
三路出击,英伟达打造云原生超级计算架构
2021-12-21
09:01:53
来源: 互联网
点击
现在的数据和计算量正在爆发性增长,传统上,如果需要小算力的业务时可以找到云服务商来提供算力服务,而当需要较大的算力资源时,就需要找到超算中心。但是,用户对算力资源的需求波动性非常大,并不是一直需要大算力,所以就需要更灵活的架构,对此,英伟达认为,云原生超级计算架构则是不二之选。
通过云原生超算技术把超级计算技术带入千家万户的数据中心中,让数据中心拥有了超算技术的高性能,同时也把云数据中心中云的灵活性和安全性带进了超算平台,所以,云原生将会是未来提供算力平台的发展趋势。
云原生需要会计算的网络:Quantum-2
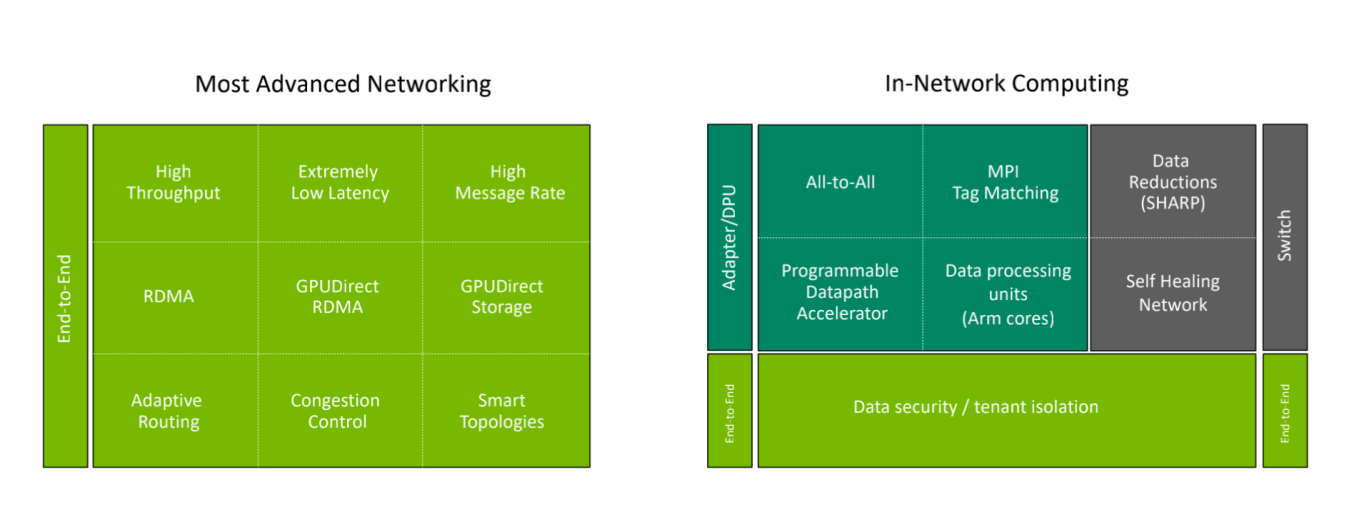
面向云原生超级计算,英伟达推出了融计算与通信于一体的Quantum-2平台。Quantum-2平台主要集合了三个产品,一是Quantum-2交换机;二是基于CONNECTX-7的InfiniBand网卡;三是基于BlueField-3的InfiniBand DPU。基于这三个Quantum-2设备,英伟达可以提供云原生上需要的五个关键功能:多租户、可以实现性能隔离、实现拥塞控制、SHARP第三代网络计算技术,以及能实现高精度计时。

英伟达使用InfiniBand网络把云原生的设备高效的连接起来,InfiniBand网络也是目前看到最贴切、最合适的网络,主要原因包括四大方面,一是InfiniBand是会计算的网络,在网卡、DPU和交换机上都能进行计算;二是它可以很容易的扩展到非常大规模,扩展到几万、几十万、上百万的节点,拓扑灵活,InfiniBand是无死锁、无网络风暴的网络,同时其动态路由可以让网络的利用效率变得非常高;三是在InfiniBand网络中可以由软件来定义规则,在执行规则时由硬件来实现,InfiniBand网络是即插即用网络;四是它可以向前向后兼容IBTA标准规范。
超级计算需要会计算的网络,网络成为计算的重要部分。Quantum-2平台真正契合了超级计算和云原生对网络的需求。Quantum-2平台的目标是实现数据在哪里,计算就在那里。
在先进网络技术中,GPU Driect RDMA、GPU Driect Storage等都是至关重要的技术。在通信模型计算中,MPI Tag Matching能对点对点通信的性能大幅度优化,在MPI业务中或者在AI业务中会用到的All-to-All通信,英伟达在InfiniBand网络中特意添加了All-to-All offload Engine,大幅提升All-to-All通信时的通信效率。在Quantum-2 平台里英伟达还专门增加了PDA (Programmable Datapath Accelerator),通过PDA可以对特定流量做编程和加速。
除了这些,英伟达还对更新的技术应用场景做了布局,如Quantum InfiniBand动态路由技术。这是一个由软件定义,硬件实现的技术。动态路由技术,即流量在网络中走的时候,可以根据网络拥塞的状况,自动选择一个最不拥塞、更畅通的道路,将数据由发送端送到接收端,通过动态路由技术可以让通信效率达到96%以上。在VASP和BSMBench两大业务场景中,动态路由都带来了非常好的性能提升。
英伟达网络事业部的宋庆春指出,但动态路由的价值远不止此,它更好的价值在于,与InfiniBand拥塞控制技术联合使用。在面向多租户的超算云中,其面临的挑战是资源共享性导致了性能的下降,而动态路由+InfiniBand拥塞控制技术可以让这个业务在云的情况下和在原来HPC环境、Bare-metal环境下性能完全一致。英伟达基于Telemetry的拥塞控制技术实现了性能隔离。
在微软的AZURE公有云上的测试结果也显示,InfiniBand动态路由+拥塞控制技术,实现了云上对于性能的保障,同时,在不同的业务之间进行了隔离,业务之间不会互相影响。
3U一体已成为数据中心的必然的架构
BlueField DPU的出现为3U一体奠定了基础,基于DPU 实现了新的云原生计算架构,把传统的所有基础设施上的操作都放到了BlueField DPU上,由DPU执行通信框架、存储框架、安全框架和业务隔离,让Host里面的CPU和GPU资源都释放给应用。

除此之外,英伟达还提出了对业务性能做优化的思路,那就是把通信和计算重叠起来,这样的话可以通过DPU来加速HPC业务中的通信,由DPU来运行通信框架,由CPU和GPU执行真正的浮点计算。
具体看,可以让DPU直接对HOST的内存进行操作,比如要进行RDMA的读写操作时,可以由DPU直接对HOST Memory发起RDMA的读写操作,在HOST CPU不感知的情况下就可以把数据读走或者把数据写到HOST CPU的内存里来,通过这样的方式实现了通信和计算的重叠,同时DPU再配合通信框架可以智能识别通信时Messenger Size的大小,根据Messages Size大小选择不同的优化方式,比如如果传的是小包,它就会自动选择针对小包的通信优化方式,如果传的是大包就会选择专门针对大包的通信优化方式。

英伟达网络事业部的宋庆春介绍到,在实现了计算和通信的重叠之后,就可以从业务角度看一下它带来的性能提升。比如在HPC应用、AI做推荐时的经常会用到的通信模型Alltoall上,通过用DPU和CPU实现计算通信重叠,让iAlltoall性能得到44%的提升;Allgather是在做大规模模型并行训练时用到的一个通信模型,通过DPU和CPU计算通信的Overlap,可以让Allgather的性能提升36%。

云原生软件DOCA 1.2定义安全
现在网络安全已经成为数据安全的最大的威胁,现在面临着数据量越来越大,数据传输速度越来越快,各种异构数据频繁出现,非结构化的数据量远远大于结构化的数据,所以在处理非结构化数据时复杂程度会远远大于处理结构化数据的复杂程度。需要做很多跨平台的整合,各种模型迭代、计算迭代、平台迭代越来越快。所以在这样一个大环境下,使用传统的思维方式或者工具已经没有办法满足现在数据中心的安全需求了,在现代数据中心里要发现一个数据中心中的漏洞,大概需要超过半年的时间,而要修复这个漏洞需要超过两个多月的时间。这对于现在基于零信任(Zero-trust)的前提下是绝对不可接受的。因为现在零信任(Zero-trust)的前提就是对数据中心中的任何人、任何事、任何设备都不信任,如果要是发现问题需要200天,修复问题需要70天,整个数据中心将非常不安全。
那么如何解决这个问题?在今年秋季GTC上,NVIDIA发布了 DOCA 1.2。DOCA 1.2正是专门面向零信任(Zero-trust)的安全框架,在其中包括了很多和安全相关的软件。DOCA 1.0、DOCA 1.1、DOCA 1.2每个版本发布时都会有其针对性的市场,DOCA 1.2主要是面向安全。

在DOCA1.2中提供了Load Balancers、DPI、 IPS、IDS、下一代防火墙,如果是设计安全软件的用户或者安全软件的供应商,可以直接通过DOCA API调用在DPU里的硬件加速引擎,让数据中心更安全。
在GTC上,黄仁勋专门针对Morpheus安全框架做了介绍。Morpheus是NVIDIA在基于DPU+DOCA安全数据中心平台里采用AI深度学习技术来进行安全防御的一个框架,它对于未来的数据中心提供了一个更新的思路,就是通过Morpheus可以利用AI的方式,去进行安全防御,通过AI的方式来对数据中心里的人、人的行为、数据中心中的设备、数据中心里的流量和其他的一些特征进行提取、训练和推理,生成各种模型,对网络进行更全面、宽度更广的安全的监督和监控。
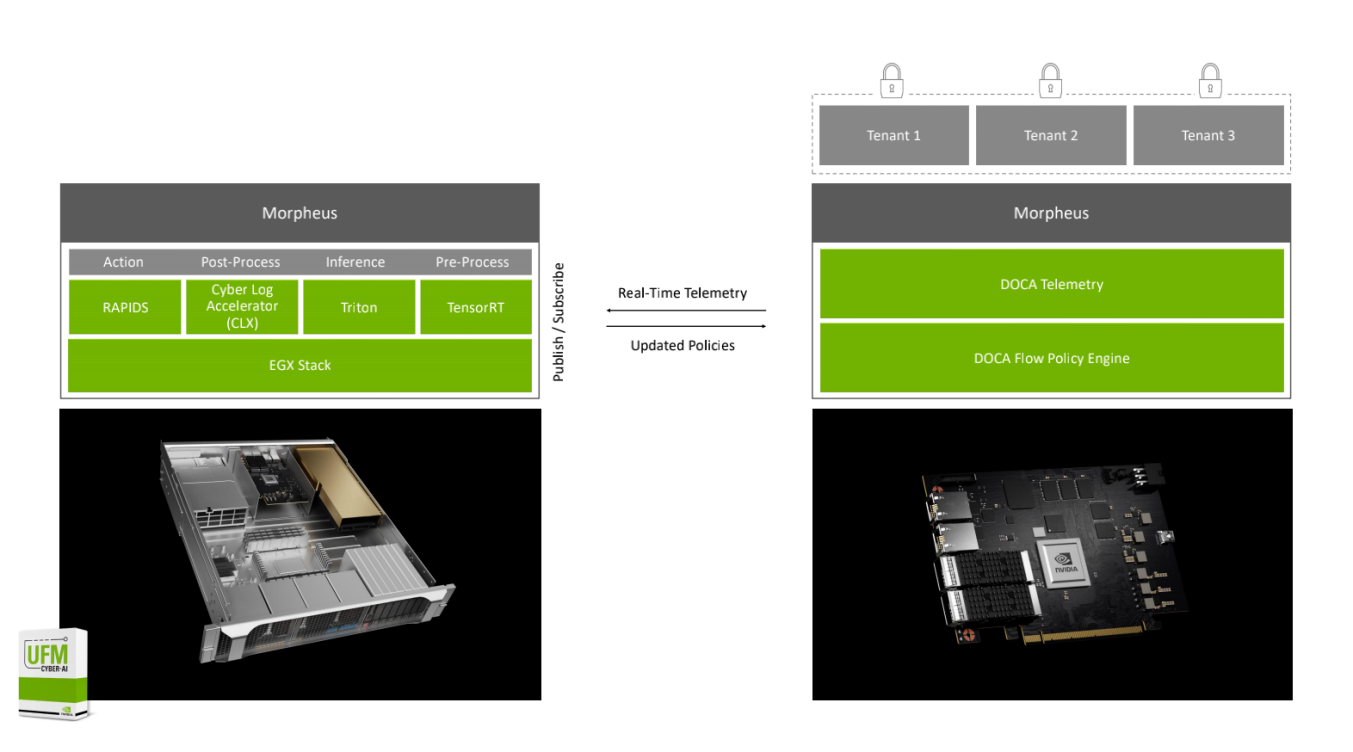
Morpheus AI网络安全框架
NVIDIA Morpheus给了用户一个完全的零监督、自学习的框架,而且通过Morpheus、采用AI技术对于安全的保障,可以实现600倍快的数据处理的速度,可以通过Morpheus根据刚才通过DPU抓到的各种特征来生成超过百万甚至超过千万级别的模型,然后在数据中心里面去进行匹配,实现对于数据中心的异常情况的侦测,只要是异常行为这时候就会去监控和识别。
结语
英伟达网络事业部的宋庆春最后总结到,数据中心对算力的需求变得越来越大,要运行大的模型需要很多的GPU,数据并行和模型并行在未来工作训练中同时使用将成为一个趋势。在这种大规模使用场景下面,如何既保持很高的算力,就能够在多租户情况下保证训练性能,保证业务的安全性,云原生技术是必不可少的。
从推理的角度看,很多人说做推理并不需要很高的算力,其实不对,因为随着现在AI模型越来越大,当我们做推理的时候,一个GPU、甚至是一个服务器中多个GPU也没有办法放下我要做推理的整个模型,这时候就需要跨服务器、跨Node做推理。在GTC上发布的数据显示,当用两个DGX A100做推理时,它的时间可以达到1/2秒。如果这样一个推理工作要放在两个CPU的服务器上来做,时间将超过1分钟。为了让推理效率更高,推理走向分布式也慢慢出现了,推理也需要更高算力和更高的通信能力。
DPU的出现弥补了在数据中心中对于基础设施加速能力的不足,实现了DPU、GPU、CPU 3U一体新型数据中心架构,让数据中心成为了新的计算单元,还给了我们一个优化算力资源的新的思路。所以,3U一体已经成为数据中心的一个必然的架构,而且,在这样一个必然的架构中通过DPU、CPU和GPU的分工合作可以实现数据中心中最优的性能。
通过云原生超算技术把超级计算技术带入千家万户的数据中心中,让数据中心拥有了超算技术的高性能,同时也把云数据中心中云的灵活性和安全性带进了超算平台,所以,云原生将会是未来提供算力平台的发展趋势。
云原生需要会计算的网络:Quantum-2
面向云原生超级计算,英伟达推出了融计算与通信于一体的Quantum-2平台。Quantum-2平台主要集合了三个产品,一是Quantum-2交换机;二是基于CONNECTX-7的InfiniBand网卡;三是基于BlueField-3的InfiniBand DPU。基于这三个Quantum-2设备,英伟达可以提供云原生上需要的五个关键功能:多租户、可以实现性能隔离、实现拥塞控制、SHARP第三代网络计算技术,以及能实现高精度计时。
英伟达使用InfiniBand网络把云原生的设备高效的连接起来,InfiniBand网络也是目前看到最贴切、最合适的网络,主要原因包括四大方面,一是InfiniBand是会计算的网络,在网卡、DPU和交换机上都能进行计算;二是它可以很容易的扩展到非常大规模,扩展到几万、几十万、上百万的节点,拓扑灵活,InfiniBand是无死锁、无网络风暴的网络,同时其动态路由可以让网络的利用效率变得非常高;三是在InfiniBand网络中可以由软件来定义规则,在执行规则时由硬件来实现,InfiniBand网络是即插即用网络;四是它可以向前向后兼容IBTA标准规范。
超级计算需要会计算的网络,网络成为计算的重要部分。Quantum-2平台真正契合了超级计算和云原生对网络的需求。Quantum-2平台的目标是实现数据在哪里,计算就在那里。
在先进网络技术中,GPU Driect RDMA、GPU Driect Storage等都是至关重要的技术。在通信模型计算中,MPI Tag Matching能对点对点通信的性能大幅度优化,在MPI业务中或者在AI业务中会用到的All-to-All通信,英伟达在InfiniBand网络中特意添加了All-to-All offload Engine,大幅提升All-to-All通信时的通信效率。在Quantum-2 平台里英伟达还专门增加了PDA (Programmable Datapath Accelerator),通过PDA可以对特定流量做编程和加速。
除了这些,英伟达还对更新的技术应用场景做了布局,如Quantum InfiniBand动态路由技术。这是一个由软件定义,硬件实现的技术。动态路由技术,即流量在网络中走的时候,可以根据网络拥塞的状况,自动选择一个最不拥塞、更畅通的道路,将数据由发送端送到接收端,通过动态路由技术可以让通信效率达到96%以上。在VASP和BSMBench两大业务场景中,动态路由都带来了非常好的性能提升。
英伟达网络事业部的宋庆春指出,但动态路由的价值远不止此,它更好的价值在于,与InfiniBand拥塞控制技术联合使用。在面向多租户的超算云中,其面临的挑战是资源共享性导致了性能的下降,而动态路由+InfiniBand拥塞控制技术可以让这个业务在云的情况下和在原来HPC环境、Bare-metal环境下性能完全一致。英伟达基于Telemetry的拥塞控制技术实现了性能隔离。
在微软的AZURE公有云上的测试结果也显示,InfiniBand动态路由+拥塞控制技术,实现了云上对于性能的保障,同时,在不同的业务之间进行了隔离,业务之间不会互相影响。
3U一体已成为数据中心的必然的架构
BlueField DPU的出现为3U一体奠定了基础,基于DPU 实现了新的云原生计算架构,把传统的所有基础设施上的操作都放到了BlueField DPU上,由DPU执行通信框架、存储框架、安全框架和业务隔离,让Host里面的CPU和GPU资源都释放给应用。
除此之外,英伟达还提出了对业务性能做优化的思路,那就是把通信和计算重叠起来,这样的话可以通过DPU来加速HPC业务中的通信,由DPU来运行通信框架,由CPU和GPU执行真正的浮点计算。
具体看,可以让DPU直接对HOST的内存进行操作,比如要进行RDMA的读写操作时,可以由DPU直接对HOST Memory发起RDMA的读写操作,在HOST CPU不感知的情况下就可以把数据读走或者把数据写到HOST CPU的内存里来,通过这样的方式实现了通信和计算的重叠,同时DPU再配合通信框架可以智能识别通信时Messenger Size的大小,根据Messages Size大小选择不同的优化方式,比如如果传的是小包,它就会自动选择针对小包的通信优化方式,如果传的是大包就会选择专门针对大包的通信优化方式。
英伟达网络事业部的宋庆春介绍到,在实现了计算和通信的重叠之后,就可以从业务角度看一下它带来的性能提升。比如在HPC应用、AI做推荐时的经常会用到的通信模型Alltoall上,通过用DPU和CPU实现计算通信重叠,让iAlltoall性能得到44%的提升;Allgather是在做大规模模型并行训练时用到的一个通信模型,通过DPU和CPU计算通信的Overlap,可以让Allgather的性能提升36%。
云原生软件DOCA 1.2定义安全
现在网络安全已经成为数据安全的最大的威胁,现在面临着数据量越来越大,数据传输速度越来越快,各种异构数据频繁出现,非结构化的数据量远远大于结构化的数据,所以在处理非结构化数据时复杂程度会远远大于处理结构化数据的复杂程度。需要做很多跨平台的整合,各种模型迭代、计算迭代、平台迭代越来越快。所以在这样一个大环境下,使用传统的思维方式或者工具已经没有办法满足现在数据中心的安全需求了,在现代数据中心里要发现一个数据中心中的漏洞,大概需要超过半年的时间,而要修复这个漏洞需要超过两个多月的时间。这对于现在基于零信任(Zero-trust)的前提下是绝对不可接受的。因为现在零信任(Zero-trust)的前提就是对数据中心中的任何人、任何事、任何设备都不信任,如果要是发现问题需要200天,修复问题需要70天,整个数据中心将非常不安全。
那么如何解决这个问题?在今年秋季GTC上,NVIDIA发布了 DOCA 1.2。DOCA 1.2正是专门面向零信任(Zero-trust)的安全框架,在其中包括了很多和安全相关的软件。DOCA 1.0、DOCA 1.1、DOCA 1.2每个版本发布时都会有其针对性的市场,DOCA 1.2主要是面向安全。
在DOCA1.2中提供了Load Balancers、DPI、 IPS、IDS、下一代防火墙,如果是设计安全软件的用户或者安全软件的供应商,可以直接通过DOCA API调用在DPU里的硬件加速引擎,让数据中心更安全。
在GTC上,黄仁勋专门针对Morpheus安全框架做了介绍。Morpheus是NVIDIA在基于DPU+DOCA安全数据中心平台里采用AI深度学习技术来进行安全防御的一个框架,它对于未来的数据中心提供了一个更新的思路,就是通过Morpheus可以利用AI的方式,去进行安全防御,通过AI的方式来对数据中心里的人、人的行为、数据中心中的设备、数据中心里的流量和其他的一些特征进行提取、训练和推理,生成各种模型,对网络进行更全面、宽度更广的安全的监督和监控。
Morpheus AI网络安全框架
NVIDIA Morpheus给了用户一个完全的零监督、自学习的框架,而且通过Morpheus、采用AI技术对于安全的保障,可以实现600倍快的数据处理的速度,可以通过Morpheus根据刚才通过DPU抓到的各种特征来生成超过百万甚至超过千万级别的模型,然后在数据中心里面去进行匹配,实现对于数据中心的异常情况的侦测,只要是异常行为这时候就会去监控和识别。
结语
英伟达网络事业部的宋庆春最后总结到,数据中心对算力的需求变得越来越大,要运行大的模型需要很多的GPU,数据并行和模型并行在未来工作训练中同时使用将成为一个趋势。在这种大规模使用场景下面,如何既保持很高的算力,就能够在多租户情况下保证训练性能,保证业务的安全性,云原生技术是必不可少的。
从推理的角度看,很多人说做推理并不需要很高的算力,其实不对,因为随着现在AI模型越来越大,当我们做推理的时候,一个GPU、甚至是一个服务器中多个GPU也没有办法放下我要做推理的整个模型,这时候就需要跨服务器、跨Node做推理。在GTC上发布的数据显示,当用两个DGX A100做推理时,它的时间可以达到1/2秒。如果这样一个推理工作要放在两个CPU的服务器上来做,时间将超过1分钟。为了让推理效率更高,推理走向分布式也慢慢出现了,推理也需要更高算力和更高的通信能力。
DPU的出现弥补了在数据中心中对于基础设施加速能力的不足,实现了DPU、GPU、CPU 3U一体新型数据中心架构,让数据中心成为了新的计算单元,还给了我们一个优化算力资源的新的思路。所以,3U一体已经成为数据中心的一个必然的架构,而且,在这样一个必然的架构中通过DPU、CPU和GPU的分工合作可以实现数据中心中最优的性能。
责任编辑:sophie
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 英特尔重磅发布OPS 2.0,智能教育时代加速到来
- 2 破除AI落地难题!英特尔全新软硬件平台,助力企业AI创新
- 3 晶圆厂中的“超纯水”,你真的了解吗?
- 4 三方联合,上海国际汽车电子与半导体应用展览会将于明年4月在上海举办
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号