英伟达再出招,加速AI普及
2021-06-25
10:00:17
来源: 李寿鹏
点击
最近这些年,在英伟达等芯片厂商、方案商以及应用厂商的推动下,人工智能正在以迅雷不及掩耳之势在千行百业普及。据德勤德勤此前发布的《全球人工智能发展白皮书》预测,到2025年世界人工智能市场规模将超过6万亿美元,2017年至2025年复合增长率达30%。
虽然人工智能的普及是不可逆的趋势,但对于开发者来说,他们还是需要面对各种各样的挑战。例如如何将AI应用到不同的场景中?又如何提高开发效率?以上问题就成为了开发者关注的重中之重。
作为行业内领先的AI芯片供应商,英伟达正在通过其各种利器,推动AI来改变人们的生活。
全新的迁移学习工具包
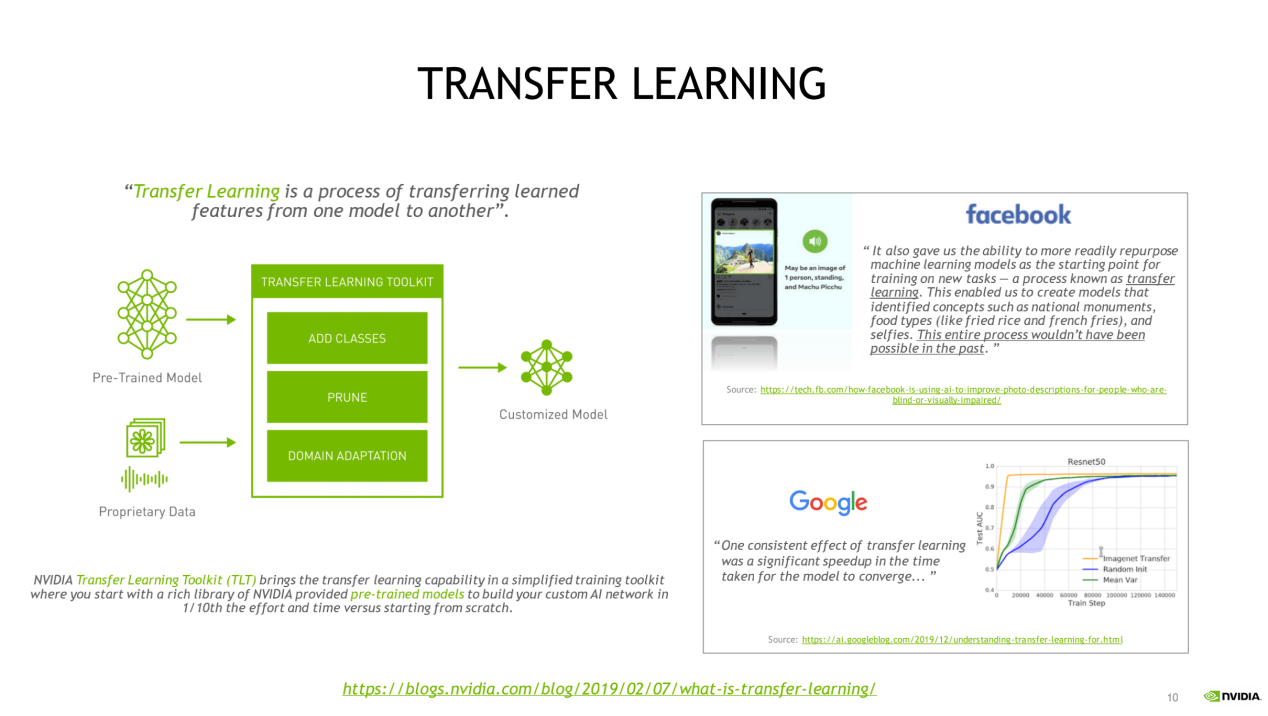
所谓迁移学习,是指将已经在相关任务中训练过的模型的一部分复用到新模型中,从而很大程度地降低对大量计算资源的需要。具体而言就是可以从现有神经网络中提取已学习特征,并通过从现有神经网络转移权重来迁移这些已学习特征。据英伟达方面介绍,公司的迁移式学习工具包是一个基于Python的工具包,它提供了大量预先训练的模型,并提供一系列的工具,使流行的网络架构适应开发者自己的数据,并且能够训练、调整、修剪和导出模型,以进行部署。

在发布第一代工具包的时候,英伟达方面也表示,这套方案拥有许多预训练的优化过的领域特定DNN,预先打包在里面;有计算机视觉中,物体分类、检测的应用示例;在异构的多GPU环境中,易于做模型适应 (Model Adaptation) ,易于重新训练;可以轻松修改配置文件,增加新类别、新特征,压缩模型大小;Model Export API可以把模型轻松部署在英伟达的DeepStream SDK 3.0上,做智能视频分析 (IVA) 应用;Model Export API在可以把模型部署到Clara平台上,来做医学影像相关应用。
自2018年发布以来,英伟达迁移学习工具包受到了客户的高度认可。到了今年二月,他们又带来了迁移学习工具包 3.0 版本(开发者测试版)。据介绍,借助这个全新工具,开发者可以通过 NVIDIA 为常见 AI 任务开发的多用途生产级模型或者 ResNet、VGG、FasterRCNN、RetinaNet 和 YOLOv3/v4 等 100 多种神经网络架构组合,使用自己的数据对特定用例的模型进行微调。所有模型均可从 NGC 获得。
今日,英伟达再带来了新的好消息,那就是发布全新预训练模型并宣布迁移学习工具包(TLT)3.0全面公开可用。

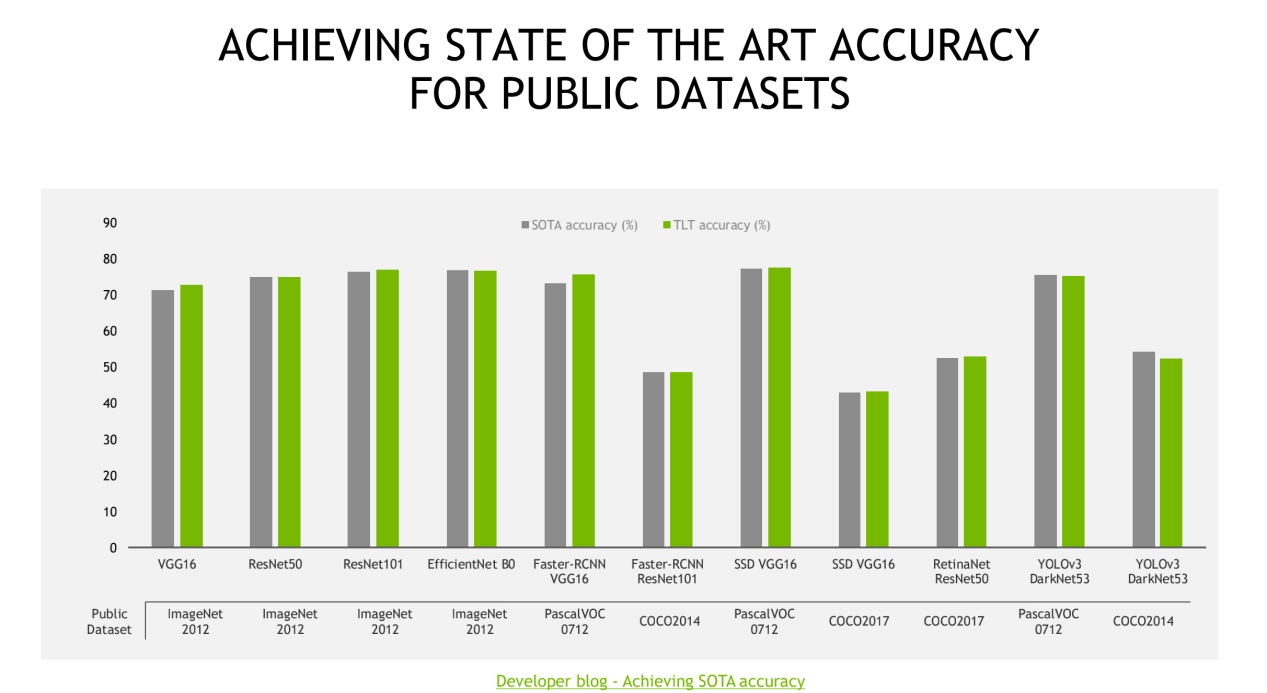
英伟达方面表示,迁移学习工具包在NVIDIA TAO平台指导工作流程以创建AI的过程中起到核心作用。新版本包括各种高精度和高性能计算机视觉和对话式AI预训练模型,以及一套强大的生产级功能,可将AI开发能力提升10倍。
他们进一步指出,新版本包括以下多个亮点:
一个支持边缘实时推理的姿态估计模型,其推理性能比OpenPose模型快9倍。
PeopleSemSegNet,一个用于人物检测的语义分割网络。
各种行业用例中的计算机视觉预训练模型,如车牌检测和识别、心率监测、情绪识别、面部特征点等。
CitriNet,一个使用各种专有特定域和开源数据集进行训练的新语音识别模型。
一个用于问题回答的新Megatron Uncased模型以及许多其他支持语音文本转换、命名实体识别、标点符号和文本分类的预训练模型。
AWS、GCP和Azure上的训练支持
在用于视觉AI的NVIDIA Triton™和DeepStream SDK上以及用于对话式AI的Jarvis上的开箱即用部署。
而从他们的介绍我们也得知,TLT 3.0现在还与数家领先合作伙伴的平台集成,这些合作伙伴提供大量多样化的高质量标签数据,使端到端AI/机器学习工作流程变得更快。换而言之,现在您可以使用这些合作伙伴的服务来生成和注释数据、通过与TLT无缝集成进行模型训练和优化并使用DeepStream SDK或Jarvis部署模型以创建可靠的计算机视觉和对话式AI应用。
在英伟达方面看来,随着企业竞相推出AI解决方案,企业竞争力将有赖于是否能够获得最佳开发工具。对于许多尝试使用开源AI产品创建模型进行训练的工程和研究团队来说,在生产中部署自定义、高精度、高性能AI模型可能是一段十分艰难的开发历程。
“NVIDIA提供高质量的预训练模型和TLT以帮助降低大规模数据采集和标注成本,同时告别从头开始训练AI/机器学习模型的负担。初入计算机视觉和语音服务市场的企业现在也可以在不具备大规模AI开发团队的情况下部署生产级AI。”英伟达方面强调。
GAN 研究如何重塑视频会议
除了提供工具帮助开发者进行应用开发外,英伟达还在CVPR 2021 上带来了基于 GAN 研究的NVIDIA Maxine 云 AI 视频流 SDK。按照他们的说法,这个全新的SDK将能够帮助重塑视频会议,是的每个人在参与视频通话的过程中都能完美展现自己。而背后倚仗的就是类似Vid2Vid Cameo 这样的深度学习模型。
据介绍,Vid2Vid Cameo 模型基于 NVIDIA DGX 系统开发,使用包含 18 万个高质量人脸说话视频的数据集进行训练。相应网络学会了识别 20 个关键点,这些关键点可用于在没有人工标注的情况下对面部动作进行建模。这些点对特征(包括眼睛、嘴和鼻子)的位置进行编码。
然后,它会从通话主导者的参照图像中提取这些关键点,这些关键点可以提前发送给其他的视频会议参与者,也可以重新用于之前的会议。这样一来,视频会议平台只需发送演讲者面部关键点的移动情况数据,无需将某参与者的大量直播视频流推送给其他人。
通过仅来回压缩及发送头部位置和关键点,而不是完整的视频流,此技术将视频会议所需的带宽降低 10 倍,从而提供更流畅的用户体验。该模型可以进行调整,传输不同数量的关键点,以实现在不影响视觉质量的条件下,适应不同的带宽环境。
此外,还可以自由调整所生成的人脸说话视频的视角,可以从侧边轮廓或笔直角度,也可以从较低或较高的摄像头角度来显示用户。处理静态图像的照片编辑者也可以使用此功能。
英伟达方面指出,Vid2Vid Cameo 模型本周将在著名的CVPR大会上发表,这是 NVIDIA 在本次虚拟会议上发表的 28 篇论文之一。此外,它还在 AI Playground 上推出,在此所有人均可亲身体验我们的研究演示。
按照英伟达的说法,Vid2Vid Cameo 只需两个元素,即可为视频会议打造逼真的 AI 人脸说话动态,这两个元素分别是一张人物外貌照片和一段视频流,它们决定了如何对图像进行动画处理。
换而言之,借助这个技术,使用者上传一张穿着正装的照片之后,即使头发凌乱、穿着睡衣,也能在通话中以穿着得体工作服装的形象出现,因为 AI 可以将用户的面部动作映射到参照照片上。如果主体向左转,则技术可以调整视角,以便参与者看上去是直接面对摄像头的。
除了可以帮助与会者展现出色状态外,这项 AI 技术还可将视频会议所需的带宽降低 10 倍,从而避免抖动和延迟。它很快将在 NVIDIA Video Codec SDK 中作为 AI Face Codec 推出。
NVIDIA 研究人员兼项目的联合创作者 Ming-Yu Liu 表示:”许多人的互联网带宽有限,但仍然希望与朋友和家人进行流畅的视频通话。这项基础技术除了可以为他们提供帮助外,还可用于协助动画师、照片编辑师和游戏开发者的工作。”
得益于英伟达这些先进的工具和模型,一个全新的科技新世界正在缓缓向我们走来。
责任编辑:sophie
相关文章


©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号