来源:内容
转载自期刊《微纳电子与智能制造》,作者:江先阳,容源,王永甲,张惟,谢谢。
自1971年依据电路理论完备性预测有忆阻器的存在,到2008年惠普实验室将忆阻器和现实器件联系起来以来,人们围绕忆阻器的研究层出不穷,而针对高效能计算面临的存储墙和功耗墙问题,忆阻计算体系和电路便是重要的候选者。以基于忆阻器的数值表达、存储、传输和计算方式为基础,阐明了忆阻计算中的蕴含逻辑、布尔逻辑、阈值逻辑等的发展现状和优缺点,总结了忆阻计算在神经形态计算、精确计算、近似计算等方面的突出研究工作。现阶段,忆阻计算仍然处在相对初级的阶段,其中的逻辑电路基础体系、信号退化、良好扩展性等问题还需要深入研究以迎接忆阻计算时代的到来。
忆阻器作为电阻、电容、电感以外第四种无源基本电路元件,由蔡少棠教授于 1971年依据电路理论完备性角度预测并命名,它在理论上表征着电荷和磁通量之间的关系。2008年,惠普实验室首次将现实器件和理论中的忆阻器联系起来,点燃了基于忆阻器的相关研究热潮。自此,人们不仅仅试图探索其器件相关机理,同时,热切地探索其优良特性例如无源性、能够实现非易失性存储、访问速度高、低功耗、易于集成、与CMOS工艺兼容、存储和计算可以在同一物理位置实现等,并期待着在非易失存储器、逻辑运算、神经形态计算等方面发挥广泛应用,图1给出了忆阻器在这些代表性的需求上展现的能力。
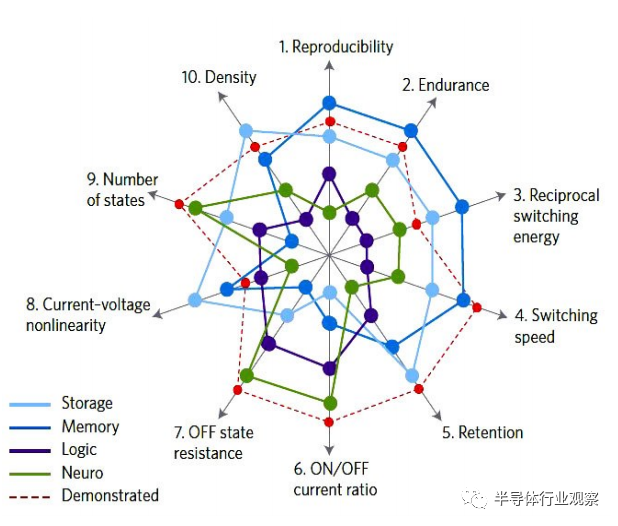
图1.4种应用对器件的需求,在相应轴上的位置越高代表需求的能力越高(虚线代表器件可达的最好性能)
在百花齐放的忆阻器相关研究(包括模型、机理,和其众多的应用例如字符识别、逻辑门、图像处理、目标识别、信号处理、语音识别、人脸识别等)中,一个重点是,因为其有别于CMOS器件的优良特性,人们期待它能够破除传统冯·诺依曼结构面临的存储墙问题,极大提升计算系统的性能,甚至是在类脑计算方面出现突破。
在纷繁的科技应用中,计算无疑是人类最重要的基础应用。那么忆阻器在其中充当什么角色,如何充当解决人类计算需求的先锋?或者说忆阻计算时代是否已经来临,人们准备好了吗?随着科学技术的发展,探索将一步步拨开这些迷雾。
以下首先阐述忆阻计算中涉及的基本问题,以及忆阻计算是如何达成的;随后将分别阐述忆阻计算在神经形态计算、精确计算,和近似计算领域中展现的能力,试图建立忆阻计算的完整谱系,供研究人员参考。
如果要实现计算,首要的是要解决数值在器件中的表达,然后才可能在此基础上构建计算系统。例如人们熟知的计算机系统,是基于二值布尔逻辑的,CMOS的通断正好对应了这个二值布尔逻辑。那么,对于新型的计算器件,是沿用过去的二值布尔逻辑体系,还是另外来开辟道路呢?为了厘清这一点,人们进行了众多的探索。综合分析已有的研究,按照计算中数值表达所归属的体系可以将基于忆阻器的数值表达和存储分成以下几类:
2010年,忆阻器就被展示使用其阻值来替代电压或者电量作为物理状态执行蕴含逻辑(material
implication)操作,记为pIMPq,等价于(NOTp)ORq,
在此基础上和FALSE操作一起可以构建完备的逻辑计算体系(其中FALSE操作类似复位操作,其操作结果总是将忆阻器的状态置为逻辑0),同时,忆阻蕴含操作可以被嵌入到纳米交叉阵列中实现逻辑计算,同时阵列本身也是存储单元,从而异于传统的冯·诺依曼结构,消除了从存储器和处理器之间的数据传输操作 ,从原理上提供了一种高效能的计算方式。
互补忆阻开关是蕴含逻辑的另一种实现形式,该结构可以在选择逻辑单元时避免邻近单元的潜通路电流影响,但它也可以是布尔逻辑的实现方式。
MAD门也是另外一种蕴含逻辑的实现方式。它提供一种统一的方式实现各种逻辑门,每个基本逻辑操作最多需要3个忆阻器和2个驱动器,操作步骤可以限于一步。
蕴含逻辑计算需要对电路在不同位置施加一序列电压操作来实现,同时输出存于其中一个充当输入的同一个忆阻器中,其数值的读出非常不方便。此外,该方法需要额外的电路例如电阻来辅助计算,增加了功耗,控制电路复杂,因此其扩展性的研究非常关键。采用CMOL实现蕴含逻辑并用于向量运算,是一种有效的扩展方法。综合能够查阅到的研究,可以发现,到目前为止,蕴含逻辑仍然是最有效的、应用最广泛的忆阻计算方法。
类比于CMOS电路,以布尔逻辑为基础,利用忆阻器构建基本逻辑门的逻辑体系是很自然的一种电路设计方法,其中也有相当部分研究采用互补忆阻开关的结构。这类设计的一个共同点,最后都要将输出转化到电压或者电流状态上去,从而达到和CMOS电路布尔逻辑兼容。例如MeMOS逻辑门就是这种互补忆阻开关的结构,其中忆阻器充当计算结构,逻辑状态转化成电压以支持电路扩展,同时引入CMOS反相器支持逻辑的完备性。这类方法因为具有CMOS类比性,所以对电路CAD支持方面具有优势,容易形成基于单元的电路扩展,同时这种逻辑结构也适宜于采用具有对称性的忆阻交叉阵列实现。
另外一种有趣的状态逻辑方法——MAGIC逻辑方法同样采用忆阻器的阻值状态表示数值,但是它只需要忆阻器而不需要辅助逻辑就可以实现逻辑操作。它和蕴含逻辑的区别如表1所示,其主要优势是输出逻辑是采用独立的忆阻器实现的,同时只需要一个电压激励就可以实现各种基本逻辑门。
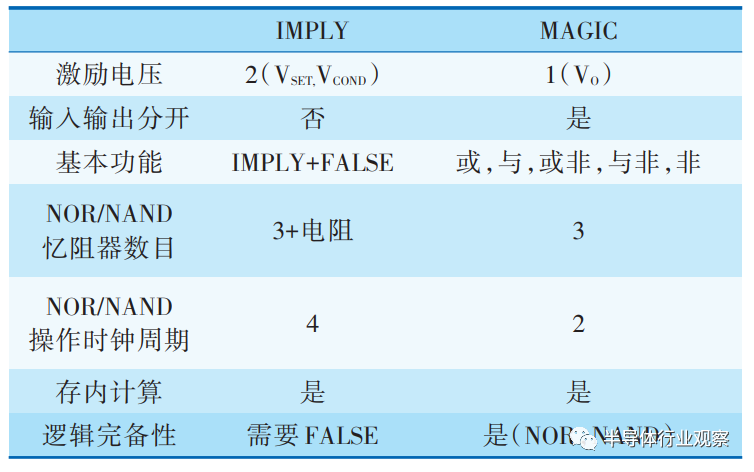
需要注意的是,以忆阻器阻值为状态的逻辑电路都被状态漂移和缺乏良好信号恢复方法所困扰。另一方面,如果需要多个电压激发一个逻辑门操作,那么就需要作为输出的忆阻器频繁的翻转,这对其寿命也是一个挑战。
在MRL(memristor ratioed logic)中,忆阻器则只是充当计算器件,而不存储最终的逻辑状态,也就是说,它采用和CMOS一样的电平逻辑,这有别于蕴含逻辑,且它的逻辑计算步骤是一步式的。MRL逻辑为了提供完备的逻辑计算功能,也引入了一个CMOS反相器,同时提高了信号整形能和与CMOS的兼容能力。
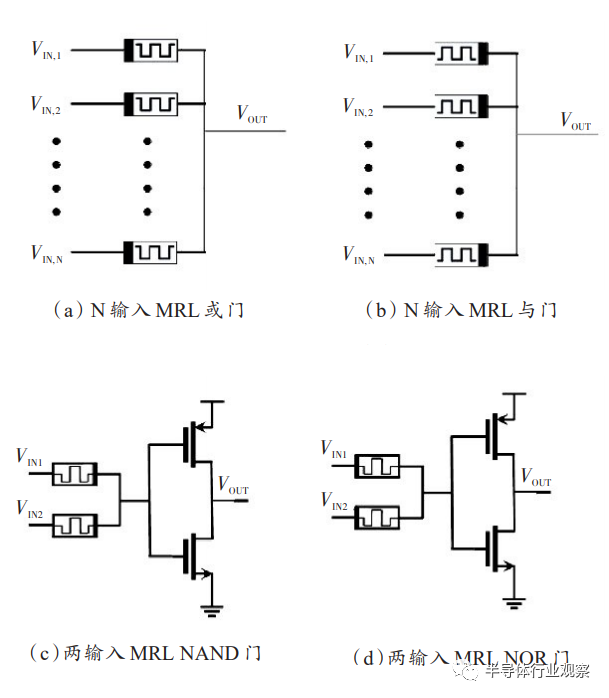
侦听逻辑(scouting logic)是一种将所有的逻辑门的操作限制在一个单一的读操作中实现的布尔逻辑体系,可以降低忆阻器的翻转率,从而不影响忆阻器的寿命。在这一逻辑结构采用的忆阻器中
,阻值代表逻辑状态,但因为引入读出结构,其状态将由电流或者电压表示。
另一种布尔逻辑实现方法利用存储器的两行或者多行单元来进行位运算,但这种布尔逻辑无法实现复杂逻辑计算。
如前所述,互补忆阻开关也可以是布尔逻辑的
实现方式。
采用两个镜像的忆阻交叉杆阵列结构来实现基本逻辑门,可以提供多扇入扇出的逻辑结构,基本逻辑操作可以在单一步骤内完成,同时逻辑操作对输入忆阻器件的状态无影响,NOR和NAND门如图3所示。

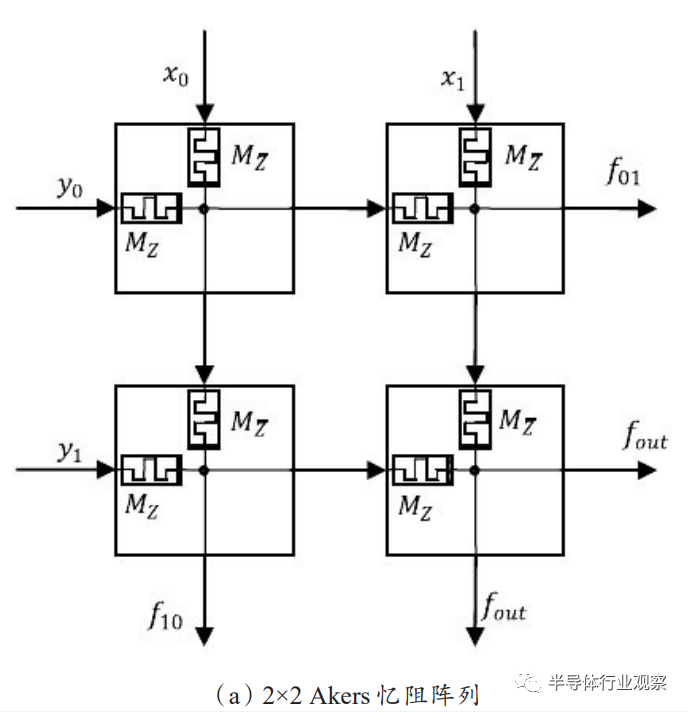
在Akers逻辑阵列中,布尔逻辑功能都是通过在阵列的基本逻辑单元之间流动数据来实现的,如图4所示,其中数据位存储在一对互补的忆阻器中而不是单一的忆阻器中,这一拥有互补忆阻器对的单元同时是逻辑操作的执行者。这种结构可以用于实现高效数据排序。令人遗憾的是,这种逻辑中同样存在输出信号退化的情况,需要提高忆阻器通断电阻的比值来降低退化的影响。
阈值逻辑是一种非传统的逻辑形式,它提供阈值门以实现输入的带权算术和超过某一阈值时进行结果输出。票决逻辑是阈值逻辑的一个子集,它的输入都是二值的,权值也是相等的。阈值/票决逻辑类的数值表达是神经形态计算的基础。为了实现阈值逻辑,一种方法是采用可编程的CMOS和忆阻器混合的逻辑结构,其中CMOS逻辑通常用于信号的放大和反向。另外一种可行的方法是混合电流镜逻辑,这种方法中,阈值的权重由忆阻器的阻值状态来代表,从而使得电压输入转化成带权的电流输入,然后求和并与阈值比较,最后获得电压输出。考虑到布尔逻辑是阈值逻辑的特殊情况,人们还可以在阈值逻辑基础上构建忆阻阈值逻辑(memristor
threshold logic)门基础上的布尔逻辑,从而形成对电路CAD的友好支持。
数值(或者说状态)的读取需要考虑3个指标:方式、速度和寿命。在方式上极大地由忆阻计算的实现结构来决定,一般而言,为了解决数值信号和CMOS的兼容和防止数值信号的衰减,阻值状态需要转化到电平逻辑上去。因此,采用CMOS反相器或者特别的读出结构就是必然的选择。对于规则的忆阻交叉杆结构,在数值的传递上可以发挥存储密集型的优势,但是因为信号的衰减或者潜通路的影响,忆阻阵列规模到目前为止是一个需要进一步突破的难题。
与忆阻交叉杆阵列的纯逻辑结构相比,以忆阻存储器来实现逻辑的方式一般都需要独特的读出和写入方式,具体实现方式包括可重构的互联,查找表、内容寻址存储器(content addressable memories,CAM)或者是序列状态逻辑。
在数值的读出、写入速度上,可以达到纳秒级别,在寿命上目前确实存在离期望还有一定的距离问题。
当阻值作为状态变量时,潜通路的影响和限制是巨大的。当然为了降低潜通路的影响,开发不同的写入方法以提高数值的传递效率,扩大阵列的规模是一种选择,开发优秀的读取方法是另外一种选择。
在蕴含逻辑的实现中,为了提高扇出能力,可以引入电流镜。
在忆阻布尔逻辑和蕴含逻辑中,为了提高逻辑结构的可扩展性,工艺变化、寄生参数、忆阻器模型等设计限制都需要考虑。特别地,针对蕴含逻辑的操作序列属性,如何将单一逻辑门的操作放到一个步骤里面实现也是重点的研究对象。
在和CMOS电路的兼容性上,从忆阻逻辑可以和CMOS电路混合形成可重构电路就可以看出,其兼容性良好,而且能够将配置信息存储在忆阻阵列中,提供保守估计10倍以上的密度(尤其是存储密度)。这一兼容性被称为是进入存储密集型计算(memory intensive computing,MIC)时代的计算机体系结构方面的激进改变的关键,MIC的两个典型应用包括多状态寄存器和非易失性的处理器,在忆阻计算中都有尝试。
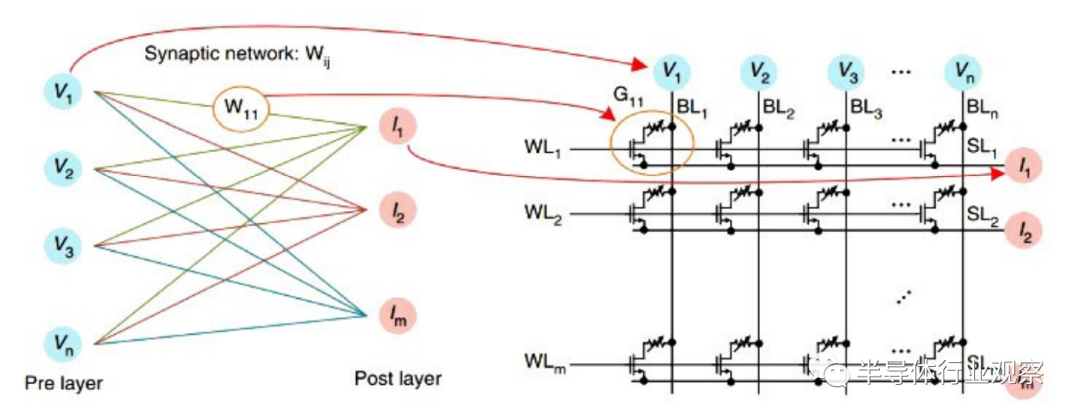
“神经形态计算”由Carver Mead在1990年提出,其灵感来自人脑处理的生物学概念,有可能取代传统的冯·诺依曼计算机体系结构。在面向神经形态计算领域的基础器件研究中,利用新器件来模拟生物突触和神经元的功能是目前的一个研究热点。忆阻器具有片上面积小、低功耗、高速、与CMOS工艺兼容等优势,与生物突触表现出来的性质十分相似,是极具潜力的突触基本单元载体。基于忆阻器的神经形态网络相比于传统计算系统主要有两个优势:首先,由于忆阻器的忆导可调,神经形态系统对纳米级器件制造技术导致的器件变化和缺陷具有高度的容错能力;其次,非易失性忆阻器有望克服冯·诺依曼计算机体系结构所面临的功耗和延迟瓶颈。
通过向忆阻器施加电压或电流可改变其内在电阻,这一行为与生物突触特别相似。此外,忆阻器可以非常高密度的方式进行集成,是当前闪存技术的几倍。这些独特的特性使得忆阻器成为大规模神经形态计算系统中最有前途的器件,吸引了大量研究者对其进行研究。
一个忆阻器(1M)就可以实现神经网络中突触的功能,1M突触实现方式具有结构简单,片上面积小,能耗低的特点。Krestinskaya等和Zhang等分别搭建了基于1M突触的神经网络,他们在系统中没有引入额外的CMOS器件。但是1M突触结构存在漏电流和误编程问题,并且这种结构无法处理负突触权重。
为了解决1M突触结构的问题,Alibart等设计了双忆阻器(2M)突触结构。2M 突触结构利用两个忆阻器来表示一个突触,将两个忆阻器通过反向器连接,可使得总体忆导值为两个忆阻器忆导相减,这样就可以实现具有正负权值的忆阻神经突触。在2M突触为基础的神经网络训练过程中,需要对两个忆阻权值分别进行改变,因此外围控制电路比较复杂。
目前忆阻器和MOS晶体管串联(1T1M)以构建突触是解决1M突触结问题的另一种有效方案。采用1T1M突触结构,通过控制晶体管的门级电压,可以安全地切断外部的编程电压,从而解决潜通路和误编程问题。2T1M突触也可以解决忆导的正负值表达问题,但此种突触的缺点是面积较大,只适合小规模电路。
忆阻桥突触也是一种在人工神经网络中实现突触权重的候选者,此外忆阻桥电路还可以实现乘法器,可用来替代传统的模拟乘法器。Adhikari等设计了4个忆阻器组成的忆阻桥突触,其中为了补偿忆阻桥突触的空间不均匀和非理想特性,还提出了一种适合于其所设计的神经网络体系结构的在线学习方案。
Alibart等通过构建基于TiO
2-x
忆阻交叉阵列的单层感知机网络,实现了模式分类,其电路结构如图5所示。TiO
2-x
器件的IV特性是非线性的,因此为了在交叉阵列中抑制潜通路电流的影响,基于TiO
2-x
的忆阻器阵列被限制在小的规模。该感知机网络可以通过原位和异位方法训练。对于异位方法,使用软件计算突触权重;对于原位方法,在忆阻交叉阵列中直接调整突触权重。异位方法易于实施 ,只需要较短的训练时间。这项工作展示了基于概念验证的忆阻ANN。虽然面临相当的技术困难,然而可以期望的是,通过将这项工作扩展到大规模电路中,有望将其用于实现复杂的神经网络。
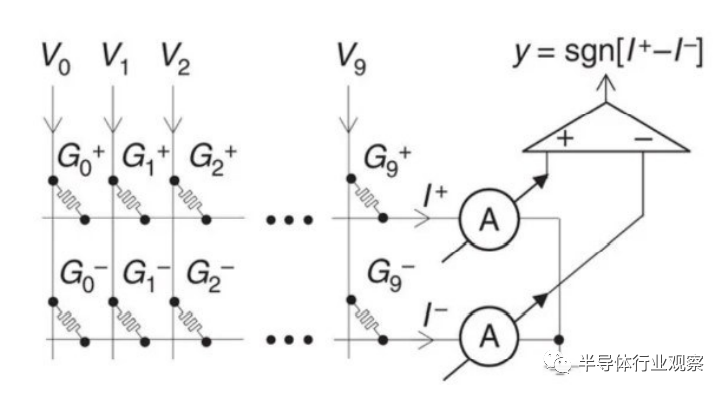
Prezioso等实现了基于2M结构突触的忆阻交叉阵列,也可构成单层感知机网络,其电路结构如图6所示。利用delta规则算法对该网络进行训练,可将3×3黑白像素分为3类。
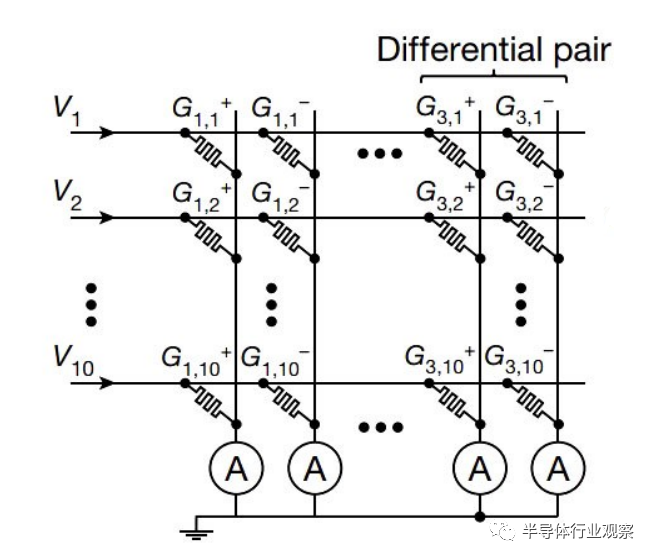
清华大学Yao等基于1T1R突触结构的忆阻交叉阵列实现了单层感知机网络,并用之于识别9张灰度人脸照片中不同的3个人。其电路结构如图7所示,神经网络的输出层与1T1R忆阻器阵列的选择线(SL)对应,输出为加权求和后的电流值。神经网络中的突触与阵列中的忆阻器对应,其中权值大小对应忆阻器的忆导大小。
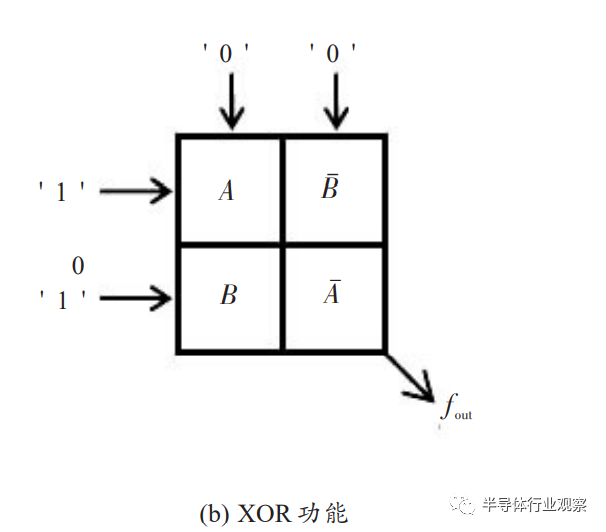
Zhang等设计了基于1M的突触结构,并将其用于忆阻多层神经网络,通过自适应反向传播算法训练网络,可以实现XOR功能和字符识别。Burr等使用两个相变存储器作为一个突触,通过在神经形态系统中对突触施加连续脉冲,可以实现较好的增强和抑制特性。他们建立了一个3层感知器网络,在MNIST数据集上训练了总共164885个突触,达到了82.2%的训练准确度。在该研究中,作者还发现基于相变存储器的网络可以容忍器件的一定变化。
CNN网络结构最早是由Fukushima于1980年提出的,但是由于其训练算法难以实现,因此当时未得到广泛应用。在20世纪90年代,LeCun等在CNN中应用了基于梯度的学习算法获得了成功。现在CNN已被证明是针对多种分类任务、图像识别问题和视频分析的有效解决方案。与CNN的软件实现相比,基于忆阻电路的CNN硬件实现并不多。
Gao等将CNN中的卷积核从二维变换到一维,把神经网络中卷积核的权值映射为忆阻交叉阵列中忆阻器的阻值,将图像像素值转换成读电压输入到忆阻交叉阵列,实现了卷积操作的并行运算,图8为其实现过程。
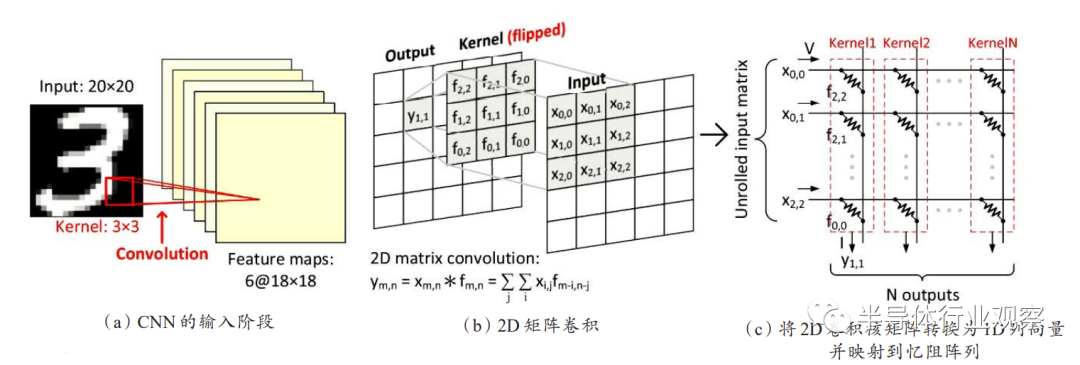
Yakopcic等
设计了基于忆阻交叉阵列的CNN,其中利用忆阻阵列代表卷积核执行卷积操作,实现手写数字识别的准确率达到94%。Ni等构造了基于忆阻交叉阵列的二值CNN,利用忆阻交叉阵列和辅助电路完成了二值的卷积、归一化、池化等操作,实现了低功耗的CNN。
在过去的十几年时间中,脉冲时间依赖可塑性(STDP)的发现为神经网络的研究开辟了新途径。理论研究表明,STDP学习规则可用于训练脉冲神经网络(SNN)而无需权衡其并行性。Jo和Chang等制备了一种纳米硅基忆阻器,并展示了由CMOS管构成的神经元和忆阻突触组成的混合电路可以实现STDP学习法则。Cai等对一种具有自适应阈值的忆阻器进行了高阶建模,成功展示了双脉冲和三脉冲STDP学习过程,在其中忆阻阈值可以根据具体情况自适应调整,很好地实现了Froemke抑制原则。Ntinas等基于压控忆阻器的行为模型,开发了数字忆阻硬件仿真器,在此基础上演示了STDP学习规则。
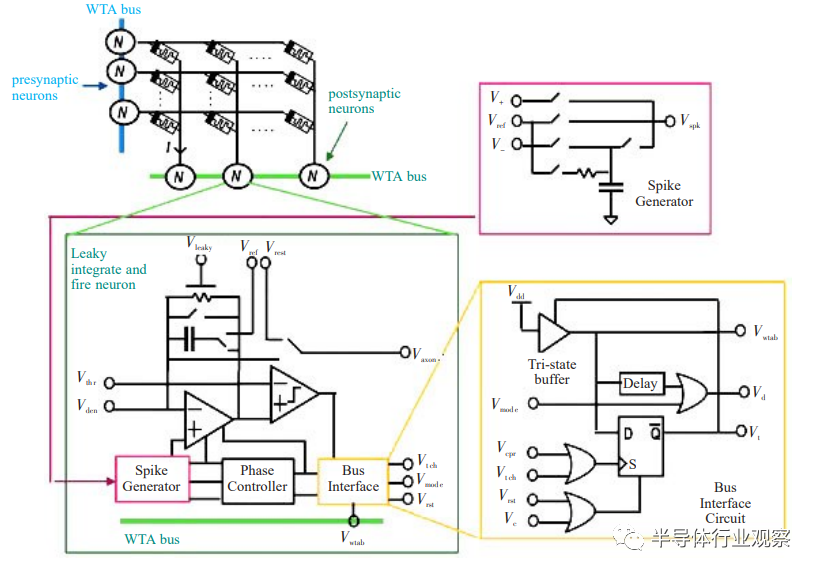
Wu等设计了基于忆阻器的SNN架构,如图9所示,它由1M突触结构连接的前神经元和后神经元组成。系统中的忆阻突触采用STDP规则学习,其神经元采用“赢者通吃”策略,自然地实现了突触的在线学习和计算功能。该设计展示手写数字识别之10位数字的识别正确率为83%。
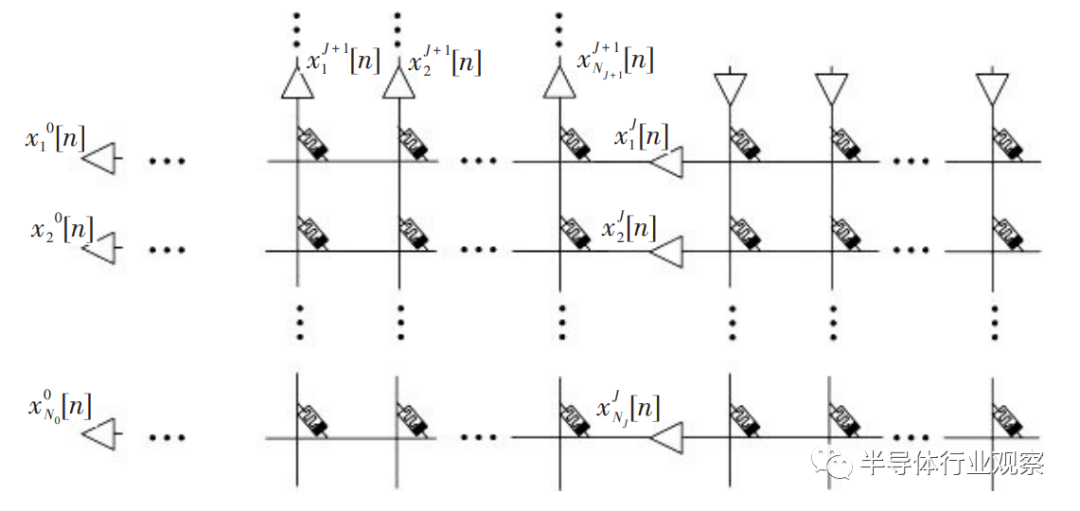
Zhou等证明了RRAM阵列可以表现出出色的二进制STDP特性,并基于这一特性,构建了一种新颖的无监督在线模式识别系统。仿真结果证明,该系统可以有效完成手写数字识别任务。Pedretti等实现了基于忆阻突触的SNN网络中模式的无监督学习和跟踪。其实现的网络中突触结构为1TIM,只有2个突触状态,即低抵抗状态和高抵抗状态。实验结果表明,由于采用在线无监督学习模式,突触权重可以实现动态跟踪。Zheng等提出一种在线学习算法,用于多层脉冲SNN的监督学习。作者发现可以利用SNN中神经元的脉冲时序来估计突触的梯度,以此为基础,提出了估计梯度的方法,实现了类似于传统ANN中采用的随机梯度下降方法的学习过程,在MNIST数据集上进行测试,可达97.2%的识别精度。之后,他们又提出了一种基于忆阻交叉阵列的SNN架构,图10中给出了这种SNN硬件架构。在该研究中,研究人员考虑了神经网络中存在的各种非理想性,包括CMOS神经元和忆阻突触的变化以及更新突触权重时的噪声,证明了所提出的学习算法和硬件体系结构对大多数器件变化和噪声具有鲁棒性。该结构对手写数字识别任务的识别精度高达97.1%。
Wijesinghe等基于忆阻器将ANN转化为深度随机SNN,并通过实验证明了即使在非理想情况下该神经网络的图像识别精度仅比基线精度下降约1%,而功耗则比同规模CMOS网络少约6.4倍。Tavanaei等提出了新颖的监督学习算法,其中既可以得到准确的下降梯度,也可高效实现STDP学习规则。
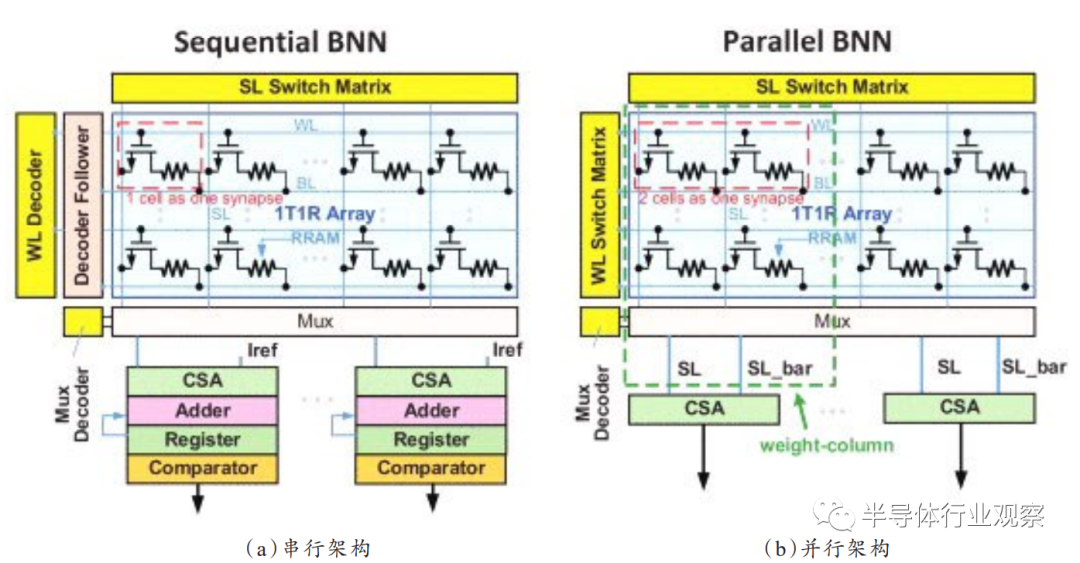
除了上面介绍的几种忆阻神经网络,一些基于忆阻器的新型网络架构也被提出来了。Sun团队设计了基于忆阻器的二值神经网络,其有两种形式:串行和并行,其结构如图11所示。串行结构采用1M突触结构,并行结构利用两个忆阻器表示一个权值。这一工作表明基于忆阻器的二值神经网络硬件化能够有效降低神经网络硬件的面积、功耗,是很有前景的神经网络计算加速方案。
Truong等搭建了基于忆阻交叉阵列的层次时序网络,通过忆阻器将感官信息转换为稀疏分布表示(SDR),并基于MNIST数据集进行测试,识别准确率高达 95%。概率神经网络(PNN)是为解决分类问题而开发的前馈人工神经网络,Krestinskaya等设计了基于忆阻器的PNN网络架构,该架构利用忆阻交叉阵列计算点积乘法,对权重进行归一化,并量化为16个级别,降低了电路的复杂度。该实现在Iris数据集上进行验证,带有阈值逻辑的APNN算法的准确率为98%。Du团队利用具有短时记忆特性的忆阻器构建储存池系统直接处理时域中的信息,并证明了利用只有88个忆阻器的小型硬件系统即可完成手写数字识别。此外,该系统还可用于二阶非线性任务。
目前,忆阻器面向大规模的神经形态计算实用电路还存在一些挑战:(1)忆阻器的阻值具有一定随机性。这种随机性主要有两种:空间随机性和时间随机性。空间随机性源于不同的制造技术和工艺导致器件和器件之间存在差异;而时间随机性则源于忆阻器忆导会随着工作电压的周期变化而变化,同时在不同周期之间也存在差异。(2)与当前CMOS制造工艺的兼容问题。即使忆阻器为双端元件,可确保减小忆阻电路的面积,但复杂忆阻神经形态架构的制造过程仍然非常困难。在忆阻阵列和CMOS电路相结合的复杂多层架构中,制造温度的控制就是一个关键问题。较高的温度会损坏器件,而低温又不能保证元件之间的有效连接。(3)大规模电路集成和规模扩展问题。目前,大多数研究所实现的电路中实际运行的忆阻交叉阵列拥有少于1000个忆阻器,这阻碍了忆阻神经网络的实际应用。造成这种现实主要是因为:一是将大量的忆阻器集成到一个交叉阵列,寄生电阻的影响将增强,会大大降低阵列加权求和的精度;其次器件和器件之间的差异会对数值(例如神经网络权值)的配置产生不利影响。
探索解决随机性、CMOS兼容性和实现大规模集成的方法是目前的研究热点。进一步的材料和器件开发对于解决忆阻器随机性问题至关重要,而开发合适的算法、体系结构也是重要途径。为了应对大规模集成问题的挑战3D堆叠可能是一种潜在的良好解决方案,目前人们发现该结构设计方案可以有效减小忆阻寄生电阻的影响。
在计算领域,人们总期望获得精确解,但是许多应用中,精确解的获得需要通过复杂的计算过程,因而需要较长的计算时间、高性能的计算资源、更多的存储和更多的功耗。为了解决这一问题,在诸如信号处理、模式识别、计算机视觉和自然语言处理等应用中,人们容忍其结果的不精确性,发展了近似计算技术。近似计算牺牲了不必要的精度,提高了效率、性能,降低了功耗,从而获得了额外的收益,是推进这些应用最可行的方法之一。
图12展示了忆阻器近似计算单元(memristor
approximate computing unit,MACU)的一种典型结构。MACU是基于忆阻器的前馈多层网络(含一个隐藏层)的硬件实现,其前馈网络的基本操作是矩阵向量乘法,该乘法被映射到忆阻交叉杆阵列,用于计算输出,交叉杆阵列的输出
V
oj
可以表示为:
其中
V
ik
和
V
oj
是每行和列的输入和输出电压;
k
和
j
分别表示输入电压和输出电压的索引值,也是交叉杆阵列的行和列的索引号;
M
kj
和
g
kj
分别表示交叉杆阵列中每个忆阻器的电阻和允许值R是交叉杆阵列末端引入的电阻。
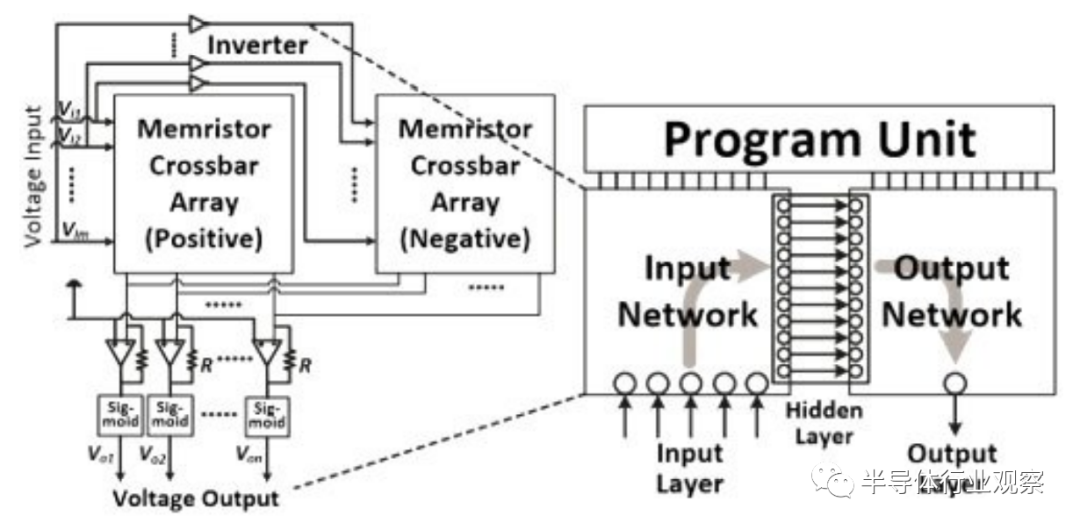
在这一结构中,运算放大器用于提高输出精度并隔离两个网络层。所有运算放大器都作为电流反馈放大器工作,以便交叉杆阵列实现矢量矩阵乘法。由于R和忆阻器阻值M只能为正数,所以采用两个交叉杆阵列来分别表示网络的正负权重,前述已经提到,类似结构在多种神经形态计算网络结构中出现。
在MACU基础上,通过将两个双层网络结合在一起,可以实现多层前馈网络单元(具有一个隐藏层),从而构成一个通用的近似计算器,用于向量乘、倒数、正弦、对数、指数、开方等运算,在良好控制噪声条件下,该电路进行的近似计算可以达到MSE小于10
-7
。
图13给出了基于MACU的一种忆阻近似计算框架。框架的基本单元是忆阻处理单元。每个忆阻处理单元由若干MACU组成。每个忆阻处理单元还配备自己的模数转换器,以生成模拟信号进行处理,并维持一段时间,直到MACU完成计算。此外,忆阻处理单元还可能具有多个本地存储器,用来根据功能需要以忆阻器阻值的形式存储模拟数据。全部忆阻处理单元都以循环算法控制方式通过两个多路选择器组织。
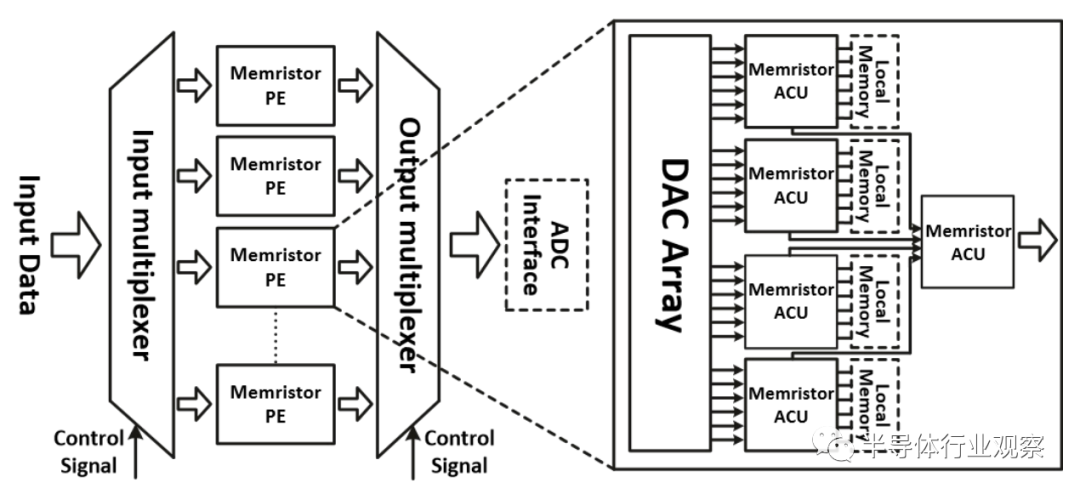
这一框架是可扩展的,用户可以根据个人需求对其进行配置。例如,对于所需功耗效率高的任务,可以选择低功耗运算放大器来构建MACU,并且忆阻处理单元在低频下工作。对于高性能的计算,则选择高速运算放大器和ADC以及层次式任务分配方式。
当然随着操作时间的增加,MACU也会缓慢退化,其原因是忆阻器的参数从初始状态逐渐漂移,这是忆阻计算面临的常见开放问题。另一方面,忆阻处理单元互连结构也是性能的重要决定性因素,这一点我们在忆阻神经形态计算网络研究介绍中已有认识。
研究表明,忆阻器在未达到电压阈值的激励下存在随机的开关行为,导致了逻辑门的概率输出。基于这种固有的随机性,人们提出了一种新颖的近似计算方案:在蕴含逻辑的基础上,引入概率输出,可以牺牲一定程度的精度来达成近似计算,并提高功耗效率。
在这一研究中,首次在一位加法器中引入概率行为分析,在这个基础上,随机加法器被提出来。该研究还表明,如果采用更长的时间周期,则在更低的电压水平下可以实现更多的功耗节省。
Nourazar等展示了为通用X86处理器设计基于忆阻器的近似计算加速器的可行性。设计的加速器是一种基于忆阻器的混合信号矢量-矩阵乘法器,也能够处理浮点符号复数。当然这一乘法器主要用于加速CNN。与神经形态计算的区别是,这一研究的重点在于利用其近似计算特性。该研究的评估是通过一个全系统仿真器实现的,其中耦合了周期精度的MARSS x86处理器模拟器与Ngspice混合电平/混合信号电路模拟器。在验证中,基于忆阻器的电路加速器在一个64×64的矩阵乘法上以90%的精度获得了超过100倍的加速和能耗节省。该加速器的结构如图14所示。加速器由多个处理单元组成,这些处理单元可以通过扩展指令集架构(ISA)方式同时用于独立计算,也即ISA扩展了新的指令以配置和控制紧耦合的忆阻加速器。
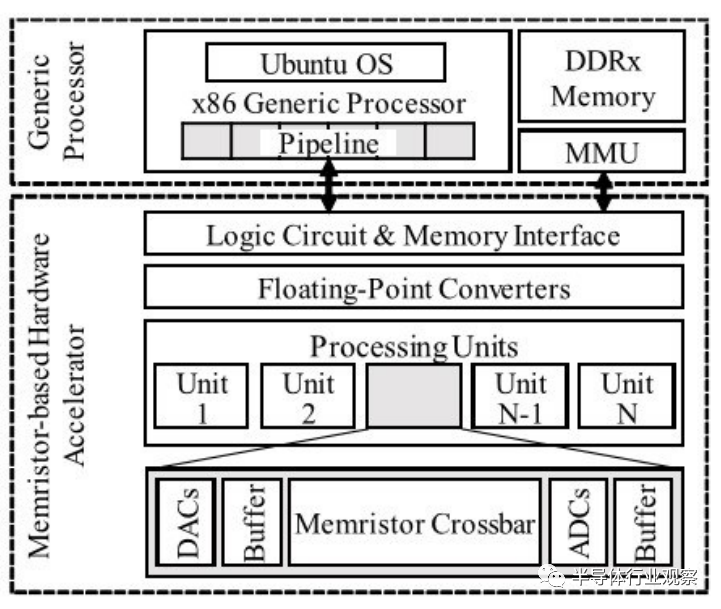
处理单元具有混合信号架构,包含一个基于忆阻器的交叉杆阵列、输入输出缓冲器和逻辑电路,为了执行复数和非复数的正数或负数的乘法还引入了模拟开关扩展忆阻器交叉杆阵列。输入缓冲器采用先进先出(FIFO)结构进行主要应用中的卷积运算。
忆阻近似计算已经崭露头角,在近似计算单元和框架上已有了基本的尝试,可以看出,其功耗优势将是这种应用的最大优势。同时,也不能低估在电路规模扩展性、体系结构等上遇到的困难。
虽然忆阻器在神经形态计算和近似计算等领域已经被证实拥有超越传统CMOS 电路功能所受传统限制的高功效,但通过引入忆阻器进行逻辑电路的结构和架构创新进而取代传统数字逻辑电路构成的精确计算系统仍是忆阻计算的最大和最重要的目标之一。从前文可以看到,忆阻器独特的电气特性和状态保持能力为集成电路提供了新的设计方法和设计理念。基于忆阻器的逻辑电路与传统数字逻辑电路相比主要有两个方面的突破,一是通过忆阻器的阻变特性实现状态逻辑电路,打破了冯·诺依曼瓶颈从而可以形成存算融合的体系结构;二是基于忆阻器的电气特性设计更高效的逻辑电路,从而减小电路的面积、功耗,提高能效比。
从前述可以看出,研究人员着眼于基于忆阻器实现完备的布尔逻辑,已经涌现出了IMPLY、MAGIC、MRL、LTG、MAD、CRS、MIG等多种不同的逻辑实现方法,它们能通过一些基本逻辑单元和操作的组合来实现复杂的布尔逻辑函数。在这些逻辑设计方法的基础上,以加法器和乘法器为代表的复杂逻辑运算电路设计成果不断涌现,目前不同的设计方法和设计思路还处在百家争鸣的状态 ,没有哪一种设计方案确立了绝对优势。
与此同时,研究人员还从更高层次着眼于忆阻计算系统的研究,他们的目标是设计出存算一体的通用硬件架构。基于IMPLY逻辑的内存处理器和基于内存查找表的FPGA是最早发展的存内忆阻计算系统。目前的研究表明,忆阻计算系统与传统的硬件方案在架构上存在很大区别,其性能优势不能仅通过底层逻辑单元的高效性来展现。综合起来看,基于忆阻器的电路结构和架构创新是发展忆阻精确计算系统的两个主要路径。
加法器和乘法器是许多复杂计算系统的最重要的基本模块,它们决定着系统的精确计算能力,因此目前忆阻电路结构创新也主要集中在加法器和乘法器的设计上。
基于忆阻器的加法器主要有两种设计理念,一是实现存内加法器或非易失性加法器,二是设计出比传统CMOS加法器性能更好的电路结构。Bickerstaff等最早研究了基于蕴含逻辑的加法器设计,其中1位全加器需要19步操作,n位加法器步骤数目为8n+12。该研究指出尽管忆阻逻辑有着逻辑密度和速度方面的优势,忆阻阵列实现蕴含逻辑时仍然存在操作延迟和控制编程逻辑开销较大的问题。Shaltoot等通过优化逻辑表达式以减少蕴含操作的步骤数目,进一步设计了基于蕴含逻辑的超前进位加法器,并指出这种加法器随着输入数据位宽加大能提
供比传统超前进位加法器更好的性能。Guckert等通过把每一位加法并行执行的方式用7n+1个忆阻器实现了2n+19步的并行加法器,如图15所示。该研究还指出不同器件的延迟不同,不能通过步骤数直接比较忆组逻辑电路和CMOS电路的性能。Ahmad等认为Guckert等提出的并行加法器面积太大,因此提出了新的并行和串行结构,其中并行结构需要4n+1个忆阻器和5n+16步,串行结构仅需要2n+3个忆阻器和21n步。Rohani等借鉴并行结构的思想实现了1位加法器内的并行性并提出了一种半并行结构,在2n+3个忆阻器内实现了17n步的加法器。
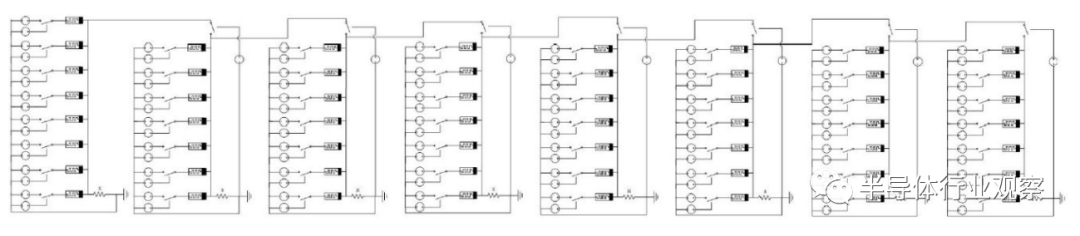
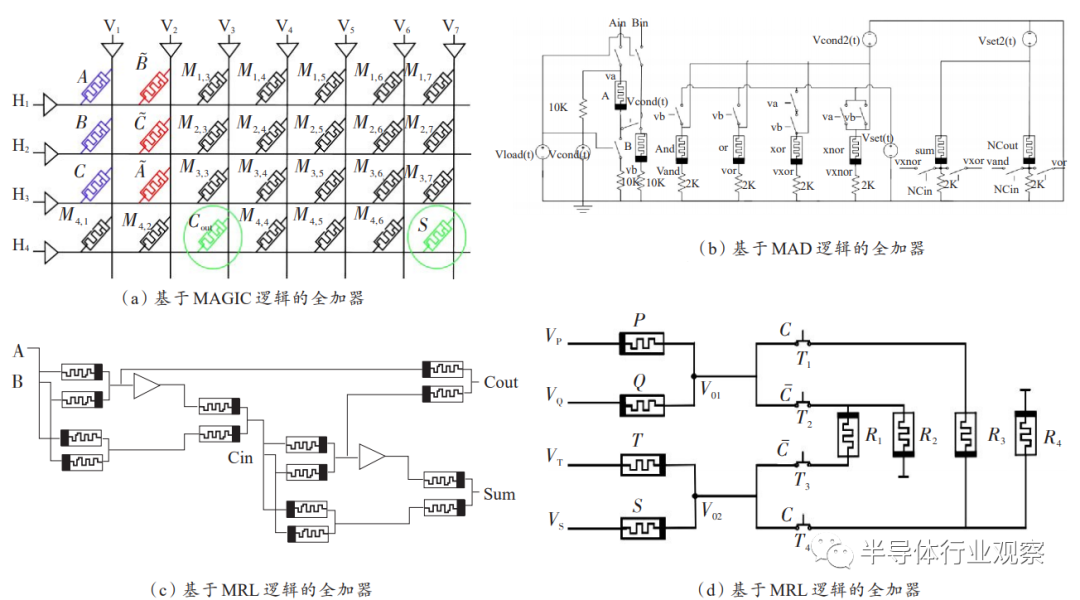
受限于蕴含逻辑复杂的序列操作特性,这些加法器的运算速度无法得到根本性的提高,而且蕴含逻辑也存在漏电流等其他一些固有技术问题。因此部分研究人员致力于发展其他逻辑基础上的非易失性加法器和电平逻辑的忆阻-CMOS混合加法器。Siemon等提出了两种基于CRS逻辑的串行加法器,分别需要2n+2个忆阻器、2n+4个操作步骤和n+2个忆阻器、4n+5个操作步骤。由于CRS逻辑同样可以在无源忆阻交叉杆阵列上实现,并且没有蕴含逻辑存在的严重漏电流以及信号退化问题,所以该方案可能是实现存内计算的一种有竞争力的选择。Talati等利用MAGIC逻辑实现了基于忆阻阵列的非易失性加法器,与蕴含逻辑相比较其速度和功耗表现均有较大的提升,如图16(a)所示。Guckert等基于蕴含逻辑提出了具有阻值感知功能的MAD逻辑,并基于MAD逻辑设计了一个具有按位流水特性的加法器,仅需8n个忆阻器和n+1步,如图16(b)所示。Wang等基于MIG逻辑设计了1位全加器,可以在3个忆阻器内用4步实现非破坏性读出的加法器,该加法器可以用两步实现位的扩展。Cui等设计了一组基于RRAM的4步逻辑门,可以实现门级逻辑块间的流水结构,在该逻辑结构基础上设计的n位加法器具有良好时序特性,可以在2n+2步内完成。在基于电平逻辑设计方面,Guckert等基于MRL逻辑提出了忆阻器-CMOS混合加法器,如图16(c)所示,该加法器需要14n个忆阻器和12n个晶体管,其门级延迟为3n+4。该研究指出忆阻器开关延迟特性比CMOS要好,所以同样的组合逻辑结构下忆阻器-CMOS混合电路的延迟会比CMOS更短。由于电平逻辑的延迟仅由电路电平信号的传播延迟决定,所以电平逻辑电路的运算速度远远高于依赖于控制电路的非易失性逻辑电路。Liu等利用一种基于MRL逻辑的复合逻辑门简化了超前进位加法的设计,与文献提出的基于蕴含逻辑的超前进位加法器相比该设计所用的忆阻器数量更少。Wang等基于MRL逻辑提出了一种可以保存运算结果状态的新逻辑,并利用其设计了可逐位进位的加法器,如图16(d)所示。该逻辑利用电平信号作为输入、输出保存在忆阻器阻值状态中,并可以实时通过电平信号读出。该研究为设计非易失性加法器提供了新的思路,然而,该设计的存储密度和集成度都比阵列型电路要低。
乘法器是DSP、CPU等处理器和众多通信系统的核心部件,主要由加法累加器、部分积生成器和移位器等构成。硬件乘法器通常是信号处理算法的关键路径所在,其时延决定了系统的最高运行频率。基于忆阻器的乘法器的出现,为乘法器设计提供了新的思路和视角。
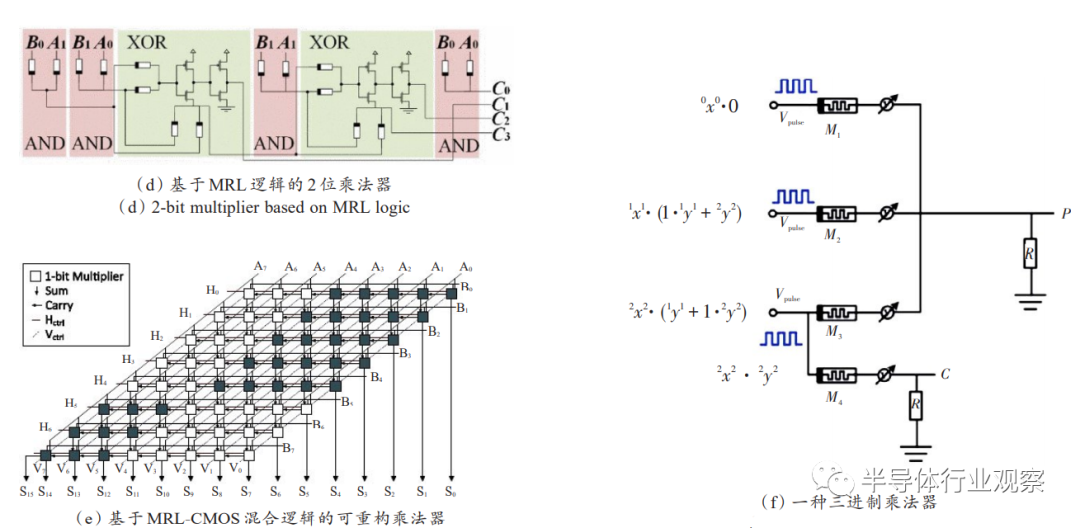
Bickerstaff等最早研究了基于蕴含逻辑的乘法器设计,4位乘法器可以在73个步骤中完成。Guckert等发展了基于蕴含逻辑的乘法器并设计了基于MAD逻辑的乘法器,如图17(a)(b)所示,其中蕴含逻辑乘法器由7n+1个忆阻器构成,需要2n
2
+21n个步骤完成,并且可以进行24个步骤的位流水,有效延迟为 24n。为了解决蕴含操作的复杂序列带来的时延问题,MAD逻辑乘法器被引入,可以由5n个忆阻器在n
2
+n步内实现,并且具有4n步流水功能。Haghiri等通过优化逻辑表达式的方法将基于蕴含逻辑的2位乘法器的计算步骤缩减到8步,该设计使用了20个忆阻器。Radakovits等设计了一种基于半串行加法器的蕴含逻辑乘法器,如图17(c)所示,该设计对忆阻阵列结构进行了调整,使加法具有位间并行性,该乘法器使用2n
2
+n+2个忆阻器在log
2
n(10n+2)+4n+2 步内完成计算。Wang等设计了基于MIG逻辑的4位Wallace树乘法器,并在一个由FPGA控制的忆阻阵列上进行了芯片级验证。该设计利用51个忆阻器在64步内完成了4位乘法运算。Cui等利用设计的4步逻辑门构建乘法器,可以在6n-4个周期内输出乘法计算结果,并且具有2n+2步流水功能,该设计具有逻辑门间直接级联和流水的特性,可以实现高吞吐率的存内计算。
从前述可以看出,存内计算基础上的乘法器设计通常需要较多的步骤,这导致了严重的时延问题,目前性能最好的存内计算乘法器的时间复杂度在O(n)级别。因此,部分研究者着眼于利用忆阻器快速开关和高集成度特性来优化传统乘法器的性能,亦或基于忆阻器的电气特性实现较为新颖的乘法器结构。Teimoory等利用基于MRL逻辑的复合逻辑门进行了2位乘法器的设计,如图17(d)所示,该结构仅需16个忆阻器和8个晶体管就可以1步完成2位乘法运算。Lee等基于MRL-CMOS逻辑设计了一种混合结构的可重构乘法器(如图17(e)所
示),验证表明该设计可以在与传统乘法器几乎相同的延迟下减小电路的面积和功耗。Baek等发展了该可重构乘法器,通过流片进行了进一步的评估,以FFT 为例展示了该可重构乘法器的流水功能。Chen等利用三值忆阻器实现了一种三进制乘法器,其输入为具有3种电平状态的方波序列,输出为3进制电平信号,如图17(f)所示。可以看到,其中一些设计从传统技术指标来看并不十分高效,但它们提供了相当不错的设计思想,证明在忆阻器基础上具有设计不同工作方式的逻辑电路的潜力。

现代计算系统的各种处理单元主要由加法器、乘法器、计数器、多路复用器、移位寄存器等复杂逻辑电路构成,它们并非简单地由基本逻辑门组合而成。在高层次电路设计中,自底向上的设计通常包括组合和优化。由于忆阻器特殊的电气特性和目前已有的基于忆阻器的多样化逻辑工作方式,优化设计在基于忆阻器的复杂逻辑电路设计中发挥着重要的作用,许多复杂的逻辑功能可以不拘泥于基本逻辑门的设计方法而被高效地设计出来。
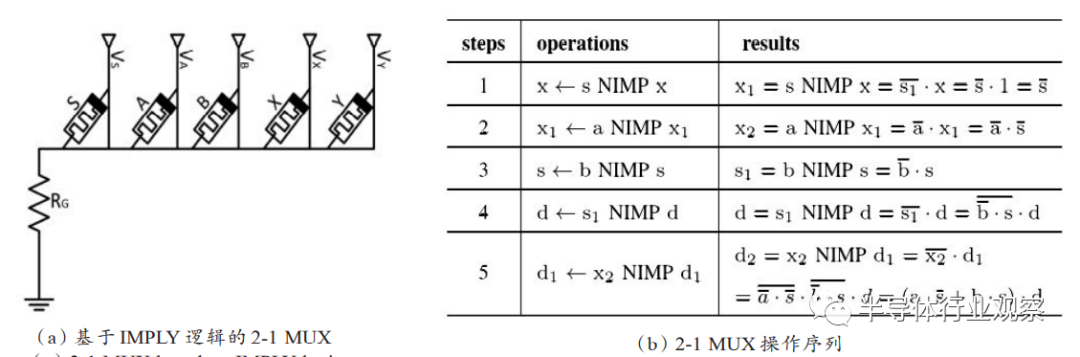
以多路复用器为例,Owlia等设计了一种基于蕴含逻辑的多路复用器,其中2-1 MUX由6个忆阻器在7个步骤内完成一次数据选择输出。基于CMOS逻辑的2-1 MUX一般由5个逻辑门构成,相比之下基于忆阻器的设计在功能实现上具有明显的效率优势。该研究指出在基于忆阻器存储阵列的体系结构中由CMOS构成的接口电路一般占主要面积,多路复用器的引入可以有效增加单位面积的功能,
从而提高整个系统的效率。Wang等进一步发展了基于蕴含逻辑的多路复用器电路结构,将2-1
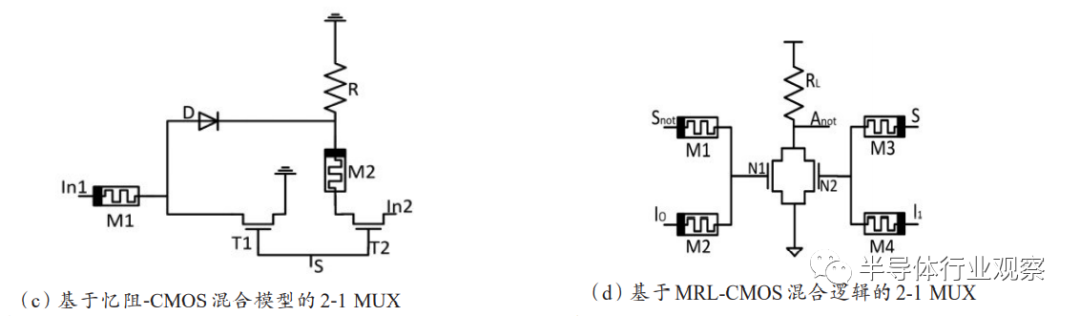
MUX使用的忆阻器数量降至5个,步骤降为5步,并给出了n位输出的扩展方法,提出了相应的外围读出电路。该设计基于NIMP操作,可以有效缓解内存计算中的信号退化问题,如图18(a)(b)所示。Karimi等基于多输入的AND和OR操作分别提出了n位多路复用器的设计方法,该设计在输入位扩展时能提供更好的性能。除了基于蕴含逻辑之外,还有其他创新的多路复用器结构被提出。Priyanka等基于忆阻-CMOS混合模型提出了4:1和8:1的新型多路复用器,如图18(c)所示,该设计与传统的CMOS设计相比功耗、面积和时延都有所减少。Verma等基于MRL-CMOS混合逻辑设计了一种2:1多路复用器(如图18(d)所示),并在特定工艺下和CMOS进行了比较,计算了相关参数,验证了忆阻器高集成度、低功耗的优势。
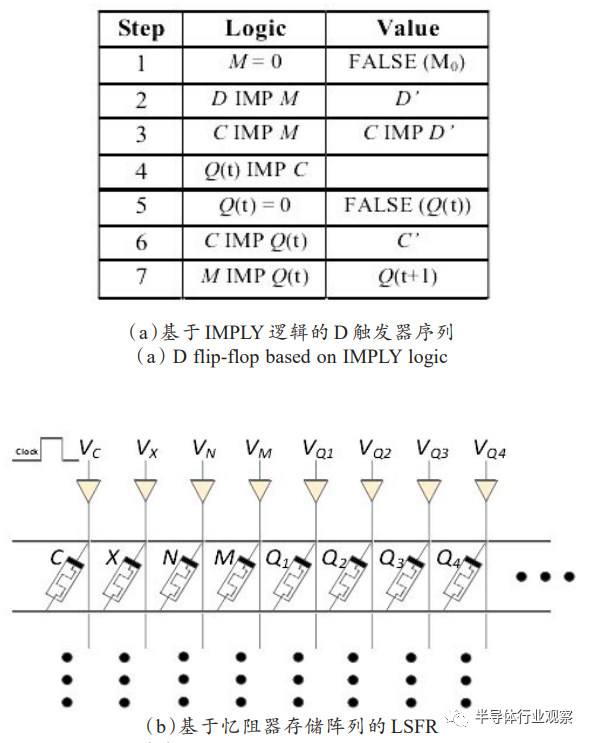
一些研究采用了传统的电路结构方案来设计复杂逻辑电路,但电路本身具有存内计算的特点,为存算融合的体系结构提供了参考。Teimoory等设计了一种基于蕴含逻辑的线性反馈移位寄存器(LSFR),由8个忆阻器组成,可以在55个步骤内生成4位数字。该设计还基于蕴含逻辑在忆阻器存储阵列上实现了D触发器的功能(如图19(a)),并进一步构建出LSFR(如图19(b))。Chakraborty等设计了基于蕴含逻辑的T触发器,并在此基础上构建了一个基于存储器的4位计数器,其中T触发器和计数器分别由6、16个忆阻器构成,操作序列分别有11和52步。
存算融合体系结构在突破冯·诺依曼瓶颈上被寄予了厚望。在这一条道路上,许多路径已经被研究人员探索过,例如基于闪存的存算一体架构已经被成功地商业化了。但基于忆阻器的存算一体化和此前的许多方案并不一样,它提供了一种新型的CIM(computation-in-memory,CIM)架构。CIM别于PIM(processing-in-memory,PIM)架构,其试图缩小内存和处理器间的距离 ,但是计算仍然在一个单独的物理单元中进行,虽然CIM有时也被称为PIM。目前的研究表明,以蕴含逻辑基础为代表的CIM架构具有极高的电路复用性,不同的逻辑运算可以在同一片电路内重复进行。然而,这样的架构需要依赖于控制逻辑和外围电路的辅助才能进行正常工作,脱离这些硬件部分来对电路体系进行评估无法得到全面的结果。因此研究人员需要致力于构建完整的存算融合体系结构,深入挖掘忆阻器在精确计算系统当中的应用潜力。
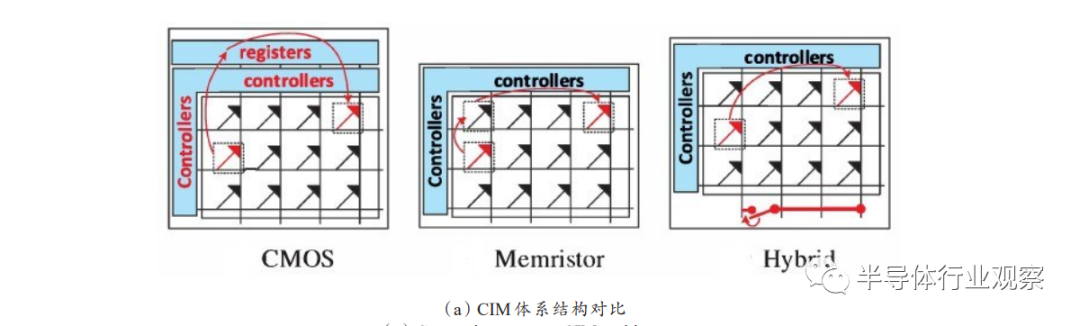
基于前述的现实,人们对忆阻计算体系结构的研究集中于忆阻器阵列内部的互联网络结构和包含一定控制逻辑和外围电路的整体性方案上,而且两者都致力于提供具有一定通用性的计算系统框架。CMOS技术中采用的互连网络和通信方案,由于工作原理完全不同,不完全适用于忆阻器存储阵列。Hamdioui等提出了基于忆阻器的CIM体系结构的基本框架,分析讨论了该架构的应用需求和潜在优势。由此我们知道,基于忆阻器的CIM架构主要面向数据密集型应用,具有高并行性、非易失性、低功耗和面积小等优点。Nguyen等在此基础上提出了基于忆阻存储阵列和忆阻器-CMOS混合结构的两种CIM架构,并针对并行加法器评估了两种互联网络方案的延迟、面积和功耗以及与CMOS作为互联网络的方案进行了比较,如图20(a)所示。研究指出,完全集成在忆阻器阵列上的互连网络效率不高,可能导致性能大幅降低,这是因为该架构在计算时如果输入忆阻器不在同一行或者列上则需要进行拷贝操作。相比而言,混合互联网络方案在时延、能量和面积方面具有最高的效率。
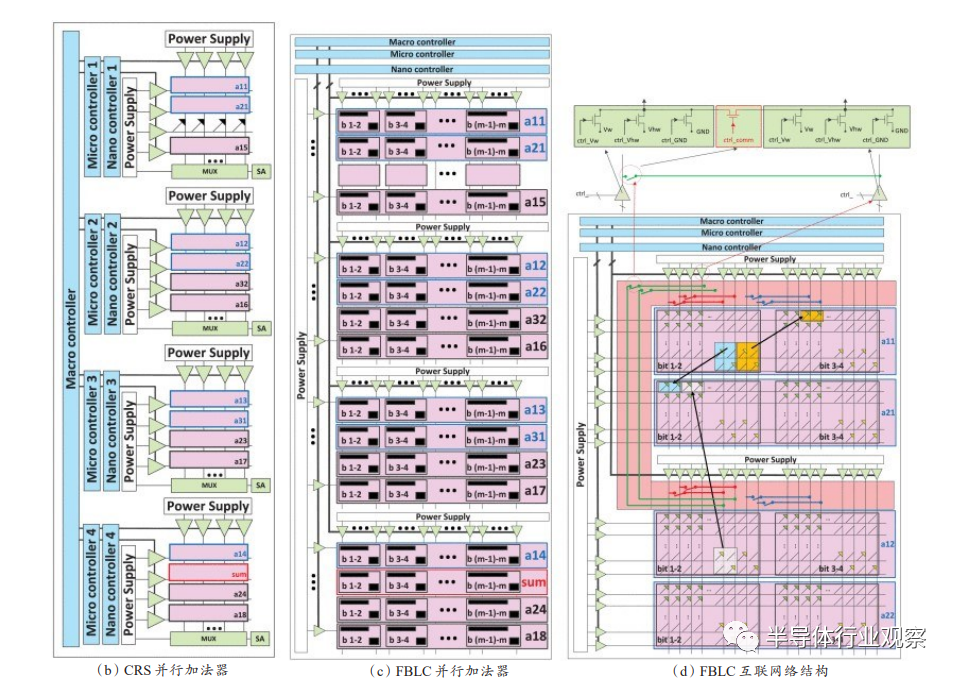
为了准确评估基于忆阻器的存内计算架构的性能,需要将其与传统的解决方案进行对比。Nguyen等讨论了基于蕴含(CRS)和非蕴含逻辑(FBLC)的两种并行加法器在忆阻器存储阵列上的实现,全面评估了包括忆阻器阵列和CMOS控制器在内的电路时延、面积、功耗和可扩展性,电路架构如图20(b)(c)(d)所示。研究结果表明忆阻CIM并行加法器在功耗延时积、能效和面积效率方面的性能显著优于等功效的多核、GPU和FPGA实现。Nguyen等还基于类似的架构比较了忆阻CIM体系结构和传统的多核处理器架构的性能,结果显示忆阻CIM架构有10倍的性能-能效比,能效提升超过4个数量级。
一些研究提供了包括外围电路在内的整体性解决方案。例如Li等提出了一种名为 Pinatubo的存内计算架构,该架构没有集成复杂的逻辑,但是可以通过外围电路高效地进行一步多行的按位操作,计算结果可以直接输出或者写回到内存中。该研究还提供了相应的软硬件接口,可以方便地对该架构进行测试。Pinatubo 架构和最先进x86处理器对比测试结果表明,该架构相比于传统处理器有1.12倍的总体加速和1.11倍的总体节能。Imani等提出了一种名为MPIM的存内计算架构,它提供了基于kNN算法的数据搜索功能和高度并行性的位操作功能。实验表明,MPIM与算法基于AMD的GPU实现相比在搜索操作上可以达到5.5倍的节能和19倍的加速,在逻辑运算方面与Pinatubo架构相比有7.1倍的加速和1.9倍的节能。然而,应当认识到,Pinatubo架构和MPIM架构在计算时在一定程度上依赖外围感知电路,因此增大了系统的延迟,而且系统并行度受到外围感知电路规模的限制。Gupta等提出了一种名为FELIX的存内计算方案,可以在单周期中以低延迟实现NOR、NOT、NAND和OR等多种逻辑操作。为了对该方案进行系统级评估,研究人员设计了一些机器学习应用来进行测试,结果显示FELIX与GPU相比平均提供了128.8倍加速和5589.3倍的节能,这真是一个惊人的性能数据。
目前,面向忆阻精确计算的通用架构已经发展出了若干不同的解决方案,而面向特定计算任务的专用架构却鲜有见诸报道。相比通用处理器,专用集成电路对计算性能的要求更高,而当前基于内存的忆阻计算架构通常缺乏良好的逻辑级联能力,导致其面对计算密集型任务时难以提供足够的算力。通用的存内计算架构相比传统处理器有着非易失性的优势,但其更多地受到控制逻辑的限制,灵活性相对较低,面向多样化的计算任务时是否能维持性能优势还需要进行更多的测试评估。
基于忆阻器的精确计算架构主要是为了抵抗存储墙并面向数据密集型应用提出的解决方案。但是这些架构真正解决了内存瓶颈的问题吗?复杂的控制逻辑和外围电路会不会成为忆阻器精确计算体系结构的下一个计算瓶颈呢?忆阻器在精确计算领域的发展道路才刚刚开始,需要更多时日才能逐渐解开谜底。
目前基于忆阻器的各类电路结构和架构创新已经取得了一定的成果,这些研究展现了忆阻器在忆阻计算领域的潜力,但短期内忆阻计算电路还无法取代传统的CMOS电路在现代计算系统中的地位。为了推进这一点,除了需要制造出符合计算需求的具有高度一致性的忆阻器件之外,还有许多电路设计和体系结构上的技术挑战需要克服。
(1)虽然基于蕴含逻辑的研究相对较成熟和众多,但蕴含逻辑具有操作步骤多,控制逻辑复杂,并行性实施困难,计算周期长,忆阻器一致性要求高的缺点,这给基于蕴含逻辑的计算方案带来了挑战。面对这些问题,不同的研究人员思路有较大不同,有的研究者通过改善外围电路、释放架构的并行潜力来弥补这些缺点,另一些研究则试图修改电路内部互联网络结构,牺牲一定的通用性来提高忆阻阵列的计算性能。
(2)因为忆阻计算中,逻辑表达的方式众多,所以忆阻计算面临着状态感知的问题。在忆阻计算架构中许多计算需要花费一定的时间和硬件资源来感知当前级输出的逻辑状态,以此提供给下一级进行输入,这使得忆阻计算电路在每次计算操作过程都产生不小的额外延时。研究人员正在试图通过引入CMOS逻辑而设计具有状态感知功能的电路架构来解决这个问题。
(3)忆阻计算面临着状态(例如阻值)漂移的问题。这与器件性能无关,是忆阻器在进行逻辑操作过程中固有和无法避免的。在忆阻互联网络当中,逻辑功能上跨越阈值并不能保证完全和确定的状态更改,施加的激励(例如电压或者其它)与阈值之间的差异以及施加激励的持续时间会影响状态变化的程度。
(4)忆阻计算在近似计算和神经形态计算方面已经有若干令人欣喜的进展,在CMOS电路擅长的精确计算领域虽未取得压倒性的普遍优势,但其突破存储墙的能力和功耗优势令人印象深刻。
综上所述,忆阻计算已经“小荷才露尖尖角”,需要更多包括电路理论和模型、器件制备、逻辑结构、互联网络、体系结构、对EDA的支持等方面的大量研究和测试来推进,我们也欣喜地看到,国内中国科学院、清华大学、北京大学、国防科技大学、华中科技大学、武汉大学、电子科技大学等都在这一领域上贡献着自己的力量。
忆阻计算时代来临了吗?[J]. 微纳电子与智能制造, 2020, 2(1): 12-36.
Is the era of memristor-based computing coming? [J]. Micro/nano Electronics and Intelligent Manufacturing, 2020, 2(1): 12-36.
《微纳电子与智能制造》刊号:CN10-1594/TN
投稿邮箱:tougao@mneim.org.cn(网站:www.mneim.org.cn)
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2607内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|IC
|射频|集成电路|美国|苹果|华为|模拟芯片
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!




