来源:内容来自公众号「
机器之心」,谢谢。
我这两年的工作重心从 general purpose CPU 逐渐分散了些到 HPC 和 Graphic,坊间俗称兼职做 GPU 。
从去年到今年,国内各路 VC 突然转向不投 AI CHIP 了,一致转向 GPU:
沐曦、摩尔线程、壁仞
、
燧原。
我跟你港,把海思也凑进去的话,额滴个乖乖。
木、金、土、火、水,五行居然都凑齐了!!!
回到GPU,我猜 VC可能被某些 AI 公司伤了心,觉得太专用的 chip 在落地上过于拘束或者都是些 toG 市场。
所以更普世更灵活应变的架构开始变得更受欢迎,大不了转个向?
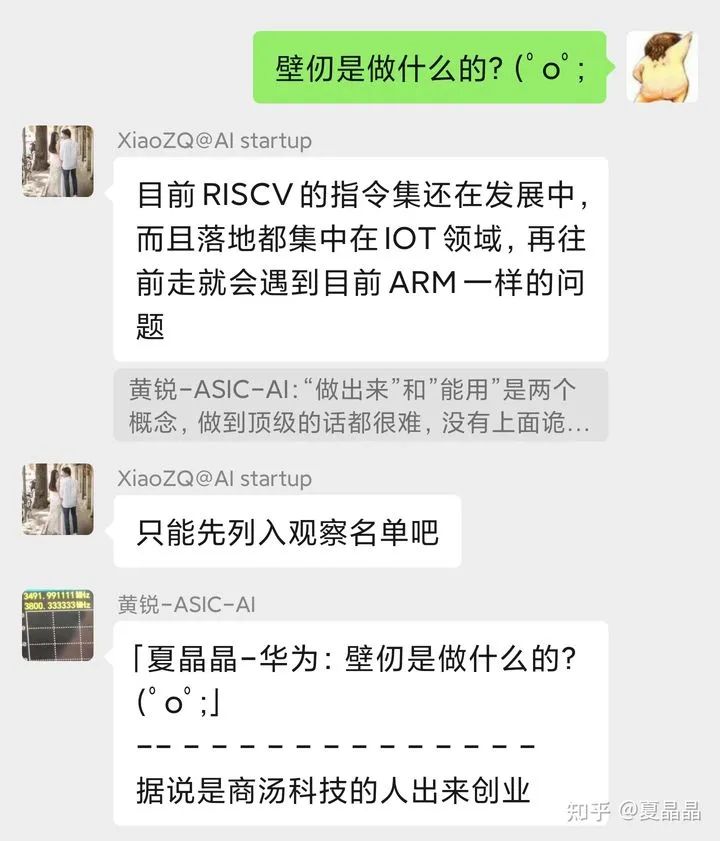
不过,这些公司正在做什么 GPU,其实我也是蛮好奇的。在一个微信群里,我还有意提了一个问题,‘壁仞是做什么的?’,哈哈,我当然知道壁仞是商汤的大佬及梁晓峣老师几位,算是一个混编军团吧,也知道摩尔线程是 NVIDIA 一脉,沐曦是 AMD 一脉,但我作为同行,更想知道的是他们的技术和架构的方向和选择。嗯,当然认识他们的血统来源和纯度,对理解他们的架构方向也很有帮助的。
但是呢,GPU 就是 GPU,从字面上来讲,它是 Graphic Processing Unit 的缩写。虽然说 NVIDIA 提出了 GPGPU 的说法,但随口一句 GP,那 GPU 就真的那么简单就做到 general purpose 吗?我觉得有点难。
AI、HPC、Graphic,先不说挖矿之类更细分的。你把三个领域都做一做,才会体会到,它们之间的差异,比人和狗之间的差异还要大。
HPC 依旧是最难的领域,做了快两年,你看它,感觉依旧像陷入了一望无际、群峰笔立的昆仑山脉之中,偶尔觉得前进了几步,抬头一看,那眼前的山峰依旧在云深不知处,而转个头,却只能发现周围还有一众更多的山峰,峰峰之间并不相连。虽然也有人认为存在一种 tensorflow 一样的框架,削峰填谷,天堑变通途,让世间没有难做的计算,嗯,我还是存疑吧,毕竟‘我又不懂’,不过这事也值得另起一贴聊聊,牛年不吹牛那一年也白过。
就这篇文章的立足点,要谈个人粗浅的理解的话,当下的 HPC 其实和 general purpose CPU 的困难是一样的,做好通用、易用才是最大的难点。君不见,其实 HPC 超算中心,本质上就是一个特殊的公有云? 而且还是个 IaaS,只是通常的公有云是一颗 CPU 分割成多份卖给多个用户,让每个用户体验独享了单个 CPU 的感觉,而 HPC 是把多个 CPU 高效联动地卖给单个用户,也是让用户体验到独享了单个 CPU 的感觉……
再谈 AI,其实 AI 也蛮特别的计算形态。nvidia 和 AMD 都从前年开始把他们的 GPU 分成了两类,Compute 和 Graphic,其中的 compute GPU,nvidia 叫 X100,AMD 叫 CDNA,同时兼任了 AI 和 HPC 两部分能力。很多人被误导认为 AI 和 HPC 的架构是兼容的,其实不然。其实是,即使业界 AI 市场的主要体量都被 nvidia 占有,也依旧改变不了 nvidia 的架构在 AI 计算上能效不够高效的事实。
否则你看坊间那么多 AI 公司为啥都能号称算力或能效超过 nvidia? 也就是 NVIDIA 嫌拆分之后的性能收益能带来的商业收益不够大,以及要维系 CUDA 的一定程度的稳定才退而求其次。以 ampere 架构为例,其计算和 AI 都不算是发挥了体系结构的极致能力(NVDLA 都能效更高)。
其实这事的算法是很简单的,HPC 与 AI 的 flops/byte,俗称 roofline 模型是差别很巨大的。如果以通常的 1MB 片上 SRAM size 为 tiling 尺寸的话,HPC 最密集的运算 HPL 即 GEMM 也就 16 flops/byte,即每个 byte 数据触发十六次计算,这基本上传统 HPC 领域的天花板了。
而这放到 AI,特别是深度学习,我用 FP64 折算 FP16 精度,也是能轻松超过 60 flops/byte,如果直接以 FP16 或 INT8 算 flops/byte 值是爆表的。因为 GEMM 不过是矩阵乘以矩阵,o(n3)的复杂度,而 AI 主要以 convolution 为主,在转换为 GEMM 之后复用率比单纯的 GEMM 高了一纬,是 o(n3+)的复杂度。
所以讲道理一个高效的 AI 芯片应该才用更大的 tensor 尺寸并通过更激进的片上 SRAM 配置来达成极高的 flops/byte 值目标。所以才有 Google TPU 以及更激进的 graphcore 的成功(GC 通过放大 SRAM 和重算几乎达成了无限高的 flops/byte)。
你想,像 HPL 这样 GEMM 咋可能在 graphcore 那种无外存的 datflow 架构跑呢? 所以呢,如果 AI 业务的颗粒度足够大(包含商业和业务),还是值得用独立一套架构来获得竞争力的,当然如果业务起不来,用 nvidia GPGPU、甚至 Server CPU(intel AMX)算也都有人做,这图的是一个方便。基于用户的取舍,谈不上计算性能的极致。
最后是 Graphic。嗯,如果说做 HPC 是每一个做体系结构人源自血脉深处的吸引力,那么做 graphic 就是每一个体系结构人的本性表露了。
但真开始深入 Graphic,你才会发现,这是一个充满了欺诈和诡计行业。与其说其他行业更多的是数学家,这个领域则更多的是魔法师、彩戏师。
去年海思图灵技术峰会时,我作为会议主持人,与第二日最受欢迎演讲者、曾经的 AMD fellow、当下沐曦的 CTO 杨建有一段互动,其讨论的问题就是要真实地模拟这个世界的光影,到底需要怎么样的算力规模。答案是:做不到,当前技术能力不足。
就是这么个道理,基于算力的不足和人民群众日趋高涨的对更好半球体的追求的矛盾,以及人眼在不同环境下对事物细节的敏感度差别,延伸出无数欺骗视觉的方法。嗯,人的视觉在脱离其他感官的基础时,真的蛮容易被欺骗的。这些个技术,本质上和魔术表演还真是一脉相承。
这些 trick,随着 GPU 数十年的发展,逐渐形成了非常坚实的理论和流程。但也最终变成了 Graphic 持续发展的一种屏障,能模拟简化的东西,谁还真正去计算呢? 目前也就大制作的电影动画还在用 hiph poly 真实地计算每一个细节,从 console 到 PC 到 mobile,poly 的数量不断地下降,会愈发倾向于用更少的 poly 再用绘画的技法去补偿。mobile 著名的王者荣耀,直接占用了 10GB 以上的内存,原因就是其中大量的立体和光影效果都是靠更多的贴图来完成的。
所以我想,凡是进入 graphic GPU 微架构领域的人,都一定会在 fix pipe 与 shader 分工上做激烈的斗争。这事也找个时间专题来详细聊聊吧。对于我这种喜欢暴力计算的,永远都是 high poly 的簇拥。
前面提到了AI与HPC的Flops/byte差异很大,这里展开再进阶说一下。
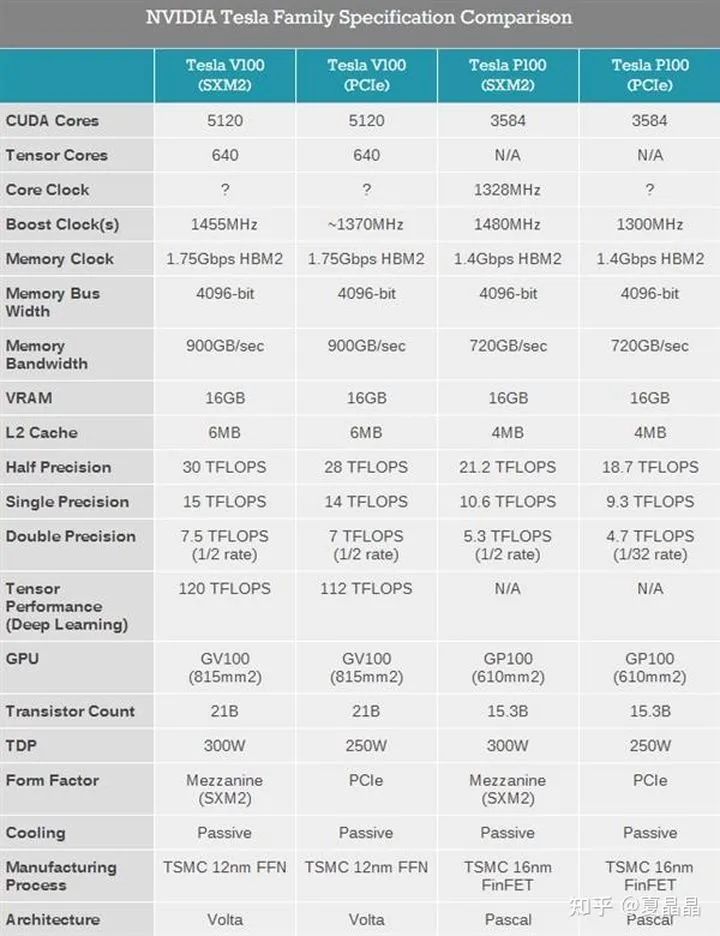
第一个引入这个差异特征的是著名的炼丹神器 nvidia 的 V100,我不知道大家第一眼看到 V100 的特征时什么感受,但对于一个传统 HPC 的人都会非常诧异,为啥半精度算力在 cuda 下只有 30Tflops,但在 tensor 下突然就变成了 120Tflops ?计算单元微架构的差异当然都能理解,但 flops/byte 凭什么能够改个 MAC 就提升 4 倍?除如果说 CUDA 的算力对 HBM 带宽配比是太低,NV 架构师不可能那么蠢。所以,这个答案的差异就是来自于不同业务的 flops/byte 的差异了,tenser 的算力是针对 AI 的。
我先把 AI 与 HPC 的精度差异放到一边,因为这个特征虽然也影响 FLOPS/BYTE,但更多是算法源头带来的可计算可收敛差异。其次我们把 AI 的随机梯度下降(SGD)和 HPC 的直接计算及共轭梯度(CG)等计算收敛带来的差异也先放到一边,这同样也是更多是算法本身的收敛差异。嗯,有空再专贴把精度和收敛算法做一下对比,这个影响其实也很大。
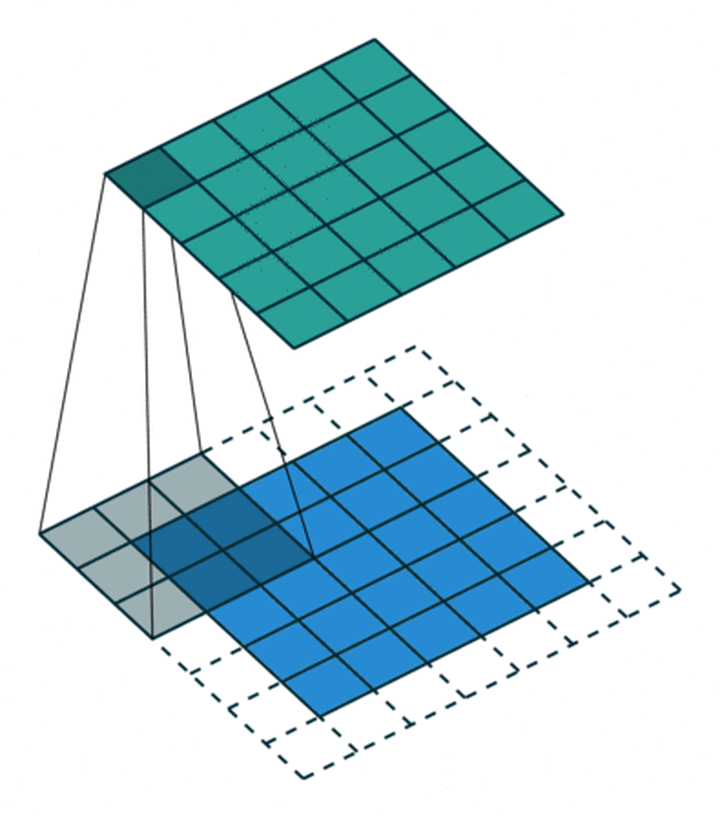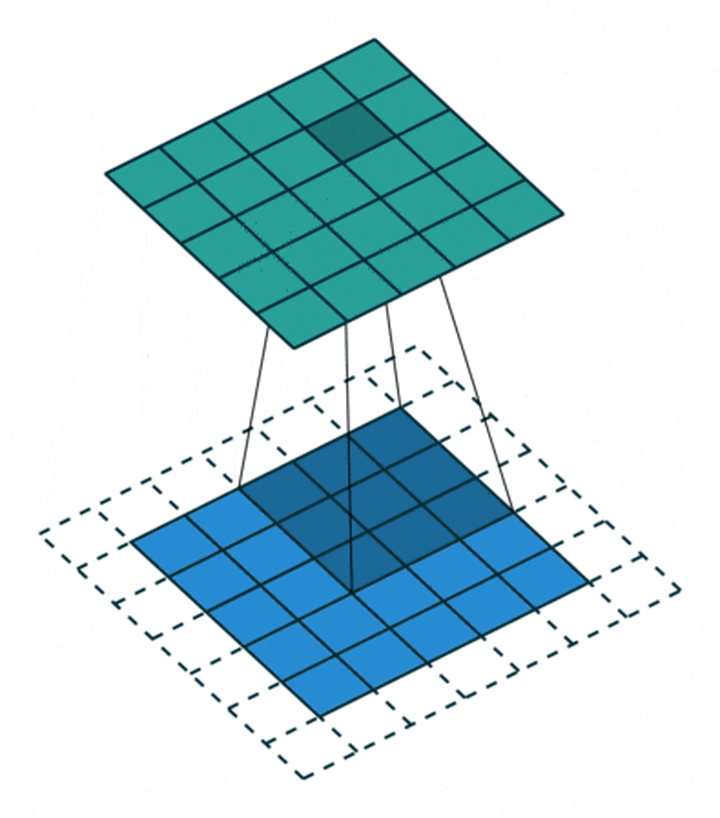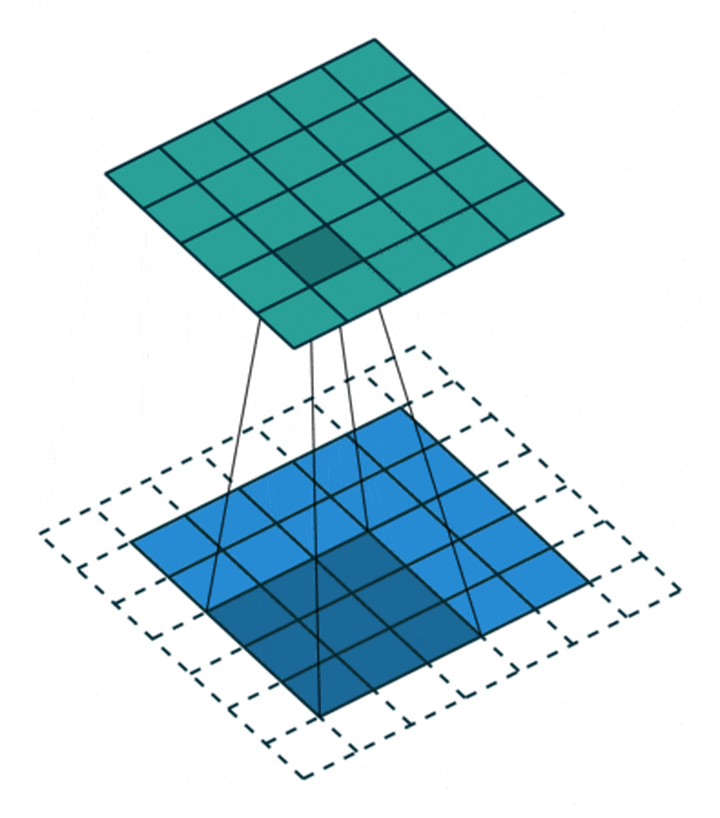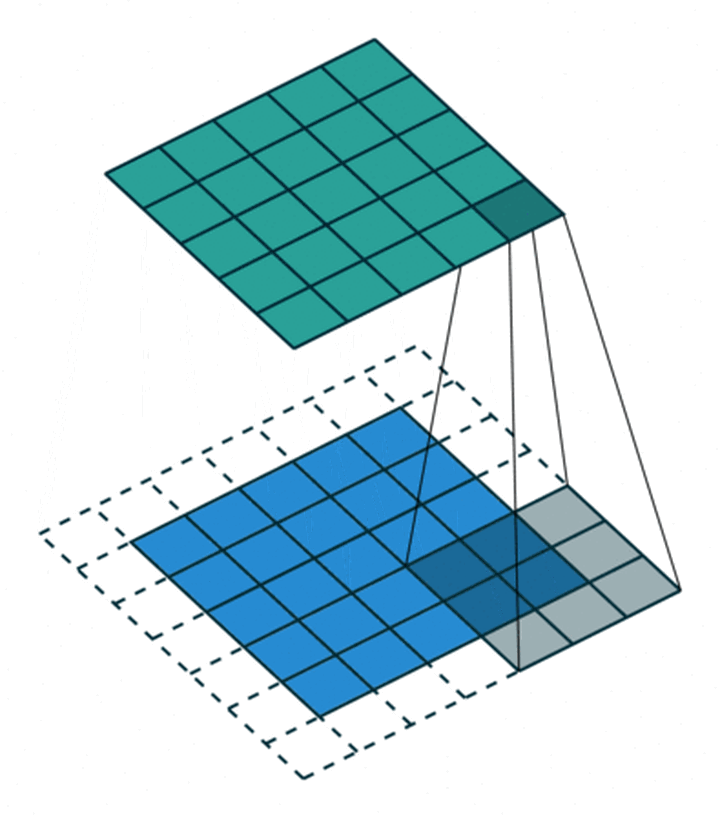
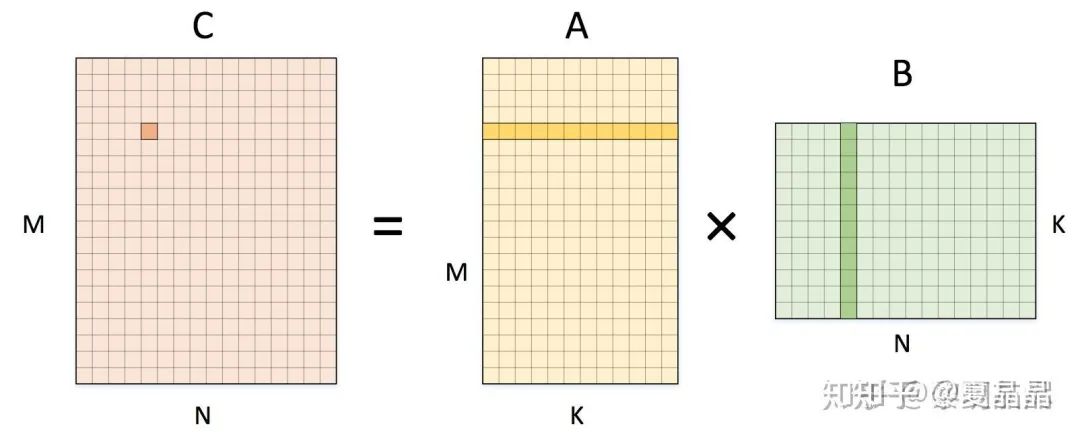
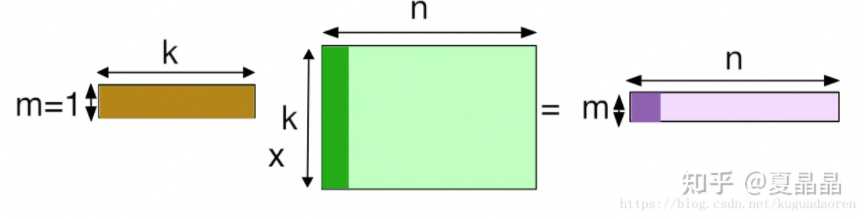
但如果专注到计算本身,我们就特定地看一下 AI 的卷积、HPC 的 GEMM 和 GEMV 的差别,用图表达非常清楚,小学生都能理解。
这是一个单通道的卷积,卷积原则上不能用 o(n3)来表示,而且他的循环展开在传统计算机体系结构上非常不好计算,所以往往会做一次 img2col 转换成 GEMM 的矩阵 x 矩阵,但为啥我写作 o(n3+)呢,数一下蓝色矩阵第二行第二列的数字即可明白,这个元素在被 filter 卷积遍历的时候,复用的次数是 filter 矩阵尺寸 MxN 次,即通常巨大的左矩阵的每一个元素复用了右矩阵总元素个数次。虽然有时候 filter 尺寸不大,但抵不住 AI 还有巨大的 channel 尺度,即 K 个 filter 的常态,即左矩阵一个元素最终复用次数是 MxNxK,复用率瞬间爆炸。
然后看看 GEMM,如下,左矩阵 A 的一个元素的复用次数是 N 次,右矩阵 B 的一个元素的复用次数是 M 次。这可是 cache 设计上最喜闻乐见的计算形态了,但复用率也相比 AI 是降维的一个程度了。
如果再看 GEMV,更惨,基本上所有 GEMV 无论是 dense 还是 sparse,都成为了 memory bound,vecter 固然还有复用率,但消耗带宽最大的 matrix,复用率为 1。
HPC 绝大多数 solver 都采用将计算分解为 GEMV 来进行,我猜其原理是在过去的 CPU/MEM 能力配比约束下最经济有效的解法。也许未来矩阵 MAC 形态增多,未来会出现更多矩阵分解的 solver 吧。
综上,AI 相比传统 HPC 具有更高纬度的 flops/byte,所以我们可以采用更加激进的 MAC/MEM 配比更高效完成 AI 的计算。所以,原则上讲,nvidia 因为强调 GPGPU 的 GP,导致 tensor 部分必须复用 CUDA 部分的 load/store 能力,所以 NVIDIA GPU 并不是最高效的 AI 计算芯片,这也是国内很多 AI 芯片公司有更进一步的可能空间。
除开计算本身的复用率(可以说是 input reuse),神经网络本身的串行化结构导致了其 output 数据的 temporal locality,如果能够有足够大的片上 SRAM 把 layer N 的 output 放下,并在提供给 layer N+1 作为 input 使用后丢弃(训练不能丢弃但可以重算),就可以做到无主存 AI 加速芯片,达成近乎无限大的 flops/byte,graphcore 和 cerebras 都是以此放飞自我的。
NVIDIA 为什么在游戏卡上死活不用 HBM2 显存?
做GPU的人,在面对 DRAM 的生物多样性问题的时候,难免都是懵逼的。
GPU 本身代表着异构,而异构本身就代表着多样性。如果是做 CPU 的人基本上精力都放在 DDR 上死磕,那做 GPU,面对的是 LPDDR、DDR、GDDR、HBM、甚至曾经的 HMC,未来的 3D DRAM。
最直接莫过于价格,按最新主流算,LPDDR 大致是 $5/GB、DDR 大约是 $4/GB、GDDR 算 $9/GB,HBM 得 $20/GB。
领导提问:“你能不能用 LPDDR 做一个能替代 GDDR 的方案?这才体现了你架构师的水平啊。”
聪明的你只需要 0.1S 时间思考就知道正确答案有且只有一个:“可以的,没问题”。
第一性原理,颠覆性思维固然没错。但不能预设立场,DRAM vendor 内的架构师都是傻叉啊。
你得先问自己,DRAM 架构师是怎么考虑这个问题的。
DRAM foundry 和 TSMC 这样的 logic 代工 foundry 还不太一样,DRAM 的制造,原则上和银行印钞机差不了太多,用沙子印钱罢了。光机一开,黄金万两。
DDR 是美元、LPDDR 是 RMB、GDDR 是欧元,大抵就是这个样子,所以 DRAM 的 architect 一定是一个经济学家,天天都会盘算不同货币之间的折算关系,你说要是某种货币会大幅贬值,foundry 根本就不会再印它。
这里,就回到了 DRAM DIE 本身的架构差异了。
如上图示例,绿色的规整大块是 DRAM CELL,就像农田一样,正如农田都有田坎和道路,DRAM 也是,为了获取访问农田的带宽以及为了 3D 堆叠更多的农田,IO 和 wire 的开销是不可避免的,甚至于需要把农田切割得更加细碎。
物理化学的世界很简单,无论是更高的带宽或更低的功耗或更高的扩展性,你都得付出代价,这并不会跟随领导的主观意愿而变化。
GDDR 为什么贵,量少价高固然是原因,更多的是,整个 GDDR 的 die,差不多一半以上的面积都是 IO 和走线,都得算钱的。
回到最初,基于 DRAM foundry 的产能良率最大甜点,无论 LPDDR 或 GDDR,DIE 都不会超过 100mm2。
做一颗 LPDDR,最新工艺大约能做到 IO 16bit(按 6.4G 速率折算)12.8GBps 速率下 1.5GB 容量 per Die。
做一颗 GDDR,因为走线 IO 损耗,大约就只能做 1GB 容量,但 IO 32bit(按 14G 速率折算)是 56Gps 带宽 per die。
LPDDR 可以进一步叠多层,GDDR 不能,但这并不重要了。因为 die 的基本能力已经决定了最大等价交换的空间。
不考虑 GPU 的 IO 数量差异,功耗差异,单纯讲替代。
如果 GDDR 带宽是 560GBps(就是 AMD RDNA2 显卡水平),只需要 10 个 GDDR DIE,共 10GB 容量,折合 90$。
用 LPDDR 达到等价带宽 560GBps,需要大约 40 个 LPDDR DIE(当然合封之后不是 40 个颗粒),共 60GB 容量,折合 240$。
逻辑很简单,虽然每 GB 的价格 GDDR 是 LPDDR 的 2x 还多,但如果要用 LPDDR 达成 GDDR 同样的带宽,需要购买~5x 的容量(折合~2x 的价格)。如果最终~5x 的容量确实成为了竞争力让最终客户能够买单,那么用 LPDDR 换 GDDR 就是血赚。否则这容量就变成了损失。
最后,聪明的同学也会明白如何进一步答复领导的 “可以的,没问题” 了,如果这个 GPU 场景确实即需要带宽也需要大内存,那么血赚,作为优秀架构师你通过第一性原理思考完成了用 LPDDR 替代 GDDR 的方案,大幅节省成本,获奖感言的 PPT 都可以提前准备了。如果大内存价值低,那把多种方案详细用 PPT 列出来,让领导给出英明的决策即可。
这部分讲一个GPU及异构的重要逻辑:RISC-V。
因为大家说法不一致,下文中的 DSA 泛指异构 GPU 的形态。
因为刚好 RV 的一个相当重要度的会议马上要开了,很棒,希望这一次峰会的召开能够再一次刷新大家对 RISC-V 的认知。我相信在 IC 行业里,RV 一定能爆发出巨大的能量。
是的,作为业界差不多 TOP 级别的 ARM 处理器架构师吧,我毫不掩饰自己的喜好,我是 RISC-V 的死忠粉。
一定有人觉得 RISC-V 和 ARM 之间是竞争关系,坊间也一直把 RISC-V 比做 X86、ARM 之后的第三个新起 ISA,嗯,CPU 的第三次革命,革命。
曾经的我,也错误地理解 RISC-V。Patterson 大佬有一段时间到处宣讲关于 DSA 的黄金十年,摩尔定律停滞了,未来是 DSA 的天下。这些都没错,但是 patterson 教授你为啥每次讲 DSA 讲着讲着就转到 RISC-V ? 这个逻辑是怎么转折的? 是我英语太差吗?
我相信应该不止我一个人这么迷惑吧。讲 DSA,和 RISC-V 是个什么关系啊? 很长一段时间,我把 patterson 大佬讲 DSA 带 RISC-V 的事认为是他夹带私货……
直到我慢慢学习慢慢理解,我才发现,我和大佬就差那么一点点。
所以讲结论吧:
RISC-V 并不是一个通用指令集。
任何妄图用 RISC-V 构建一个高性能处理器的意图都是错误的,光是指令密度 RISC-V 就差了一大截。举个例子,如果要达成 ARM 8x decode 的同等性能,RISC-V 需要 10x decode 甚至更宽,即使指令简单,但物理实现的难度是比指令复杂度更加难以跨越的。所以,不要妄图用 RISC-V 替代 ARM 或 X86 的通用处理器领域。最近 20 年,根本就没有新的第三个 ISA 诞生,甚至于某种角度,RISC-V 不是一个 ISA。
确实,如果不考虑性能,只关注高能效地完成一些控制类任务,RISC-V 简单小巧的特征有很好的发挥空间。
1、RISC-V 根本的实质是一个 DSA 扩展的平台。
这是 patterson 在 DSA 黄金十年中隐含的第一个谜底。
这个才是 RISC-V 最核心的本质,所以我作为 ARM 架构师又是 RISC-V 死忠粉的原因,两者非但不冲突,反而是互补的。
我始终不明白为什么 patterson 教授不直白地说出这个答案,而要人自己去悟? 也许,大佬的心思你别猜吧。
为什么 RISC-V 是一个 DSA 的平台? 因为 RV 的最大特征是用最小指令集合实现了图灵完备,这代表着已经完成了一个最优美的 background,你只需要在此之上涂上你想要的任意颜色就好了。有人攻击 RISC-V 指令容易分裂,错了,这反而是 RISC-V 最大的优势,因为它就是能让你任意地分裂啊,你无聊怎样分裂,最终的基本面都是图灵完备的,而图灵完备意味着什么?意味着你可以用 C 语言编程。
为什么 DSA 或者做 GPU 要图灵完备? 要支持 C 语言?
呵呵,这里可能会得罪到包括寒武纪、壁仞、沐熙等一切号称 DSA 的同学了。
随着认识的充分,我逐渐理解 patterson 在 DSA 黄金十年中隐含的第二个谜底。
DSA 包含:易于使用的通用型与极致能效的专用型两种。
曾经有一个业界著名的疑问:为什么 Google 的 TPU 不外卖? 曾经有人说这是 Google 有意为之,为了自己把握算力巅峰。不能说错,但也不对。实际上我现在理解,TPU 是云巨头基于私有的软硬件竞争力的极致定制化 DSA,他的编程框架是私有的(绝对难用),它最终将以云服务而不是白盒硬件方式提供给用户。AWS 的逻辑亦是如此。
而 nvidia,它是一个通用的 DSA,拥有着广泛使用的编程生态,也因此,它的硬件在计算能效上往往被专用 DSA 各种吊打。
事实上,长远来看,nvidia 与 TPU 是两个正交的赛道。面对广泛的体量较小,更在乎开发效率的企业个人和小云厂商,先期选用 Nvidia 是更适合的。而但 cloud 长到一定体量,需要计算能效的极致化,并且能够以算力方式给用户提供服务时,一定会类似 TPU 一样定制 DSA 私用,通过支撑或 SAAS 间接面对客户。
所以无论是寒武纪、某某、某某,甚至某某,我认为在产品定位上是存在某些偏差的。要么通用博爱天下好好做个青楼红牌,要么专用就被某家 cloud 包养,相夫教子做一个强者的贤内助才是归宿。
一个个通用型不够好,定制性不够佳。为了提升算力能效放弃通用编程能力,为了扩展应用范围又花钱开发大量基础算子来提升通用性。
当然,最大的问题是国内没有 Google 或 AWS 这样的富商能出的起包养的钱…… 次要问题是 CUDA 的生态又太过于强大,再建一个同样的非图灵完备的通用编程生态极度困难。
抄袭 CUDA 是不可取的,先不说法律问题,要模拟到一定相似度,基本上就是一个 SIMT 了,高能效的天花板也就是那样了。
答案就是 patterson 的 DSA 黄金十年的第二个谜底:2、基于 RISC-V 扩展 DSA,有可能同时兼顾通用和专用。
怎样做到? 这里还会涉及到 patterson 的 DSA 黄金十年的第三个谜底。大佬就是大佬,早已安排了一切,就看你有没有明白。
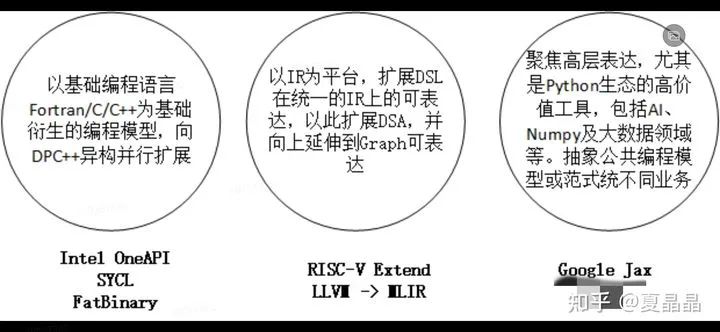
3、RISC-V 配套了 chisel 编程语言和 MLIR,在图灵完备性基础上,chisel 可以快速基于用户特定算法(注意这里强调算法而不是电路)定制 RISC-V 扩展 coprocessor(扩展指令集),同时,这部分算法抽象可以自己通过 LLVM 拓展的 MLIR 在 compiler 上描述出来。
结果是,基于 RISC-V 的 DSA,首先可以用 C 语言编程,然后,业界开放的 OMP、DPC++、MPI 等等通用编程方式都可以用于这个 DSA 异构编程,基于 MLIR,用户原本已有的 C 或其他以 C 为基础的高层语言(例如 Python),都可以在代码不做修改的情况下通过 MLIR 编译到 RISC-V DSA 上高效执行。
当然,有人会诟病目前 RISC-V 的扩展指令不能 cover 目前看到的很多业务领域,私有扩展能力可能有不足。
没有关系,时间会解决所有的问题。基于 RISC-V 的 matrix ISA for DL 在制定中,很快会出来的。基于 RISC-V 的 rendering ISA 也将要发布了,性能还不够好,时间会解决。此外,还有更多…… 更多……
所以,作为 ARM 架构师,我同时也是 RISC-V 的死忠粉。
假设我某一天创业,我会选择 ARM 来做 general purpose CPU,选用 RISC-V 来做 DSA(GPU),搭建完整的异构计算平台。
ARM 购买 ARM 公司 IP 即可,而 RISC-V,甚至都不需要购买,直接到业界抓开源版本(例如瑞士 luca benini 教授的)下载,选择最契合的版本,二次开发即可。
patterson 大神到处宣扬 DSA 的黄金十年,嗯,无论你信不信,我在上面一部分内容努力地以我的理解把他想讲的硬件测的故事圆了一下。
开源 + Risc-V+chisel+MLIR,但如果你真的这么走一轮,你会发现有一些东西,虽然间接地提到了,但不完备,缺乏一个理论上的指导思想,一个古圣级别的大计划。
这个问题很重要,因为光做一个 DSA 硬件不难,难点是要如何把 DSA 的特征正确地表达给程序员,毕竟这个世界上,软件开发者的数量几乎是硬件开发者的一百倍还多。
C 语言,是过去三十年软件和硬件两个阵营之间,签署的最坚实的盟约。歃血为盟,永不背叛。
硬件为 C 语言的语义提供了最能发挥其性能的 silicon,而软件虽然搞了很多的圆环套圆环般的层次(说的就是 Python),但最终都以 C 语言作为最后的沉淀收尾。
CUDA C++,最终也是回到 C 语言上扩展了 CUDA 的生态,来达成基于 CUDA 生态的异构编程。
但时代变了,我们需要一种能够更加普世的编程框架或者范式,吸引并影响更多的软件、硬件同志们参与到 DSA 其中,再次歃血为盟,为未来的三十年定下下一轮的契约。
每一个 IT 公司都希望这份新的契约是以自己为中心的,所以他们都从自身所能掌控的生态出发,以期吸引更多程序员的认同。基于生态层次的划分方式,甚至于在当下战场中兵戎相见的某些公司,也不由自主地站在了一个阵营。
i
ntel 为首的 general purpose CPU,背负着前三十年的历史包袱,是包袱,更是财富,毕竟汉室正统,挟天子以令诸侯。
所以 intel 继续从过去证明成功的 C 语言最底层表达继续出发,从最具群众基础的底层向上拓展,以期在原有的契约通过 extension 的方式再续三十年。
这不得不说一下 DPC++,很多人都特别小看 DPC++,据说我领导和 SYCL 的 CEO 面谈的时候问 “这东西能提升硬件的性能吗?”,“不能”。这天就聊死了。实际上 DPC++ 并不是为了提升硬件性能而存在,而是为了充分释放编程人员在 DSA 及 parellel 上的潜力而存在的。
知道 CUDA 为什么能成功吗?其实就是 SIMT,这曾经是最适宜人类普世编程思路的并行范式,它把并行编程伪装成了串行编程,如果一个计算控制流不复杂,而显性地存在了同构的并发性,编程人员只需要按照自己的思路编写一个 scalar 的代码即可,SIMT 可以自动帮你按 32 分组地展开成并发。这事提升硬件性能了吗?没有,但解放了编程人员的生产力。很多时候解放生产力比提升生产力更加重要,改革开放不就如此吗?DPC++ 在重复同一个故事。你问为啥 intel 以前不搞? 因为 intel 在 DSA 的时代有了类似 SIMT 能力的 AVX512,还有了 RAJA 搞出来的一堆 XE 架构,以前只能靠 openmp 和 mpi,现在有新的机会逐鹿中原了。
魏国最大的弱点是什么? 是 C 语言开发者数量的逐渐式微,新兴的语言有了太多的语法糖(说的就是你,Python)。这些语法糖在解放生产力,的同时让开发者能力逐渐分层,吃惯了白面谁还吃红薯啊…………
以 Google 为首,代表着从 AI 为创新源头的新兴势力。
framework,即框架在 AI 领域的成功,让集中在这个领域的高密度人才携其创造的高密度思想结晶,希望像 AI 的泛化能力一样,把 framework 的思维方式泛化到其他编程领域。
framework 最大的好处是什么,是信息的上传下达的尽可能无损。随着各种高层语言的层次不穷,为了最终适配原有的软硬件契约,语言在多种格式之间来回转义,就像中转英,英转法,法转日一样,来回一圈信息得损失多少? 所以很多人都希望最高层的信息能够直达底层。
左手 framework,右手 Differentiable Programming,是这个流派最大的特征。
一句话讲呢,这个流派希望破旧立新,重新制定软硬件的盟约,把 C 变成 Python。
这个思路最大的优势就是这几年 AI 在 framework 和 differentiable 上看到的收益,前者能够打开窗口释放一波过去没有的高层次的设计空间,后者证明了一种新的方法有可能可以解决曾经没有解决的问题(典型就是谈的比较多的 DSE,还有 HPC+AI 等等,以前都是硬算的,现在突然发现,我能猜啊,猜对血赚啊)。
1、framework 其实代表着对一个领域的统一的高层抽象,AI 其实就是比较清晰的数据流图框架,但是,并不是所有领域的框架都能用 AI 的框架完美替换,当然你说可以针对不同领域区别调整,但是这个领域够大吗?值得像 AI 一样定制一个 tensorflow 出来吗?真有值得的空间,早该有人做啦。
2、可微分这事,很神奇啊,低精度,猜一猜,高分辨率就出来了啊。其实也没有什么很神奇的,在我看来,一切可计算问题,如果自动可微能够拿到收益,那么必定是原本的计算存在冗余,或者原本的公式不完备,存在未能识别的隐变量,能够被可微分策略拟合出来。所以,这条路需要盘算一下,计算存在冗余及存在隐变量的空间又有多大?
3、其实这个问题最要命。这个世界的本质,是 1% 的天才和 99% 的普通人建立的,而生产力的本身,是这 99% 的普通人创造的,这是我身处 99% 太久而亲身体会,而那 1% 的天才往往对此并无感知。要提升或解放生产力,你必须针对这 99% 的常人,让一个方法更加普世、简单、易行。这个角度,往往是 Google 那 1% 的天才同学所忽视的(何不食肉糜呼)。
基于 IR,分层的 IR。以 compiler 为中心,让编程人员无感知地任意使用语言开发,用中间多级 IR 逐级构筑信息表达,硬件侧还是以 C 为基本面,通过 IR 的扩展性(dialect)来承载各层语言的语义无损,就像日本人和印度人最终通过英语完成交互一样(虽不完美)。
这个方向的描述在最近的 asplos 上,大神 Chris Lattner 已经讲得足够好了:
链接:https://zhuanlan.zhihu.com/p/367035973
Chris Lattner 跳槽到 sifive 的时间不长,我也不清楚他和 patterson 是什么关系,为什么他们之间的故事就这样勾搭上了。但 sifive 是一个小公司,这么位大神愿意屈尊,肯定是有点我们所未能认识到的原因的。
这条路径,上能同吴,下能通魏,要说破绽,一个是 IR dialect 到底效果如何,还有待时间证明。还有就是,我感觉是力量太小,太分散,明显关张都未到位,还未能呈现出逐鹿中原的霸者之气,要是再有某些巨头突然加入,形势可能会有巨大的变数。
但目前还未有迹象看出某个方向有大一统的趋势,还有得打。
本文为机器之心经授权转载,作者知乎原专栏链接:https://www.zhihu.com/people/xia-jing-jing-57
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2706内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|集成电路|设备
|汽车芯片|存储|美国|华为|苹果
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!