来源:本文由半导体行业观察(ID:icbank)编译自anandtech,谢谢。
昨天,苹果发布了他们全新的MacBook系列产品。这不是一个普通的发布版本,如果说有什么不同的话,苹果今天所做的这一举动是15年来从未发生过的:开始了整个消费类Mac系列的CPU架构转型。
这个巨大的改变多亏了该公司在硬件和软件上的垂直整合,除了苹果公司,没有人能够如此迅速地引入。上一次苹果公司在2006年进行这样的尝试时,放弃了IBM的PowerPC ISA和处理器,转而支持英特尔x86设计。如今,英特尔正在被抛弃,苹果转而采用基于Arm-ISA的内部处理器和CPU微体系结构。
新处理器称为Apple M1,这是该公司首款针对Mac设计的SoC。它具有四个大型性能内核,四个效率内核和一个8-GPU内核GPU,在5nm工艺节点上具有160亿个晶体管。苹果公司正在为这种新的处理器系列启动新的SoC命名方案,但至少在理论上它看起来很像A14X。
今天的活动包含了许多新的官方公告,但也缺少(以典型的Apple方式)详细信息。今天,我们将剖析新的Apple M1新闻,并基于已经发布的Apple A14 SoC进行微体系结构的深入研究。
新款Apple M1确实是Apple进行新的重大旅程的开始。在苹果公司的演讲中,该公司并未在设计细节上透露太多,但是有一张幻灯片告诉了我们很多有关芯片的封装和架构的信息:
这种在有机封装中嵌入DRAM的封装方式对苹果来说并不新鲜;他们从A12开始就一直在使用它。当涉及到高端芯片时,苹果喜欢使用这种封装而不是通常的智能手机POP封装(封装上的封装),因为这些芯片在设计时考虑到了更高的TDP。因此,将DRAM放在计算机芯片的旁边,而不是放在其上,有助于确保这些芯片仍能得到有效冷却。
这也意味着,我们几乎可以肯定地看到新芯片上的128位DRAM总线,与上一代a-X芯片非常相似。
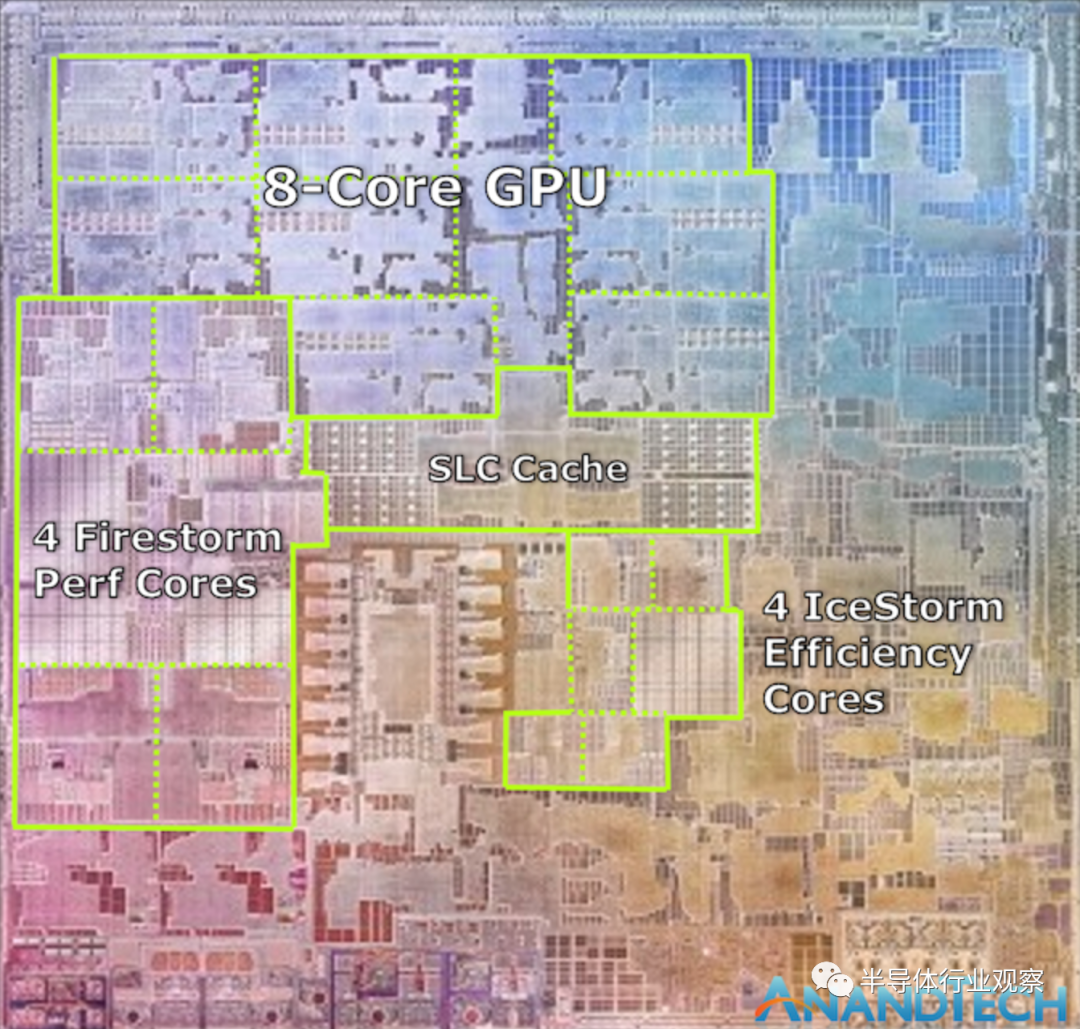
在同一张幻灯片上,苹果似乎也使用了新M1芯片的实际裸片(die)镜头。它完全符合苹果公司所描述的芯片特性,看起来就像一个真正的裸片照片。这可能是我做过的最快的裸片注释了:
我们可以看到M1的四个Firestorm高性能CPU核心在左侧。注意大量的缓存——12MB缓存是这次事件的一个令人惊讶的发现,因为A14仍然只有8MB的二级缓存。新的缓存看起来被分成了3个更大的块,考虑到苹果的新配置从8MB过渡到12MB,这是合理的,毕竟它现在被4核使用而不是2核。
同时,在SoC中心附近找到了4个Icestorm效率核心,在上面,我们可以找到SoC的系统级缓存,该缓存在所有IP块之间共享。
最后,8核的GPU占据了大量的die space,并且位于这个die shot的上半部。
M1最有趣的地方是它与Intel和AMD其他CPU设计的比较。上述所有模块仍然只覆盖了整个裸片的一部分,并带有大量的辅助IP。苹果提到M1是一个真正的SoC,包括之前Mac笔记本电脑内部的几个分立芯片的功能,比如I/O控制器和苹果的SSD和安全控制器。
苹果声称它是全球最快的CPU内核。这将是今天文章的中心内容,因为我们将深入研究Firestorm核心的微架构,并查看非常相似的Apple A14 SoC的性能数据。由于它的附加缓存,我们预计M1中使用的Firestorm内核比我们今天将要用A14进行分析的速度还要快,因此苹果声称拥有世界上最快的CPU核心似乎极为合理。
整个SoC采用了160亿个晶体管,比最新款iphone内置的A14多35%。如果苹果能够保持两个芯片之间晶体管的密度相似,我们应该可以期待一个大约120mm的晶体管尺寸。这将比苹果MacBook上一代的英特尔芯片要小得多。
事实上,苹果甚至可以如此无缝地完成一个重大的架构转换,只是一个小小的奇迹,毕竟苹果在实现这一点上有着相当丰富的经验。毕竟,这并不是苹果第一次为他们的Mac电脑切换CPU架构。
在21世纪中期左右,这家长期经营的PowerPC公司走到了一个十字路口,当时负责PowerPC开发的Apple-IBM-Motorola(AIM)联盟越来越难以进一步开发芯片。IBM的PowerPC970(G5)芯片在台式机上有着可观的性能指标,但它的功耗却相当可观。这使得该芯片无法用于日益增长的笔记本电脑领域,苹果仍在使用摩托罗拉的PowerPC 7400系列(G4)芯片,虽然该芯片的功耗确实更好,但其性能无法与英特尔的核心系列处理器相媲美。
因此,苹果打出了一张他们保留的牌:Marklar项目。利用Mac OS X及其底层Darwin内核的灵活性(与其他Unix一样,达尔文内核设计为可移植),苹果一直在维护Mac OS X的x86版本。尽管最初主要被认为是一种良好编码实践的练习,但要确保苹果编写的操作系统代码没有不必要的约束PowerPC及其big-endian内存模型——Marklar成为苹果从停滞不前的PowerPC生态系统中退出的策略。该公司将改用x86处理器,尤其是英特尔的x86处理器,颠覆其软件生态系统,同时也为更好的性能和新的客户机会敞开大门。
从所有指标来看,切换到x86都是Apple的一大胜利。英特尔的处理器提供的每瓦性能优于苹果留下的PowerPC处理器,尤其是英特尔在2006年底推出Core 2(Conroe)系列处理器之后,英特尔就牢固地确立了自己在PC处理器领域的主导地位。最终,这奠定了苹果在未来几年的发展轨迹,使他们成为拥有笔记本超本(MacBook Air)和令人难以置信的MacBook Pro的笔记本电脑公司。同样,x86具有Windows兼容性,引入了直接启动Windows的功能,或者可以在开销非常小的虚拟机中运行它。
然而,这种转变的代价来自软件方面。开发人员需要开始使用苹果最新的工具链来生成可以在PPC和x86 mac上运行的通用二进制文件,而且并不是所有苹果以前的api都会跳到x86上。当然,开发商也做出了飞跃,但这是一个没有真正先例的转型。
至少在某种程度上,缩小了差距的是Rosetta,这是Apple用于x86的PowerPC转换层。Rosetta允许大多数PPC Mac OS X应用程序在x86 Mac上运行,尽管性能有些过失(x86上的PPC并不是最简单的事情),但是Intel CPU的更高性能有助于携带东西适用于大多数非密集型应用。最终,Rosetta对苹果来说只是一个创可贴,而苹果很快就撕毁了它;在2011年Mac OS X 10.7 (Lion)面世时,苹果已经放弃了Rosetta。因此,即使有了Rosetta,苹果公司也向开发者明确表示,如果他们想继续销售并让用户满意,他们希望他们为x86更新他们的应用程序。
最终,PowerPC向x86的转变为现代、敏捷的苹果定下了基调。从那时起,苹果就创造了一整套快速发展的理念,并在他们认为合适的情况下改变事物,只在向后兼容性方面做了有限的考虑。这给了用户和开发者很少的选择,只能享受这段旅程并跟上苹果的发展趋势。但它也给了苹果提早推出新技术的能力,如果有必要的话,还可以打破旧的应用程序,这样新功能就不会因为向后兼容的问题而受阻。
所有这些都是以前发生的,并且所有这些都会在下周苹果发布其首批基于Apple M1的Mac时再次发生。通用二进制文件又回来了,Rosetta又回来了,苹果公司敦促开发人员在Arm上启动并运行他们的应用程序已全面展开。从PPC到x86的过渡为Apple进行了ISA更改创建了模板,在成功过渡之后,随着Apple成为自己的芯片供应商,他们将在接下来的几年中再次进行此操作。
在接下来的页面中,我们将研究A14的Firestorm内核,它也将在M1中使用,也会在iPhone芯片上做一些广泛的基准测试,设定M1的最低标准:
那么苹果打算如何在这个市场上与AMD和Intel竞争呢?过去几年来一直在关注苹果在硅技术方面的努力的读者一定不会惊讶地看到苹果在活动中宣称的性能。
秘密之处在于苹果公司内部的CPU微体系结构。苹果在定制CPU微体系结构方面的漫长旅程始于2012年在iPhone 5中发布的Apple A6。即使在那时,凭借其第一代“ Swift”设计,与移动竞争对手相比,该公司的性能数据仍然令人印象深刻。
然而,真正在业界引起轰动的是苹果随后在2013年的Apple A7 SoC和iPhone 5S中发布的Cyclone CPU微体系架构。苹果早期采用的64位Armv8震惊了所有人,因为该公司是业界首个实施新指令集架构的公司,但他们甚至比Arm自己的CPU团队早了一年多,因为Cortex-A57 (Arm自己的64位微架构设计)要到2014年底才问世。
苹果公司将其“ Cyclone”设计称为“桌面级架构”,事后看来,这可能对公司的发展方向有一个明显的指示。在接下来的几代中,苹果已经以惊人的速度发展了他们定制的CPU微架构,每一代都取得了巨大的性能提升,这些我们已经在过去的几年里广泛报道过:
今年的A14芯片包括了苹果64位微体系结构家族中的第8代芯片,这是从A7和Cyclone设计开始的。这些年来,苹果的设计节奏似乎已经稳定下来,围绕着主要的双代微架构更新,从A7芯片组开始,A9、A11、A13都大幅增加了设计的复杂性和微架构的宽度和深度。
考虑到苹果没有透露任何细节,苹果的CPU在很大程度上仍然是一个黑匣子设计,而且关于此事的唯一公开资源可以追溯到A7旋风时代的LLVM补丁,这与今天的设计已经不再相关。虽然我们没有官方的手段和信息来说明苹果的CPU是如何工作的,但这并不意味着我们无法弄清楚设计的某些方面。然而,通过我们自己的内部测试以及第三方微基准测试(这是@Veedrac的微体系结构测试套件的一项特殊学分),我们可以公布苹果设计的一些细节。以下披露是基于测试iPhone 12 Pro中最新的Apple A14 SoC的行为得出的:
苹果最新一代A14内部的大核心CPU设计代号为“Firestorm”,延续了去年苹果A13内部的“Lightning”微架构。今天讨论的核心是新的Firestorm核心和它多年来不断改进的血统,这也是苹果如何从英特尔x86设计大幅跳跃到他们自己内部的SoC的关键部分。
上图是苹果最新大核心设计的估计功能布局–这里表示的是我尽最大努力确定新设计的功能,但是仍然不能详尽地深入研究苹果设计必须提供的所有内容–因此,可能会出现一些错误。
与业内其他设计相比,真正定义苹果的Firestorm CPU核心的是其微架构的宽度。具有8-wide解码块,苹果的Firestorm是目前行业中最广泛的商业化设计。IBM即将在POWER10中推出的P10内核是唯一一个有望在市场上发布的具有如此宽解码器设计的官方设计,此前三星取消了他们自己的M6内核,后者也被描述为具有如此宽的设计。
今天的其他现代设计,例如AMD的Zen(1至3)和英特尔的µarch,x86 CPU仍仅采用4-wide解码器设计,由于ISA固有的可变指令长度特性,目前似乎无法将其扩展到更大的范围,与ARM ISA的固定长度指令相比,设计能够处理体系结构方面的解码器更加困难。在ARM方面,三星的设计从M3开始已经达到了6-wide,而Arm自己的Cortex内核随着每一代的发展都在稳步扩大,目前在现有的硅片中达到4-wide,并且预计会增加到即将推出的Cortex-X1内核具有5-wide设计。
苹果的微架构是8-wide实际上对新的A14来说并不新鲜。回到A13,似乎我在测试中犯了一个错误,因为我最初认为它是一台 7-wide机器。最近我对它进行了重新测试,证实苹果正是在这一代升级了A11和12的7-wide解码。
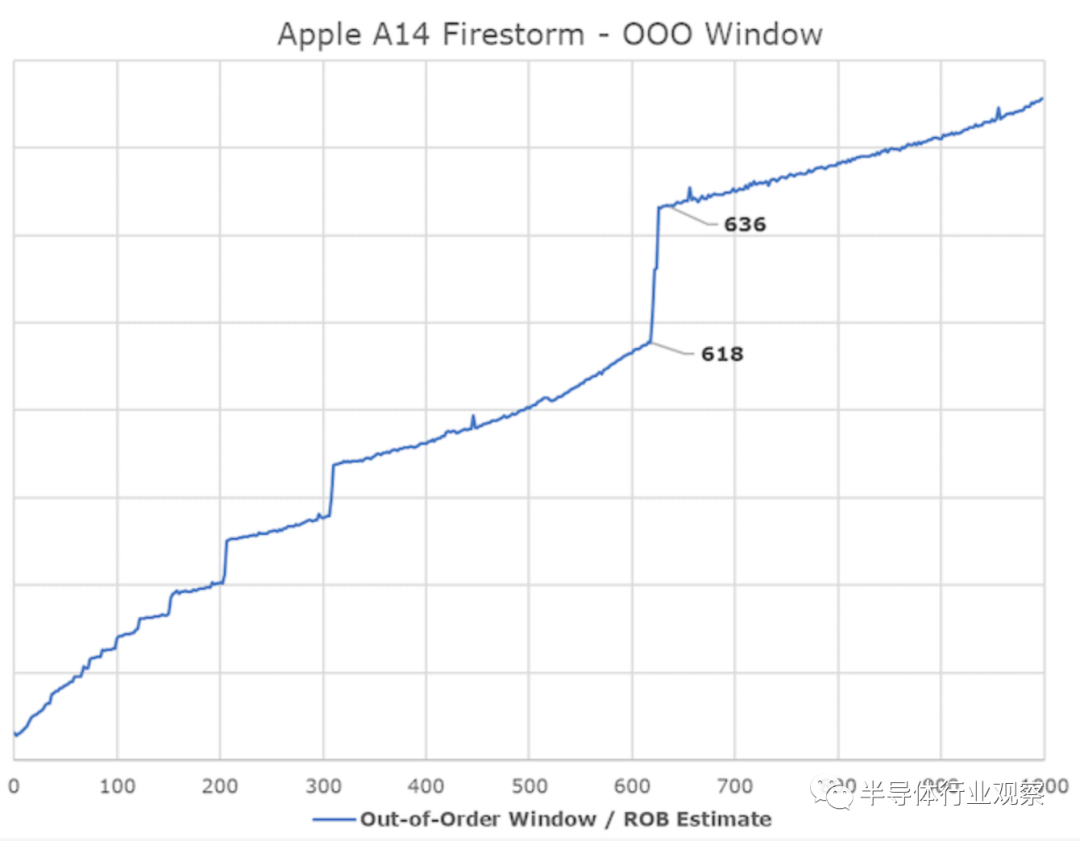
苹果公司最近的设计中,有一个方面我们从来没有真正能够具体回答,那就是他们的无序执行能力有多深。我们在此问题上获得的最后官方资源是2013 Cyclone设计中ROB(重排序缓冲区)的192数字。再次感谢Veedrac实施的测试似乎暴露了µarch的这一部分,我们似乎可以确认Firestorm的ROB在630指令范围之内,这是对去年的A13 Lightning内核(在560中测得)的升级。目前还不清楚这是否与其他架构中的传统ROB相同,但测试至少暴露了与ROB相关的微架构限制,并暴露了行业中其他设计的正确数据。无序窗口是指当内核试图获取并执行每条指令的依赖关系时,内核可以“停放”的、等待执行的指令数量。
对于苹果的新核心来说,A+-630 deep ROB是一个巨大的无序窗口,因为它远远超过了业内其他设计。英特尔的Sunny Cove和Willow Cove型内核是第二大“深”OOO设计,拥有352个ROB型架构,AMD最新的Zen3型内核有256个条目,最近的Arm设计如Cortex-X1有224个架构。
与业内其他设计师相比,苹果是如何以及为什么能够实现如此不成比例的设计还不清楚,但这似乎是苹果实现高指令水平并行的设计理念和方法的一个关键特征。
拥有高ILP也意味着这些指令需要由机器并行执行,这里我们还可以看到苹果的后端执行引擎具有非常广泛的功能。在整数方面,我们估计其在运行中的指令和重命名物理寄存器文件的容量大约为354个条目,我们找到了至少7个用于实际算术操作的执行端口。其中包括4个简单的算术逻辑单元能够加法指令,2个复杂的单元也具有MUL(乘法)功能,以及一个似乎是专用的整数除法单元。核心每个周期可以处理2个分支,我想这是由一个或两个专用的分支转发端口实现的,但我无法100%确认这里的设计布局。
这里的Firestorm核心在整型设计方面似乎没有重大变化,因为唯一值得注意的变化是该单元的整型除法延迟明显略有增加(是的)。
在浮点和矢量执行方面,新的Firestorm内核实际上更令人印象深刻,因为苹果增加了第四个执行管道,使其功能增加了33%。在这里,FP重命名寄存器似乎有384个条目,这也是相当庞大的。因此,这四个128位的NEON管道在理论上可以与AMD和Intel的桌面内核的当前吞吐量相匹配,尽管它们的吞吐量更小。这里的端点操作吞吐量与管道计数是1:1,这意味着Firestorm可以每循环执行4个FADD和4个FMUL,分别有3个和4个周期延迟。这是英特尔CPU和之前AMD CPU的四倍,也是最近的Zen3的两倍,当然,仍然在较低的频率运行。这可能是苹果在浏览器基准测试中表现如此出色的原因之一(JavaScript数字是浮点双精度数)。
这四个管道的向量能力似乎是相同的,唯一看到吞吐量较低的指令是在四个管道之一上的FP除法,倒数和平方根运算仅具有1的吞吐量。
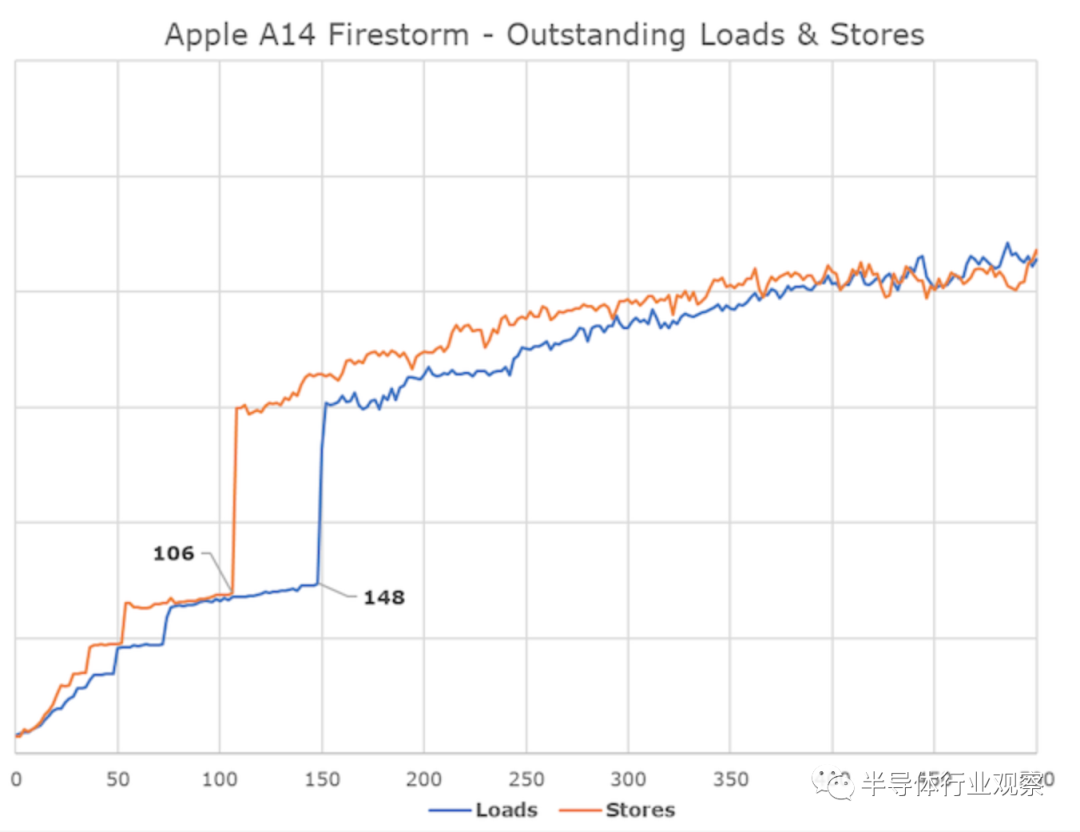
在加载存储方面,我们看到了似乎有四个执行端口:一个加载/存储,一个专用存储和两个专用加载单元。核心每个周期最多可以执行3个负载,每个周期最多可以执行2个存储,但是最多只能同时执行2个负载和2个存储。
这里有趣的是苹果处理内存事务的深度。我们测量了大约148-154个未完成的负载和大约106个未完成的存储,这应该是内存子系统的负载队列和存储队列的等价数字。毫不奇怪,这也比市场上的任何其他微体系结构都要深入。相比之下,AMD的Zen3和英特尔的Sunny Cove分别为128/72和128/ 64。英特尔在这里的设计与苹果相差不远,实际上这些最新的微架构的吞吐量是相对匹配的——如果苹果将这种设计部署到非移动内存子系统和DRAM上,那将是很有趣的。
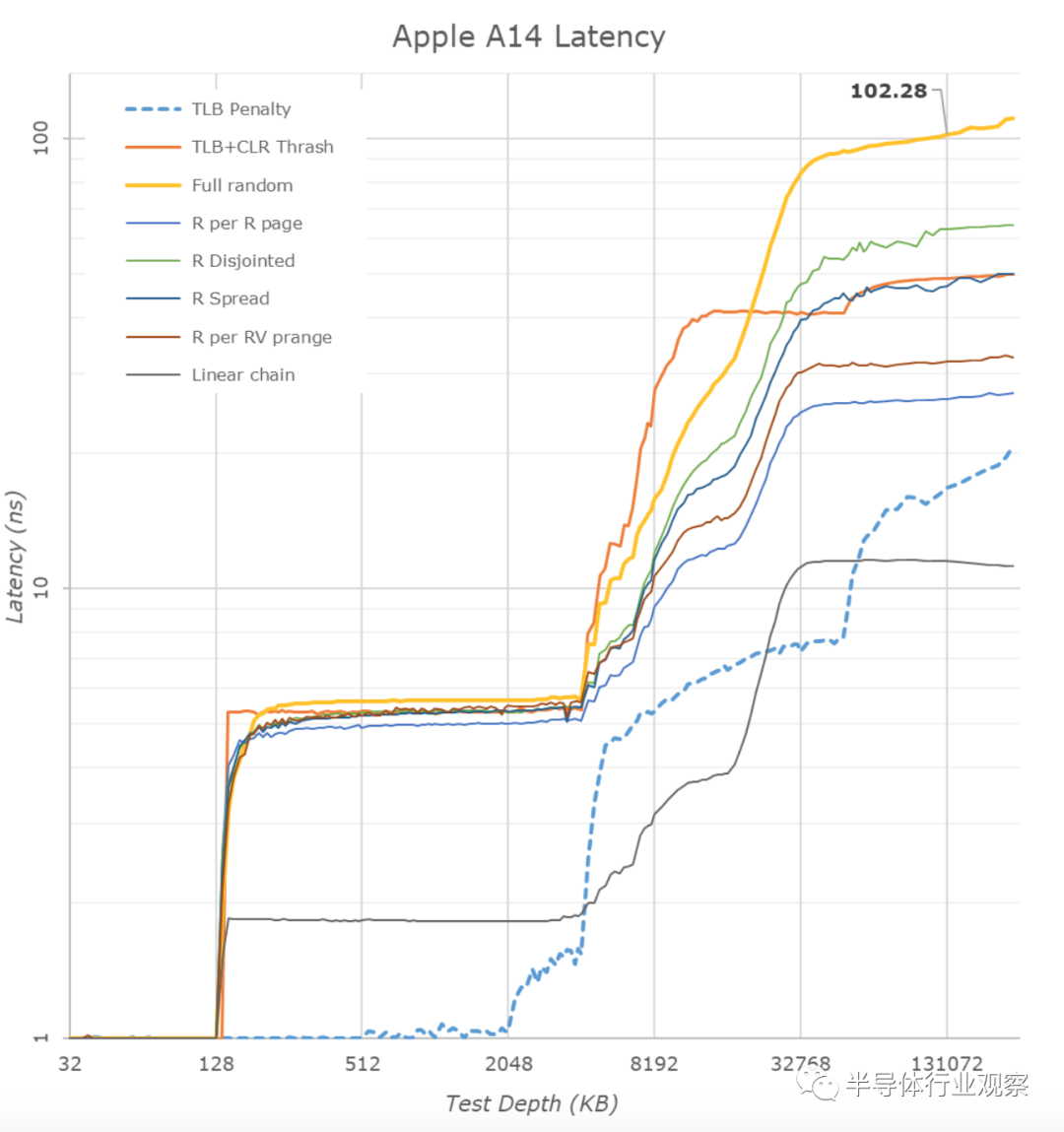
在这一代的Firestorm核心方面,最大的改进就是TLB。L1 TLB从128页增加了一倍,达到256页,L2 TLB从2048页增加到3072页。在当今的iPhone上,这是一个绝对过大的更改,因为页面大小为16KB,这意味着L2 TLB覆盖48MB,甚至超过了A14的缓存容量。随着苹果将微体系结构转移到Mac系统上,与4KB页面兼容并确保设计仍提供足够的性能,这将成为苹果为何选择在这一代进行如此大规模升级的关键部分。
在缓存层次结构方面,我们早就知道苹果的设计是可怕的,而A14 Firestorm内核延续了这一趋势。去年我们曾猜测A13有128KB的L1指令缓存,类似于我们可以测试的128kbl1数据缓存,但是在Darwin内核源代码转储之后,苹果证实了它实际上是一个巨大的192KB指令缓存。这绝对是巨大的,比竞争对手的Arm设计大3倍,比目前的x86设计大6倍,这可能再次解释为什么苹果在非常高的指令压力工作负载(如流行的JavaScript基准测试)方面表现出色。
巨大的高速缓存似乎也非常快– L1D以3个周期的负载使用延迟进入。我们不知道这是否是如三星核心所描述的那样巧妙的负载级联,但是无论如何,对于如此大的结构来说,这是非常令人印象深刻的。AMD具有32KB的4周期缓存,而英特尔最新的Sunny Cove在将大小增加到48KB时看到了5周期的回归。慢频或快频设计的优缺点值得深思。
在L2方面,Apple一直采用两个大核心共享的8MB结构。这是一个非常不寻常的缓存层次结构,与其他人使用的中间大小的私有L2和更大的较慢的L3形成对比。苹果在这里不理会规范,而是选择大型而快速的L2。奇怪的是,这一代A14看到了大核的L2在访问延迟方面进行了回归,从14个周期回到了16个周期,还原了A13所做的改进。我们不确定为什么会发生这种情况,我确实看到标量工作负载有更高的并行访问带宽进入缓存,但是峰值带宽似乎仍然与上一代相同。另一个假设是,由于Apple在内核之间共享L2,因此这可能是Apple Silicon SoC发生变化的指标,因为只有两个以上的内核连接到单个缓存,这与A12X代很相似。
苹果已经在其SoC上使用大型LLC了好几代了。A14上,这似乎又是一个16MB的缓存,服务于SoC上的所有IP块,当然对CPU和GPU最有用。相对而言,这种缓存层次结构并不像其他设计的实际CPU-cluster l3那么快,而且近年来,我们看到越来越多的移动SoC供应商为了提高功率效率而在内存控制器前使用这种LLC。苹果会在更大的笔记本或台式电脑芯片上做什么还不清楚,但我认为我们会看到类似的设计。
我们已经讨论了苹果设计的更多具体方面,比如它们的MLP(内存级并行)功能,而A14在这方面似乎没有改变。我注意到A13的另一个变化是,新的设计现在也利用了Arm更轻松的内存模型,它能够自动优化流媒体存储到非临时存储中,模仿Cortex-A76和Exynos-M4中引入的变化。从理论上讲,x86设计无法实现类似的优化,如果有人尝试这样做,将非常有趣。
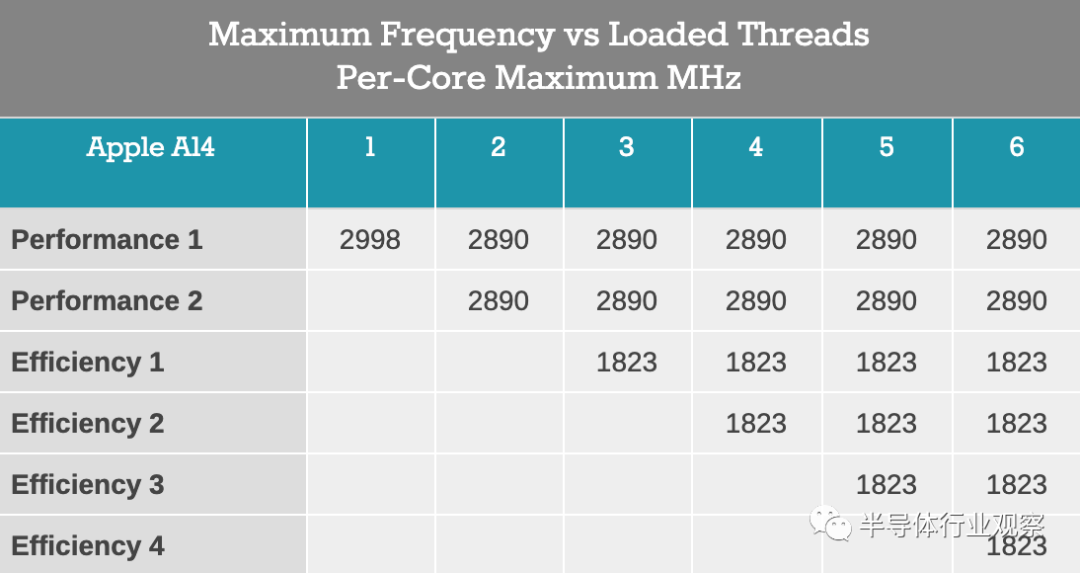
当然,关于拥有非常广泛的体系结构的古老观点是,你不能把时钟设到与比它窄的东西一样高的地方。这在某种程度上是正确的;不过,我不会对苹果的设计在更高功率设备上的性能做出任何结论。在新款iphone的A14上,新的Firestorm内核可以达到3GHz的时钟速度,当有两个内核同时工作时,时钟速度可以降至2.89GHz
我们将稍后详细研究功耗,但是我目前看到Apple受实际手机散热的限制,而不是微体系结构的固有时钟上限。新的Firestorm内核现在的时钟速度与Arm上其他移动CPU微体系结构的速度大致相同,即使它的设计范围更广。因此,由于设计更加复杂而不得不降低时钟速度的论点似乎也不适用于这个实例。苹果不仅可以在笔记本电脑这样的高温度封装设备上做什么,还可以在Mac这样的壁挂式设备上做什么,这将是一件非常有趣的事情。
在我们深入探讨x86与Apple Silicon的争论之前,有必要更详细地研究A14 Firestorm内核在A13 Lightning内核基础上的改进方式,以及详细介绍新芯片5nm工艺的功率和功率效率改进节点。
在这里的比较中,流程节点实际上是一个通配码,因为A14是市场上第一个5nm芯片组,紧随其后的是华为Mate 40系列的麒麟9000。我们碰巧有设备和芯片在内部进行测试,对比一下麒麟9000(N5上的Cortex-A77 3.13GHz)和Snapdragon 865+(N7P上的Cortex-A77 3.09GHz),我们可以从某种程度上推断出处理节点在功率和效率方面有多大影响,将这些改进转化为A13与A14的比较。
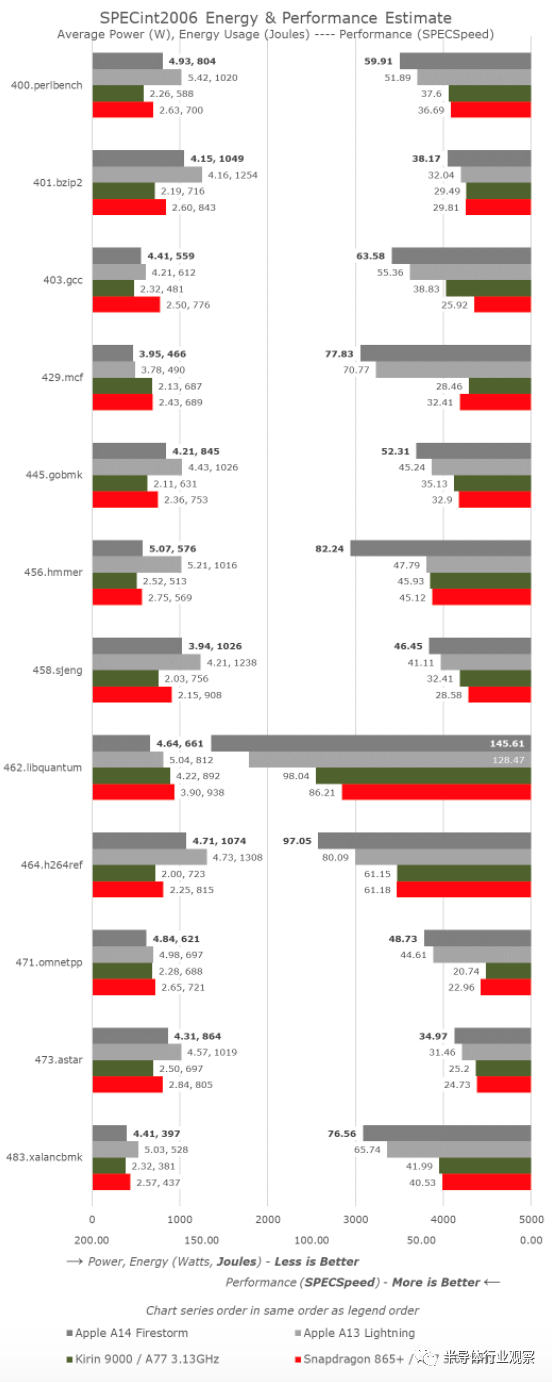
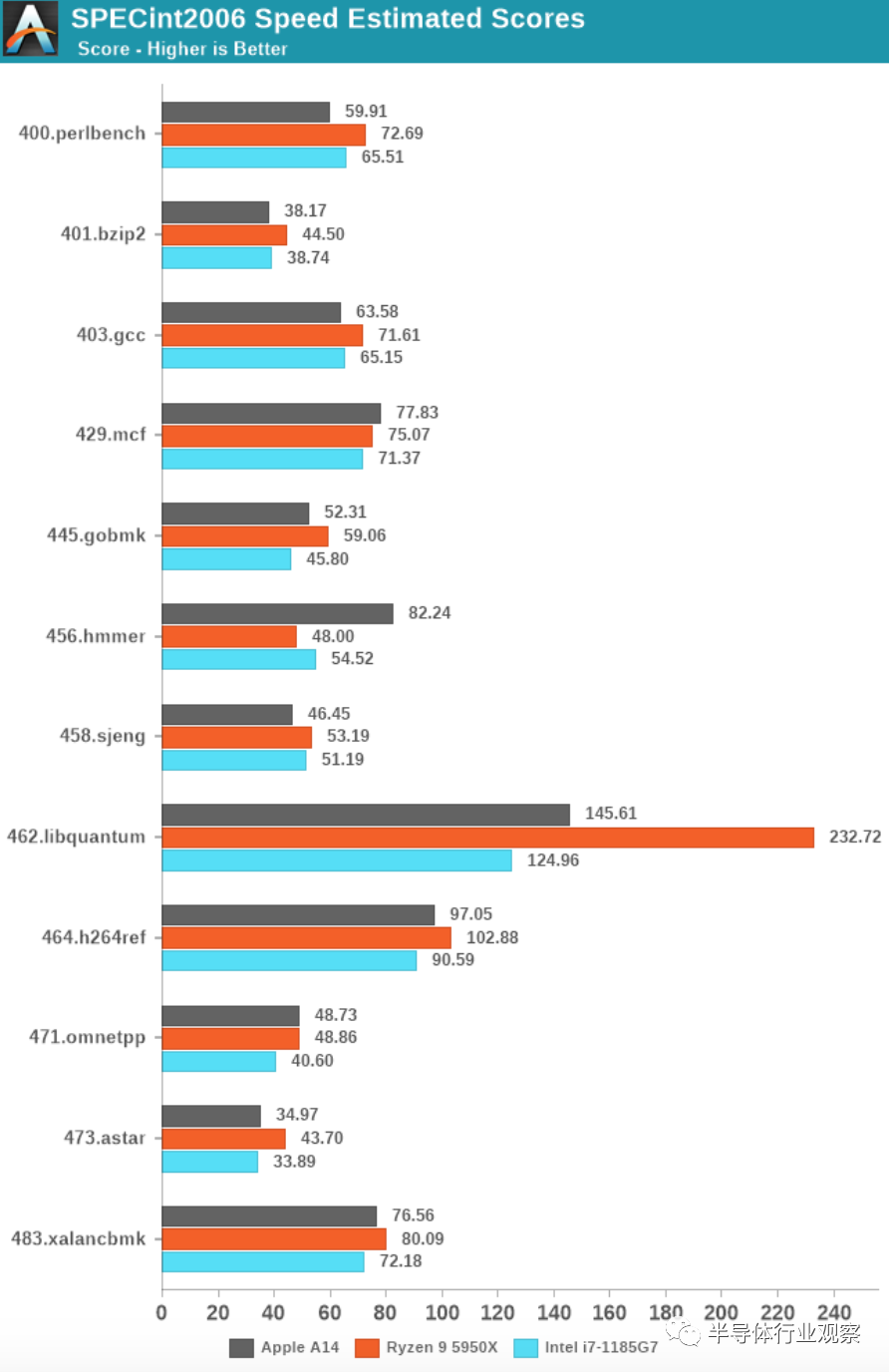
从SPECint2006开始,我们没有看到A14分数有什么不寻常的,除了456的巨大进步。实际上,这并不是由于微架构的飞跃,而是由于Xcode 12中新的LLVM版本进行了新的优化。在这里,编译器似乎使用了类似于在GCC8上发现的循环优化。A13的分数实际上已经从47.79提高到了64.87,但我还没有在整个套件上运行新的数字。
对于其余的工作负载,A14通常看起来像一个相对于A13的线性进程,因为时钟频率从2.66GHz增加到3GHz。IPC的整体涨幅在5%左右,略低于苹果的前几代产品,不过时钟速度的涨幅要大于通常的水平。
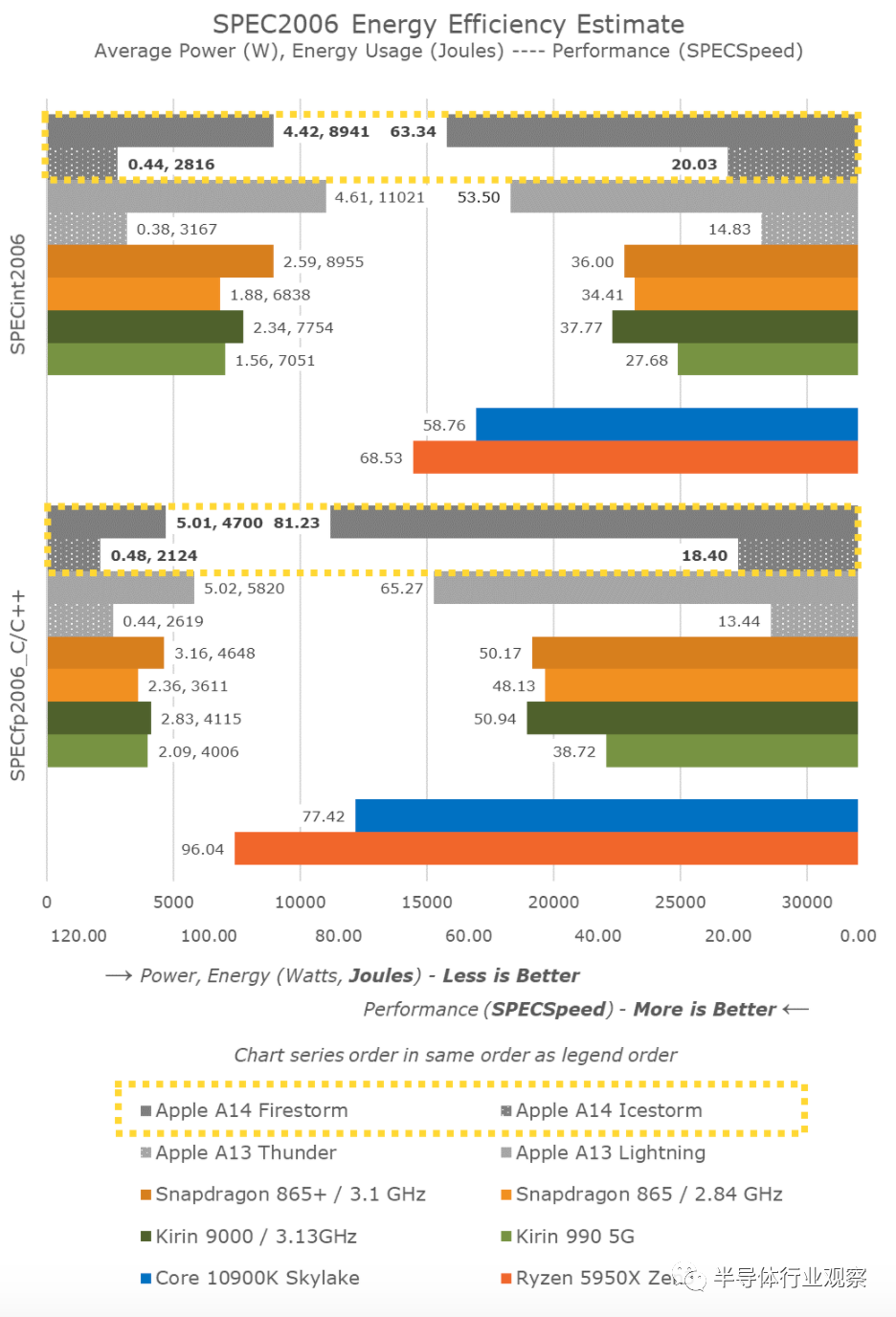
新芯片的功耗实际上是一致的,有时甚至比A13更好,这意味着这一代的工作负载能源效率已经看到了明显的改善,即使在峰值性能点。
与当代的Android和以Cortex-core为核心的SoC相比,苹果的性能似乎相当不平衡。最突出的一点是内存密集型、稀疏内存,其特点是工作负载(如429.mcf和471.omnetpp),苹果的设计功能远远超过性能的两倍,尽管所有芯片都运行着类似的移动级LPDDR4X/LPDDR5内存。在我们的微体系结构调查中,我们发现Apple设计上存在“记忆魔力”的迹象,我们可能会认为它们正在使用某种指针追随预取机制。
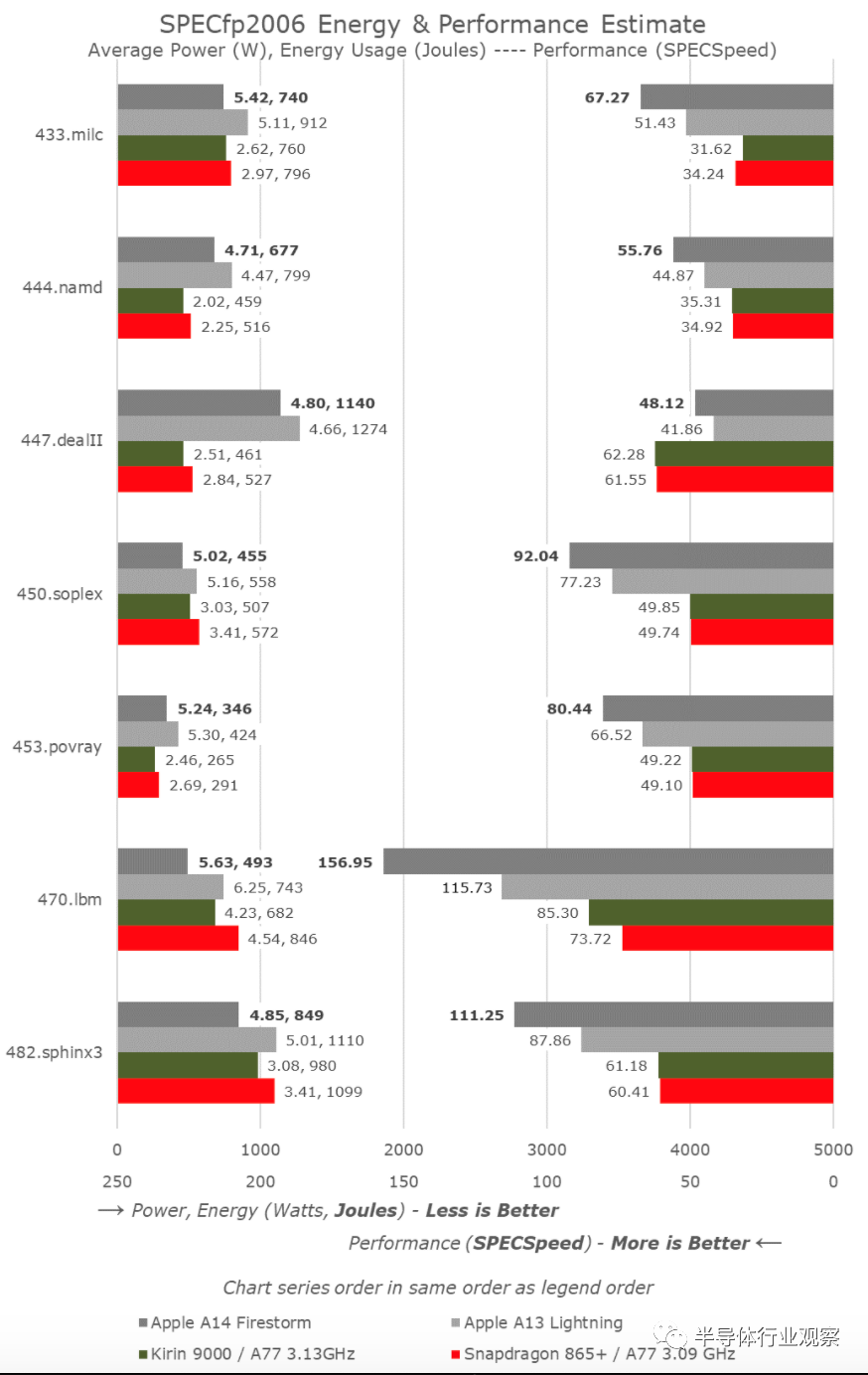
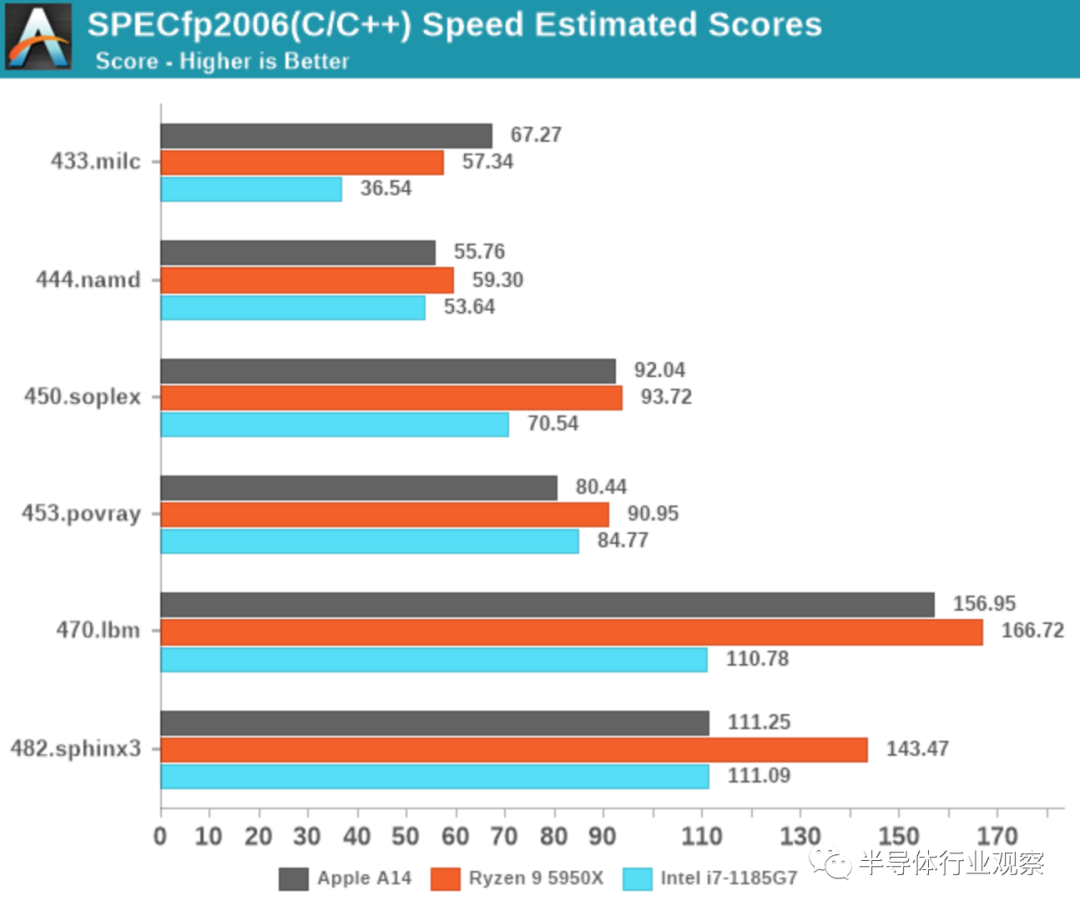
在SPECfp中,A14在A13上的增长比线性时钟频率的增长略高,因为我们在这里测量了10-11%的IPC上升。考虑到设计中额外的第四个FP/SIMD管道,这并不太令人惊讶,而与A13相比,核心的整数部分保持了相对不变。
在整体的手机比较中,我们可以看到新的A14在性能提升方面比A13取得了强劲的进步。与竞争对手相比,苹果遥遥领先——我们必须等到明年的Cortex-X1设备才能看到差距再次缩小。
还有非常重要的一点需要注意的是,苹果在实现这一切的同时,还保持了扁平状态,甚至降低了新芯片的功耗,显著降低了相同工作负载下的能耗。
看看麒麟9000和Snapdragon 865+,我们发现功率在相对相似的性能下降低了10%。两种芯片都使用相同的CPU IP,只是它们的处理节点和实现方式不同。看起来苹果的A14不仅能够实现工艺节点的改进,而且能够取得更好的数据,这也是考虑到它也是一种新的微体系结构设计。
还有一点需要注意的是A14小型效率核心的数据。在这一代中,我们看到了这些新内核的巨大微体系结构提升,与去年的A13效率内核相比,这些新内核现在的性能提高了35%,同时还进一步降低了能耗。我不知道小核将如何在Apple的“ Apple Silicon” Mac设计中发挥作用,但是与其他当前的现代Arm设计相比,它们肯定仍然非常高效且非常高效。
最后,是x86与苹果的性能比较。通常对于iPhone的评论,我会在这篇文章的这一部分对此进行评论,但是考虑到今天的背景和苹果为苹果硅所制定的目标,让我们用一个完整的专门章节来研究这个问题…
迄今为止,我们对Apple芯片组的性能比较一直是在iPhone评论的背景下进行的,与x86设计并列的内容在本文中只是一个很小的脚注。今天的Apple Silicon发布会完全改变了我们对性能的描述,抛开了人们通常争论的典型苹果与橘子的比较。
我们目前没有Apple Silicon设备,很可能再过几周都不会使用它们,但我们确实有A14,并且预计新的Mac芯片将基于我们在iPhone设计中看到的微架构。当然,我们仍然在比较手机芯片与高端笔记本电脑,甚至是高端台式机芯片,但考虑到性能数字,这也正是我们在这里要说的重点,这是苹果新推出的Apple Silicon Mac芯片所能达到的最低限度。
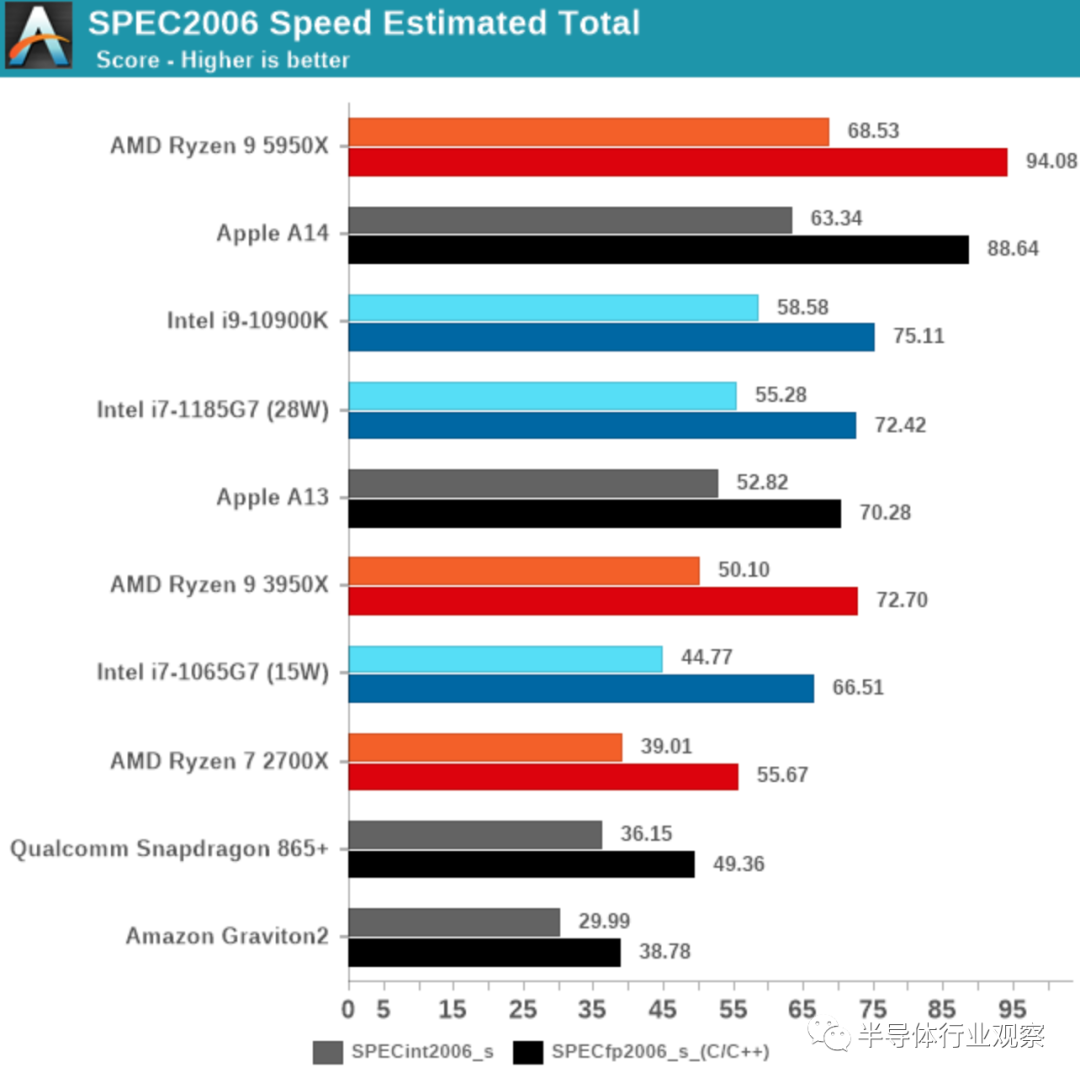
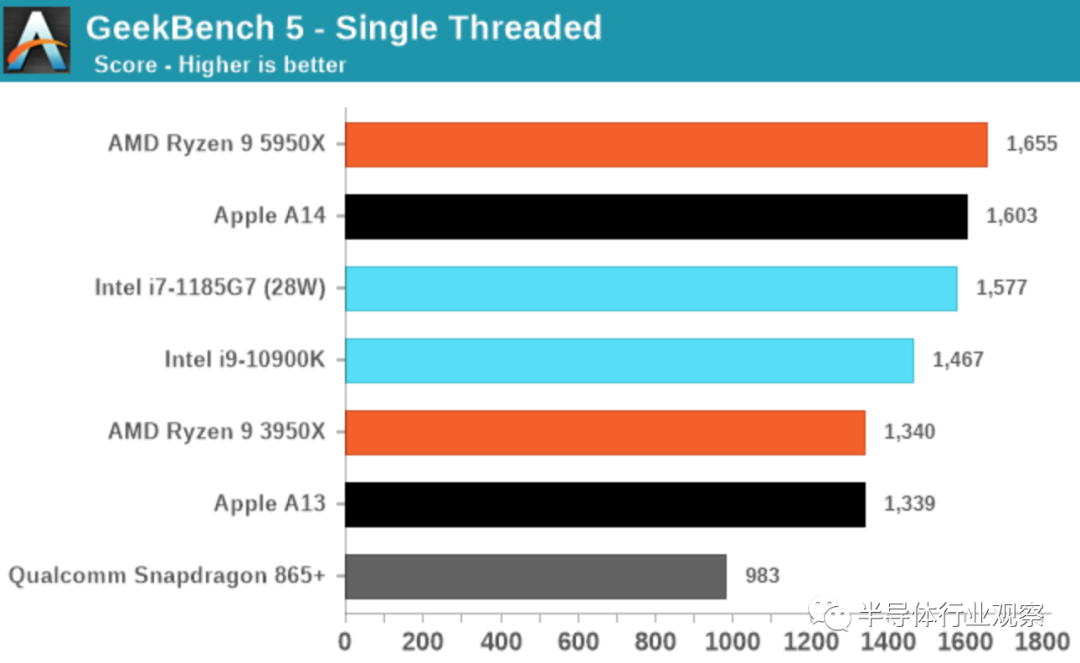
这张图表上A14的性能数字令人难以置信。如果我在隐藏A14标签的情况下发布此数据,可能会猜到这些数据点来自AMD或Intel的其他x86 SKU。A14当前可以与当今x86供应商在市场上拥有的最佳顶级性能设计相抗衡,这真是一个了不起的壮举。
查看详细分数,再次令我感到惊讶的是,A14不仅保持了这种速度,而且在内存延迟敏感型工作负载(例如429.mcf和471.omnetpp)上实际上击败了这两个竞争对手,即使它们具有相同的性能内存(带LPDDR4X-4266的i7-1185G7)或台式机级内存(带DDR-3200的5950X)。
同样,请忽略A14的456.hmmer得分优势,这主要是由于编译器差异造成的,请减去33%,以获得更合适的比较数字。
即使在SPECfp中,A14不仅可以跟上,而且通常比Intel的CPU设计好得多。如果不是最近发布的Zen3设计,AMD也不会看起来很好。
在整个SPEC2006图表中,A14的表现绝对出色,在绝对性能上领先于AMD最近的Ryzen 5000系列。
事实上,苹果能够在一个包括SoC、DRAM和监管机构在内的设备总功耗为5W的情况下实现这一点,而在没有DRAM或监管的情况下,设备功耗为+21W (1185G7)和49W (5950X)。这绝对是令人震惊的。
对于GeekBench等更常见的基准测试套件,已经有了许多批评,但坦率地说,我发现这些担忧或争论是完全没有根据的。SPEC中的工作负载和GB5中的工作负载之间的唯一实际区别是,后者的异常值测试较少,这意味着它更多地是一个CPU基准测试,而SPEC更倾向于CPU+DRAM。
苹果公司在两种工作负载中均表现出色,这证明它们具有极其平衡的微体系结构,并且Apple Silicon将能够在性能方面扩展至“桌面工作负载”而不会出现太大问题。
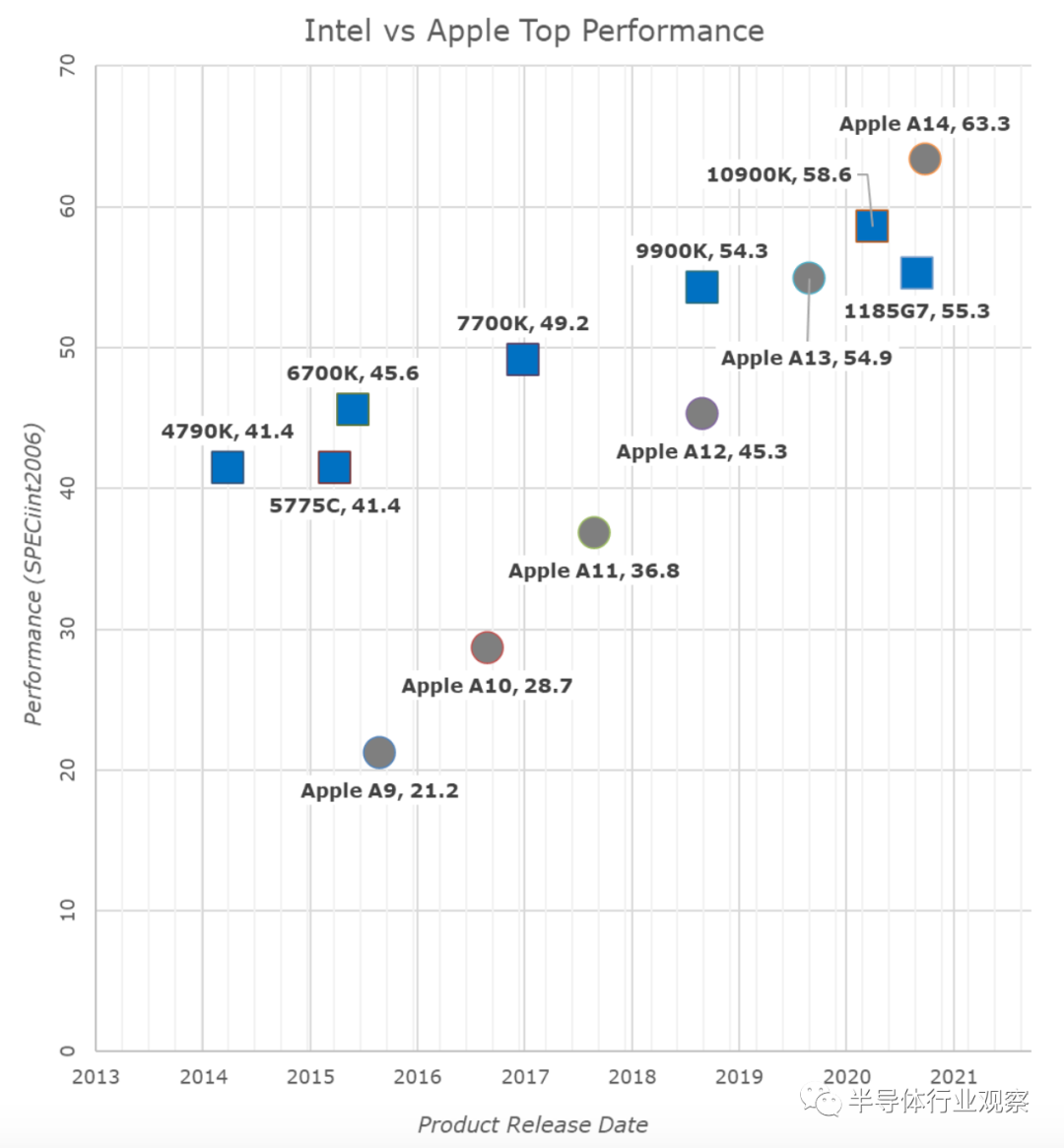
在A7发布期间,人们对苹果称其微体系结构为桌面类设计的事实相当不屑一顾。人们对我们几年前把A11和A12称为接近桌面水平的性能数据也非常不屑一顾,今天标志着这个行业的一个重要时刻,因为苹果A14现在显然能够展示出英特尔所能提供的最佳性能。这是一个多年来一直在稳步执行和进步的绩效轨迹:
在过去的5年里,英特尔成功地将他们最好的单线程性能提高了约28%,而苹果成功地将他们的设计提高了198%,或者说是2015年底苹果A9性能的2.98倍(3倍)。
这些年来,Apple的性能轨迹和毫无疑问的执行力已使Apple Silicon成为当今的现实。任何看到这张图表的荒谬之处的人都会意识到,苹果除了放弃英特尔和x86、转而采用自己的内部微架构之外,没有其他选择——按部不动将意味着停滞不前和更糟糕的消费产品。
今天的公告只涉及苹果笔记本电脑级的苹果硅芯片,虽然我们在撰写本文时还不知道苹果将推出什么产品的细节,但苹果巨大的能效优势意味着新芯片将能够提供大幅延长的电池寿命和/或大幅提升的性能当前的英特尔MacBook产品线。
苹果公司声称,他们将在两年内将整个消费产品线完全转换为苹果硅芯片,这也预示着我们将看到未来的Mac Pro将采用高TDP 多核设计。如果该公司能够继续目前的表现轨迹,它将看起来非常令人印象深刻。
前几页是在苹果正式宣布新的M1芯片之前写的。我们已经看到了A14的出色表现,并超过了英特尔所能提供的最好的性能。新的M1的表现应该明显高于这一水平。
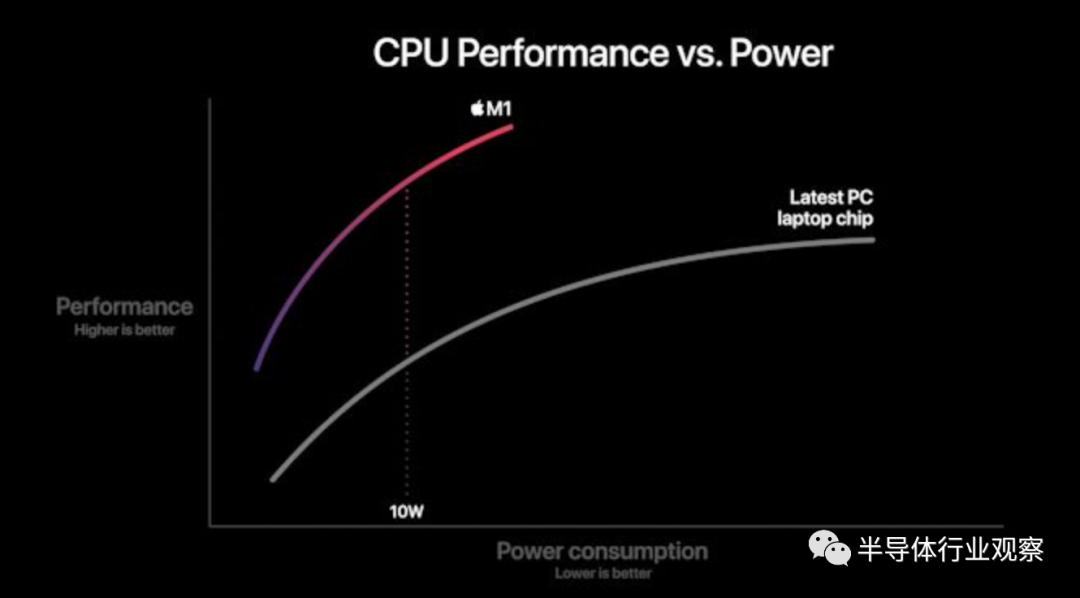
在演示过程中,我们将回顾苹果的几张幻灯片,以期对性能和效率有何期待。特别是性能/功率曲线,这是苹果目前分享的最详细的信息:
在这张图中,苹果展示了新的M1芯片,其CPU功耗峰值约为18W。与之竞争的PC笔记本电脑芯片在35-40W范围内达到峰值,因此这些数据肯定不是单线程性能数据,而是全芯片多线程性能。我们不知道这是否是比较M1与AMD Renoir 芯片或英特尔ICL或TGL芯片,但在这两种情况下,同样的普遍结论适用:
苹果公司使用了更为先进的微体系结构,该体系结构提供了显着的IPC,可在低内核时钟下实现高性能,与现有的x86处理器相比,可显着提高电源效率。该图显示,与现有竞争产品相比,M1在峰峰值处的性能提升约40%,而功耗仅为40%。
苹果公司对随机性能点的比较是值得批评的,但是苹果声称其性能是2.5倍的10W测量点确实是有道理的,因为这是基于Intel的MacBook Air使用的芯片的标称TDP。同样,这要归功于Apple在移动领域已经实现的能效特性,因此M1有望展现出如此大的收益-它肯定与我们的A14数据相匹配。
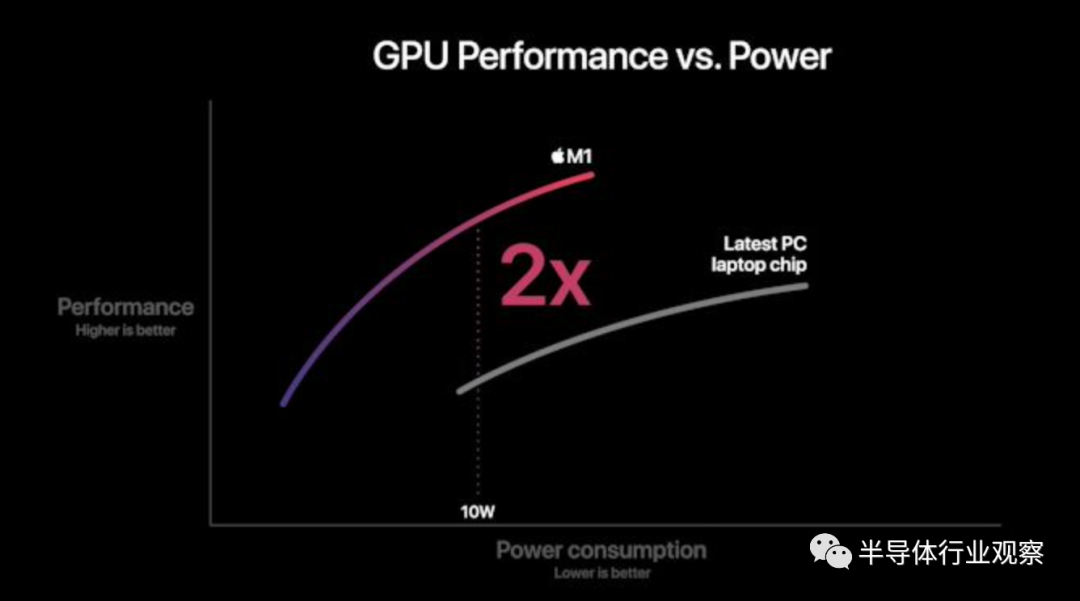
今天,我们主要讨论了CPU方面的问题,因为这是发生前所未有的行业转变的地方。但是,我们不应忘记GPU,因为新的M1代表了Apple首次将其自定义设计引入Mac领域。
苹果在性能和能效方面的声明确实缺乏背景,因为我们不知道他们的比较点是什么。我不会试图在这里建立理论,因为有太多的变量在起作用,而且我们不知道足够的细节。
我们所知道的是,在移动领域,苹果在性能和能效方面绝对领先。上次我们测试A12Z的时候,它的设计远远超过了集成图形设计。但从那以后,AMD和英特尔的业绩都出现了更显著的跃升。
苹果声称M1是世界上最快的CPU。根据我们的数据,A14击败了所有英特尔的设计,只是低于AMD最新的Zen3芯片——高于3GHz的更高时钟,更大的L2缓存,和释放的TDP,我们当然可以相信苹果和M1能够实现这一目标。
这个时刻已经酝酿了多年,而新的Apple Silicon既令人震惊,也让人非常期待。在接下来的几周内,我们将尝试得到我们的新硬件,并证实苹果的说法。
英特尔在市场上停滞不前,今天失去了一个主要客户。AMD最近已经有了很大的进步,但是要赶上苹果的耗电量还是非常困难的。如果苹果的性能轨迹继续以这种速度发展下去,x86的性能皇冠可能永远也无法重新获得。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2491期内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
存储|晶圆
|光刻
|FPGA|并购|Marvell|华为|功率半导体
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!