来源:内容来自cpuTECHandECO,谢谢。
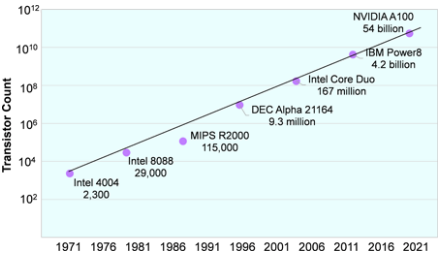
以英特尔4004的诞生为开端,五十年的微处理器历史已经书写完成。几乎没有一个领域像微处理器那样发展的如此迅速,在短短五十年间,微处理器的发展跨越了七个数量级--从2300个晶体管到540亿个。最初的4位单个ALU设计已经演变成众核巨无霸,这些进步几乎为人类生活的每个方面提供了动力。
为了说明这些变化,MPR重点突显了一些能定义整个行业的产品,包括英特尔8088、MIPS R2000、DEC Alpha 21164、英特尔Core Duo、IBM Power8和NvidiaA100。每一个产品都通过频率和微体系结构的升级展示出不断增长的性能。
在过去的50年里,晶体管数量的上升与戈登-摩尔的预测(摩尔定律)保持了惊人的一致,即晶体管的数量每两年就会翻一番。将这一翻倍速度应用于4004的晶体管,预测2020年将出现540亿个晶体管的处理器,如图1所示,Nvidia通过A100实现了这一目标。尽管晶体管数量仍然与性能密切相关,但在这段期间,各公司也通过电路结构和微体系结构创新提高了性能。
(按照摩尔定律,这一数字稳定的每两年翻一倍。Nvidia的A100,当前达到光罩孔极限尺寸的芯片(reticle-size chip),完美的匹配这一预测。(数据来源:各个厂商))
英特尔于1971年发布了其4位4004处理器,在两英寸晶圆上以10微米的工艺制造它。与以前拥有几十或几百个晶体管的集成电路相比,它是当时最先进的设计,包括2250个晶体管。然而,它是由单独一名工程师费德里科-法金(Federico Faggin)创造的,他每周工作80小时,以按期交付740kHz的处理器(见MPR 12/18/06,"英特尔4004的35周年")。除了设计逻辑和电路之外,他还必须手工切割用于制造光学掩模的红宝石薄膜。在一个自我陶醉的时刻,设计师在一个掩模上刻下了“F.F.”。
4004只实现了46条指令,其中5条是双倍长度。该处理器集成了一个单一的ALU,在8个时钟周期内完成4位加法(和大多数其他指令),使其有效执行率低于0.1MHz。尽管有一个完整的CPU,尺寸为12平方毫米,但4004无法独立运行,因为除了64位(16x4位)寄存器文件外,它缺乏任何存储器。因此,Faggin还交付了4001 ROM芯片、4002总线接口芯片、4002 RAM芯片和4003总线接口芯片。
4004彻底改变了市场,因为它是第一个软件可编程的芯片。它首先服务于Busicom公司的141-PF计算器,因为该公司拥有该设计的独家权利。但Intel意识到可编程性使这一设计适用于广泛的系统,因此它通过谈判达成协议,允许Intel向其他客户出售4004,从而开创了微处理器市场。即使在1971年,该公司也着眼于游戏市场;例如,4004最终进入了弹球机,为曾经的纯机械游戏增添了光彩。
16位的Intel 8088于1979年投入生产。如图2所示,该公司使用其3微米技术制造了这个包含29000个晶体管的芯片。峰值速度徘徊在5MHz左右。英特尔在其新建的以色列海法实验室创造了8088。该处理器与8086基本相同,后者引入了x86指令集,但8088将外部总线接口减少到8位以降低系统成本。与8086一样,它有一个6字节的取指队列,一个16位的ALU和16位的寄存器。它的简单流水线有两个流水段:取指/译码和执行。
(8088有33平方毫米和29,000个晶体管。虽然芯片最早是Intel设计的,许多类似AMD的厂商获得了设计授权能够进行制造。(照片源自Pauli Rautakorpi《维基百科<https://en.wikipedia.org/wiki/Intel_8088#/media/File:AMD_8088_die.JPG>》,按照CC BY 3.0授权))
然而,与8086相比,8088由于其较窄的数据总线和较小的预取队列而出现性能问题。它体现了顺序处理器的低效率:例如,程序员需要将长指令与短指令交错使用,以避免瓶颈。8088在调用、跳转和中断方面也有困难,因为这些指令重置了预取队列,可能需要15个周期来重新填充。4004需要定制存储芯片,而8088可以使用商品RAM和ROM。客户通常将8088与英特尔的8位锁存器8282处理器、8284时钟发生器、8位8287驱动器、8288总线控制器、8259总线仲裁器和8087数学协处理器配对使用。
8088在第一台IBM PC中赢得了一个重要的设计,确保了英特尔和x86体系结构在个人电脑PC革命的长期中心地位。英特尔并不是唯一一家提供8088解决方案的公司;IBM要求有第二个供应来源,因此英特尔将8088设计授权给AMD、NEC、德州仪器和其他公司。在这一时期,授权处理器是很常见的,但英特尔最终在1985年的80386时代停止了这种做法。
MIPS计算机系统公司在1986年提供了MIPSISA的第一个商业实现,从而震撼了计算机体系结构的世界。R2000是第一个商业化的RISC体系结构,启动了RISC与CISC的辩论。这款32位110,000晶体管的芯片有三个速度等级:8.3MHz、12.5MHz和15MHz。MIPS是第一批无工厂产线的处理器供应商之一,将R2000外包给Sierra半导体公司并使用其2微米的双层金属CMOS工艺(见MPR 2/89,"MIPS挑战SPARC和88000")。
R2000的执行引擎有一个ALU和一个乘法/除法单元。简化的RISC结构在每个时钟周期处理一条指令,远远超过了竞争性的CISC处理器。该CPU有五个流水段,使其成为未来几十年内的顺序RISC设计模板,包括RISC-V的RocketCPU。像同时期的80386一样,R2000需要外部芯片来实现高速缓冲存储和(可选择)执行浮点(FP)运算。
R2000在工作站和服务器制造商中特别受欢迎。其强大的数学性能使MIPS成为工程师和科学家的理想选择,而ISA因其优化的软件栈而变得更加流行。编译器设计者帮助创建了最早的ISA模拟器之一,这加速了UNIX在MIPS机器上的应用。
如图3所示,Alpha 21164是一款野兽般的微处理器。数字设备公司(DEC)于1994年发布,它的最高频率为300MHz(见MPR 9/12/94,"Digital公司以21164引领潮流")。七级流水线比任何竞争者的设计都要深,使该处理器具有速度优势。21164实现了DEC专有的64位Alpha体系结构,支持UNIX和OpenVMS。该公司用自己的0.5微米工艺制造该芯片,塞进了930万个晶体管。
图3 DEC公司Alpha 21264的晶片管芯照片
(这款芯片在当时是庞然大物,尺寸为314平方毫米。主频300MHz,远远超过其他竞争芯片。(照片源自Pauli Rautakorpi《维基百科<https://en.wikipedia.org/wiki/Intel_8088#/media/File:AMD_8088_die.JPG>》,按照CC BY 3.0授权))
21164的超标量微体系结构与最近的处理器相似。它集成了一个8KB的指令缓存,并将指令传递给一个宽度为4的译码器,该解码器每个周期向执行引擎发出四条译码后的指令。21164包括两个整数单元和两个浮点单元用于算术运算。它还实现了一个片上二级缓存,容量为96KB。该设计有一个43位的虚拟地址空间和一个40位的物理地址空间,使其能够处理比同时代更多的存储。8TB的虚拟内存和1TB的DRAM。这种地址空间为需要大型数据集的应用提供了独特的优势。
在发布时,21164扩大了DEC的性能领先优势:它在SPECint95中的得分是15.4,在SPECfp95中的得分是21.1,在这两个方面都超过了英特尔的Pentium。由Alpha 21164驱动的系统因此完成了新的壮举,如CAD建模,多媒体编辑,甚至是视频会议。1994年,DEC公司处于世界之巅,因为它的Alpha组合提供了无可匹敌的性能。但是,当英特尔的Pentium Pro(P6)到来时,好日子就结束了,它使用RISC技术来提高x86性能。从那时起,RISC在PC和服务器中的受欢迎程度急剧下降,DEC在2001年放弃了Alpha。
英特尔在2006年发布了Core Duo,这是第一个多核的个人电脑PC处理器。服务器之前已经采用了多核芯片,但该公司将这种方法带到了个人电脑上,为笔记本电脑和台式机提供了两种不同的设计(见MPR 10/3/05,"Yonah做双核的权利")。该公司在其65纳米节点上制造了管芯面积为143平方毫米的台式机版本(Conroe),包装了2.91亿个晶体管。它的频率达到3.0GHz,同时运行32位和64位x86体系结构。在英特尔的高主频NetBurst方法火了之后,Conroe是第一批使用Core微体系结构的处理器之一,该体系结构仍然是该公司目前旗舰CPU的基础。
酷睿双核Core Duo开启了今天的多核运动,并成为中心。通过将两个CPU装在一个管芯Die上以填补其晶体管预算,英特尔大大提升了性能。另一个选择是建立一个更复杂的单核CPU,相对于上一代产品,其尺寸增加了一倍,但这被证明是不可行的。乱序的Core CPU核心集成了一个32KB的指令和数据缓存,四个解码器,一个96个条目的重排缓冲器,以及五个用于内存和算术操作的执行端口。它集成了一个128位SIMD单元,用于加速英特尔的向量(SSE)扩展。
新的双核处理器不仅因其性能而闻名,而且还因其(当时)令人印象深刻的65W功耗TDP等级而闻名。然而,双核模式给软件带来了问题,这些软件被设计为在单个CPU上运行。工程师需要实现多线程编程模型。发布升级的软件花了几年时间;在这期间,很少有用户能看到承诺的性能提升。
到2014年,多线程软件已经成为常态,但Power8将多线程带到了一个新的水平。2014年发布的它是一个多线程的怪物,包装了12个核心,有96个线程(见MPR 12/29/14,"Power8冲击商业市场")。IBM用22纳米绝缘体上硅(SOI)工艺制造了这颗190W的芯片。即使按照现代标准,它也是巨大的,面积为650mm2,装有42亿个晶体管,如图4所示。这也是第一个可供商业购买的POWER芯片。
(在2014年,IBM通过12核,每核4线程将多线程推进到新的高度。22纳米的晶片管芯尺寸是650平方毫米,同时封装了42亿晶体管。(由IBM拍摄的晶片管芯照片))
在设计Power8时,片上存储器成为IBM的重点。该芯片每个内核采用512KB的二级缓存,96MB的嵌入式DRAM(eDRAM)用于L3缓存。eDRAM的使用是独一无二的:它使IBM能够在芯片上集成大量的存储,而单靠SRAM是不可能做到的。即使是巨大的内核数量,Power8的速度也达到了3.6GHz。该设计的特点是具有14个执行单元的特别宽的执行引擎,可以处理分支以及整数、浮点、定点和向量操作。广泛的执行引擎帮助Power8在IPC方面超过了竞争对手。
该处理器仍然让Intel在服务器市场上赚到钱。Power8的价格比英特尔的旗舰产品至强E5-2699v3低30%,提供类似的整数性能和领先的浮点性能。全球的银行家和零售商都受益于定点的十进制引擎,它加速了传统的Cobol软件。尽管有更好的性能和更低的价格,但该处理器缺乏X86兼容性,使其在IBM自己的系统之外没有获得吸引力。
Nvidia A100达到了光照极限(Reticle Limit)
Nvidia的A100最能代表当今的高性能处理器,它使用专门的体系结构在一个流行的应用程序上实现了领先的性能。该公司的GPU已经成为神经网络训练的代名词(见MPR 6/8/20,"Nvidia A100在AI性能方面名列前茅")。在过去十年中,人工智能应用的普及率飙升,触及日常生活的许多方面。但神经网络带来的巨大计算压力造成了对专门硬件的需求。用于数据中心400W的A100 GPU在20年第二季度投入量产,并立即成为AI的热门产品。它具有540亿个晶体管;在7纳米统一中,826毫米的巨大芯片测试了台积电的光照尺寸极限。
A100实现了Nvidia的AmpereGPU体系结构,以加速AI训练和推理。VLIW配置减少了指令调度逻辑,许多SIMD单元有利于计算神经网络经常采用的大型卷积。该芯片有108个GPU核心,包含矩阵乘法单元和向量ALU。它的发布使英伟达处于人工智能市场的顶端。该公司围绕A100及其他基于GPU的人工智能加速器建立了一个庞大的软件生态系统,其目标是几乎所有可以想象的领域,从医疗保健到农业到分子动力学。
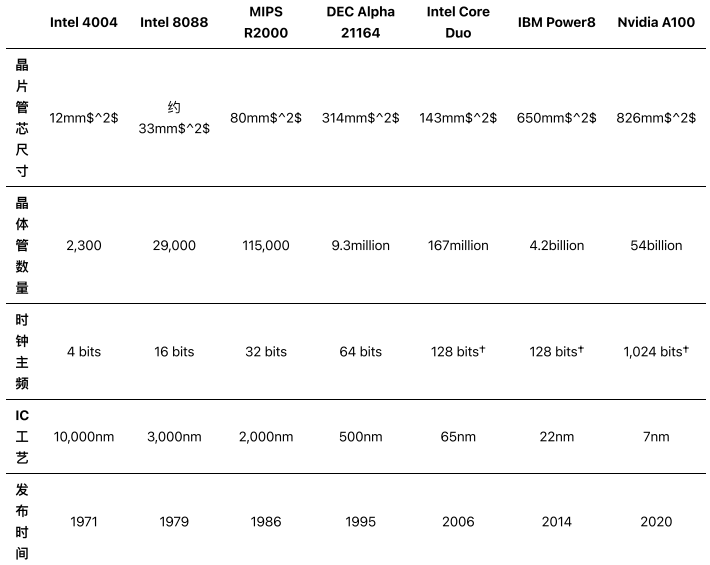
如表1所示,在过去的50年里,单个芯片上的晶体管数量已经爆炸性增长。表中的每个产品都需要重大的工艺技术进步,从光学光刻到紫外线、多重曝光,以及今天的EUV(见MPR 5/20/19,"EUV工艺达到大规模生产")。晶体管面积下降了200万倍。随着缺陷率的下降和工艺的改进,晶片管芯尺寸也在增加,允许每个芯片有更多的晶体管。这些因素使更复杂的微体系结构、更多的片上存储器,以及最终每片更多的内核成为可能,提高了性能。
(50多年来,晶体管数量猛增。这种增长之所以可能,是因为主流工艺技术的改进。†使用了向量(SIMD)单元。(来源:厂商))
对于基于CPU的处理器,频率上升了四个数量级。4004开始时不到1MHz,但现代Intel处理器可以达到5,200MHz。CPU设计者使用了两种技术来提高时钟频率:一种是依靠代工厂提高晶体管速度,另一种是通过微体系结构的升级来实现收益。
虽然A100是一个GPU,但MPR仍然认为它是一个处理器,因为它加载和执行指令。MPR把Nvidia的芯片包括在内,以强调GPU和AI产品现在是如何推动摩尔定律的。最先进的设计有数百个1,024位的ALU,与原始微处理器上的单一4位ALU相比,相差甚远。
没有一篇文章能涵盖微处理器50年的全部历史。MPR的精心策划包括了其认为在这个时间段内具有代表性的产品,强调了处理器所经历的许多结构变化。最早的例子只能执行最基本的功能,如加法,而且缺乏片上存储器。随着时间的推移,设计者集成了一些功能,如浮点单元和总线接口,而这些功能以前是在独立的芯片上。
一旦整个CPU都在芯片上,公司开始增加更多的CPU。数据路径从4位扩展到64位,对于专门的SIMD单元来说甚至更宽(在这个过程中消耗了许多晶体管)。缓存在20世纪80年代开始成为一种外部功能,在20世纪90年代转移到芯片上,并发展成为今天复杂的多级缓存。更深的流水线实现了更高的时钟速度,但它们需要更多的缓冲器和旁路逻辑,进一步增加了晶体管数量。
虽然更深的流水线和更宽的执行单元等技术似乎已经达到了极限,但芯片设计者仍在试图通过尝试不同的方法来提高性能,如特定应用和异构体系结构。当他们缺乏更好的想法时,他们会增加更多的CPU内核,尽管很少有PC应用能够使用它们。
相对于人类历史的跨度,50年几乎是一个小点。然而,在这个微不足道的时期,微处理器的发展速度令人难以置信。它们无处不在,从微波炉到自动驾驶汽车。当人们花时间欣赏微处理器时,也必须记住这项宝贵的发明是如何从简陋的4004开始的。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2965内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|集成电路|设备
|汽车芯片|存储|台积电|AI|封装
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!