来源:内容转载自公众号
IEEE电气电子工程师
,作者:
GEOFFREYW.BURR等
,谢谢。

机器学习和人工智能(AI)已经深入到我们的生活和工作中,以至于你可能已经忘记了与机器的交互曾经是什么样子。我们过去只要求对数字键盘、电子表格或编程语言表达的问题给出精确的定量答案,例如:“10的平方根是多少?”“按照这个利率,我在未来五年的收益是多少?”
但在过去的10年里,我们已经习惯了机器,也常常向它提出一些模糊的问题:“我会喜欢这部电影吗?”“今天的交通情况如何?”“那笔交易是欺诈性的吗?”
深度神经网络(DNN)是一种学习如何在对非常相似的查询进行正确答案的训练后对新查询做出响应的系统,它启用了这些新功能。据国际数据公司(International Data Corporation)称,DNN是快速增长的全球人工智能硬件、软件和服务市场的主要驱动力,今年价值3275亿美元,预计2024年将超过5000亿美元。
卷积神经网络首先通过提供超人的图像识别能力推动了这场革命。在过去的十年中,用于自然语言处理、语音识别、强化学习和推荐系统的新DNN模型已经实现了许多其他商业应用。
但不仅仅是应用程序的数量在增长。网络的规模和所需的数据也在增长。DNN具有固有的可扩展性,当它们变得更大时,当您使用更多数据对它们进行培训时,它们提供了更可靠的答案。但这样做是有代价的。2010年至2018年间,培训最佳DNN模型所需的计算操作数量增长了10亿倍,这意味着能耗大幅增加,而在新数据(称为inference,推理)上使用已培训过的DNN模型所需的计算量大大低于培训本身,因此能耗也大大降低,这种推理计算的数量是巨大的,而且还在增加。如果要继续改变人们的生活,人工智能就必须提高效率。
从数字计算到模拟计算的转变可能是我们所需要的。通过使用非易失性存储设备和电气工程的两个基本物理定律,简单电路可以实现深度学习最基本的计算,只需要千分之一万亿焦耳(毫焦耳)。在这项技术能够应用于复杂的人工智能之前,有大量的工程要做,但我们已经取得了巨大的进步,并制定了前进的道路。
在大多数计算机中,当大量数据必须在外部存储和计算资源(如CPU和GPU)之间移动时,时间和能源成本最高。这就是“冯·诺依曼瓶颈(von Neumann bottleneck)”,以分离内存和逻辑的经典计算机体系结构命名。一种大大降低深度学习所需能量的方法是避免将数据移动到存储数据的地方进行计算。
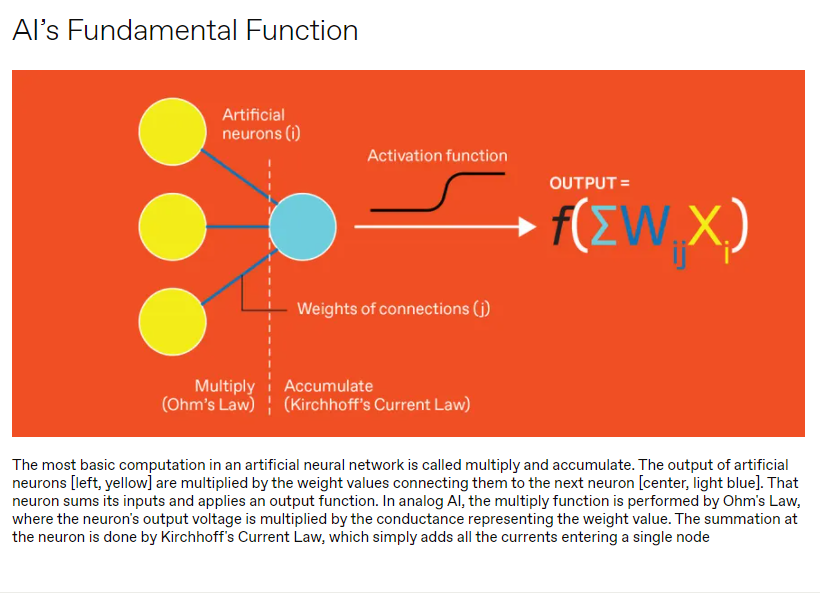
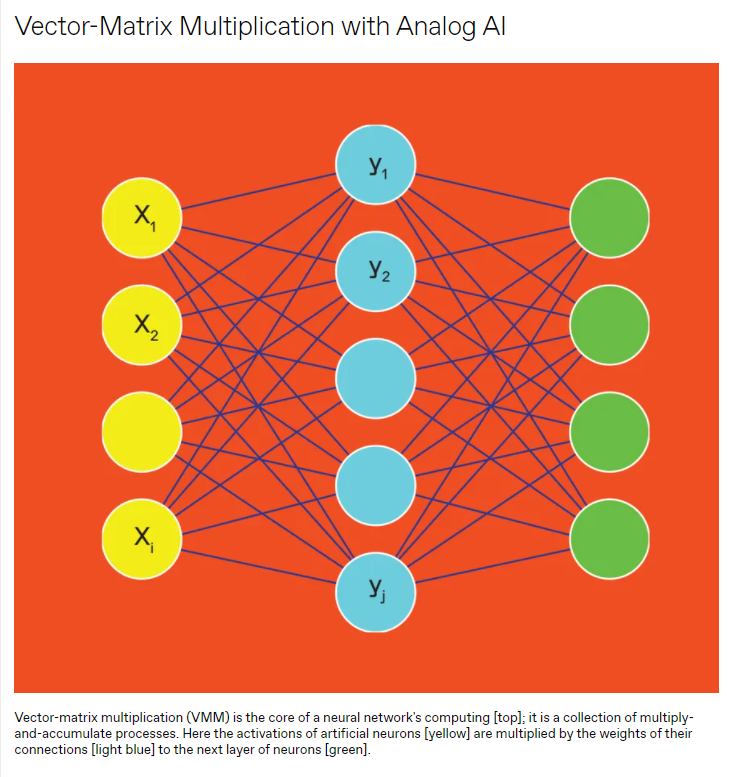
DNN由多层人工神经元组成。每一层神经元根据一对值——神经元的“激活”和与下一层神经元连接的突触“重量”——驱动下一层神经元的输出。
大多数DNN计算由所谓的向量矩阵乘法(vector-matrix-multiply,VMM)操作组成,其中向量(a one-dimensional array of numbers,一维数字数组)与二维数组相乘。在电路级,这些操作由许多乘法累加(MAC)操作组成。对于每个下游神经元,所有上游激活必须乘以相应的权重,然后将这些贡献相加。最有用的神经网络太大,无法存储在处理器的内存中,因此在计算网络的每一层时,必须从外部内存引入权重,每次计算都会受到可怕的冯·诺依曼瓶颈的影响。这使得数字计算硬件更倾向于DNN,它从内存中移动更少的权重。
早在2014年,IBM Research就向我们提出了一种全新的节能DNN硬件方法。与其他研究人员一起,我们一直在研究非易失性存储器(NVM)设备的交叉阵列。纵横制阵列是一种结构,其中设备(例如存储单元)构建在两组垂直水平导体(即所谓的位线和字线)之间的垂直空间中。我们意识到,只要稍作修改,我们的内存系统将非常适合DNN计算,尤其是那些现有权重重用技巧效果不佳的计算。我们将这一机会称为“模拟人工智能”,尽管其他从事类似工作的研究人员也使用“在内存中处理(processing-in-memory)”或“在内存中计算(compute-in-memory)”等术语。
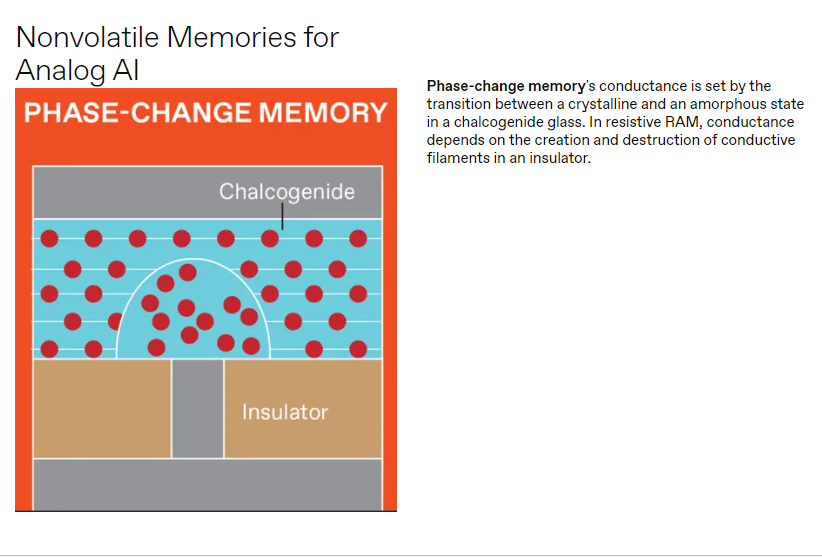
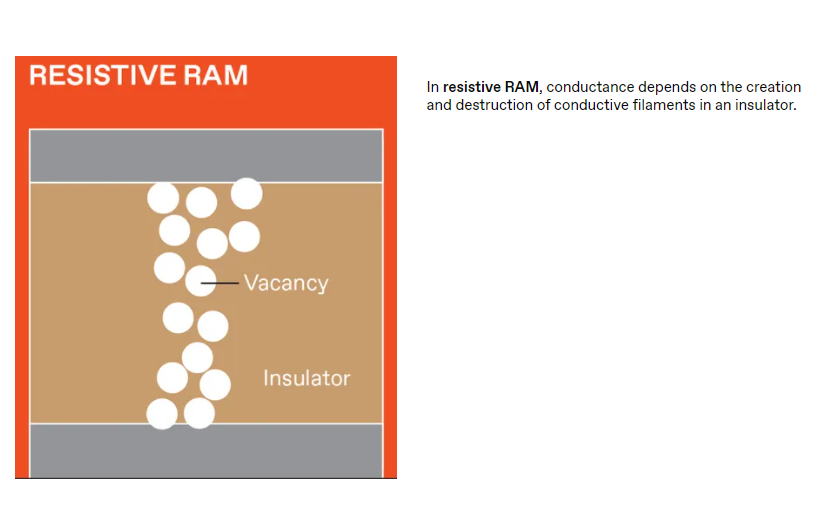
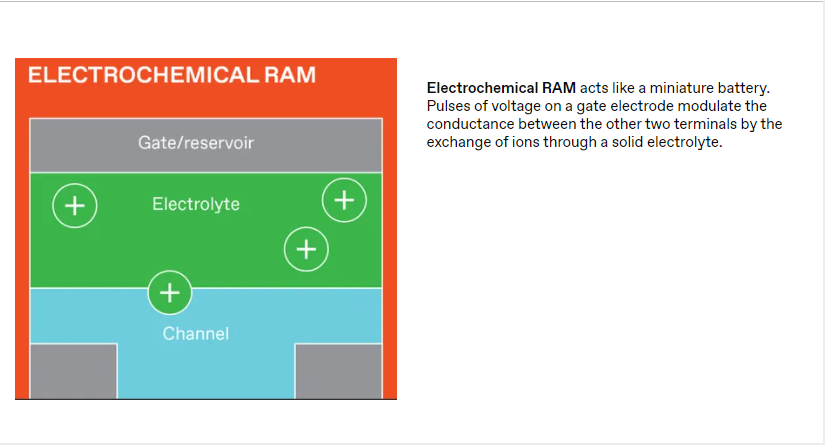
NVM有几种不同的类型,每种类型都以不同的方式存储数据。但是数据是通过测量设备的电阻(或者,等效地,它的反向电导)从所有这些设备中获取的。磁阻RAM(MRAM)使用电子自旋,而闪存使用捕获电荷。电阻RAM(RRAM)器件通过在微小的金属-绝缘体-金属器件内产生并随后破坏导电细丝缺陷来存储数据。相变存储器(PCM)利用热量在高导电性晶相和低导电性非晶相之间诱导快速可逆转变。
闪存、RRAM和PCM提供常规数字数据存储所需的低电阻和高电阻状态,以及模拟AI所需的中间电阻。但在高性能逻辑中,只有RRAM和PCM可以容易地放置在硅晶体管上方布线中的交叉阵列中,以最小化内存和逻辑之间的距离。
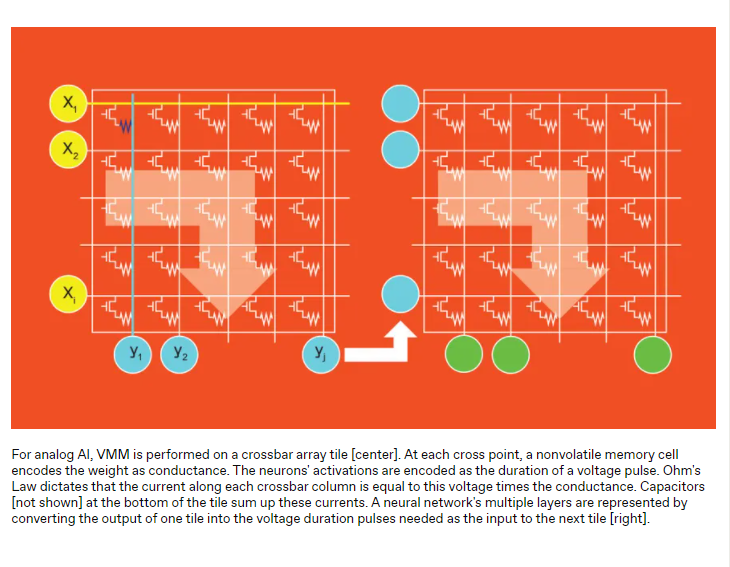
我们将这些NVM内存单元组织在二维阵列中,或“平铺”磁贴(tile)上包括控制NVM设备读写的晶体管或其他设备。对于内存应用,寻址到一行(字线)的读取电压会产生与NVM电阻成比例的电流,可在阵列边缘的列(位线)上检测到该电流,从而检索存储的数据。
为了使这样一个块成为DNN的一部分,每一行用一个电压驱动,持续时间编码一个上游神经元的激活值。沿行的每个NVM设备用其电导编码一个突触重量。通过欧姆定律(在这种情况下表示为“电流等于电压乘以电导”),产生的读取电流有效地执行激励和重量的乘法。然后,根据基尔霍夫电流定律(Kirchhoff's Current Law),每个位线上的单个电流相加。这些电流产生的电荷随时间积分在电容器上,产生MAC操作的结果。
这些相同的模拟内存求和技术也可以使用闪存甚至SRAM单元来执行,SRAM单元可以存储多个位,但不能存储模拟电导。但是我们不能把欧姆定律用于乘法步骤。相反,我们使用的技术可以适应这些内存设备的一位或两位动态范围。然而,这种技术对噪声非常敏感,所以IBM一直坚持使用基于PCM和RRAM的模拟AI。
与电导不同,DNN权重和激活可以是正的,也可以是负的。为了实现有符号权重,我们使用一对电流路径,一个向电容器添加电荷,另一个减去。为了实现有符号激励,我们允许每行设备根据需要交换它连接的路径。
当每列执行一个MAC操作时,磁贴并行执行整个向量矩阵乘法。对于权重为1024×1024的磁贴,这是一次100万个MAC。在我们设计的系统中,我们预计所有这些计算只需32纳秒。由于每个MAC执行的计算相当于两次数字运算(一次乘法后一次加法),因此每32纳秒执行100万次模拟MAC代表每秒65万亿次运算。由此,每次操作仅使用36毫焦耳的能量,相当于每焦耳28万亿次操作。研究人员最新设计将这一数字降低到10 fJ以下,使其效率比商用硬件高100倍,比最新定制数字加速器的系统级能效高10倍,即使是那些为了能效而牺牲精度的加速器。
对我们来说,提高per-tile的能效非常重要,因为一个完整的系统在其他任务上也会消耗能量,比如移动激活值和支持数字电路。
要使这种模拟人工智能方法真正起飞,还有许多重大挑战需要克服。首先,根据定义,深层神经网络具有多层结构,需要要级联多个层。最近,我们推出了一种基于PCM的高性能磁贴,使用了一种新型ADC,帮助磁贴达到每瓦10万亿次以上的操作。
第二个挑战与NVM设备的行为有关,也更麻烦。数字DNN已被证明是准确的,即使它们的重量是用相当低精度的数字描述的。CPU经常使用的32位浮点数对于DNN来说是多余的,当使用8位浮点值甚至4位整数时,DNN通常工作得很好,能量也比较少。这为模拟计算提供了希望,只要我们能够保持类似的精度。
鉴于电导精度的重要性,将电导值写入NVM设备以表示模拟神经网络中的权重需要缓慢而仔细地完成。与传统存储器(如SRAM和DRAM)相比,PCM和RRAM的编程速度较慢,并且在编程周期较少后会磨损。幸运的是,对于推理,权重不需要经常重新编程。因此,模拟AI可以使用耗时的写验证技术来提高对RRAM和PCM设备编程的精度,而不必担心设备磨损。
这种提升是非常必要的,因为非易失性存储器具有固有的编程噪声水平。有一些方法可以解决这个问题。通过使用两个电导对,可以显著改善重量编程。这里,一对保存大部分信号,而另一对用于纠正主对上的编程错误。噪声被降低,因为它在更多的设备上得到平均值。
我们最近在基于多片PCM的芯片上测试了这种方法,每个重量使用一对和两对电导对。有了它,我们在几个DNN上证明了卓越的准确性,甚至在递归神经网络上也是如此,这种神经网络通常对权重编程错误非常敏感。
到目前为止,我们只讨论已经训练好的神经网络作用于新数据的推理。但模拟人工智能也有机会帮助培训DNN。
DNN使用反向传播算法进行训练。这将通常的正向推理操作与另外两个重要步骤错误反向传播和权重更新相结合。错误反向传播就像反向运行推理,从网络的最后一层返回到第一层;权重更新然后将来自原始正向推理运行的信息与这些反向传播的错误相结合,以使模型更准确的方式调整网络权重。
模拟人工智能的成功将取决于同时实现高密度、高吞吐量、低延迟和高能效的程度。密度取决于NVM集成到芯片晶体管上方布线的紧密程度。磁贴级别的能源效率将受到用于模数转换的电路的限制。
前进的道路必然不同于数字人工智能加速器。但是,模拟AI必须首先提高内部模拟模块的信噪比(SNR),直到它足够高,足以证明与数字系统的精度相当。任何后续的信噪比改进都可以用于提高密度和能源效率。
这些都是令人兴奋的问题,需要材料科学家、设备专家、电路设计师、系统架构师和DNN专家的共同努力才能解决。人们强烈且持续地需要更高的能效AI加速,并且缺乏其他有吸引力的替代品来满足这一需求。考虑到各种各样的潜在存储设备和实现途径,某种程度的模拟计算很可能会进入未来的人工智能加速器。
这篇文章刊登在2021年12月的印刷版上,题为“欧姆定律+基尔霍夫现行定律=更好的AI”。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2894内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|集成电路|设备
|汽车芯片|存储|台积电|AI|封装
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!