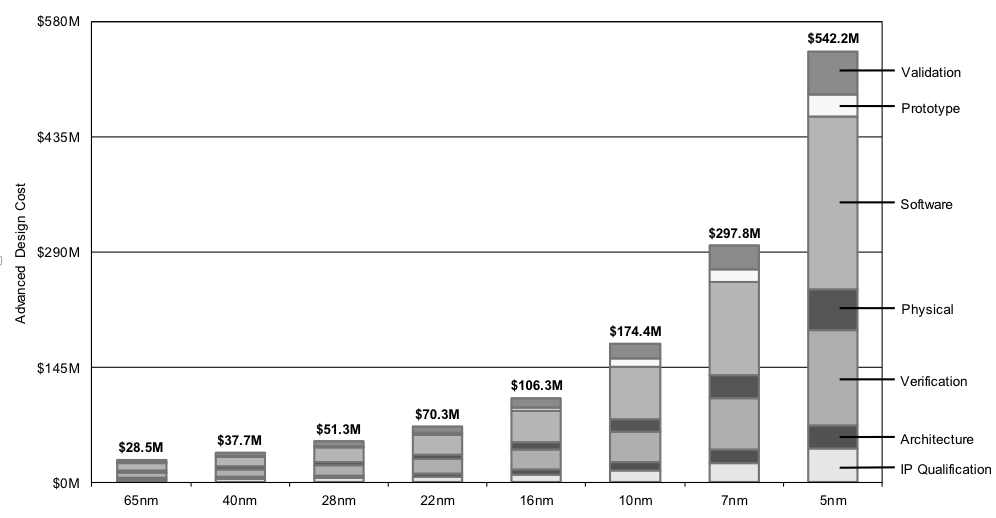
图1 不同工艺节点的芯片设计制造成本:数据来源IBS
在此情况下,Chiplet芯片异构集成技术成为未来芯片设计的一种可行途径。实际上,在上世纪八十年代出现的多芯片模块封装技术(Multi-Chip Modules,MCMs)就已体现了Chiplet的技术概念。MCM技术通过将多个芯片在基板等介质上连接以满足满足功能性能需求的复杂系统芯片。MCM技术可以减少板级互连等开销,降低板级系统设计复杂度,显著降低系统构建成本。近几年,英特尔公司、AMD等公司基于MCM技术已开发出系列化高性能芯片产品。然而,MCM技术更聚焦底层封装技术,未考虑到芯片系统异构集成的多层次互连标准、接口、工具以及生态等芯片模块化复用所需要解决的高层次问题。
2017年,美国国防部高级研究计划局(DARPA)在“电子复兴计划”中规划了“通用异构集成和IP重用战略”(CHIPS)”项目试图发动工业界和学术界力量共同解决上述问题,参与方不仅有系统集成厂商洛克希德·马丁、诺斯罗普·格鲁曼公司、波音,英特尔、美光等芯片厂商以及Cadence,Synopsys等EDA厂商,还包括密歇根大学,乔治亚理工学院和北卡罗来纳州立大学等科研机构。该项目的重点在于开发一种新的技术框架,该框架中将包含不同的功能的芯片裸片(Die)混合、匹配和组合到中介层上,从而可以更轻松地以更低的成本集成到芯片系统中,从而有效增强芯片系统整体灵活性并减少下一代产品的设计时间。
Facebook等公司推动的开放计算项目(Open Computer Project, OCP)也在2018年末积极启动了开放领域特定架构(Open Domain-Specific Architecture, ODSA)研究,试图开发完整体系结构的接口栈,创建一个Chiplet的开放市场,通过定义开放的标准化接口,使得Chiplet芯片中集成的裸片可以互操作,以支持不同供应商的裸片自由组合,构建更为灵活的芯片系统。
为达到上述目标,物理层、链路层及网络层全栈可行的互连接口规范和标准、配套的先进芯片封装技术、面向良率良率额的EDA等软件工具链的研发以及行业的典型应用将是Chiplet技术发展成熟所需着手解决的重要问题。
Chiplet技术的优势
与传统PCB板集成以及单片ASIC集成方式相比,Chiplet异构集成技术的优势主要体现在技术、成本以及商业方面。
在技术优化方面,通过多个小芯片的灵活重组,可提供较大的性能功耗优化空间,从而有效支持面向特定领域的灵活定制,缓解摩尔定律放缓带来的影响,满足多样化芯片研制需求。例如,对于提供高密度高速接口为特征的网络芯片,高速Serdes 对芯片的功耗排布要求较高。而采用Chiplet技术将网络芯片高速Serdes IO模块与核心逻辑分离,可以提供更多针对功耗优化的布局选择,这也是英特尔公司可编程交换芯片Tofino2采用Chiplet技术的一个重要原因。此外,对于高性能CPU以及AI芯片,访存带宽通常是性能瓶颈,通过Chiplet技术将处理器核心和存储芯片通过3D堆叠技术等进行组合封装,可以有效提升信号传输质量和带宽,在一定程度上缓解“存储墙”问题,这也是AMD和英特尔公司较早关注和采用Chiplet技术的关键。
在研制成本方面,Chiplet芯片一般采用先进的封装工艺,将小芯片组合代替形成一个大的单片芯片。利用小芯片(具有相对低的面积开销)的低工艺和高良率可以获得有效降低成本开销。除芯片流片制造成本外,研发成本也逐渐占据芯片成本的重要组成部分,通过采用已知合格(Known Good Die,KGD)裸片进行组合,可以有效缩短芯片的研发周期及节省研发投入。AMD采用Chiplet技术研制的EPYC CPU将32核CPU的开发和制造成本降低高达40%。此外,大规模高性能芯片,尤其是商用芯片,在采用传统单片集成方式时,通常通过多次硅验证才能改进成熟并投放市场,从而导致较大的研发成本压力。而Chiplet芯片通常集成应用较为广泛和成熟的芯片裸片,可以有效降低了Chiplet芯片的研制风险,从而减少重新流片及封装的次数,有效节省成本。
在商业方面,Chiplet技术可以有效提高芯片的研发速度,降低研发成本和壁垒,从而使得科研和商业机构可以更加专注核心算法及技术的攻关,有力推动技术创新。另一方面,Chiplet技术生态的不断演进完善将催生新的产业。在Chiplet技术商业模式中可能会催生三类商业角色,包括供应Chiplet模块芯片的Chiplet供应商、将Chiplet模块芯片集成组合形成系统能力的Chiplet集成商,以及进行工具链和设计自动化支持服务的EDA软件提供商。目前,英特尔公司、美光等公司已开始承载了产业链中的部分角色,而zGlue等初创公司则着重试图打通Chiplet产业链的缺失环节。
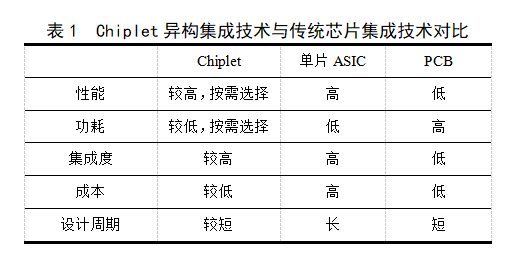
表1给出了Chiplet技术与传统技术的对比,在性能、功耗及集成度等方面接近单片ASIC,而在成本及设计周期等方面则与传统具备优势的PCB技术差距较小。由此可见,Chiplet技术是单片ASIC和PCB技术的良好折中,发展潜力巨大。
Chiplet技术面临的挑战
Chiplet技术虽然具有诸多优势,但其发展成熟至可广泛应用仍面临来自互连接口与协议、封装技术以及质量控制等方面挑战。
互连接口与协议
Chiplet各裸片的互连接口和协议对于Chiplet技术十分关键,其设计必须考虑与工艺制程及封装技术的适配、系统集成及扩展等要求,还需满足不同领域Chiplet集成对单位面积传输带宽、每比特功耗等性能指标的要求。通常,上述指标要求通常是相互矛盾的,从而给Chiplet互连接口与协议的设计带来较大挑战。
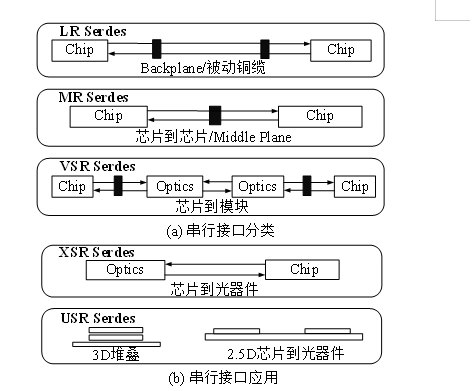
图2 主要串行接口分类与应用
参考OSI网络通信层次模型,Chiplet互连接口与协议可以划分为物理层(PHY层)、数据链路层、网络层以及传输层。目前在研的互连接口及协议更多集中在物理层,其与工艺、功耗以及性能紧密相关,链路层及以上接口更多依赖沿用或扩展已有接口标准及协议。
物理层(PHY层)
可用于Chiplet技术物理层互连的接口可以分为串行接口及并行接口两大类。
a)串行接口
从应用的传输距离角度,串行接口主要包括长/中/短距Serdes(LR/MR/VSR Serdes)、特短距XSR Serdes和超短距USR Serdes,图2给出了几类接口的主要应用场景。
LR/MR/VSR(Middle Reach/Long Reach/Very Short)Serdes通常用于芯片间以及芯片与模块间通过PCB板连接,广泛用于实现PCI-E、以太网、RapidIO等通信接口。这一类接口的主要优势是成熟可靠、传输距离长、低成本且易于集成。然而,由于在功耗、面积以及延迟方面不具优势,难以支撑对上述指标敏感的高性能Chiplet芯片的构建。
特短距XSR(Extra Short Reach)Serdes针对裸片间(Die-to-Die,D2D)及裸片-光器件间(Die-to-Optical Engine,D2OE)间互连定义的Serdes标准。XSR设计更着重于面向芯片与光器件间的互连,采用集成了时钟数据恢复电路(CDR)的传统Serdes结构,对插损开销要求更为严格。为达到更低的误码率,需要集成复杂的前向纠错(FEC)机制,因此会引入显著的延迟和功耗,当带宽达到112G或更高时,信号反射带来的开销会使得这种情况更加恶化。此外,为了支持良好的信号完整性,需要更高性能的芯片制造工艺和封装基板材料来支持大规模集成。XSR更适合部署在具备端到端FEC的裸片与光器件间。
与XSR相比,USR(Ultra Short Range)Serdes的设计更专注于利用2.5D/3D封装技术实现Chiplet芯片内裸片到裸片的极短距离(10mm级别)高速互连通信。由于通信距离短,USR可以利用高级编码、多比特传输等先进技术提供更高效的解决方案,实现更好的性能功耗比,并具有更好的可扩展性。例如,Kandou公司利用CNRZ-5编码实现的Glasswing 112G USR Serdes可以达到0.72pJ/bit,224G Serdes可以实现0.8pJ/bit的每比特功耗。由于USR接口的实现通常涉及相关专利技术(例如编码方式),其互操作兼容性面临较大挑战。此外,USR对传输距离的要求制约大规模的Chiplet芯片集成。
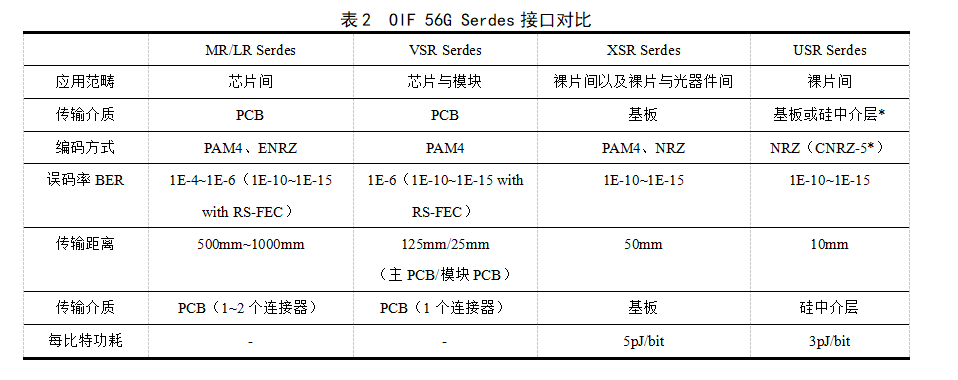
根据OIF定义的56G Serdes接口规范,表2给出了不同类型接口在传输、应用等方面特性的对比分析。
b)并行接口
目前可用于Chiplet裸片互连的通用并行接口主要有英特尔公司的AIB/MDIO、TSMC的LIPINCON以及OCP的BoW等。HBM接口也属于此类接口,但主要专用于高带宽存储器互连。
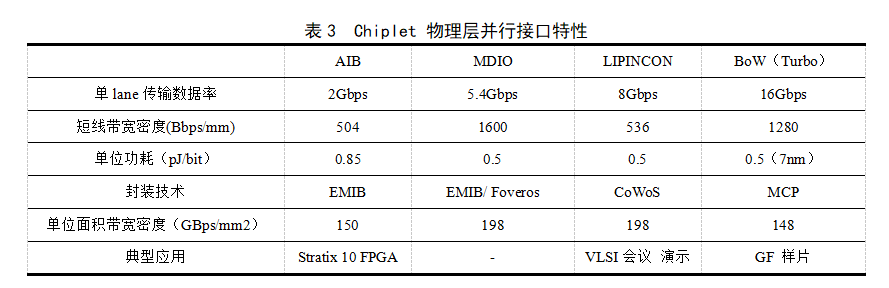
AIB高级接口总线(Advanced Interface Bus)类似DDR DRAM接口,是英特尔提出的物理层并行互连标准。在DARPA的CHIPS项目中,英特尔免费提供AIB接口许可给相关厂商,以支持广泛的Chiplet生态系统。MDIO作为AIB的升级版本,可以提供更高的传输效率,响应速度和带宽密度可以达到AIB的两倍以上。AIB以及MDIO技术主要适用于通信距离短和损耗低的2.5D及3D封装技术,例如EMIB、Foveros等。
LIPINCON是台积电针对Chiplet设计提出的一种高性能互连接口。通过利用InFO及CoWoS等高级的硅基互连封装技术,并采用时序补偿技术,LIPINCON可以在不使用PLL/DLL的同时较低功耗和面积开销。LIPINCON接口包括两种PHY类型:PHYC用于SoC裸片,PHYM用于存储及收发器类裸片。
BoW 接口由OCP ODSA组设计提出,着重面向解决基于有机基板的并行互连问题。BoW定义了三种类型,即BoW-Base、BoW-Fast和BoW-Turbo。
BoW-Base面向10mm以下传输距离,采用非端接的单向接口,每线数据传输率可达4Gbps;BoW-Fast可以支持走线长度到50mm,采用端接接口,支持每线16Gbps传输速率;与BoW-Fast相比,BoW-Turbo采用双线支持双向16Gbps传输。BoW支持后向兼容,对芯片工艺制程和封装技术限制较少,不依赖高级硅基互连封装技术,具有较为广泛的应用范围。
表3给出了上述Chiplet物理层并行接口在封装、传输速率、带宽密度等方面特性对比。
值得注意的是,上述先进的电信号物理层接口已达到较低的每比特数据传输功耗。然而,随着高性能网络、计算等应用迅猛增长的带宽需求,数据传输带来的功耗增长仍是芯片研制所面临的重要挑战。Mark Wade等人提出采用光电混合技术解决I/O瓶颈问题,为Chiplet未来高性能低功耗互连技术和标准的发展提供了新的思路。
上述各接口标准都着重面向优化Chiplet特定互连需求设计,最优的Chiplet互连解决方案与具体应用相关。并行接口虽然可以提供低功耗、低延迟和高带宽,但需要更多的布线资源;串行接口所需布线资源较少,但是会带来更多的功耗和延迟。因此,Chiplet芯片设计者必须根据实际应用需求、约束以及裸片特性选择合适的一种或多种物理层接口达到系统优化的目标。
链路层及以上
可用于构建Chiplet系统的链路层及以上接口标准主要有PIPE、CCIX、Tilelink以及ISF等。
PIPE接口标准由英特尔公司在2002年定义,之后作为PCIe规范的一部分被不断更新。PIPE接口可以作为一种通用的物理层和数据链路层的接口,用于屏蔽上述多样化PHY接口的差异,为上层提供统一的抽象。
原则上,传统的数据链路层接口标准(例如以太网MAC、PCIe等)通过和底层的PHY适配,都可以用于Chiplet的链路层传输。由于开源开放性,Tilelink接口协议目前受到较为广泛的关注。其试图将片上网络以及Cache控制器的实现与Cache一致性协议本身解耦。遵循Tilelink事务结构的任何Cache一致性协议可以和任意物理层网络以及Cache控制器结合使用。CCIX接口标准是面向芯片间加速器结构设计的,其在标准PCIe数据链路层基础上通过扩展事务层、协议层等功能,实现了对Cache一致性支持。CCIX可以支持灵活的拓扑结构,主要用于主CPU和加速器间通信。
针对Tilelink、CCIX等同步通信机制的可扩展性问题,ODSA项目的积极参与者Netronome公司设计了ISF接口协议。ISF包含传输层、网络层以及链路层,是一种可以支持异步存储访问的轻量级消息协议。ISF最初用于Netronome公司的NFP网络流处理器片上部件的互连,目前拟扩展支持Chiplet裸片间互连。
与工业界密切进行Chiplet相关互连标准规范的研究不同,学术界的研究焦点主要集中于裸片间网络层NOC架构及算法的设计优化,较多关注基于主动中介层实现高性能的Chiplet片上网络通信。
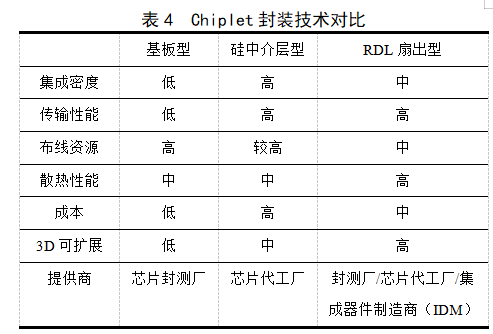
封装技术
Chiplet中裸片的互连的物理实现依赖于芯片封装过程完成,多芯片封装技术的性能、成本以及成熟度极大影响Chiplet芯片的应用。如图3所示,根据连接介质及工艺的不同,可用于支持Chiplet互连的封装技术可分为基于基板(Substrate)的封装技术、基于硅转接层(interposers,也称中介层、转接板)的封装技术和基于重分布层(Redistribution Layer,RDL)的扇出(Fan-Out)封装技术。

图3 Chiplet封装技术示意
由于成本等方面原因,有机基板使用较为广泛。有机基板材料与传统PCB类似,通过蚀刻工艺完成布线连接,不依赖于半导体制造设备的硅工艺。多个裸片可以基于基板通过引线键合(Wire bonding)或倒装(Flip Chip)技术利用有机基板进行高密度连接。由于不需要依赖芯片代工厂(Foundry)工艺,基于基板的封装方式材料及生产成本较低,封装大小可以达到110mm*110mm(栅格阵列封装LGA),在大规模Chiplet系统中使用较为广泛。然而,键合以及倒装互连IO引脚密度较低,且芯片大量引脚被电源地占据,导致可用于传输数据的引脚更加紧张,限制了全芯片对外带宽。此外,串扰效应也会阻碍单引脚数据传输能力的提升。上述问题也会限制Chiplet裸片间连接的传输带宽,从而影响更高性能Chiplet芯片构建。
基于硅中介层的封装技术是2.5D/3D封装技术的主要形式,通过在基板和裸片间上放置额外的硅层承接裸片间的互连通信,裸片与基板之间则通过硅过孔(Through-silicon vias,TSVs)和微凸点(Micro-Bump)连接。由于微凸点和TSV可以提供更小的凸点间距和走线距离,基于硅中介层的封装技术可以提供更高的IO密度以及更低的传输延迟和功耗。然而,由芯片代工厂提供的硅中介层的实现与有机基板相比,在材料和工艺实现成本方面都大大增加。如图3(c)所示,针对这一问题,硅桥(Silicon Bridge)技术试图融合基板和硅中介层技术,通过在基板上集成较小的薄层进行裸片间互连(小于75um),以期在性能和成本间取得良好的平衡。值得注意的是,硅中介层有两种形式,一种是只包含连接电路的被动中介层,另外一种是不仅包含连接电路还集成逻辑电路的主动中介层。主动中介层实现成本较高,但可以提供比被动中介层更灵活更易于扩展的解决方案,因而在学术界受到广泛关注。
基于重分布层的无基板的扇出封装技术在晶圆表面沉积金属和介质层,形成重分布层(RDL)承载相应的金属布线图形,对芯片的IO端口进行重新布局,将其布置到超出裸片面积外的宽松区域。扇出封装技术中,RDL可以缩短电路的长度,使得信号质量大幅提高,同时有效减少芯片的面积,提高Chiplet集成度。此外,扇出封装作为一种无基板(Substrate-less)的封装方式,其垂直高度较低,从而能提供额外的垂直空间让更多的元件可以向上堆叠。与基于硅中介层的封装技术相比,扇出封装的成本相对较低,但布线资源受限于RDL布线层次。由于台积电的InFo(集成扇出封装)技术在苹果公司iPhone 7中A10处理器的成功应用,扇出型技术受到了封测厂和芯片代工厂的广泛关注,目前市场已有10余种扇出封装技术推出,可为Chiplet集成提供更多选择。
表4给出了可用于Chiplet集成的封装技术的对比。随着Chiplet技术的不断发展成熟,与之匹配的封装技术也在不断演化,以期通过克服性能、功耗、成本以及可实现性问题,为Chiplet技术应用提供更好支撑。
质量控制技术
Chiplet中集成的裸片通常都是经过硅验证的产品,可以保证本身设计和物理实现的正确性,但在进行筛选和封装的过程中,仍然会出现良率的问题。对于Chiplet芯片来说,单个问题裸片会导致全芯片失效,代价很高。因此,完善全面的测试对于Chiplet芯片质量控制尤为重要,而与单芯片集成相比,Chiplet将多个裸片封装在一起,加剧了芯片测试的困难。Chiplet芯片管脚有限,可能仅能保证裸片部分管脚或部分裸片的测试连接需求,这对Chiplet全面测试带来了新的挑战。
Chiplet配套的EDA软件是解决这一问题的重要手段。在芯片设计制造过程中,30%-40%的成本是工具软件。Chiplet技术需要EDA工具从架构探索、芯片设计、物理及封装实现等提供全面支持。以在各个流程提供智能化、优化的实施辅助,将人工参与度降至最低,避免引入问题和错误。
在此方面,学术界和工业界的许多研究机构和公司已经开始了许多富有成效的工作。佐治亚理工学院Jinwoo Kim等人介绍了面向2.5D Chiplet封装的EDA流程,该流程覆盖并完全自动化了架构、电路和封装的整个设计阶段,并使用具有NOC配置的ROCKET-64 CPU验证了其EDA流程的可用性。此外,Cadence、Synopsys和Mentor等传统的集成电路EDA公司都在研发支撑Chiplet集成的相关工具。
Chiplet技术的应用及发展趋势
虽然Chiplet异构集成技术的标准化刚刚开始,但其已在诸多领域体现出独特的优势,应用范围从高端的高性能CPU、FPGA、网络芯片到低端的蓝牙、物联网及可穿戴设备芯片。
在高性能CPU芯片方面,AMD推出的Zen 2架构通过将不同工艺节点的多个处理器核裸片(7nm)、IO裸片(14nm)以及存储器裸片组合构建成Chiplet芯片,从而以较低的成本获得高端工艺带来的计算处理性能提升。
英特尔公司 Stratix 10高性能FPGA较早采用Chiplet技术研制,通过EMIB硅桥封装技术(2.5D)基于AIB接口实现FPGA逻辑裸片与Serdes IO裸片之间的集成。Stratix 10集成了来自三个芯片代工厂的6种工艺节点的裸片,有效证明了不同代工厂面向Chiplet技术的互操作性。英特尔公司 Agilex系列FPGA则利用了先进的3D封装技术实现了包括10nm FPGA核心与112G Serdes的集成,证明了Chiplet技术应用于构建高工艺制程和高I/O性能芯片的可行性。
zGlue公司专注于中低端Chiplet芯片的研制和标准化,其研制或代工的蓝牙、物联网、WiFi等Chiplet芯片,裸片来源ADI、Dialog,Macronix和Vishay等30多家公司的近100种芯片产品。其建立了一套基础的Chiplet EDA工具链,使得快速实现裸片组合与复用成为可能。
总体来看,Chiplet技术由于可以在芯片涉及的良率、成本等多个维度提供可定制性和可优化性,其延伸的领域将越来越广泛,随着芯片开源生态及敏捷开发的快速兴起,Chiplet异构芯片集成技术将成为未来芯片研制的主流技术,值得科研机构和工业界对相关技术挑战和问题提前布局,展开研究。
总结
Chiplet异构集成技术作为破解摩尔定律放缓的可能解决方案近年来受到广泛关注。尽管Chiplet技术还存在一些尚未解决的技术问题,例如缺少成熟的互连接口、良率控制难度大等,但是在众多芯片研制领域已展现出较好的效能及性价比。与成本高昂的高工艺制程(在7nm及以下)单芯片技术方案相比,具有显著优势。因此,在工业界和学术界Chiplet技术逐渐成为研究和讨论的热点。在对Chiplet技术的优势和挑战进行了详细讨论的基础上,我们认为Chiplet技术将成为下一代芯片研制的主流技术,应予以密切关注,积极参与技术研发和标准规范制定过程,有效把握这一技术趋势,从而在部分芯片研制领域实现弯道超车。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2455期内容,欢迎关注。
推荐阅读
半导体行业观察

『 半导体第一垂直媒体 』
实时 专业 原创 深度
识别二维码 ,回复下方关键词,阅读更多
晶圆|IP | SiC|并购|射频|台积电|Nvidia|苹果
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复 搜索 ,还能轻松找到其他你感兴趣的文章!




-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号