计算存储时代来临,处理器IP为其助力
2021-12-09
14:00:09
来源: 半导体行业观察
当下我们正处于一个数据大爆发的时代,量的增加使得数据处理难度加大,耗能增加。据Fortune Business Insights 称,为了管理在未来几年增加的数据,服务提供商每年将增加约 25% 的存储支出,2022 年达到 850 亿美元,2027年达到近 3000 亿美元。而另一方面,数据中心运营商则希望减少能源费用以及与运营相关的碳排放。因此,服务提供商将投资重点放在更高性能和更低功耗计算能力上,从而减少数据移动。
在这样的趋势下,
计算存储不失为一个改善数据处理的关键技术
。计算存储使计算处理更接近数据,从而提升了应用性能和整体基础架构效率。业界认为,部分SSD硬盘或将朝着计算存储方向发展,这将为SSD存储解决方案带来计算能力,并减少存储和应用处理器之间传输的数据量。Wikibon 预测,未来五年或更长时间,SSD 闪存容量的出货量将每年增长30%以上。
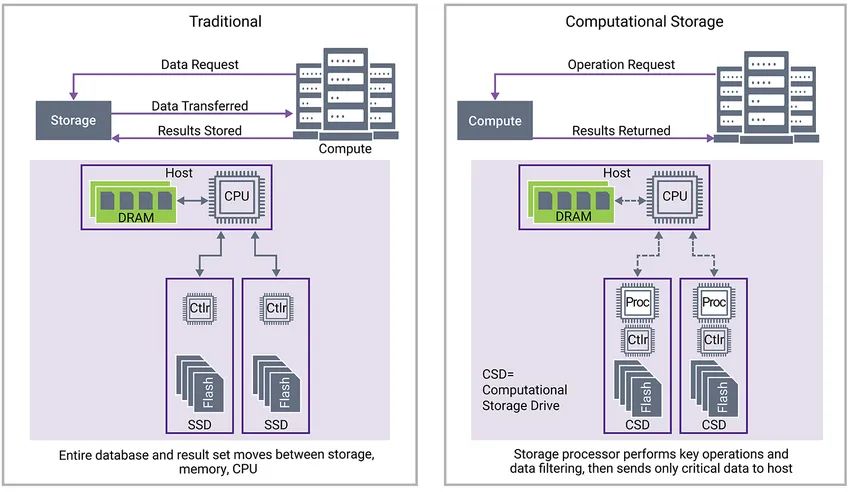
举个例子,美国环境保护署 (US EPA) 每小时会采集美国数百个城市的污染物含量,以检测空气质量。这些测量值已经有数百万条,每天还在不断增长。如果要在这海量的数据库中查找某些数据,需要将一个个的数据库从存储服务器 SSD 复制到与主机处理器关联的DRAM上,然后主机 CPU 扫描并查找所有记录,直到系统从数百万条记录中提取所有相关信息,这样做无疑是大海捞针,耗时耗力。
而如果使用计算存储系统,将存储服务器中的固态硬盘替换为内置有处理能力的计算存储硬盘,要查找某个信息,只需由主机服务器向存储服务器发送请求,请求其提供相关记录,这样每个计算存储硬盘中的处理器都会对信息进行预处理,仅返回相关信息,而不是移动整个含有百万条记录的数据库。这样的好处是,数据处理占用了更少的网络带宽,因为只有一小部分数据库通过网络发送;需要的主机CPU周期也会少的多,因为主机CPU只需要查看相关记录,而不是整个数据库。
那么数据究竟是如何在计算存储事务中流动的呢?如图2所示。首先,传统的主机请求通过主机接口进入存储 SSD 控制器(计算存储硬盘),以请求数据。从 SSD 提取到 DRAM 并由主机处理器处理的数据可能极其庞大。在这种情况下,主机向计算存储处理器发送简单的高级命令,以请求开始事务。
其次,计算存储处理器启动并分析来自主机的命令,然后向 DRAM 发起读取请求。该请求告知存储处理器构建传输描述符(步骤 3),该描述符随后用于调度到适当的 Flash 通道,以从 NAND 闪存元素获取读取数据(步骤 4)。
接下来,从 NAND Flash 通道引入计算存储处理器的读取请求进行分析,如图3所示。处理器查找请求的数据或密钥匹配。如果找到匹配记录,则将该匹配记录发送到 DDR DRAM(步骤 6)。然后,将数据打包在主机接口协议中,并通过主机接口将数据 DMA 发送到主机内存,然后由主机处理器进行处理或使用(步骤 7)。一旦完成,计算存储处理器将消息发送回主机处理器,告知事务已完成且数据可用,或者如果过程没有实现匹配,则发送一条错误消息(步骤 8)。
图 3:计算存储硬盘从读取数据到成功完成指示的数据流
在计算存储系统中,随着存储量和硬盘数量的增加,存储设备中的计算处理器的数量也随之增加。因此,处理能力随存储而扩展。计算存储处理器可以优化为特定工作负载,以进一步改善性能。
使用计算存储可减少从本地存储 (NAND Flash) 发送到 DRAM 以供主机处理的数据量。在美国 EPA 的示例中可以看到,只有极少量的记录需要将数据存储在 DRAM 中,从而释放主机处理器,使其专注于最重要数据。
当今的系统会在边缘侧生成大量数据,相比于把所有数据通过云端发送回去再处理,直接在边缘进行计算存储,可以减少数据的移动,同时运用AI技术,可以将边缘端本地存储的数据进行单独的离线处理,然后仅将所需数据移动到主机或数据中心,能够大幅降低功耗和金钱成本,提升性能。
随着人工智能 (AI) 技术对人类大脑功能和神经元的学习,形成了更多数学函数,创建出可以处理数据的专用硬件、加速器和神经网络引擎,计算存储的功能和效率也将得到进一步的优化和提升。
那么有哪些应用适合用计算存储?例如处理器卸载、视频转码和搜索文本、图像或视频,也包括汽车应用中的图像分类和对象检测与分类,这些应用都可以使用机器学习、加密和/或压缩,来简化或减少需要在系统周围传输到主机处理器的数据量。
明白了计算存储对系统的帮助之后,我们就要开始考虑采用哪种处理器来管理数据,因为更多的计算能力所需要的处理能力也就更高。
针对计算存储的应用,新思科技推出了ARC HS4x/HS4xD处理器IP。
DesignWare
®
ARC
®
处理器 IP可提供非常灵活、可扩展的架构。其广泛的处理器产品组合涵盖从低端三级管道处理器,到更高端的 10 级管道实时和嵌入式应用处理器。此外,新思科技的嵌入式视觉处理器还提供神经网络加速器,可以帮助进行AI部分的处理。
图 4:一个计算存储硬盘可以包含多个用于不同功能
的 ARC
®
处理器
随着计算存储驱动器收到的计算需求不断增加,数据处理压力增大,为了满足这些需求,DesignWare
®
ARC
®
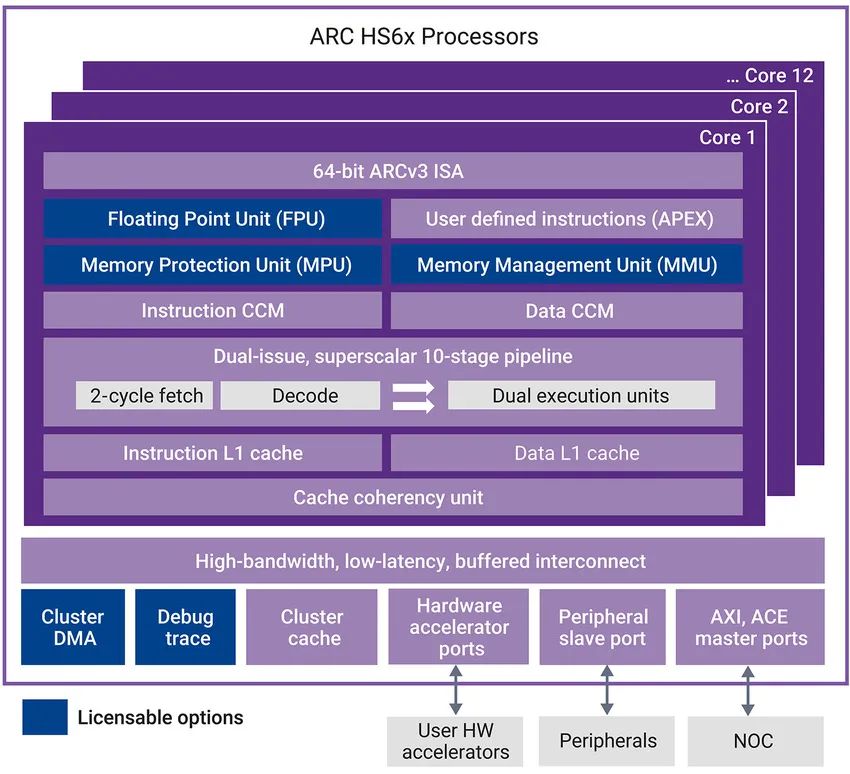
HS6x处理器采用Dual Issue 64 位超标量架构(图 5),可提供高达 6.1 CoreMark/MHz的性能,体积小且功耗低。ARC
®
HS6x处理器基于先进的 ARCv3 指令集架构 (ISA) 和管道,可提供领先的功率效率和代码密度。该处理器具有 52 位物理地址空间,可直接解决内存大小高达 4.5 PB (4.5x1015) 的问题。
当我们将更多外部计算从存储访问控制转入本地存储处理器时,将需要构建额外的处理能力,以支持所需的编程工作负载。ARC
®
HS6x内核非常适合提供这种额外的处理能力。
对于需要更高性能的应用,HS6x 的多核处理器版本可在单个一致的处理器群集中支持多达 12 个 ARC
®
HS6x CPU 内核和多达 16 个硬件加速器。
从传统存储架构到计算存储的转变正在发生。相比在传统存储系统中,主机处理器需要处理从存储到 DRAM 的所有存储请求和数据副本,转向存储内或计算存储架构,在硬盘上本地操作数据,此种方式将更加降本增效。新思科技的处理器IP将为计算存储的发展提供强有力的支撑。
今天是《半导体行业观察》为您分享的第2883内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|集成电路|设备
|汽车芯片|存储|台积电|AI|封装
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!
责任编辑:Sophie