芯行纪推出AmazeFP智能化布局规划解决方案
2022-08-24
10:44:00
来源: 芯行纪
点击
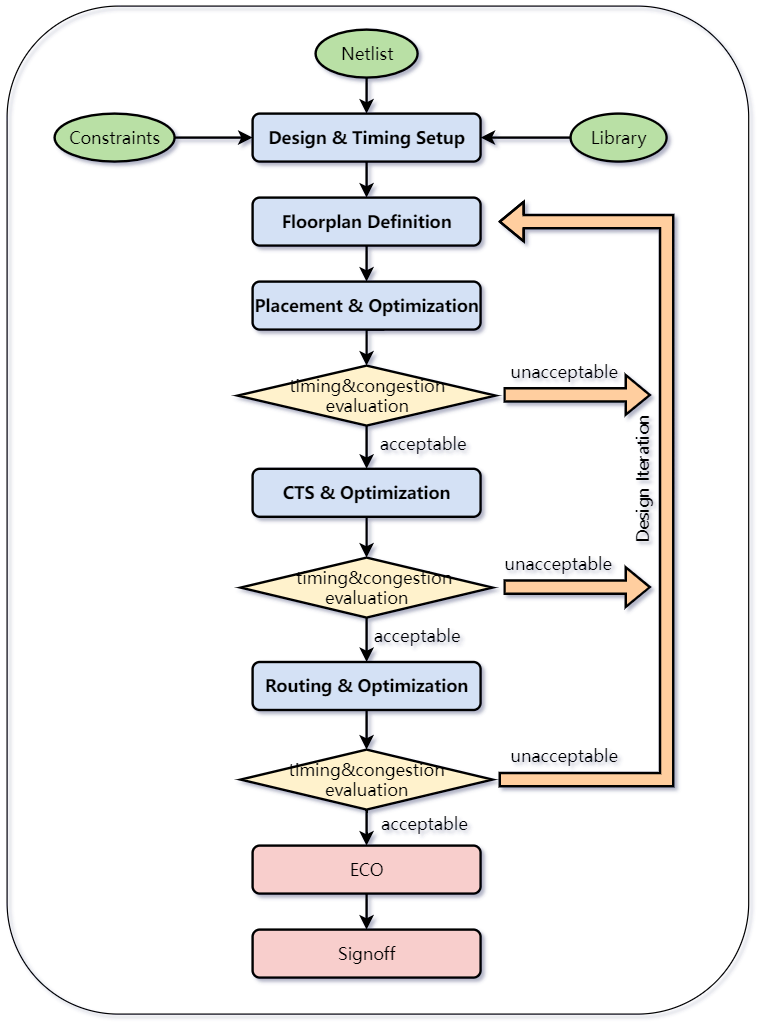
数字芯片后端设计流程中,布局规划的好坏直接影响整体设计的时序收敛以及布线质量,因此其过程需要经历反复迭代。随着先进工艺的不断发展,设计规模日趋庞大,后端设计的每个环节所需的时间也相应增长,有的单个环节需要花费数天甚至数周,这对于模块后端设计人员应对紧张的项目时间节点也提出了更大的考验,因此减少设计中的迭代次数就成为优化设计流程的关键。

图1 数字芯片后端布局布线流程
数字实现EDA先进解决方案供应商芯行纪科技有限公司(以下简称“芯行纪”)宣布推出的首款完全自主研发的数字实现EDA产品——AmazeFP智能布局规划工具,将机器学习技术应用于布局规划引擎,在兼顾性能、功耗和面积(PPA)的同时,提供了高度智能的拥塞感知、便捷的数据流分析和宏单元自动整理对齐功能,有效解决当前数字芯片在后端设计的布局规划节点面临的对经验依赖度高、手工耗时长、数据流分析手段单一、设计问题依赖后期定位导致的收敛性差等难题。
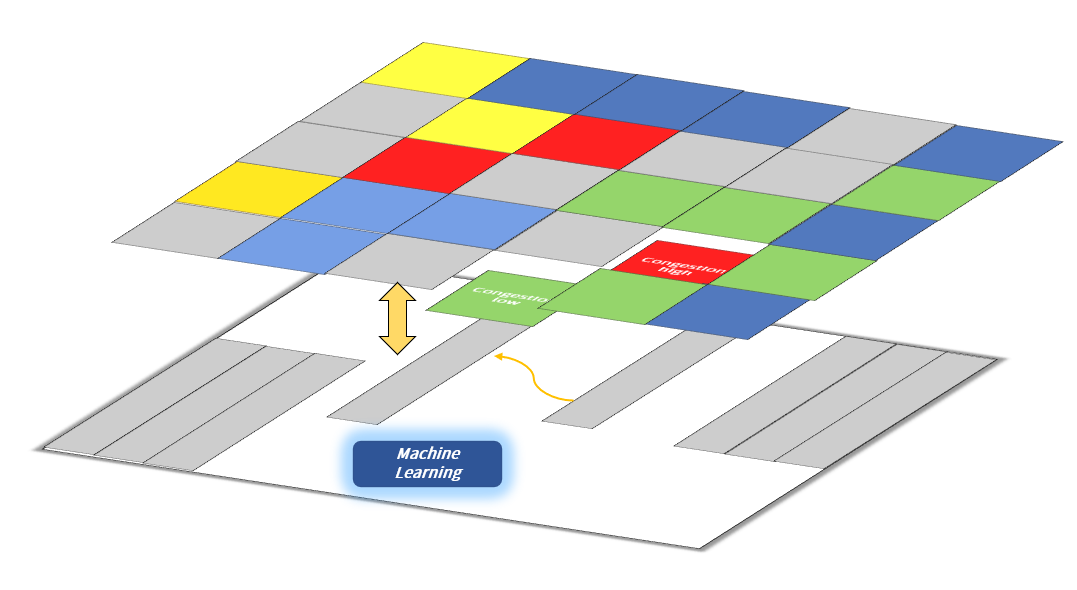
图2 融合机器学习和拥塞感知技术的布局规划引擎
AmazeFP采用的机器学习技术可快速获取高质量的宏单元布局思路,提供给用户初步布局规划;内置的数据流导向引擎,可智能规划宏单元摆放,加速宏单元关键路径的时序收敛;拥塞感知功能可准确预测拥塞度并调整宏单元位置,实现高效且有针对性的全局优化;宏单元自动整理对齐功能可以动态地根据所选的宏单元自动生成网格化窗口,极大地节省用户规整对齐宏单元的时间。
产品发布的同时,芯行纪也发起“AmazeFP优客计划”,用于听取广大集成电路设计企业对于软件功能的创意需求或者亟待解决的设计难点,在已有的自主研发的产品基础上进行快速定制化开发,将新功能及时呈现至后续的更新产品中。
本文将着重分享AmazeFP在应用中的具体表现,并详细介绍“AmazeFP优客计划”,鼓励开发者使用软件并随之共同创新,携手推动数字实现EDA的进步。
案例一: 在GPGPU设计模块中的测试情况
案例一为GPGPU设计模块,工作频率1GHz,包含宏单元246,布局规划如图3所示。其中,左图为设计人员耗时5天通过手工调整和迭代摆放出的宏单元布局,右图为AmazeFP用时不到2小时自动摆放的宏单元布局。
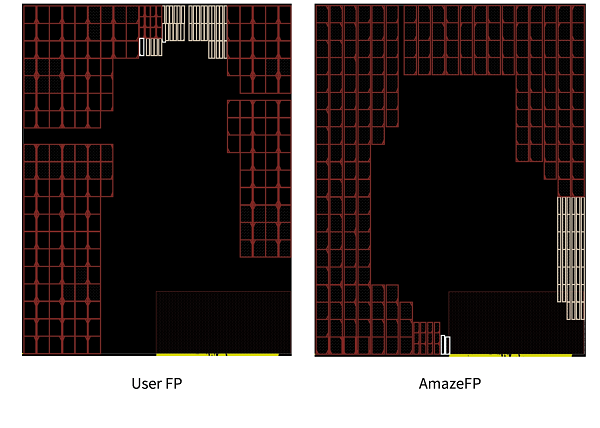
图3 GPGPU模块的宏单元布局对比
将图3中的两个布局规划结果应用于完全相同的布局布线流程,最终对比绕线之后的PPA质量,如图4所示。AmazeFP在时序、绕线以及功耗方面均取得了可观的进步。其中,对比设计人员的布局规划,AmazeFP的布局规划在时序方面,WNS(Worst Negative Slack,最差负时序裕量)由-266ps提升至-14ps, 提升了94.7%;TNS(Total Negative Slack,总负时序裕量)提升了99.93%;设计总绕线长度缩短12.6%;静态功耗降低18.3%。

图4 GPGPU用户和工具布局规划的PPA对比
对比两个不同的布局布线结果的模块分布,如图5所示。
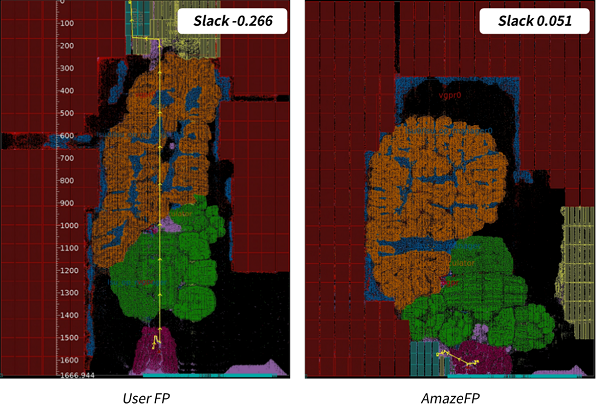
图5 GPGPU用户和工具布局规划的模块分布以及路径对比
相对于用户的布局规划,应用AmazeFP布局规划的模块分布更加紧凑,而用户布局规划的模块分布相对分散,对比其中标识橙色的模块分布对比尤为明显。具体分析时序最差的一条路径,分别在两个不同布局规划中对比,即图5中标识为黄色的路径。在用户的布局规划中,这条路径由寄存器连接到宏单元,起点寄存器在整个设计的最底端,而终点寄存器在设计的最顶端,整条路径长度超过1600um。而在AmazeFP布局规划中对比同一条路径,可以看到路径终点的宏单元被放置在设计的最底端,起点寄存器仍然在靠近设计端口的位置,同一条路径的长度大幅度缩短,时序也得到了明显的提升。
案例二:在视频编解码设计模块中的测试情况
案例二为视频编解码设计模块,工作频率为1.5GHz,包含宏单元44个,其布局规划如图6所示。
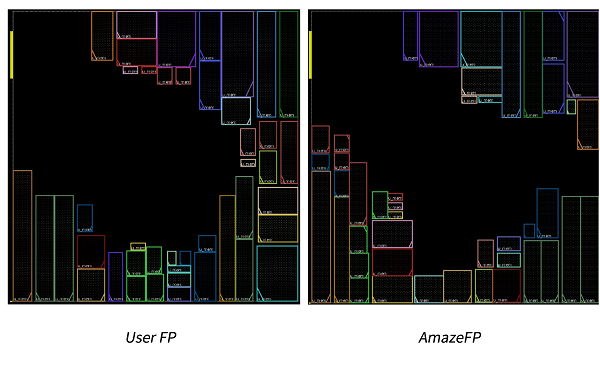
图6 视频编解码模块的宏单元布局对比
其中,左图为设计人员耗时3天通过手工调整和迭代摆放出的宏单元布局,右图为AmazeFP用时0.5小时得到的宏单元布局。将图6中的两个布局规划结果应用于完全相同的布局布线流程,最终对比绕线之后的PPA质量,如图7所示。
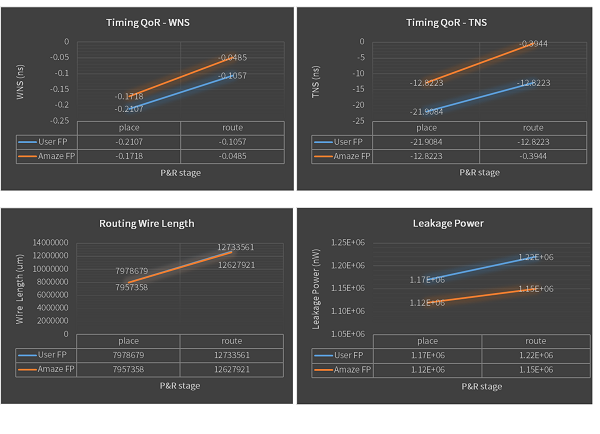
图7 视频编解码模块基于用户和工具布局规划的PPA对比
对比设计人员的布局规划结果,AmazeFP的布局规划在时序上实现了54.1%的WNS提升和86.0%的TNS提升;绕线长度也得到了一定改善;静态功耗降低了5.7%。
进一步对比两个布局规划的模块分布,如图8所示。可以看到,用户设计的布局规划结果中,模块的分布相对分散,受制于模块之间的交互关联,一些模块被分割成了多个部分,并且分布在相对较远的位置,如左图中的模块A,模块B和C都被分割成多个部分。而对比右图中相应的模块分布,可以看到同一模块被分割的现象并不明显,模块的分布较为集中,这将更有利于推进该设计的PPA优化。
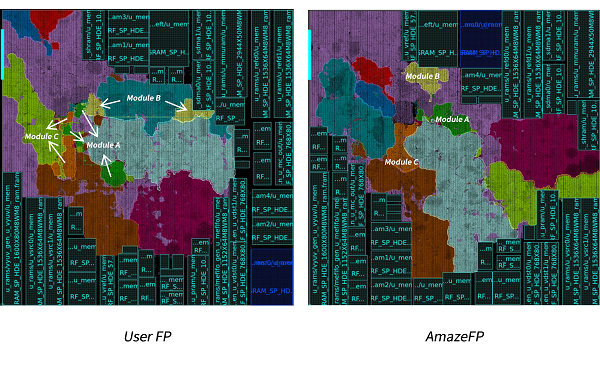
图8 视频编解码设计基于用户和工具布局规划的模块分布对比
具体分析两个布局规划的时序结果,按照路径分组(Path Group)进行分类对比,如表1 所示。其中对于寄存器到时钟门(Reg_to_ICG)的时序路径分组,AmazeFP的布局规划获得了57.77%的WNS收益,66.67%的TNS收益,以及47.22%的NVP(Number of Violating Path, 违例路径条数)提升;而对于寄存器到宏单元的时序路径(Reg_to_Mem)分组,AmazeFP的布局规划则获得了87.32%的WNS收益,94.74%的TNS收益,以及23.91%的NVP收益。
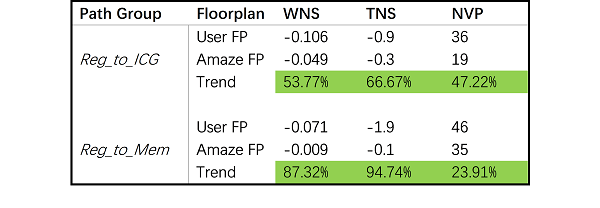
表1 视频编解码模块布局布线后的时序对比
图9中左图高亮出了用户布局规划中最差的一条Reg_to_ICG时序路径,其中红色五星标识了该路径的终点,即时钟门逻辑(ICG)的位置,黄色圆点标识了该时钟门逻辑的扇出(Fan-out)寄存器的分布,橘色圆点标识了该时钟门逻辑的扇入(Fan-in)寄存器的分布。右图则对应高亮出了同一个时钟门逻辑的位置以及其Fan-out和Fan-in的寄存器分布。对比图9的左右两幅图,可以看出在AmazeFP的布局规划中,ICG上一级寄存器分布范围相对左图更为集中,Reg_to_ICG的整体路径相对更短,路径时序也得到了更好的优化结果,WNS由-107ps提升至-33ps。
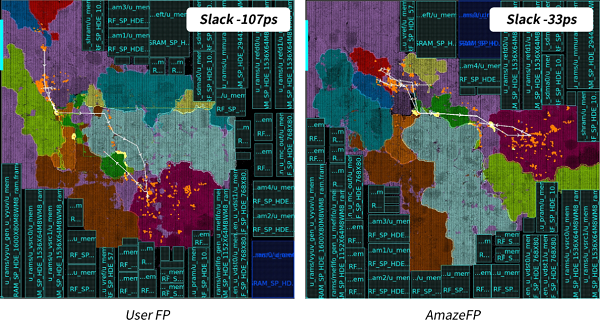
图9 视频编解码模块的Reg_to_ICG路径对比
对于寄存器到宏单元的时序路径(Reg_to_Mem),AmazeFP的布局规划结果也表现优异。对比用户布局规划中最差的一条Reg_to_Mem路径,以及AmazeFP的布局规划中到同一个宏单元的路径,如图10所示。用户布局规划中,该宏单元放置在整个设计的右下角,其上一级寄存器则位于距离较远的绿色模块(模块A)的位置。而对比右图AmazeFP的布局规划结果,该宏单元被工具放置在设计的顶端,而模块A也分布在距离路径终点的宏单元不远的位置,因此Reg_to_Mem的路径相对更短,时序优化结果更佳,WNS由-71ps提升至0ps。
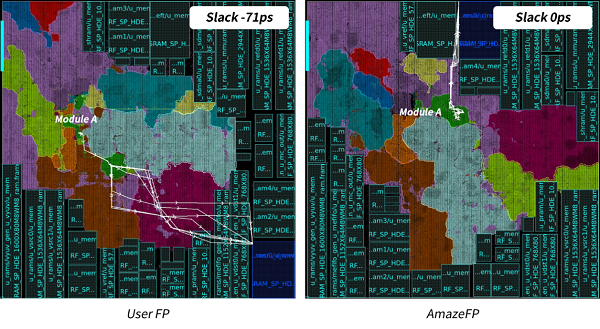
图10 视频编解码模块的Reg_to_Mem路径对比
AmazeFP的数据流导向引擎以及高度智能的拥塞感知能力能够在兼顾性能、功耗、面积(PPA)的同时实现更为合理的宏单元布局,给后续环节提供了良好的开端,也助力设计在整体布局布线流程中得到更优的结果,最大限度地减少了整个布局布线流程的迭代次数,助力设计更快收敛,加速高质量的流片。
AmazeFP优客计划
当芯片的先进工艺制程不断进步,晶体管结构变得日益复杂,电路设计需要考虑的实现难点越来越多,EDA工具也因此迎来新的挑战,基于开发者的更先进需求,在原有的工具基础上保持不断更新,才能帮助开发者更加高效地实现芯片量产。
数字实现EDA工具是非常复杂的软件,需要综合考虑工艺、电路、算法、人工智能等技术,数字实现EDA领域的研发人员尤其匮乏,使得本土集成电路设计企业的难点解决需求很难在第一时间得到响应。芯行纪拥有一支强大的研发团队,在一年多的时间里完成了从第一行代码的编写到百万行代码的实现,从底层架构就开始考虑将机器学习、云计算技术如何适配到数据结构,芯行纪启动的“AmazeFP优客计划”,正是基于这样的研发实力,最主要的设想就是零距离贴近本土市场,聆听广大集成电路企业与时俱进的创意需求或者亟待解决的设计难点,在已有的自主研发的产品基础上进行快速定制化开发,将新功能及时呈现至后续的更新产品中。
合作伙伴可访问芯行纪官方网站(www.xtimes-da.com),在AmazeFP产品页面中提交创意或者难点解决需求,芯行纪会安排专业的筛选和及时的沟通,还将为最后成功入选确定需求的参与者提供丰厚的礼品。
关于芯行纪
芯行纪科技有限公司汇聚全球杰出EDA技术支持和研发精英,着力于自主研发符合3S理念(Smart、Speedy、Simple)的数字实现EDA平台,包含新一代布局布线技术,同时提供高端数字芯片设计解决方案,可大幅度提升芯片设计效率,并助力实现芯片一次性快速量产,在人工智能、智能汽车、5G、云计算等集成电路领域为众多合作伙伴的高速发展和产业腾飞保驾护航。
图1 数字芯片后端布局布线流程
数字实现EDA先进解决方案供应商芯行纪科技有限公司(以下简称“芯行纪”)宣布推出的首款完全自主研发的数字实现EDA产品——AmazeFP智能布局规划工具,将机器学习技术应用于布局规划引擎,在兼顾性能、功耗和面积(PPA)的同时,提供了高度智能的拥塞感知、便捷的数据流分析和宏单元自动整理对齐功能,有效解决当前数字芯片在后端设计的布局规划节点面临的对经验依赖度高、手工耗时长、数据流分析手段单一、设计问题依赖后期定位导致的收敛性差等难题。
图2 融合机器学习和拥塞感知技术的布局规划引擎
AmazeFP采用的机器学习技术可快速获取高质量的宏单元布局思路,提供给用户初步布局规划;内置的数据流导向引擎,可智能规划宏单元摆放,加速宏单元关键路径的时序收敛;拥塞感知功能可准确预测拥塞度并调整宏单元位置,实现高效且有针对性的全局优化;宏单元自动整理对齐功能可以动态地根据所选的宏单元自动生成网格化窗口,极大地节省用户规整对齐宏单元的时间。
产品发布的同时,芯行纪也发起“AmazeFP优客计划”,用于听取广大集成电路设计企业对于软件功能的创意需求或者亟待解决的设计难点,在已有的自主研发的产品基础上进行快速定制化开发,将新功能及时呈现至后续的更新产品中。
本文将着重分享AmazeFP在应用中的具体表现,并详细介绍“AmazeFP优客计划”,鼓励开发者使用软件并随之共同创新,携手推动数字实现EDA的进步。
案例一: 在GPGPU设计模块中的测试情况
案例一为GPGPU设计模块,工作频率1GHz,包含宏单元246,布局规划如图3所示。其中,左图为设计人员耗时5天通过手工调整和迭代摆放出的宏单元布局,右图为AmazeFP用时不到2小时自动摆放的宏单元布局。
图3 GPGPU模块的宏单元布局对比
将图3中的两个布局规划结果应用于完全相同的布局布线流程,最终对比绕线之后的PPA质量,如图4所示。AmazeFP在时序、绕线以及功耗方面均取得了可观的进步。其中,对比设计人员的布局规划,AmazeFP的布局规划在时序方面,WNS(Worst Negative Slack,最差负时序裕量)由-266ps提升至-14ps, 提升了94.7%;TNS(Total Negative Slack,总负时序裕量)提升了99.93%;设计总绕线长度缩短12.6%;静态功耗降低18.3%。
图4 GPGPU用户和工具布局规划的PPA对比
对比两个不同的布局布线结果的模块分布,如图5所示。
图5 GPGPU用户和工具布局规划的模块分布以及路径对比
相对于用户的布局规划,应用AmazeFP布局规划的模块分布更加紧凑,而用户布局规划的模块分布相对分散,对比其中标识橙色的模块分布对比尤为明显。具体分析时序最差的一条路径,分别在两个不同布局规划中对比,即图5中标识为黄色的路径。在用户的布局规划中,这条路径由寄存器连接到宏单元,起点寄存器在整个设计的最底端,而终点寄存器在设计的最顶端,整条路径长度超过1600um。而在AmazeFP布局规划中对比同一条路径,可以看到路径终点的宏单元被放置在设计的最底端,起点寄存器仍然在靠近设计端口的位置,同一条路径的长度大幅度缩短,时序也得到了明显的提升。
案例二:在视频编解码设计模块中的测试情况
案例二为视频编解码设计模块,工作频率为1.5GHz,包含宏单元44个,其布局规划如图6所示。
图6 视频编解码模块的宏单元布局对比
其中,左图为设计人员耗时3天通过手工调整和迭代摆放出的宏单元布局,右图为AmazeFP用时0.5小时得到的宏单元布局。将图6中的两个布局规划结果应用于完全相同的布局布线流程,最终对比绕线之后的PPA质量,如图7所示。
图7 视频编解码模块基于用户和工具布局规划的PPA对比
对比设计人员的布局规划结果,AmazeFP的布局规划在时序上实现了54.1%的WNS提升和86.0%的TNS提升;绕线长度也得到了一定改善;静态功耗降低了5.7%。
进一步对比两个布局规划的模块分布,如图8所示。可以看到,用户设计的布局规划结果中,模块的分布相对分散,受制于模块之间的交互关联,一些模块被分割成了多个部分,并且分布在相对较远的位置,如左图中的模块A,模块B和C都被分割成多个部分。而对比右图中相应的模块分布,可以看到同一模块被分割的现象并不明显,模块的分布较为集中,这将更有利于推进该设计的PPA优化。
图8 视频编解码设计基于用户和工具布局规划的模块分布对比
具体分析两个布局规划的时序结果,按照路径分组(Path Group)进行分类对比,如表1 所示。其中对于寄存器到时钟门(Reg_to_ICG)的时序路径分组,AmazeFP的布局规划获得了57.77%的WNS收益,66.67%的TNS收益,以及47.22%的NVP(Number of Violating Path, 违例路径条数)提升;而对于寄存器到宏单元的时序路径(Reg_to_Mem)分组,AmazeFP的布局规划则获得了87.32%的WNS收益,94.74%的TNS收益,以及23.91%的NVP收益。
表1 视频编解码模块布局布线后的时序对比
图9中左图高亮出了用户布局规划中最差的一条Reg_to_ICG时序路径,其中红色五星标识了该路径的终点,即时钟门逻辑(ICG)的位置,黄色圆点标识了该时钟门逻辑的扇出(Fan-out)寄存器的分布,橘色圆点标识了该时钟门逻辑的扇入(Fan-in)寄存器的分布。右图则对应高亮出了同一个时钟门逻辑的位置以及其Fan-out和Fan-in的寄存器分布。对比图9的左右两幅图,可以看出在AmazeFP的布局规划中,ICG上一级寄存器分布范围相对左图更为集中,Reg_to_ICG的整体路径相对更短,路径时序也得到了更好的优化结果,WNS由-107ps提升至-33ps。
图9 视频编解码模块的Reg_to_ICG路径对比
对于寄存器到宏单元的时序路径(Reg_to_Mem),AmazeFP的布局规划结果也表现优异。对比用户布局规划中最差的一条Reg_to_Mem路径,以及AmazeFP的布局规划中到同一个宏单元的路径,如图10所示。用户布局规划中,该宏单元放置在整个设计的右下角,其上一级寄存器则位于距离较远的绿色模块(模块A)的位置。而对比右图AmazeFP的布局规划结果,该宏单元被工具放置在设计的顶端,而模块A也分布在距离路径终点的宏单元不远的位置,因此Reg_to_Mem的路径相对更短,时序优化结果更佳,WNS由-71ps提升至0ps。
图10 视频编解码模块的Reg_to_Mem路径对比
AmazeFP的数据流导向引擎以及高度智能的拥塞感知能力能够在兼顾性能、功耗、面积(PPA)的同时实现更为合理的宏单元布局,给后续环节提供了良好的开端,也助力设计在整体布局布线流程中得到更优的结果,最大限度地减少了整个布局布线流程的迭代次数,助力设计更快收敛,加速高质量的流片。
AmazeFP优客计划
当芯片的先进工艺制程不断进步,晶体管结构变得日益复杂,电路设计需要考虑的实现难点越来越多,EDA工具也因此迎来新的挑战,基于开发者的更先进需求,在原有的工具基础上保持不断更新,才能帮助开发者更加高效地实现芯片量产。
数字实现EDA工具是非常复杂的软件,需要综合考虑工艺、电路、算法、人工智能等技术,数字实现EDA领域的研发人员尤其匮乏,使得本土集成电路设计企业的难点解决需求很难在第一时间得到响应。芯行纪拥有一支强大的研发团队,在一年多的时间里完成了从第一行代码的编写到百万行代码的实现,从底层架构就开始考虑将机器学习、云计算技术如何适配到数据结构,芯行纪启动的“AmazeFP优客计划”,正是基于这样的研发实力,最主要的设想就是零距离贴近本土市场,聆听广大集成电路企业与时俱进的创意需求或者亟待解决的设计难点,在已有的自主研发的产品基础上进行快速定制化开发,将新功能及时呈现至后续的更新产品中。
合作伙伴可访问芯行纪官方网站(www.xtimes-da.com),在AmazeFP产品页面中提交创意或者难点解决需求,芯行纪会安排专业的筛选和及时的沟通,还将为最后成功入选确定需求的参与者提供丰厚的礼品。
关于芯行纪
芯行纪科技有限公司汇聚全球杰出EDA技术支持和研发精英,着力于自主研发符合3S理念(Smart、Speedy、Simple)的数字实现EDA平台,包含新一代布局布线技术,同时提供高端数字芯片设计解决方案,可大幅度提升芯片设计效率,并助力实现芯片一次性快速量产,在人工智能、智能汽车、5G、云计算等集成电路领域为众多合作伙伴的高速发展和产业腾飞保驾护航。
责任编辑:sophie

-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 国内首颗,精准纠错!德明利TWSC2985系列:支持4K LDPC技术的存储芯片
- 2 英特尔重磅发布OPS 2.0,智能教育时代加速到来
- 3 破除AI落地难题!英特尔全新软硬件平台,助力企业AI创新
- 4 MediaTek天玑汽车平台推动汽车产业加速迈入AI时代,3nm旗舰座舱平台亮相
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号