
英特尔新品采用了台积电16nm制程
来源:
内容来自「
超能网
」,谢谢。
现在深度学习已成为人工智能的重要方向,而且研究成果已经应用于日常使用中。
但训练人工智能模型需要强大的算力支持,所以除了使用GPU加速训练外,很多厂商开始推出专用于深度学习训练的ASIC芯片。
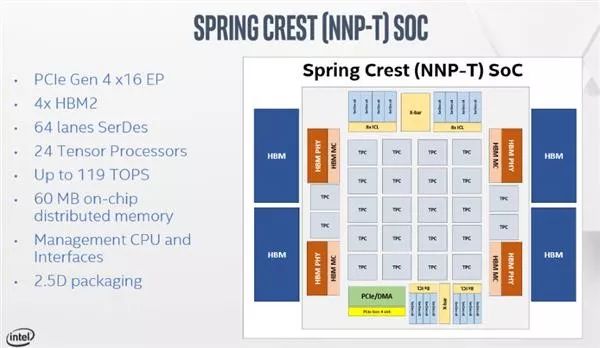
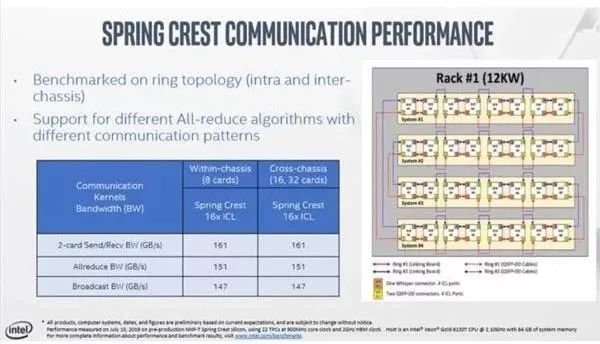
英特尔在人工智能领域投入颇多,除了FPGA产品线外,也推出了Nervana深度学习加速器,在今天的Hot Chips 31会议中,英特尔公布了旗下Nervana NNP-T深度学习加速器的细节。








*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2043期内容,欢迎关注。
推荐阅读
★ 群雄垂涎恩智浦
★ 博通变了
半导体行业观察

『 半导体第一垂直媒体 』
实时 专业 原创 深度
识别二维码 ,回复下方关键词,阅读更多
射频|台积电|制造|AMD|日韩芯片|博通|集成电路|晶圆
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复 搜索 ,还能轻松找到其他你感兴趣的文章!





-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 英特尔重磅发布OPS 2.0,智能教育时代加速到来
- 2 破除AI落地难题!英特尔全新软硬件平台,助力企业AI创新
- 3 晶圆厂中的“超纯水”,你真的了解吗?
- 4 OPPO 20周年,首次发布创新与知识产权白皮书
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号