
AMD 要在CPU中引入3D堆叠ML加速器?
来源:内容来自【tom' shardware】 ,谢谢。
AMD 已为一种处理器申请了专利,该处理器具有堆叠在其 I/O 芯片 (IOD) 顶部的机器学习 (ML) 加速器。该专利表明,AMD 可能正计划构建具有集成FPGA 或基于GPU 的机器学习加速器的专用或数据中心系统级芯片 (SoC)。
就像AMD现在可以为其CPU添加缓存一样,它可能会在其处理器 I/O 芯片上添加 FPGA 或 GPU。但是,更重要的是,该技术允许该公司在未来的 CPU SoC 中添加其他类型的加速器。与任何专利作品一样,该专利并不能保证我们会看到采用该技术的设计进入市场。然而,它让我们了解了公司在研发方面的发展方向,我们有机会看到基于这种技术的产品或类似的衍生产品进入市场。
在 I/O 芯片上堆叠AI/ML加速器
这项名为“直接连接机器学习加速器”(Direct-connected machine learning accelerator)的专利公开地描述了AMD如何利用其堆叠技术,在其带有IOD的CPU上添加ML加速器。显然,AMD的技术允许它在带有特殊加速器端口的I/O芯片上添加现场可编程处理阵列(FPGA)或用于机器学习工作负载的计算GPU。
AMD 描述了添加加速器的几种方法:一种涉及具有自己本地内存的加速器,另一种暗示这种加速器使用连接到 IOD的内存,而在第三种情况下,加速器可能使用系统内存,在此在这种情况下,它甚至不必堆叠在 IOD 顶部。
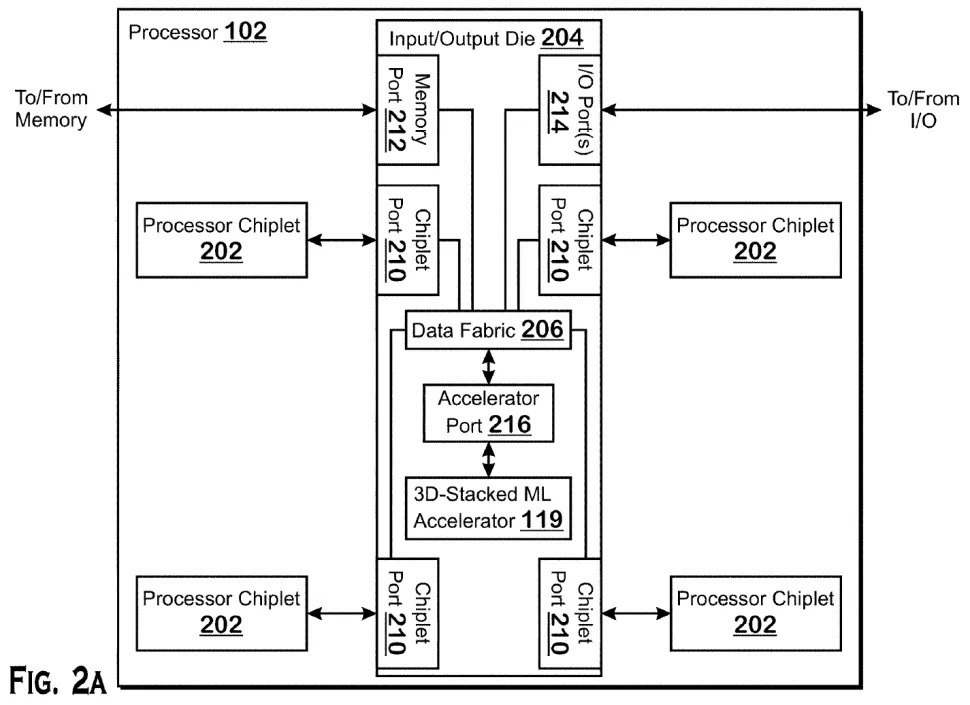
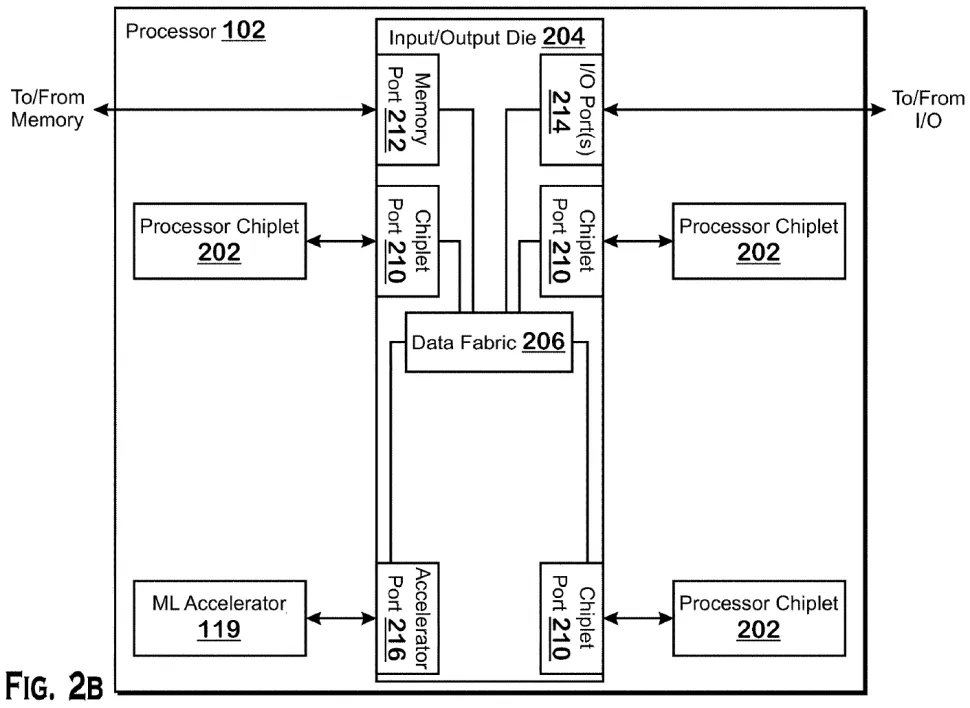
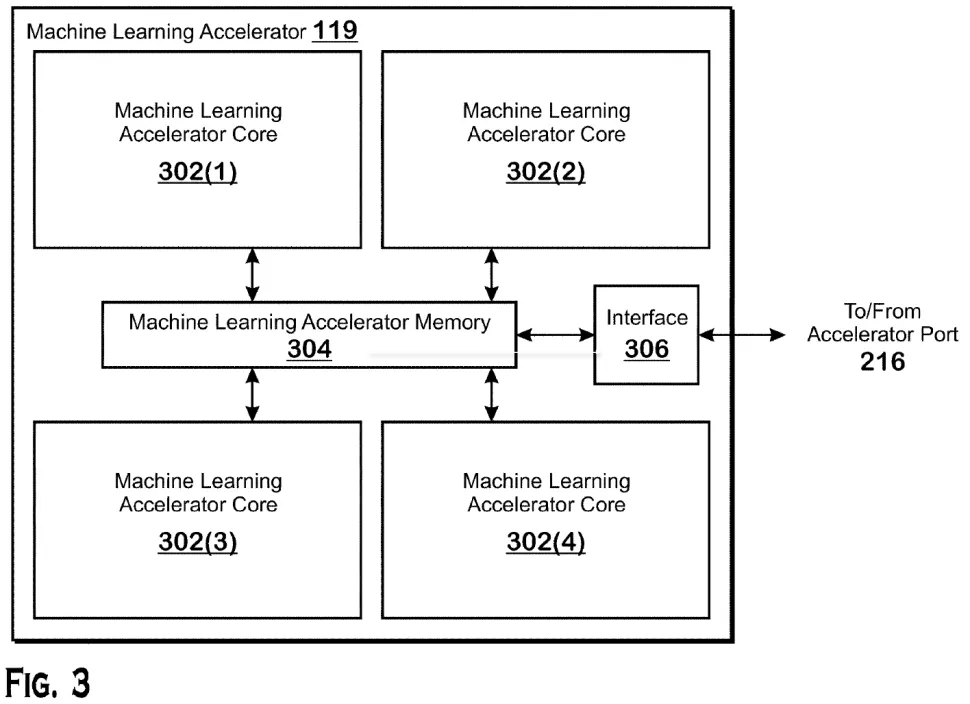
图源:AMD
机器学习技术将被未来的数据中心广泛使用。然而,为了更具竞争力,AMD 需要使用其芯片加速 ML 工作负载。在 CPU I/O 芯片上堆叠机器学习加速器可以显着加快 ML 工作负载,而无需将昂贵的定制 ML优化硅片集成到CPU小芯片中。它还具有密度、功率和数据吞吐量优势。
该专利于2020 年 9 月 25 日提交,比 AMD 和 Xilinx 宣布他们的管理团队已达成最终协议 AMD 将收购 Xilinx 早一个多月。该专利于2022年3月31日公布,AMD 研究员 Maxim V. Kazakov 被列为发明人。AMD 的首款采用 Xilinx IP 的产品预计将于 2023 年推出。
我们不知道 AMD 是否会将其专利用于实际产品,但将ML功能添加到几乎所有CPU这个想法看起来似乎是合理的。假设AMD的代号为EPYC的“Genoa”和“Bergamo”处理器使用带有加速器端口的 I/O 芯片,那么很可能会有带有ML加速器的Genoa-AI 和 Bergamo-AI CPU。
还值得注意的是,据传 AMD正在为其第 5 代 EPYC 'Turin' 处理器考虑 600W 可配置热设计功率 (cTDP),比当前一代 EPYC 7003 系列的 cTDP 高出两倍以上“Milan”处理器。此外,用于第 4 代和第 5 代 EPYC CPU 的 AMD 的 AMD SP5 平台可在极短的时间内为处理器提供高达 700W 的功率。
我们不知道 AMD 未来的 96 -128(Genoa和Bergamo)CPU 需要多少功率,但在处理器封装中添加 ML加速器肯定会增加消耗。为此,确保下一代服务器平台能够通过堆叠加速器支持cpu是很有意义的。
构建终极数据中心SoC
自2006年收购 ATI Technologies 以来,AMD 一直在谈论数据中心加速处理单元 (APU)。在过去 15 年中,我们听说过多个数据中心 APU 项目集成了用于典型工作负载的通用 x86 内核和用于高度并行的 Radeon GPU工作量。
这些项目都没有实现,原因有很多。在某种程度上,由于 AMD 的 Bulldozer 内核没有竞争力,因此构建一个需求非常有限的大型且昂贵的芯片没有多大意义。另一个原因是,传统的 Radeon GPU 并不支持数据中心/AI/ML/HPC 工作负载所需的所有数据格式和指令,而 AMD 的第一款以计算为中心的基于 CDNA 的 GPU 直到 2020 年才出现。
但是现在 AMD 拥有具有竞争力的 x86 微架构、面向计算的 GPU 架构、 Xilinx的 FPGA 产品组合以及Pensando的一系列可编程处理器,将这些不同的 IP 块放入单个大芯片中可能没有多大意义。恰恰相反,在TSMC和AMD自己的Infinity Fabric互连技术提供的封装技术下,用通用x86处理器芯片、I/O芯片以及基于GPU或fpga的加速器来构建多tile(或多Chiplet)模块更有意义。
事实上,构建多芯片数据中心处理器比构建具有内置多样化 IP 的大型单片 CPU 更有意义。例如,多块数据中心 APU 可以受益于使用 TSMC 的 N4X 性能优化节点制成的 CPU 块以及使用密度优化的 N3E工艺技术生产的 GPU 或 FPGA 加速器块。
通用加速器端口
该专利的另一个重要部分不是旨在使用 FPGA 或计算 GPU 加速机器学习工作负载的特定实现,而是在任何 CPU 中添加专用加速器的原理。加速器端口将是 AMD 的 I/O 芯片上的通用接口,因此最终,AMD 可以在其处理器中添加其他类型的加速器,以针对客户端或数据中心应用程序。
“应该理解的是,根据本专利的披露,可能会有很多变化,”专利的描述写道。例如,合适的处理器包括通用处理器、专用处理器、传统处理器、图形处理器、机器学习处理器、[DSP、ASIC、FPGA]和其他类型的集成电路(IC)。这样的处理器可以通过配置制造过程来制造,该制造过程使用已处理的硬件描述语言(HDL)指令的结果和其他中间数据,包括网表(这种指令能够存储在计算机可读的介质上)。”
尽管即使在今天,FPGA、GPU 和 DSP 仍可用于各种应用,但用于数据中心的数据处理单元 (DPU) 之类的东西只会在未来几年变得越来越重要。DPU 本质上是 AMD 现在碰巧拥有的新兴应用程序。但随着数据中心转变为处理更多类型的数据并更快(客户端 PC 也是如此,例如 Apple 如何将特定应用程序的加速(如 ProRes RAW)集成到其客户端 SoC 中),加速器变得越来越普遍。这意味着必须有一种方法可以将它们添加到任何或几乎任何服务器处理器。事实上,AMD 的加速器端口是一种相对简单的方法。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第3006内容,欢迎关注。
推荐阅读
半导体行业观察

『 半导体第一垂直媒体 』
实时 专业 原创 深度
识别二维码 ,回复下方关键词,阅读更多
晶圆|集成电路|设备 |汽车芯片|存储|台积电|AI|封装
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复 搜索 ,还能轻松找到其他你感兴趣的文章!
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号