
存算一体:2023年年度盘点 & 2024年技术前瞻
一、 2023年存算一体行业盘点
在过去的2023一年中,AI行业飞速发展,对硬件算力的需求也呈爆炸式增长,特别是生成式大模型的火热,SOTA模型的参数规模提升了几个数量级。一方面,可预见的模型参数量增长需要更大规模的片上算力,在存内计算技术应用中即意味着更大规模的存算阵列以及更多的宏单元堆叠;另一方面,复杂网络的推理或训练需要存算阵列能够支持更高精度的计算类型,例如INT16、FP16、FP32等数据类型的乘累加计算。
对于存算宏单元的设计,从过去一年中存算领域的高水平会议/期刊论文发表情况来看,数字域的高精度存内计算依然是主流,数字域计算极高的信噪比与鲁棒性使高精度的乘累加计算成为可能,在更低的芯片制程下,数字域存算宏单元也能达到很高的面积效率与计算吞吐。而另一方面,越来越多以存算宏单元为乘累加引擎构建的微架构/片上系统的出现是大势所趋,随着模型参数量的急剧增长,难以在片上实现参数的全静态处理,因而不得不将包括了大容量的片外存储(DDR)在内的存储器层级(Memory Hierarchy)纳入系统设计的考虑范畴,一些基于高带宽存储器(HBM)的存内处理体系的出现很好地印证了这一点。此外,在对功耗和性能要求严苛的边缘侧,以ReRAM和MRAM为代表的非易失性存储器存内/近存计算架构能够实现极低的待机功耗,有望在边缘端实现高能效/高安全性的网络推理乃至模型微调。
(一)存算一体学术界重点事件盘点
1. ISSCC2023会议于2月19日召开
1.1 AMD 董事长兼首席执行官苏姿丰在会上表示,到目前为止,实现计算能力持续复合增长的最大限制因素是能效,以加速下一代高性能计算所需的能效创新,并最终实现 zettascale级别的性能。要完全应对这一挑战,就需要通过扩展特定领域的架构来加速核心算法,在从晶体管到软件系统各个方面大规模部署人工智能。
7.4 台积电(TSMC)基于4nm FinFET 工艺开发了一款数字域存内计算宏单元(DCIM),通过降低阵列利用率,即部分使能阵列的方式,重构了存储的权重(Weight)的位宽(8b/12b),输入特征值(Input Feature)以比特串行(Bit-Serial)的方式输入宏单元,在乘累加后处理模块处实现了8/12/16b的位宽重构,以此来支持更高精度的整型矩阵向量乘计算。此外,该设计采用双8T+NOR门的比特单元设计以支持运算和更新的同时进行(PingPong设计)。台积电的研究人员还根据运算时流水线的延时余量设计了混合阈值电压的晶体管分布,在SRAM阵列和加法树前级采用高阈值电压晶体管以降低漏电,在后级加法树采用低阈值电压晶体管以降低延时,平衡了宏单元的整体功耗与延时。最终在先进工艺和设计技巧加持下,宏单元达到了6163-TOPS/W/b(~96TOPS/W for INT8)的能效以及4790TOPS/mm2/b(~75TOPS/mm2 for INT8)的算力密度。
7.1 & 7.2 台湾清华大学(NTHU)和东南大学(SEU)分别提出了两套基于SRAM-CIM的存内实现浮点计算的方案,NTHU的研究人员将进行乘累加计算的权重指数(Exponent)和特征值指数相加,在时域中完成一批数据(128组)的移位对指,根据对指结果对特征值尾数(Mantissa)进行移位后再与权重尾数在电荷-数字混合域进行整型的乘累加计算,而SEU的研究人员将权重数据和特征值数据分开对指,对指移位完成后的权重数据存储在SRAM阵列中,对指移位完成后的特征值数据再以2bit串行的方式输入到宏单元中在数字域完成尾数的乘累加计算。
值得一提的是,NTHU的工作以数模混合的方式平衡了整体的能量/面积效率与计算准确度,而SEU的工作利用近似数字计算的方式同样在能效/面效与准确度中做出了权衡(tradeoff)。两个宏单元支持的浮点数据类型不约而同地都选择了Google在TPUv3上提出支持的浮点数类型BF16,BF16拥有比FP16更大的数值空间,计算时不易溢出,其8bit的尾数位宽对于存算宏单元支持BF16/INT8的重构也十分友好。最终NTHU的宏单元(22nm)实现了16.22~17.59的TFLOPS/W的能效,在90%的输入稀疏性下能够达到70.21 TFLOPS/W的峰值能效,而SEU的宏单元(28nm)达到了14.04~31.6 TFLOPS/W的浮点能效以及19.5~44 TOPS/W的整型(INT8)计算能效。
16.1 & 16.2 清华大学(THU)和复旦大学(FDU)分别提出了两款支持Transformer类型网络的加速器,均以整型的SRAM-CIM宏单元为乘累加引擎,THU的加速器支持多模态Transformer,利用注意力计算的稀疏性对计算token进行实时剪枝,宏单元利用数据的比特稀疏性提高计算能效最终达到了48.4~101.1的INT8系统能效以及12.1~60.3的INT16系统能效,FDU的工作同样利用了数据稀疏性,使用蝶形数据压缩电路跳过块状(block-wise)的零数据,提升了系统运算性能,最终达到了25.22的INT8系统能效。
16.4 中科院微电子所(IMCAS)和清华大学(THU)共同发表的支持浮点计算的存算加速器工作提出了另一种实现高精度浮点计算的思路,该工作利用了神经网络计算的数据分布特征,将大的离群数值与其他数据分开计算,大的离群数值总量小,但对计算结果影响大,这部分被分配到数字逻辑中进行无精度损失的计算,而其他的总量大,数值相对小的数据被送往存算宏单元中完成乘累加计算,忍受并行计算的对指移位带来的截断精度损失。架构整体还对比特串行计算的稀疏性以及离群值的稀疏性做细致的加速,达到了17.2~91.3的系统浮点能效(FP16的数据类型)。
33.2 & 33.4 & 16.6 台湾清华(NTHU)&台积电(TSMC)团队以及东南大学(SEU)团队分别发表了两款基于MRAM的近存/存内计算宏单元(33.2、33.4)。NTHU&TSMC团队在22nm工艺下实现了一款8Mb大小支持4/8b近存计算宏单元,在部署ResNet20网络时能够达到160.1TOPS/W的峰值能效(@90%输入稀疏度),而SEU团队在70nm下验证了一款2Mb大小支持单比特存内计算的MRAM宏单元,为改善传统1T1M比特单元的读写性能,该团队创新性地提出了伪2T2M的比特单元,最终在0.85V供电电压下测得能效标准值41.5TOPS/W.
此外,NTHU&TSMC团队在28nm工艺下实现了一款基于ReRAM存内计算的边缘端处理器(16.6),该处理器摈弃传统的片外非易失性存储+片上逻辑计算的架构,利用片上4MByte的ReRAM存内计算宏单元实现了极低功耗的休眠-启动的边缘端场景应用。该加速器支持1~8比特的计算精度,在0.8V供电电压,INT8部署MobileNetv2网络的工作条件下测得芯片整体能效可达51.4TOPS/W.
2. 2023年9月14日,清华大学(THU)团队在Science杂志上发表首颗实现片上训练的ReRAM存算一体芯片.其将所有的网络参数部署在片上的ReRAM阵列,利用推理结果的符号位对忆阻器单元的电导进行调制,完成误差的反向传播,进而完成网络的片上训练,论文展示了芯片在小车循迹、手写数字识别、语音识别等任务上优秀的学习能力和推理精度。
(二) 产业界重点事件盘点
1. 后摩智能5月发布首款基于存算一体架构大算力智驾芯片后摩鸿途®️H30

后摩鸿途®️H30基于 SRAM 存储介质,采用数字存算一体架构,拥有极低的访存功耗和超高的计算密度,在 Int8 数据精度条件下,其 AI 核心IPU 能效比高达 15Tops/W,是传统架构芯片的7 倍以上。
得益于存算一体的架构优势,H30 基于 12nm 工艺制程,在 Int8 数据精度下实现高达 256TOPS 的物理算力,所需功耗不超过35W,整个 SoC 能效比达到了 7.3Tops/W,具有高计算效率、低计算延时以及低工艺依赖等特点。
2. 特斯拉DOJO 量产开始
2021年,特斯拉在AI DAY上公布的AI训练芯片“D1”及超级计算平台dojo架构细节。2023 年 7 月,特斯拉官方称Dojo 的量产已经正式开始。D1 采用台积电7nm工艺制造,核心面积达645平方毫米,仅次于NVIDIA Ampere架构的超级计算核心A100(826平方毫米)、AMD CDNA2架构的下代计算核心Arcturus(750平方毫米左右),集成了多达500亿个晶体管,相当于Intel刚刚发布的具有高达1000亿颗晶体管的Ponte Vecchio计算芯片的一半,内部走线,长度超过11英里,也就是大约18公里。

据特斯拉介绍,其D1芯片集成了四个64位超标量CPU核心,拥有多达354个训练节点,特别用于8×8乘法,支持FP32、BFP64、CFP8、INT16、INT8等各种数据指令格式,都是AI训练相关的。
特斯拉称,D1芯片的FP32单精度浮点计算性能达22.6TFlops(每秒22.6万亿次),BF16/CFP8计算性能则可达362TFlops(每秒362万亿次)。为了支撑AI训练的扩展性,它的互连带宽非常惊人,最高可达10TB/s,由多达576个通道组成,每个通道的带宽都有112Gbps。实现这一切热设计功耗为400W。
Tesla Dojo处理器采用数据流近存计算架构,通过大量更快更近的片上存储和片上存储之间的流转减少对内存的访问频度,提升系统性能,算力达362TFLOPS@FP16,每个D1芯片放置440MB SRAM,解决内存墙问题。
美国纽约州州长Kathy Hochul在今年1月26日举行的新闻发布会上表示,特斯拉将投资5亿美元,在该州的布法。 罗市(Buffalo)建造一台“Dojo”超级计算机。
3. 后摩智能点亮首款RRAM大容量存储芯片并完成测试验证
后摩智能完成首款可商用的RRAM测试及应用场景开发,探测及证实了现有工业级的RRAM的技术边界。后续将与车规级应用场景结合,希望与伙伴共同打造新兴存储及新型存算计算范式,赋能客户。
目前,后摩智能该款RRAM芯片能够满足在高质量/高安全性要求的商用场景,更新版本可以实现对车规级应用的支持,尤其是车载娱乐系统、部分低等级车规要求,在工业电子类/消费电子类,其功能/性能能满足对eFlash场景的替代,甚至能够改变原有计算架构,对只读/少读场景有较大的革命优势,尤其在亚22nm工艺之后,有望能够进一步成为高端芯片的嵌入式存储器使用。
在功耗性能方面,其整体功耗低至60mW,支持power down模式,支持不同区域分别关断功能,支持sleep模式等,可以进一步在不同应用场景进行功耗控制。
4. 2023年9月,硅谷AI芯片初创公司D-Matrix获得1.1亿美元的B轮融资
领投方为新加坡顶尖投资公司淡马锡(Temasek),微软和三星等科技巨头跟投。D-Matrix采用SRAM存算一体+Chiplet技术来构建针对大模型的计算芯片。
D-Matrix的新融资将用来打造其数字内存计算 (DIMC) Chiplet推理计算卡Corsair,据称推理速度是英伟达H100 GPU的9倍,如果是计算卡集群,与英伟达的类似解决方案相比,功率效率提高20倍,延迟降低20倍,成本降低高达30倍。
每块Corsair计算卡拥有8个Jayhawk II Chiplet,每个Jayhawk II提供2Tb/s(250GB/s)的芯片到芯片带宽,单块Corsair计算卡就拥有8Tb/s(1TB/s)的聚合芯片到芯片带宽。但是这一套硬件将在2024年才能正式投入使用。
5. 三星电子在Hot Chips 2023上公布了高带宽存储器(HBM)-内存处理(PIM)和低功耗双倍数据速率
(LPDDR)-PIM研究成果。这两款存储器是未来可用于人工智能(AI)行业的下一代存储器。近年来,随着内存瓶颈成为AI半导体领域的一大挑战,HBM-PIM作为下一代内存半导体备受瞩目。
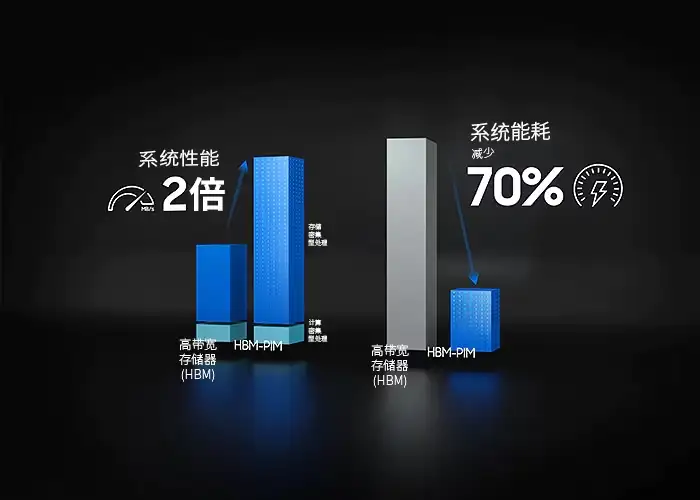
三星电子展示了一项研究成果,将HBM-PIM应用于生成式AI,与现有HBM相比,加速器性能和功效提高了一倍以上。研究中使用的GPU是AMD的MI-100。为了验证MoE模型,还构建了 HBM-PIM 集群。集群中使用了 96 台配备 HBM-PIM 的 MI-100。在MoE模型中,HBM-PIM还表明加速器性能比HBM高两倍,功率效率比HBM高三倍。
除了HBM-PIM,三星电子还展示了LPDDR-PIM。LPDDR-PIM 是一种将 PIM 与移动 DRAM 相结合的形式,可直接在边缘设备内处理计算。由于它是针对边缘设备开发的产品,因此带宽(102.4GB/s)也较低。三星电子强调,与DRAM相比,功耗可降低72%。
二、2024年存算一体(Compute-In-Memory)技术方向前瞻
1.顶层架构设计加速存内计算技术应用落地
目前,在电路宏单元层面,不论是基于SRAM或DRAM的存内高性能计算还是基于新型非易失存储器的极低功耗存内计算,在存储阵列内设计计算单元以实现较大规模数据并行计算的方式已被验证具有很高的计算能效与算力密度,但是,想要将存算技术真正落地,与存内计算电路宏单元配套的顶层架构设计以及配套的软件编译必不可少,尤其是针对较大规模网络在整个片上系统的部署,因而展望2024,有关存算一体技术的架构探索与加速器设计仍将持续火热;
2. 高精度可重构的存算宏单元设计,向着通用计算场景进发
目前,面对愈来愈复杂多变的网络推理任务,网络模型对于硬件支持的计算精度要求也在不断提高,以往的宏单元支持的INT8整型计算能够较好地完成CNN等网络的部署,而类Transformer网络往往要求INT16甚至更高的数据精度,另一方面,较大规模的网络参数以及多变的网络类型对存算宏单元的灵活性提出要求,因而支持高精度、可重构的存算宏单元,迈向着更通用的应用场景;
3. 先进封装/新型工艺助力存算一体实现极致的系统性能
一方面,2.5D/3D/3.5D等先进封装技术快速发展,高带宽存储器(HBM)、混合键合(Hybrid Bonding)、芯粒(Chiplet)等先进互连技术将实现更高速的片间互连,这也会给设计大算力的存内计算系统带来机遇;另一方面,基于新型非易失性存储器的存内计算将赋能更低功耗的边缘端网络推理,新型器件例如FeRAM、CFET等有待演化出更先进的存储&计算一体电路。
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 当我拿出 4 卡 GPU 测试 Ansys 流体仿真,阁下该如何应对?
- 2 英飞凌2024汽车创新峰会:揭秘全球汽车芯片No.1供应商的创新与布局
- 3 收购GaN Systems后,英飞凌氮化镓迎来新突破
- 4 ADI携4大产品线亮相上海慕展,引领智能边缘行业新升级
- 5 迈来芯亮相上海慕展,解析技术创新布局与中国本土化战略
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号