[原创] Chiplet能为芯片设计带来哪些变革?
2021-12-22
14:00:41
来源: 半导体行业观察
Chiplet被认为是后摩尔时代继续提升芯片规模和密度的重要技术。其化整为零的理念对于架构、互联、封装都带来了新的机遇和挑战。在近日召开的第十八届中国计算机大会(CNCC2021)上,Chiplet关键技术论坛上来自工业界和学术界的学者、专家围绕“如何构建片上超算”这一设想,一起探讨了Chiplet能为芯片设计带来哪些变革性技术。
“Chiplet互联标准有没有意义?如何推进互联标准?是否有能支持数十上百Chiplet集成方案?如何看待有源硅基板?Chiplet为体系架构带来什么变化?”等一系列问题在论坛上得到了激烈的讨论和回答。
中科院计算所副研究员王郁杰首先作了开场白,他指出,当下,Chiplet已是下一代芯片的重要设计与制造方法。业界大企业如英特尔、AMD和台积电等都在采用Chiplet的设计方法。Chiplet突破了SoC的四大设计极限:它突破了光罩面积的规模极限,通过异质集成的方式突破了功能极限,使其不再受多工艺的约束,通过算力可扩展的方式提升了芯片的性能,并通过敏捷开发的方式大大缩短了工期极限。
中科院计算所目前正在就多Chiplet处理器进行研究,他们主要围绕着三大问题展开,一是
怎么算
?多芯片并行体系的机构应该怎么设计,包括系统级设计的片间如何划分,片间的任务如何映射到Chiplet上。第二个问题是
怎么连
?多Chiplet高效互联将采用哪种方法,接口与协议怎么选择等。三是
怎么合
?怎么把多个Chiplet封装起来,在合的过程中还要解决散热问题。
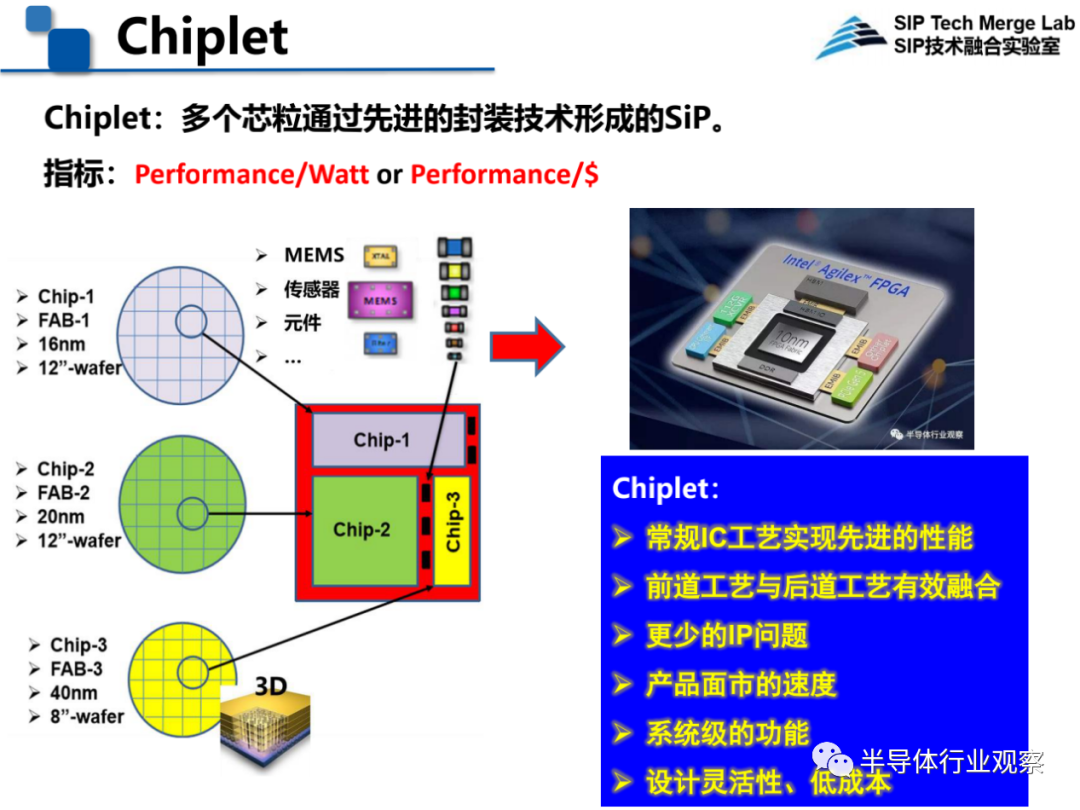
中科院微电子所王启东研究员介绍了《异质集成及其热管理技术》的发展状况和应用情况。他指出,当下摩尔定律发展撞墙,More than Moore是中国集成电路的新机遇,掌握先进的系统级封装技术是实现技术超越的良机。在这其中Chiplet是一个非常有潜力的技术。Chiplet其实就是多个芯粒通过先进的封装技术形成的SiP。
Chiplet有六大好处,一个是企业可以通过常规IC工艺实现先进的性能,二是Chiplet实现了前道工艺和后道工艺的有效融合,三是减少了IP的问题,再就是产品面市的速度大大加快,还具有系统级的功能,设计更灵活且成本低。
图源:中科院微电子所王启东在CNCC 2021上的演讲
通过芯粒集成技术,Chiplet能实现“系统集成,增加功能密度,降低成本”。再加之传递电路与器件的创新技术,可进一步提高电子产品价值,促进产业效益与规模提升。目前芯粒的技术支撑领域也非常广阔,包括新一代移动通信、高性能计算、自动驾驶以及物联网等。
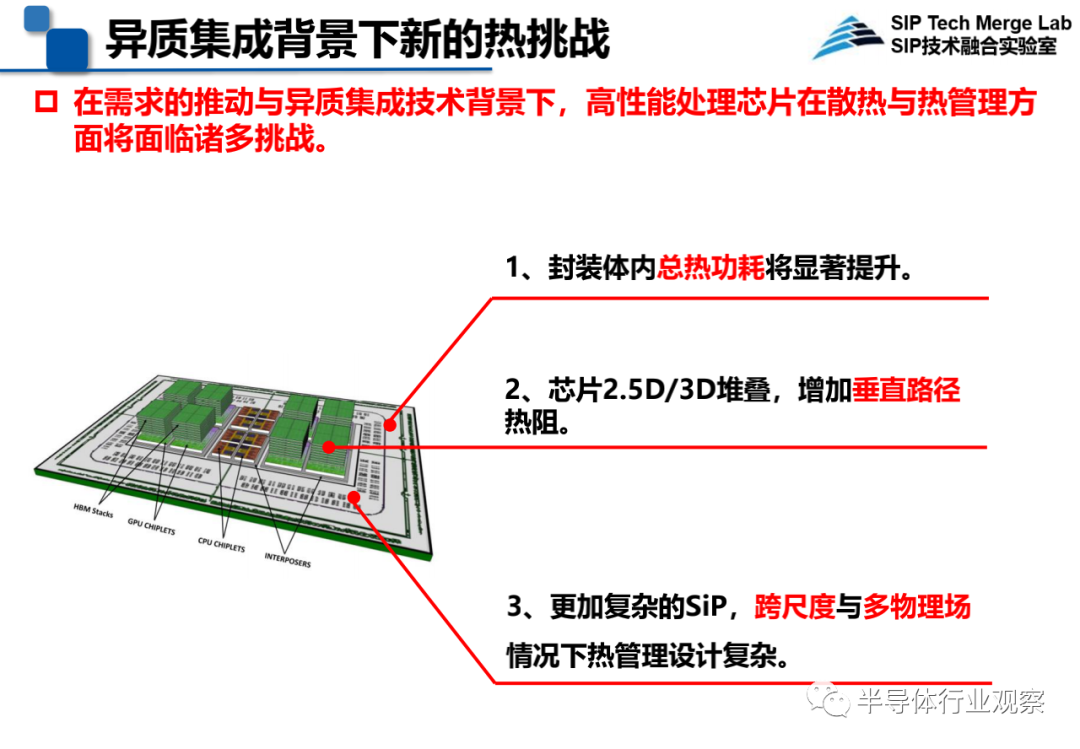
说到集成技术,现在如高性能计算、大数据和AI以及数据中心等社会需求驱动高性能处理芯片迅速发展,异质集成将是重要的解决方案。不过,在需求的推动与异质集成技术背景下,高性能处理芯片在散热与热管理方面将面临诸多挑战:
一是封装体内总热功耗将显著提升;二是芯片采用2.5D/3D堆叠,增加了垂直路径热阻;三是更加复杂的SiP,跨尺度与多物理场情况下热管理设计复杂。
图源:中科院微电子所王启东在CNCC 2021上的演讲
针对第一个挑战,王启东表示,考虑到高性能处理器芯片的封装结构以及热的传递路径,降低向上传递路径热阻在近期是最有效方案。路径一是增加热界面材料性能,降低热阻,路径二是增加热对流系数,降低热沉到环境的热阻,路径三是缩短传热路径,主要通过结构的调整去掉热界面材料TIM。针对第一个挑战,业界也作了不少研究,IBM采取芯片内嵌径向微流道相变液冷的方式,增加扰流柱进一步强化冷却;再者,通过增加3D歧管设计,可以进一步降低压降、减小热阳、降低温差。斯坦福则采用铜反转蛋白石工艺制作多孔材料,使用3D歧管来进行液冷。台积电作为一个晶圆代工厂,采用fusion bonding工艺,使用氧化硅作为TIM,实现高功率冷却。
对于挑战二来说,针对3D堆叠,IBM采用双面微流道液冷方案,顶面采用歧管微流道液冷板,底部采用内嵌微流道TSV转接板的方式。DARPA也发布了ICECOOL计划,并提出在片间或片内嵌入微流道的方案解决3D堆叠的冷却。此外,佐治亚理工采用片内嵌入微扰流柱,片间使用焊环的连接工艺实现3D片内液冷。3D片内液冷主要需要解决片间连接、片内流道密封的问题。
针对挑战三,主要是在异质集成下,模型尺寸从晶体管级到板级存在数个数量级的跨越,存在建模与网格划分等诸多困难。同时,更多功能的融合,设计过程中需要考虑的物理场及其相互之间的耦合作用对产品开发将非常重要。当下商业仿真软件,针对三个及以上的物理场的耦合仿真存在很大困难。所以就需要进行跨尺度与多物理的建模与仿真的研究。
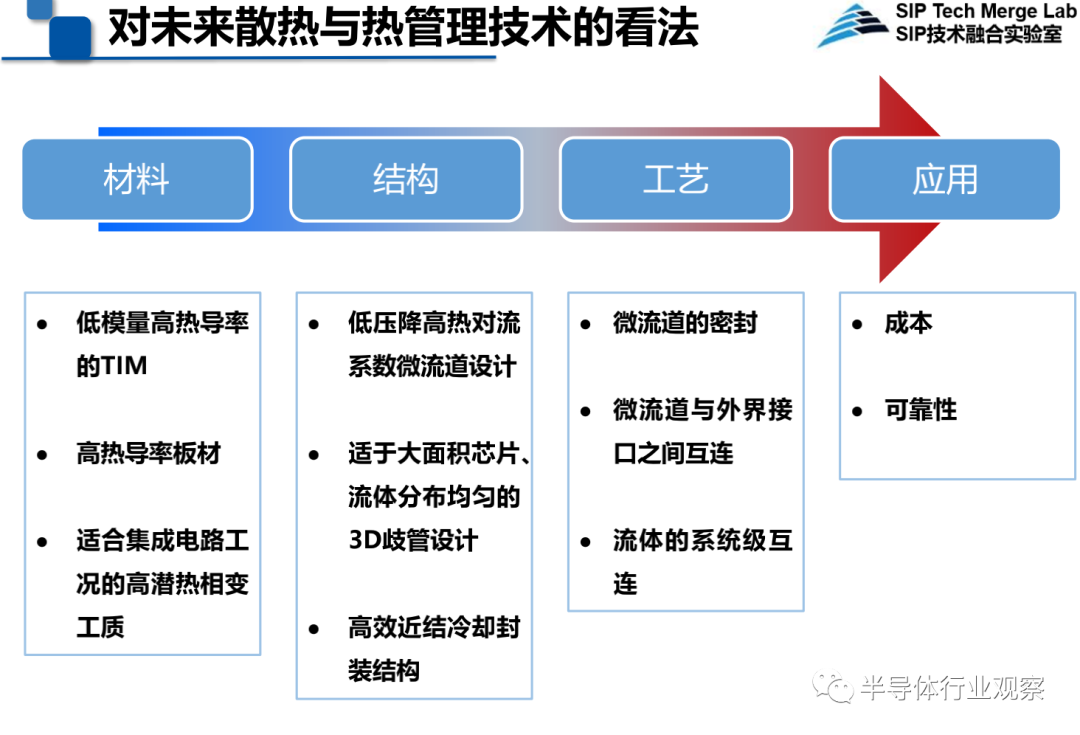
王启东总结道,对于未来散热和热管理技术,需要从材料、结构、工艺和应用多个领域来逐个击破。总之,现在谁能把大功率高热点问题解决,谁能用低成本或者更简单的方案实现,谁就能在业界占据有利地位。
图源:中科院微电子所王启东在CNCC 2021上的演讲
从产业规模来看,不计入快速出现的新技术,仅从目前技术来看,先进封装市场会有年8%的复合增长,Yole咨询预计,到2024年将达到450亿美元的规模。目前王启东团队所在的系统封装与集成研发中心是中国科学院微电子研究所的骨千科研部门之一,主要从事先进电子封装与集成技术的研究与开发,该封装中心团队也是国内最早、最全面进行系统级封装技术联合研究的团队。目前其产业化项目也在无锡落地,成立了华进半导体,他们也不断在先进封装领域进行探索。
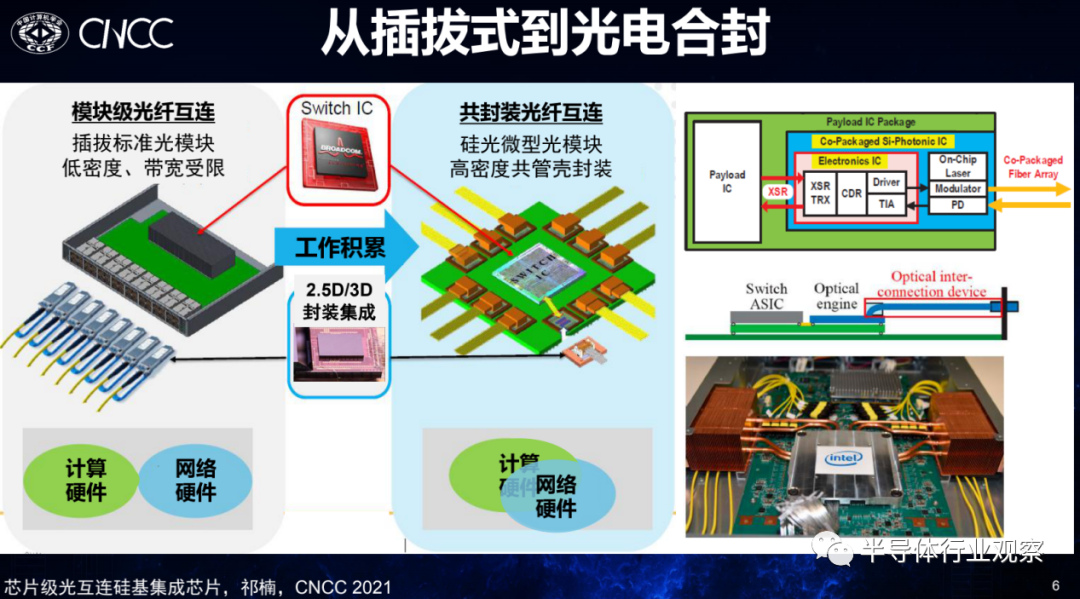
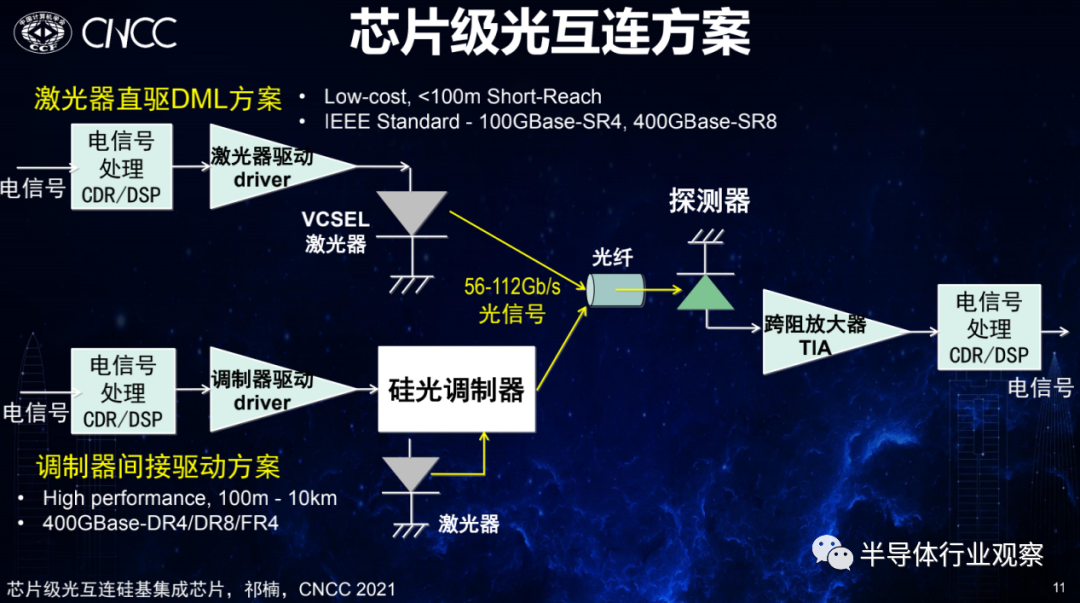
中科院半导体研究所的祁楠发表了主题为《面向芯片级光模块的硅基集成芯片》的演讲,他首先讲到,当下光互连正在往更短距离、更高密度的方向上发展,逐渐在板上芯片间和芯片上进行互连。其需要解决的问题无外乎也是带宽密度和能耗效率,集成化将是一大有效解决方案。从光通信本身来看,其也在经历从分立器件向集成化发展的趋势,以交换机为例,它正从以前的插拔式过渡到
光电合封(CPO)
的模式,英特尔和博通等公司也展示了相关的原型产品。其基本思路是把之前需要进行背板传输的长距离的电线或者铜线改成光纤互联。无数研究都证明了基于光的互联成为可能。
图源:中科院半导体研究所祁楠在CNCC 2021上的演讲
那么,光电集成化的优势什么呢?一个是电光转换靠近Switch,节省了re-timer,降低约75%功耗,而且Switch总带宽方便,整倍数放缩;第二采用芯片级器件集成,它利用快速更迭的CMOS工艺,预计能降低80%的封装成本。而光电互相转换的终极目标是单片集成,目前业界也在为之进行探索和努力。
当实现了一个小型的光电引擎之后,它能够用在哪些领域呢?祁楠介绍到,主要是用在通过以太网的互联、智能网卡、以及高性能的计算领域。例如,微软对光互连进行了预算,惠普的服务器也在规划用光互连的交互来提高运行效率。
要实现芯片级的光互连,在发射端针对不同的传输距离则需要不同的驱动方案。当芯片与芯片板间或板上的传输距离小于100m的话,通常低成本的方案是采用激光器直驱DML方案。但当传输距离较远,超过100米甚至几公里的话,则要采用调制器间接驱动的方案。两种传输要求的接收端大体是一致的。而如果想
实现小尺寸、高密度的集成,则可能需要做Chiplet的光电互联引擎。
图源:中科院半导体研究所祁楠在CNCC 2021上的演讲
祁楠阐述道,新型的光电合封(CPO)需要高速率、低功耗和高集成度的光芯片和电芯片。在这其中,CMOS亲善的方案就变得很重要,表现为需要的电压摆幅要足够低,来适应深亚微米的需求,功耗和尺寸都不能太大。因此进行新型的硅光器件时,就需要协同设计的CMOS驱动、CMOS TIA,甚至是基于这些CMOS与Serdes进行片上集成的功能完整的芯片。祁楠的课题组从2015年就开始围绕着这些方向进行努力,从最初的25G单路一直发展到目前的112G单路,未来希望向单路200G推进,同时希望在超算领域能够不注重单速率,而是注重于并行速率和能耗效率,实现一个更高总带宽的、更低能耗的光电收发引擎。
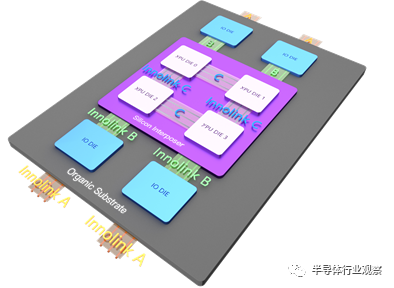
芯动科技技术总监高专介绍了公司为各种高性能计算场景而生的Innolink Chiplet IP技术。在介绍Chiplet IP之前,高专先阐述了下Chiplet的优势和必要性。从半导体产业角度来看,Chiplet是延续犘尔定理的必然选择。而对CPU/GPU等芯片厂商来说,Chiplet可以提高良率、降低成本、缩短开发周期和难度、突破die size上限。对于芯片系统集成商来说,不同芯片自由组合带来的开放繁荣。对于芯片制造商foundry来说,Chiplet可以实现不同工艺组合,吸引更多高端工艺的客户,还可发展die集成业务。
但是Chiplet也有些难点,很明显的一个问题是接口标准问题。在这方面,国外巨头实力雄厚,大都采用私有接口标准,要想制定私有标准则需要足够的销量,core die和lO die必须都能自主设计。
在CPU/GPU/高性能计算的细分领域,Chiplet的国产化标准是一个很有潜力的方向,国内CPU/GPU需要联合作战,构建自主的Chiplet技术。
统一CPU Chiplet标准,其带来的好处将是,不影响各CPU厂商的架构,不限制CPU性能,不影响CPU生态。中国急需自己的Chiplet技术。
高专接着分析了Chiplet接口的特点,他表示,与传统接口技术相比,传统芯片的管脚有限,而且每个管脚占用的die面积很大,所以提高每个管脚的速度非常重要,而Chiplet接口,IO面积小、密度高,更看重的是单位面积的带宽。
芯动科技一直在接口IP领域深耕,是连续11年市场领先的中国接口IP和芯片定制企业,具有丰富的FinFET量产经验。在Chiplet接口IP领域,芯动科技提供多版本的INNOLINK Chiplet接口IP可以为多种场景的Chiplet提供接口解决方案,包括INNOLINK A/B/C,并提供两种购买方式,一种是客户只买PHY,另一种是PHY+Controller。除此之外,芯动科技还提供定制IO芯片架构,能灵活搭配不同的CPU die,快速实现完整的core+IO的解决方案。目前芯动科技已有百万片晶圆授权,涵盖全球主流代工厂(台积电/三星/格芯/中芯国际/联华电子/英特尔等),能提供从55nm到5nm工艺全套高速IP核和ASIC定制解决方案全覆盖的Chiplet接口。
复旦大学陈迟晓发表了《多芯粒集成的存算一体电路与系统》的主题报告。他首先提出疑问,当下为什么很多AI计算体系结构中不可避免的出现了Chiplet架构?大的背景就是,人工智能的算法发展速度太快,AI芯片每3.4个月算力就提升一倍,这远远超过了摩尔定律的算力。功耗墙和存储墙的问题接踵而来,存算一体技术成为业界发力的一大方向,而Chiplet也成为必须要走的一条新的道路。
为什么单片的SoC不再适用?陈迟晓解释道,这主要是单芯片的制造面积趋于上限,而且先进节点设计面临低良率和高成本问题。传统的SoC设计也不支持异质集成,PCB版级互联有通信带宽瓶颈,难以支持超过10Gbps的通信带宽。于是基于存算一体的算法、电路、架构协同设计的新架构开始出现。
而现在不管国内外都在往Chiplet高性能计算方式和架构发展。2021年,较具代表性的有关Chiplet技术的企业动作有,英特尔的Ponte Veccho架构,AMD在今年提出了3D V-Cache Stacking架构,英伟达的Ampere GPU 架构,以及特斯拉Dojo晶圆级超算,寒武纪思元290。
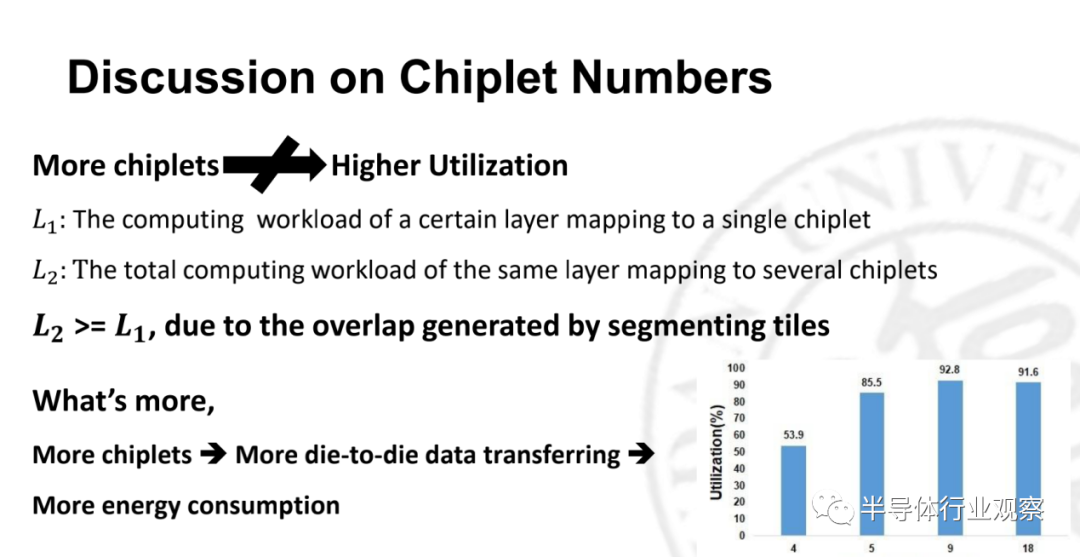
站在研究学者的角度来说,可能做不了如上述这些企业这么大的算力,但是在存算一体的发展趋势下,复旦大学陈迟晓的团队开始探索多芯粒的存算一体的研究。他介绍了团队是如何从软件的角度做高效率的映射。他们做出了一个很有意思的推导,是不是芯片越多,就能实现更高的能效,答案是否定的。虽然芯片的能效值确实是跟芯片的数量是有关的,但是当他们累加到18个芯片之前,并没有把效率真的提高,实际上,根据不同的任务场景需要映射不同的芯片数量,来达到性能的可扩展化。针对这些工作,陈迟晓团队做了更完整的芯片,论文研究将发布在2022年的ISSCC上。
-
Chiplet互联标准有没有意义?难点是什么?如何推进互联标准?
芯动科技技术总监高专表示,Chiplet互联标准有意义,有一个好的互联标准,多家的芯片进行互连,形成开放互连的局面。难点主要包括几方面,一是意义和动力,企业不想受制于人,希望内部进行垂直整合;二是场景,Chiplet的互联标准应该怎样去定义,如果定义不好,就没人用,要想定义的好,就需要考虑带宽、功耗等各个性能指标,需要充分了解各个场景的需求。要推进互联标准需要产业共同协作。
陈迟晓认为,Chiplet标准要制定很难,但没有标准,Chiplet就很难推进。如果未来是一个开放的生态,那么就需要一个Chiplet标准来协同,否则不管是从设计还是验证端,都没有办法克服一个系统中有10家公司的产品时该怎么办。
王启东的看法是,Chiplet很核心的一个应用是采用货架式的产品,由后面的应用方案对芯片进行搭建,如果没有相应的互联标准,应用方将很难推动Chiplet。这方面可以参考RISC-V。难点方面,如果集中到计算的角度来看,其具有垄断性,大企业很难把计算、存储、路由等开放出来,但Chiplet的互联不止这些,未来外涵将越来越大。
-
是否有能支持数十上百Chiplet集成方案?如何看待有源硅基板?
陈迟晓指出,上百可能没有,但英特尔的Ponte Veccho已经可以支持数十个芯片,对于无源硅基板来说,在没有量产之前的难点很多企业都能解决。有源硅基板不在于其能做不出来,核心在于,要做Chiplet,如何在有晶体管的芯片上做TSV是最大的问题。
王启东表示,目前从有源硅基板上来看,还存在比较大的问题,一方面是成本的问题,要在有源硅基板上做路由实际不需要太高的节点,而相对来说,有源硅基板的尺寸较大,很多硅上的面积会被闲置;另一方面,从尺寸来看,大概是26X33的水平,如果不对版图进行拼接的话,其尺寸还是相对较小的,单一的有源硅基板将难以支持大量的Chiplet。目前台积电正在做3-4倍 shot的硅基板,但是更多还是无源的互联线路的拼接。
高专补充道,如果是全互联的话,互联的通道会很多,走线复杂,如果不是全互联而只是附近的互联,理论上支持数百个是可以实现的。有源硅基板目前使用者少的要原因是成本,因为有源就要有晶体管,有晶体管的话,mask的层数就会多。一般无源硅基板底下的mask层数可以很少。再一个原因是,有源硅基板本身受尺寸的限制,大约是3个26X33的面积,在这样的面积下,走线的距离不是特别长,还不需要用有源来做中继和信号的加强。
-
Chiplet为体系架构带来什么变化?例如存储墙,光互联拓扑。
王启东指出,今年下半年AMD和台积电在做3D V-Cache,也就是以前在片上占据大量面积的SRAM,现在拿出来,在垂直方向上与逻辑单元进行互联。根据之前的评估,在延迟、带宽等方面基本是2个数量级的提升。所采用的技术主要是SoIC和SoIC+,这种芯片混合键合技术就可以把以前从不到1w(k)/平方毫米的互联提升到10w-100w/平方毫米的互联级别。对于连接带宽有巨量的提升,同时从互联长度上来讲,中间去掉了可能会造成高IC延迟的Bumping,在垂直互联上可以缩短到亚微米级别。从物理互联上来看,对存储墙的带宽和功耗等会有很大的提升。Chiplet跟工艺是密切相关的,通过一些最新工艺的引入,是可以缓解在系统上遇到的一些问题。
陈迟晓接着补充道,AMD的3D V-Cache从原理上证明当用Chiplet技术时,可以采用旧的节点和Chiplet先进的封装,可以达到更高节点的性能。ADM有一个Demo,两颗14nm的芯片实现了7nm的性能,也就是说,如果把SRAM放在下面大的SoC上时,下面的芯片面积会变得非常大,如果从二维变成三维,平面的面积变小,互联的面积可能从二维的200μm/300μm,变成50μm的距离。3D IC的好处是,多了一个芯片的设计维度。
Chiplet如今已收到广泛的业界关注,许多数据中心芯片都是小芯片技术的最佳选择,数据中心供应商也因为Chiplet而获益。在后摩尔时代下,Chiplet将大放异彩。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2896内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|集成电路|设备
|汽车芯片|存储|台积电|AI|封装
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!
责任编辑:Sophie