来源:内容由半导体行业观察(ID:icbank)
编译自
「anandtech」,谢谢。
当AMD 宣布将在 Hot Chips 上展示其最新的 Zen 3 微架构时,我期待着这家公司能披露更多的信息。而在 Zen 3 的演示中,情况也大致如此,这些新更新信息对于考虑 AMD 的增长战略非常重要。
为了解释为什么这些信息很重要,我们必须讨论将两个元素(如 CPU 内核、完整的 CPU,甚至 GPU)连接在一起的不同方式。
Connectivity: Ring, Mesh, Crossbar, All-to-All
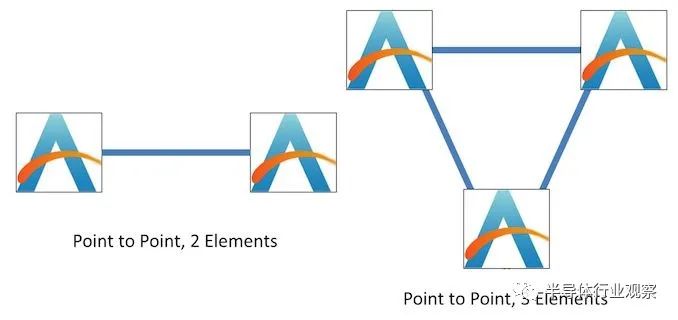
对于两个处理元件,连接它们的最简单方法是直接连接。类似地,对于三个元素,每个部分都可以直接连接到另一个部分。
当我们在面对四个元素时,选项变得更多。这些元素可以类似地以多对多的配置排列,也可以排列成一个环。
在右侧的完全连接情况下,每个元素都相互直接连接,从而实现完全连接带宽和最低延迟。但是,考虑到每个元素必须具有三个连接,因此需要权衡功耗。如果我们将其与环进行比较,每个元素只有两个连接,固定功耗,但是由于每个元素之间的平均距离不再恒定,我们必须在环周围传递数据,这会导致延迟和带宽取决于在环周围发送的其他内容。
同样对于环,我们必须考虑它是只能在一个方向上发送数据,还是在两个方向上发送数据。
几乎所有现代环设计都是双向的,允许数据在任一方向流动。对于本文的其余部分,我们假设所有环都是双向的。一些更现代的英特尔 CPU 具有双双向环,以双倍功耗为代价实现双倍带宽,但在非带宽受限的情况下,可以“关闭”一个环以节省电力。
考虑这两种四元素设计的最佳方法是通过连接数和到其他元素的 average hops:
-
4-Element 全连接:3 个连接,1
average hop
-
4 单元双向环:2 个连接,1.3
average hops
在这里,带宽和功耗之间的平衡更为极端。环形设计仍然依赖于每个元素两个连接,而全连接拓扑需要每个元素五个连接。然而,全连接设计保持平均一跳访问任何其他元素,而环现在更复杂,平均每次访问 1.8 跳(hops)。
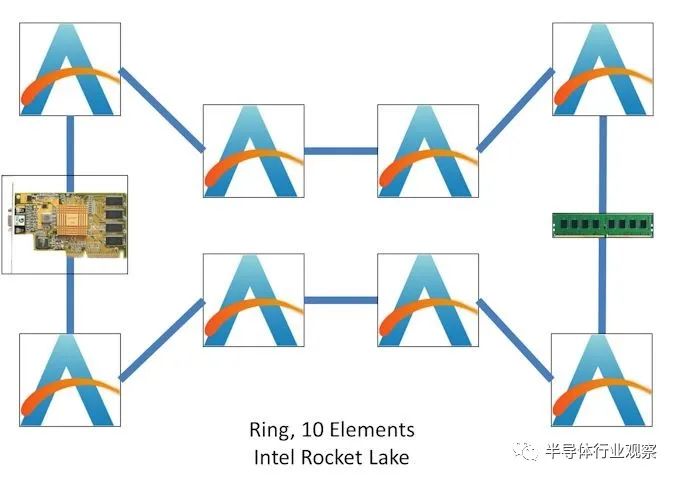
我们可以无限期地扩展两者,但是在现代 CPU 设计中,如果增加所有功能以维护这些完全连接的设计,则性能上会有很大的权衡。这里还有一点需要注意,我们还没有考虑设计中可能还有什么——例如,以具有环而闻名的现代英特尔台式机 CPU 也会将 DRAM 控制器、IO 和集成显卡放在环上,所以 8 核设计不仅仅是一个 8 元素环:
这是一个简单的模型,包括 DRAM 和集成显卡。说实话,英特尔并没有告诉我们有关连接到环的所有信息,这意味着很难确定所有东西的位置,但是通过综合测试,我们可以看到环跳的平均延迟。
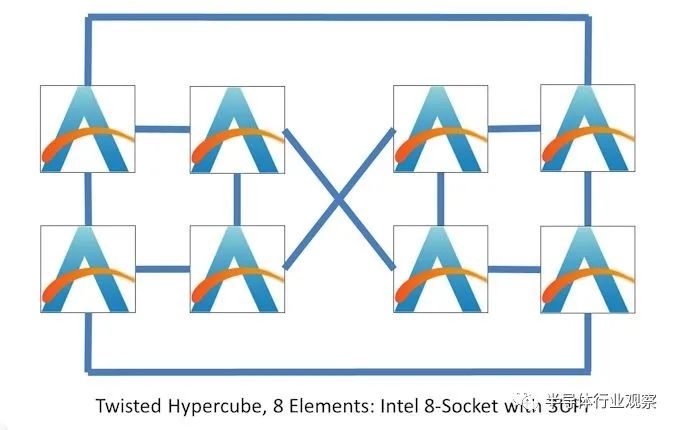
英特尔实际上已经开发出一种方法,通过让每个元素有机会拥有三个连接,将 8 个元素以非环方式连接在一起,但也不是完全连接。同样,这里的想法是为了改善延迟和带宽而牺牲一些能力:
这类似于取立方体的八个角,在两侧创建环,然后在正交面上实施替代连接策略。这意味着每个元素都直接连接到其他三个元素,其他所有元素都相距两跳:
-
扭曲超立方体,8 个元素:3 个连接,平均 1.57 跳
在下一代 Sapphire Rapids 中,英特尔为每个 CPU 提供 4 个连接,平均跳数为 1.43。
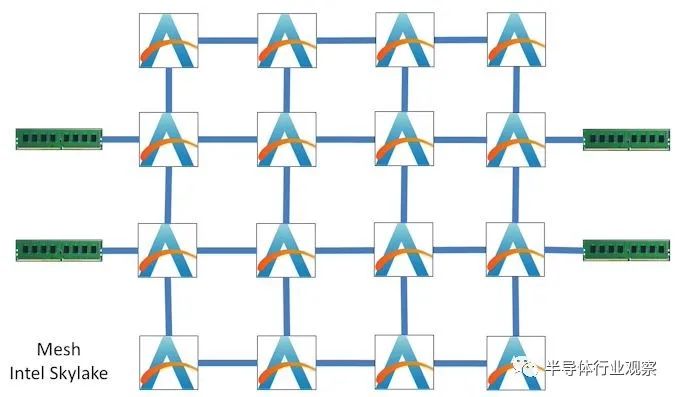
在一个环中超过 10 个元素,至少在现代核心架构中,由于延迟增加,这似乎有点问题。您最终会在环上施加越来越大的压力,因为更多的内核通常意味着需要更多的带宽来保持它们都接收到数据。英特尔和其他大核单芯片人工智能公司通过实施二维网格解决了这个问题。
网格设计权衡了一些额外的每元素连接,以获得更好的延迟和连接性。平均延迟仍然会有所不同,并且在数据流密集的情况下,数据可以通过多条路线到达需要去的地方。
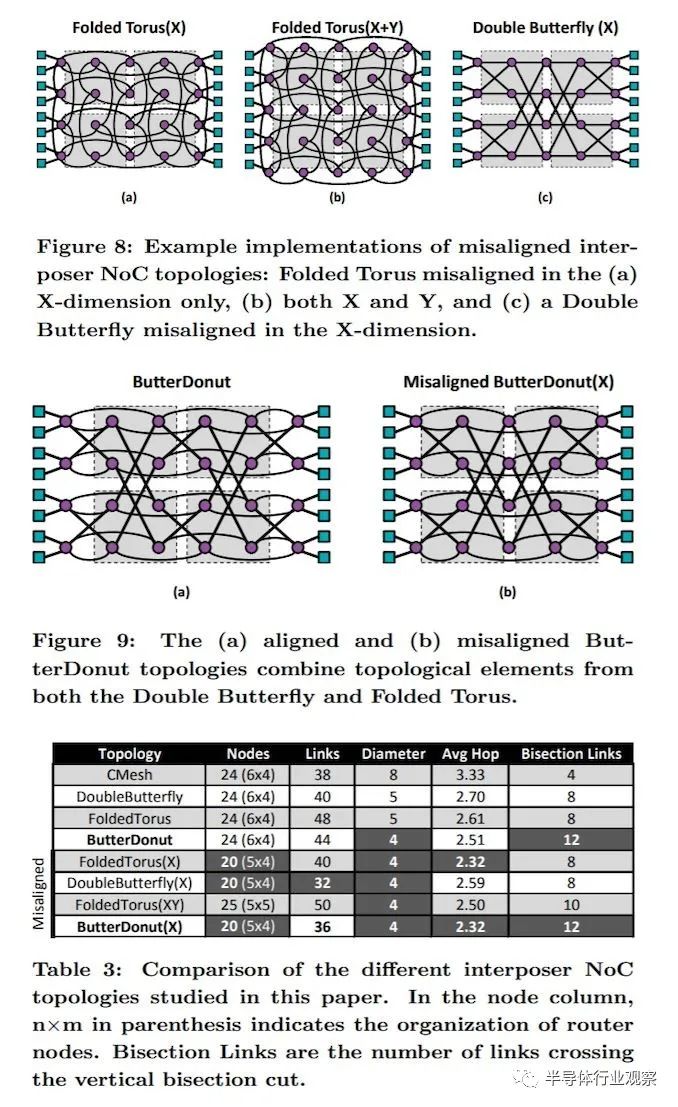
2D 网格是最简单的布局——隔壁的每个元素都在 x/y 单位之外。它围绕平面中的每个元素旋转,没有连接重叠。在利用一点 3D 的拓扑方面已经做了很多工作,当芯片上的堆叠技术被广泛实施时,我们可能会去这方面。之前有一篇论文硕大,如果在中介层级别实施网状网络, ButterDonut 可能是一个好主意,因为它最大限度地减少了跳跃链接。
另一种选择是Crossbar。Crossbar 最基本的观点是它只为单个连接实现了有效的 all-to-all 全连接拓扑。Crossbar有多种类型,同样取决于带宽、延迟和功耗要求。Crossbar并不神奇,它真正的作用是解决连接问题。
在本文的这一点上,我们还没有谈到这些元素是如何连接在一起的。在芯片内部通常意味着在硅中,但是当我们谈论将芯片连接在一起时,可能是通过interposer或 PCB,这在它可以容纳的高速连接数量和数量方面受到更多限制。通常需要物理外部Crossbar开关来帮助简化封装上的连接,例如 NVIDIA 允许 8 个 Tesla GPU 通过经过 NVSwitch(实际上是一个Crossbar)以全对全的方式连接。
在这个例子中,这是一个 Switching Crossbar 的图表,它充当一个矩阵或一个内部网格,管理数据需要去哪里。
在这些类型的环境中,即使与每个元素可能有两个或三个连接的其他配置相比,“只有”一个到纵横的连接,但考虑到纵横的带宽可能是直接连接的两倍/三倍。这仍然意味着每个元素都有多个有效连接,并在需要时享受倍数的带宽。
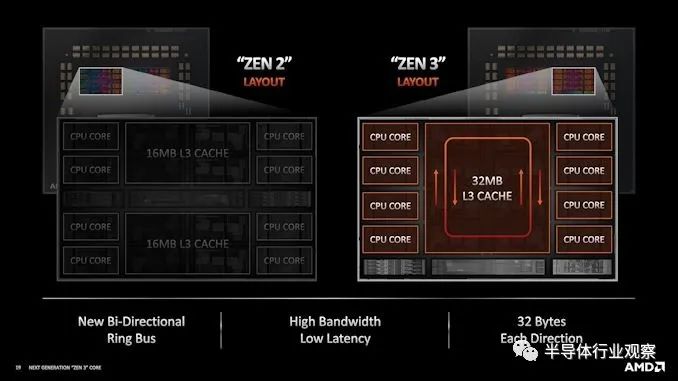
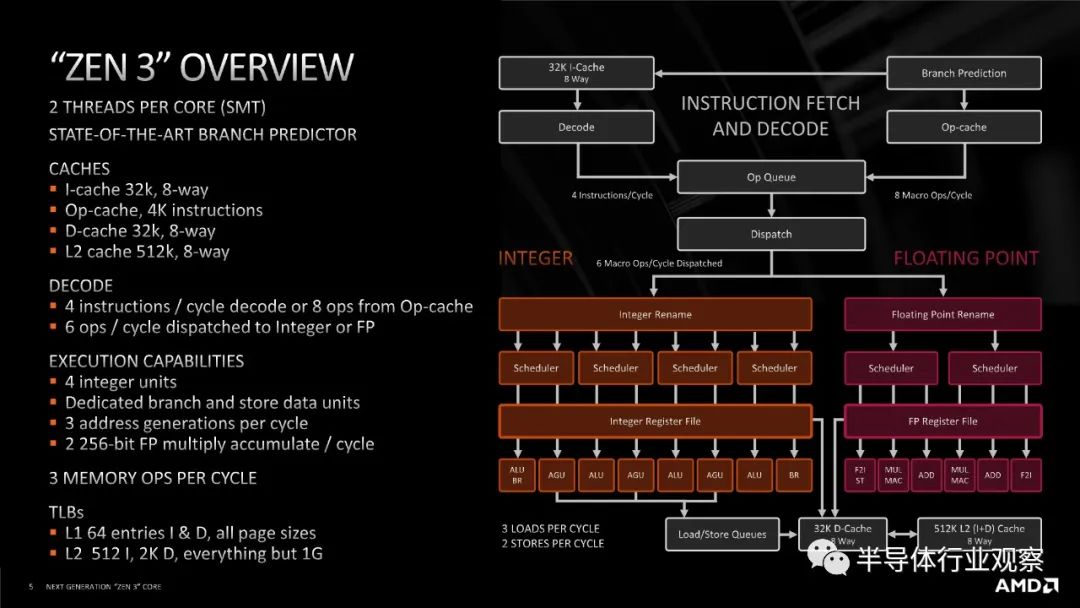
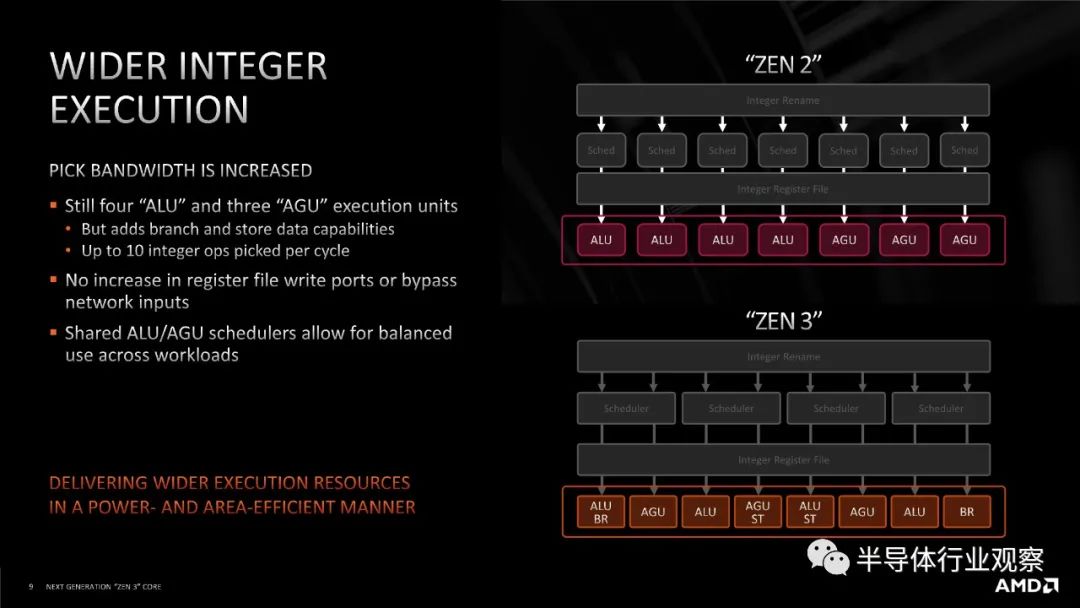
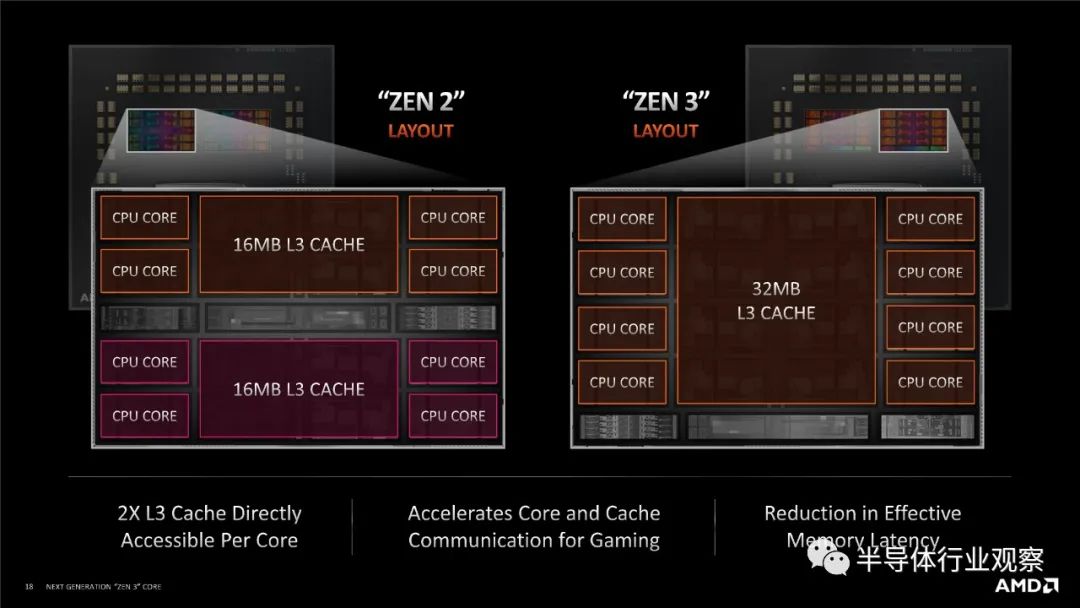
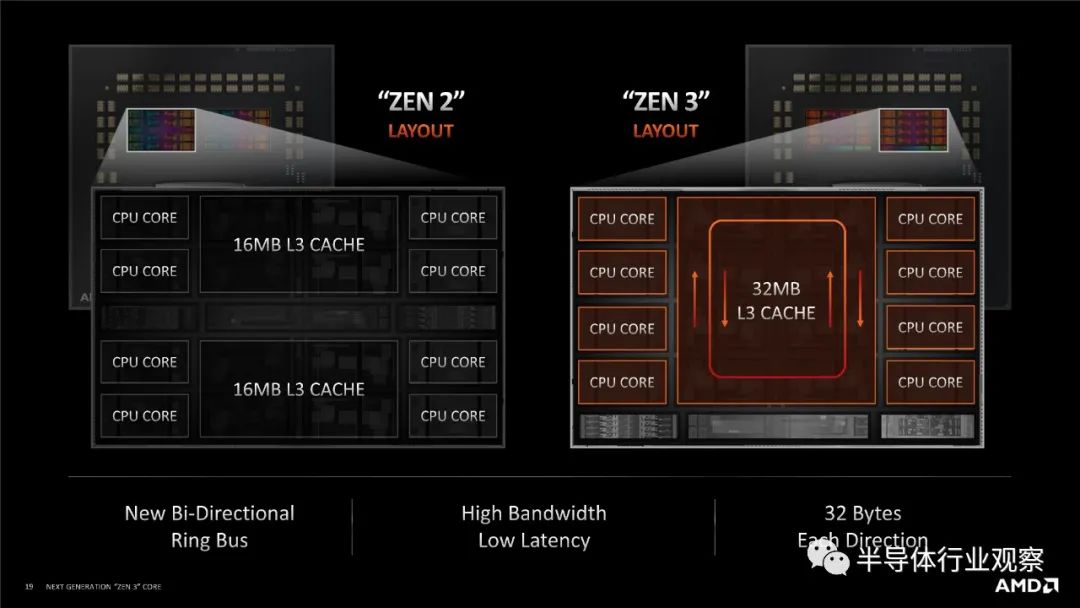
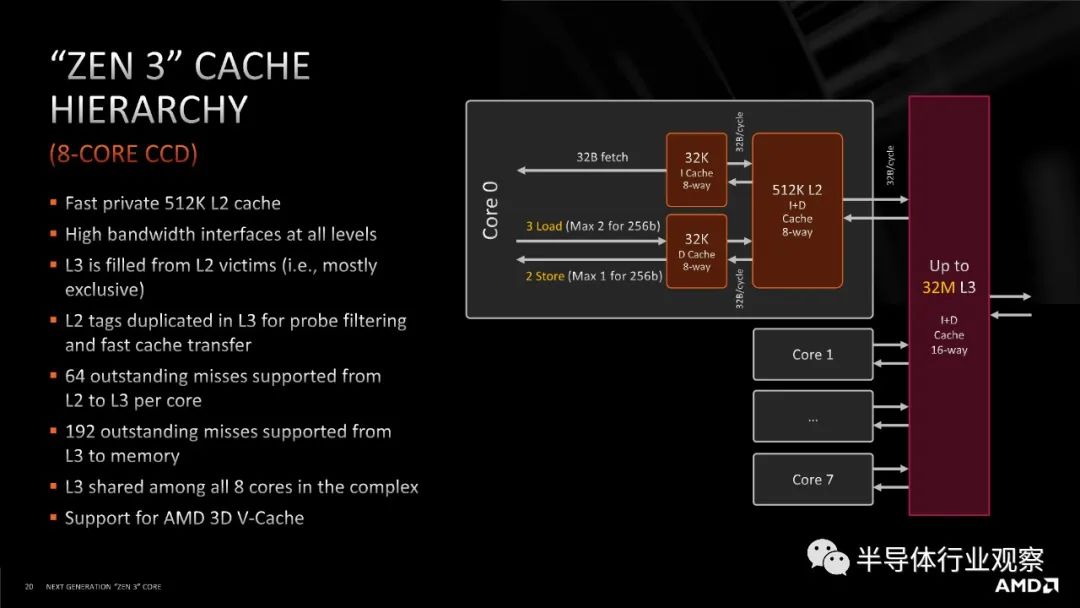
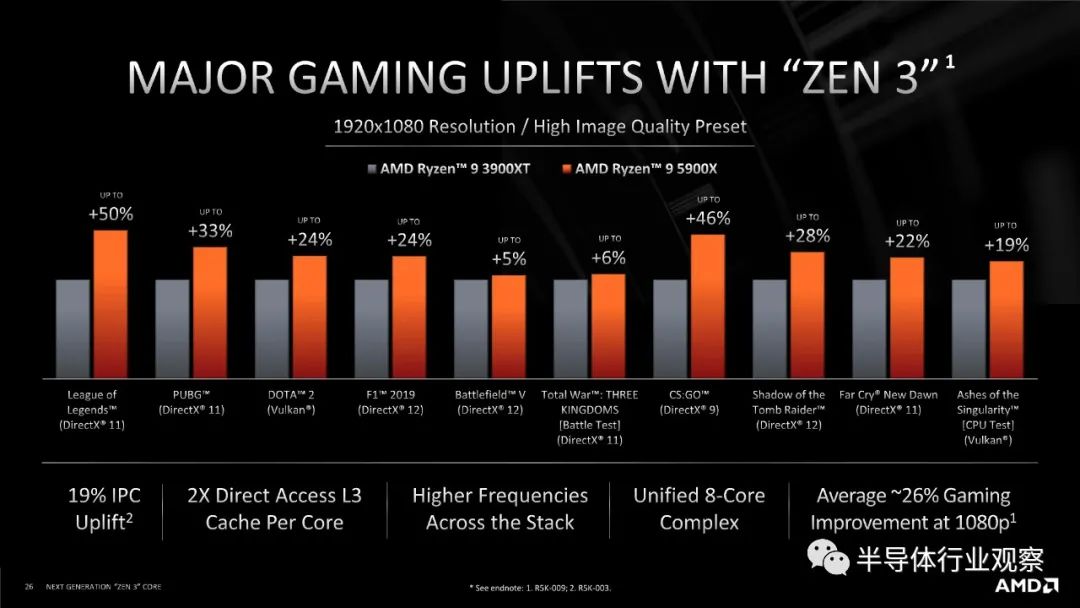
进行所有这些关于连接性的解释的原因是,当 AMD 从 Zen 2 转移到 Zen 3 时,它增加了 CCX(core complex)内的核心数量。在 Zen 2 中,一个八核chiplet(小芯片)有两个四核 CCX,每个都连接到主 IO 芯片,但在 Zen 3 中,单个 CCX 增长到八核,并且每个小芯片仍保持八核。
当每个 CCX 有四个内核时,很容易想象(并测试)完全连接的四核拓扑。期望每个核心都连接到另一个核心并没有那么多额外的。现在每个 CCX 有 8 个内核,自发布以来,AMD 一直非常谨慎地谈论这些内核是如何连接在一起的。当在发布时被问及 Zen 3 八核 CCX 中的内核是否完全连接时,AMD 的总体态度是“不完全,但足够接近”。这意味着介于ring和all to all设计之间,但更接近后者。
在我们的测试中,我们看到八核的 CCX 延迟曲线与我们在四核时看到的相似。这基本上证实了 AMD 的评论——我们没有看到任何迹象表明 AMD 正在使用ring。然而,在 Hot Chips 上,AMD 的 Mark Evers(首席架构师,Zen 3)展示了这张幻灯片:
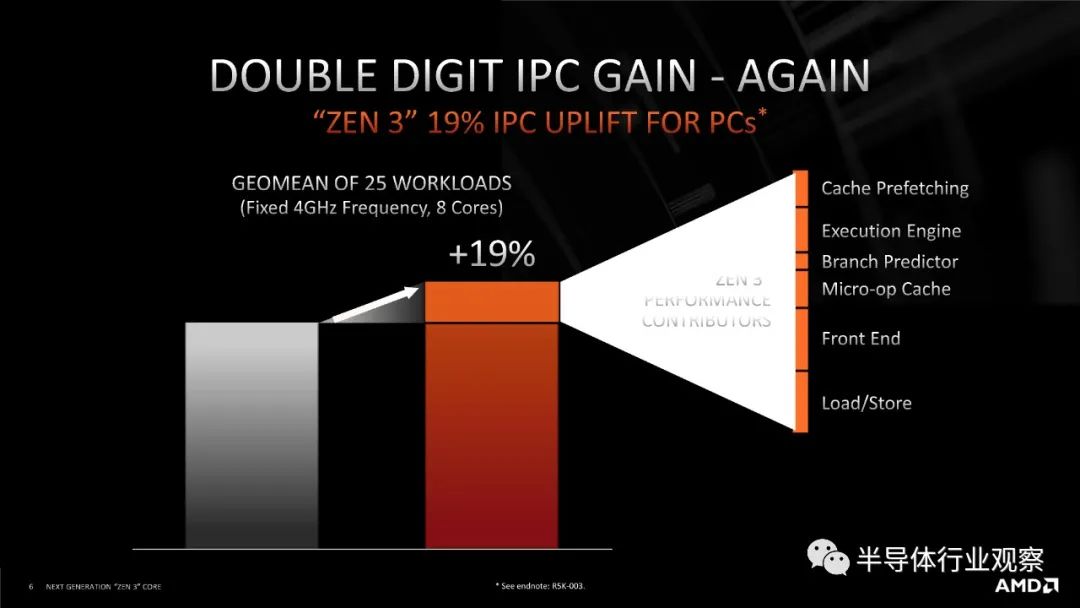
考虑到 AMD 在之前关于拓扑的讨论中的担忧,看到它如此清楚地陈述,这有点令人震惊。在本次演示中出现新内容也令人震惊,因为几乎所有其他内容都已在之前的活动中展示过。然而,这会产生影响。
由于 AMD 一直在缓慢增加其处理器的核心数量,它有两种方法可以做到这一点:更多的小芯片或每个小芯片的更多核心。随着未来几代 AMD 处理器有望拥有更多内核,它必须来自这两个选项之一。两者都是可行的,但是要考虑每个小芯片选项的核心数更多。
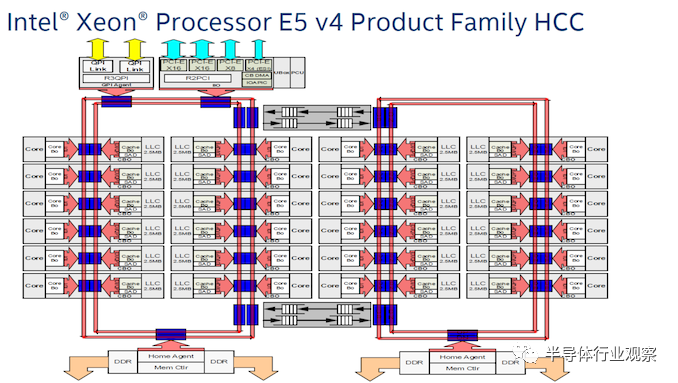
我们在这篇文章中谈到了环如何权衡每个元素的功耗和连接以换取延迟和带宽,以及如何在环成为限制因素之前对可以放入ring中的元素或内核的数量进行明显的限制. 例如,英特尔拥有使用双带宽环的 10 个内核的处理器,但它投入到环中的内核数量最多是 12 个,而 Broadwell Server 系列处理器最终使用双 12 核环。请注意,由于额外的功能,每个环有 12 个以上的环挡。
这里的每个环有 12 个用于内核的 ring stops,两个用于环到环连接,一个用于 DRAM,左环有两个额外的用于芯片到芯片和 PCIe 的停止。右边的那个环有效地连接了 17 个 ring stops/元件。在此之后,英特尔转向网格。
将此场景应用于 AMD:如果 AMD 要将 Zen 3 中每个 CCX 的内核数量从 8 个增加,那么最明显的答案是 12 个内核或 16 个内核。在ring上,这两个听起来都不那么合适。
AMD 在小芯片上增加内核的替代方法是简单地将 CCX 的数量增加一倍。与拥有两批四核的 Zen 2 一样,未来的产品可以改为拥有两批八核,这将很容易跃升至 16 核小芯片。
值得注意的是,AMD 的下一代服务器平台 Genoa 预计将拥有超过 AMD 当前一代的 64 核。这 64 个核心是八个小芯片,每个小芯片有八个核心,每个小芯片有一个八核 CCX。泄漏表明,Genoa 只是增加了更多的小芯片,但是这种策略并不是无限可扩展的。
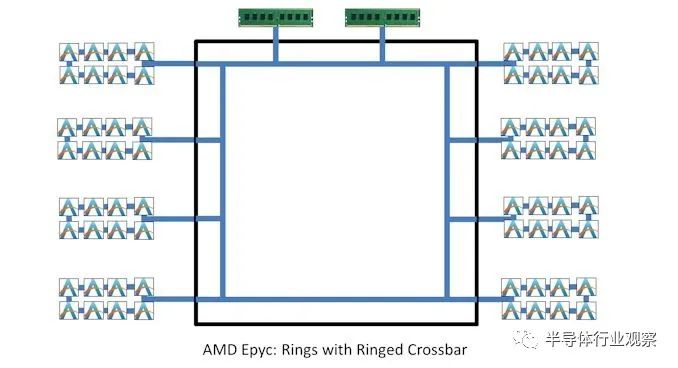
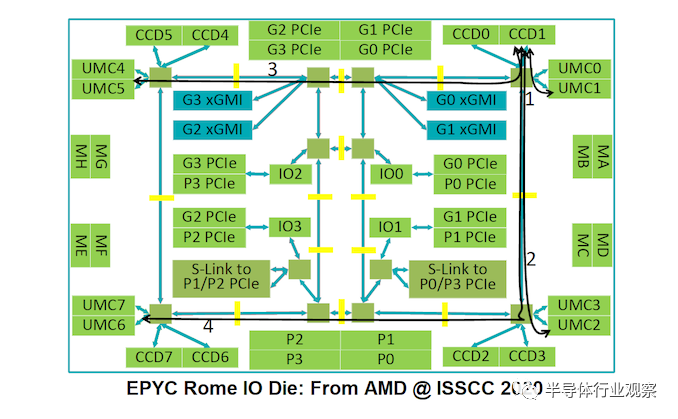
此外,考虑 AMD 在 EPYC 中的 IO die。它实际上是一个crossbar,对吧?所有的小芯片都聚集在一起进行连接,但是 AMD 的 IO 芯片本身就是一个环形交叉设计。
我们最终从 AMD 得到的是一圈环。实际上,环要复杂一些:
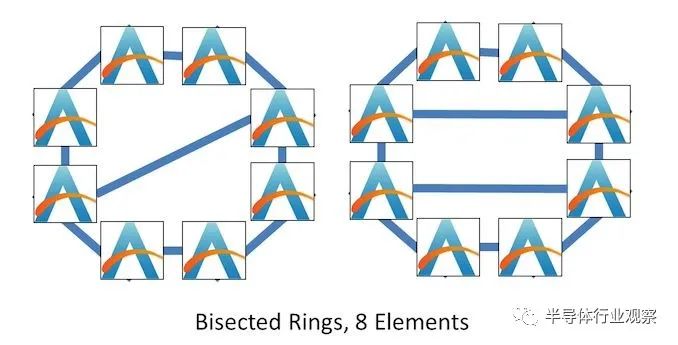
AMD 的 IO 芯片是一个大的外环,上面有八个挡块,其中一些挡块在环上有连接。它可以被认为是一个网格,或者一个二等分的环,它看起来像这样:
对于二等分环,现在每个元素的连接数和平均延迟之间存在不均匀的平衡——一些元素有两个连接,其他元素有三个。然而,这与网格相似,因为并非每个元素都具有相同的带宽或延迟配置文件。同样重要的是要注意,一分为二的环可以有一个、两个或多个内部连接。
那么AMD的Zen 3 8核CCX真的是环连接吗?
AMD告诉我们,它的八核CCX结构是双向环。如果真是这样,那么 AMD 将很难超越每个 CCX 的八个内核。通过简单地将 CCX 的数量加倍,它可以轻松地将每个小芯片的内核加倍,但除此之外,需要更改环。
在我们的测试中,我们的结果表明,虽然 AMD 的核心复合体不是all to all连接,但它也不符合我们对环延迟的期望。简而言之,它不仅仅是一个环。AMD 一直对他们的 CCX 互连的确切细节非常谨慎——通过提供一张幻灯片说它是一个环加强了这样一个事实,即它不是一个全面的互连,但我们很确定它是某种形式的二等分环, AMD 决定从演示文稿中删除的一个细节。
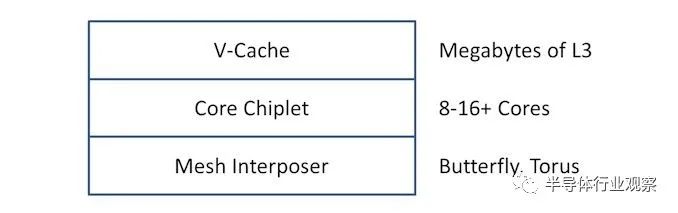
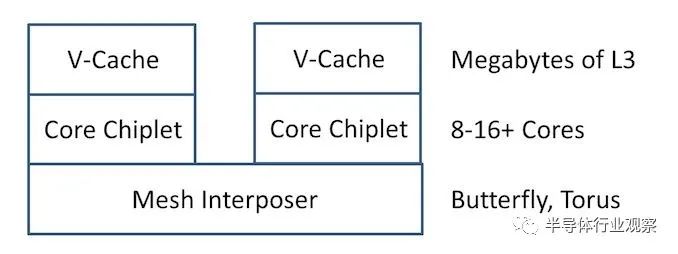
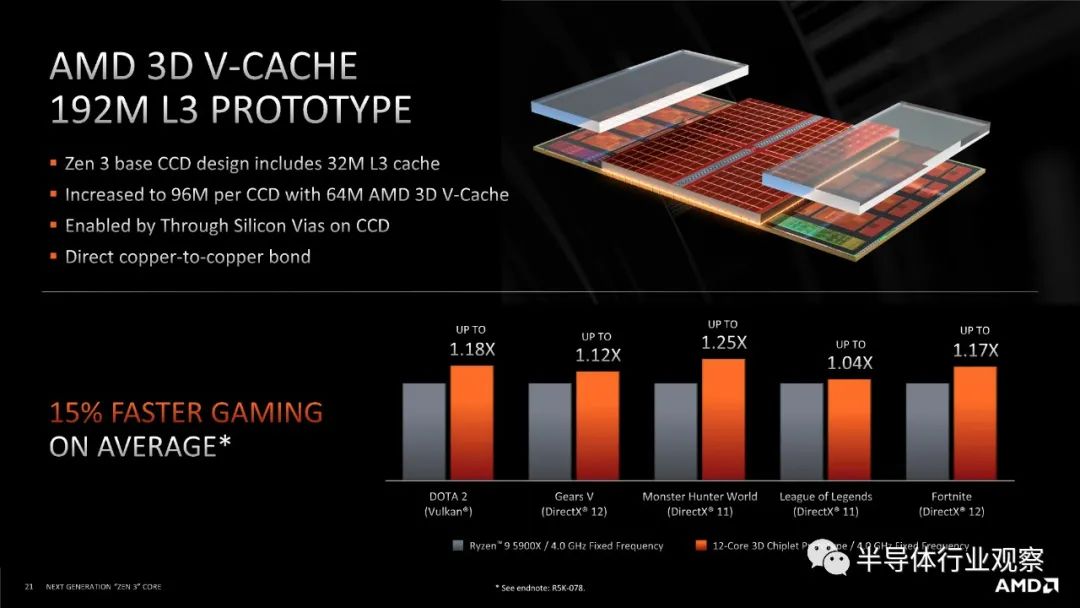
在我写这篇文章的时候,我想到了这种设计的未来可能会是什么。在 x86 世界中,AMD 率先推出了没有太多 IO 的 2D“CPU Chiplet”,并且 AMD 正在推进其去年宣布的垂直 3D 堆叠 V-Cache 技术。作为本文的一部分,我谈到了不同类型的网状互连,以及做一些创新需要中介层的事实。好吧,考虑每个 CPU 小芯片和下面的另一个小芯片,作为有效的单硅中介层,仅用于核心到核心互连。
中介层可以在更大的工艺节点上,例如 65nm,良率非常高,并将一些逻辑从核心小芯片移开,减小其尺寸或为更多创新留出更多空间。这里的关键是数据和电源所需的过孔,但 AMD 在其需要中介层的 GPU 方面拥有丰富的经验。
或者,更进一步——中介层是为多个小芯片设计的。如果 65 纳米高良率中介层很容易制作以安装两个或三个小芯片,那么只需将多个小芯片放在那里,这样它们就可以作为一个大的小芯片,在它们之间具有统一的缓存。AMD 还表示,其 V-Cache 延迟仅随线长而增加,因此 IO 芯片任一侧的两个/三个/四个小芯片之间的中介层不会显着增加缓存延迟。
小芯片和tile的出现意味着随着半导体公司开始将他们的 IP 分解为单独的硅片,并且封装技术变得更便宜和更高产,我们将在开始成为瓶颈的领域看到更多创新,例如环互连。


















★ 点击文末
【阅读原文】
,可查看本文原文链接!
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2791内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|集成电路|设备
|汽车芯片|存储|台积电|AI|封装
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!