
HBM 3的好戏,才刚刚开始
来源:内容由半导体行业观察(ID:icbank) 编译自nextplatform ,谢谢。
在某种程度上,计算系统中唯一真正重要的是它的内存发生了怎样的变化,在某种程度上,这就是让计算机像我们这样的原因。世界上所有的计算能力,或者数据的操作或转换类型,都没有创建新数据那么重要,然后将新数据存储在内存中,这样我们就可以以某种方式高速使用它。
系统及其内存的问题在于,您无法拥有一个拥有一切的内存子系统。
您可以将 3D XPoint 变成一种主内存,正如英特尔在其 Optane PMem DIMM 外形中所展示的那样;PMEM 中的这种持久性很有用,但您最终会得到一个比闪存更昂贵且比普通 DRAM 慢的内存,因此它不能真正完全替代任何一个,但它可以用作内存层次结构中的另一层——并且在某些系统和存储。
使用普通的 DRAM,你可以为应用程序和数据构建一个大的内存空间,但它可能会变得昂贵并且带宽不是很大。内存速度的提高和 CPU 上控制器数量的增加有所帮助,但延迟仍然相对较高(至少与 HBM 堆叠内存相比),并且带宽远不及 HBM 高。该行业确实知道如何大批量生产 HBM,因此产量较低且单位成本较高。
DDR DIMM 无处不在——现在已经有五代了——它们的大规模生产意味着即使带宽受到挑战,它也是低成本的。DDR SDRAM 内存由 JEDEC 于 1998 年指定,并于 2000 年广泛商业化,首次推出时的低频率为 100 MHz,最高频率为 200 MHz,每通道的带宽在 1.6 GB/秒和 3.1 GB/秒之间。通过过去几年的DDR迭代,内存时钟速率、I/O 总线时钟速率和内存模块的数据速率都在增加,容量和带宽也随之增加。DDR4 仍然普遍用于服务器,高端模块的内存运行频率为 400 MHz,I/O 总线速率为 1.6 GHz,数据速率为 3.2 GT/秒,每个模块的带宽为 25.6 GB/秒。DDR5 将带宽翻倍至 51.2 GB/秒,并将每个记忆棒的最大容量翻倍至 512 GB。
我们的猜测是,对于许多设备来说,这种容量很大,但带宽根本不够用。因此,在可预见的未来,我们最终会在节点内部实现拆分内存层次结构并靠近计算引擎。或者,更准确地说,客户必须在具有 DDR5 内存和 HBM3 内存的设备之间进行选择,他们可能会在系统内和集群中的节点之间混合使用它们,其中一些可能具有 Optane 或其他类型的 ReRAM 或 PCM 持久内存在适当情况下。
跨主要内存类型和速度的编程对于混合内存系统来说仍然是一个问题,直到有人创建一个内存处理单元和一个内存管理程序,可以为计算引擎提供单级内存空间来共享。
或者,公司将使用一种类型的内存来缓存另一种。快而瘦的内存可以缓存肥而慢的内存,反之亦然。因此,在当今的许多混合 CPU-GPU 系统中,GPU 内存是完成大部分处理的地方,CPU 中的 DDR 内存和 GPU 中的 HBM 内存之间的一致性主要用于让 DDR 内存发挥巨大作用GPU 的 L4 缓存——是的,CPU 已被降级为数据管家。相反,对于支持 Optane DIMM 的 Xeon SP 系统,在其中一种模式(也是最容易编程的模式)中,3D XPoint 内存被视为慢速主内存,机器中的 DDR4 或 DDR5 DIMM 是一种超级Optane 内存的快速缓存。
正如我们去年 7 月在介绍HBM3 内存在今年可用后将对系统可能意味着什么时 指出的那样,我们认为 HBM 内存将用于各种系统,最终将变得更加普遍,因此更便宜。毕竟,我们并不都仍然使用核心内存,而且很多工作负载都受到内存带宽的限制,而不是计算。这就是为什么我们相信会有更窄的 512 位总线和无插入器的 HBM 版本以及具有 1,024 位总线和插入器的版本。
使用 HBM 内存(以及英特尔和美光曾经创建并用于其至强融核加速器的现已失效的混合内存立方体堆叠内存),您可以堆叠 DRAM 并将其链接到非常接近计算引擎的非常宽的总线并将带宽提高许多因素,甚至比直接连接到 CPU 的 DRAM 上看到的带宽高一个数量级。但是这种快速的 HBM 内存很薄,而且价格也相当昂贵。它本质上更昂贵,但内存子系统的价格/性能可能会更好。
与 DDR 主存相比,HBM 成本多少我们并不清楚,但 Rambus IP 内核产品营销高级总监 Frank Ferro 知道与 GDDR 内存相比它的成本是多少。
“GDDR5 与 HBM2 的加法器的价格差距大约是 4 倍,”Ferro 告诉The Next Platform。“原因不仅在于 DRAM 芯片,还在于中介层和 2.5D 制造的成本。但是 HBM 的好消息是您可以获得最高的带宽,您可以获得非常好的功率和性能,并且您可以获得非常小的占地面积。你必须为这一切付出代价。但 HPC 和超大规模社区并没有特别受成本限制。他们当然想要更低的功率,但对他们来说,一切都与带宽有关。
Nvidia 知道 HBM3 内存的好处,并且是第一个在上个月宣布 的“Hopper”H100 GPU 加速器 中将其推向市场的公司。在 JEDEC 在 1 月份推出最终 HBM3 规范之后,这非常热门。
HBM3 规范的出台速度比 SK Hynix 去年 7 月在其早期工作中所暗示的要快,当时它表示预计每个堆栈至少有 5.2 Gb/秒的信号传输和至少 665 GB/秒的带宽。
HBM3 规范要求每针信号速率从三星实现 HBM2E 时使用的 3.2 Gb/秒翻倍至 6.4 Gb/秒,HBM2E 是 HBM2 的扩展形式,将技术推向了官方 JEDEC 规范之外,该规范设置了信号最初的速率为 2 Gb/秒。(有一个早期的 HBM2E 变体使用 2.5 Gb/秒信号,而 SK 海力士使用 3.6 Gb/秒信号试图获得 HBM2E 优于三星的优势。)
内存通道的数量也从 HBM2 的 8 个通道增加到 HBM3 的 16 个通道的数量翻了一番,并且在架构中甚至支持 32 个“伪通道”,据此我们假设 DRAM 组之间可能存在某种交错,这通常是常见的在高端服务器主存储器中完成。HBM2 和 HBM2E 变体可以堆叠 4、8 或 12 个芯片高的 DRAM,而 HBM3 允许扩展到 16 个芯片高的 DRAM 堆叠。HBM3 的 DRAM 容量预计在 8 Gb 到 32 Gb 之间,使用 8 Gb 芯片的四层堆栈产生 4 GB 容量,使用 32 Gb 芯片的 16 层堆栈产生每个堆栈 64 GB。据 JEDEC 称,使用 HBM3 内存的第一代设备预计将基于 16 Gb 芯片。内存接口仍为 1,024 位宽,单个 HBM3 堆栈可驱动 819 GB/秒的带宽。
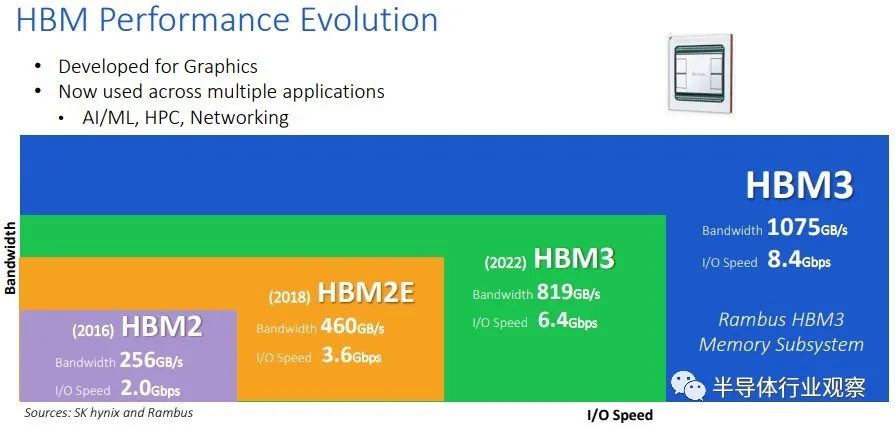
因此,使用六个 HBM3 堆栈,理论上一个设备可以驱动 4.8 TB/秒的带宽和 384 GB 的容量。我们想知道拥有如此多带宽和容量的 Hopper H100 GPU 加速器在成本和散热方面会有什么影响。.
由于计算的上层梯队对内存带宽不耐烦,Rambus 已经超越了相对较新的 HBM3 规范,最终可能在上图中被称为 HBM3E。具体来说,Rambus 已经设计了可以为 HBM3 引脚驱动 8.4 Gb/秒信号的信号电路,并为每个 HBM3 堆栈提供 1,075 GB/秒(是的,1.05 TB/秒)的带宽。其中六个堆栈,您可以获得高达 6.3 TB/秒的内存带宽。这可以通过定制 HBM3 内存控制器和定制 HBM3 堆栈 PHY 实现。(顺便说一下,Rambus 在 HBM2E 上的信号传输速率高达 4 Gb/秒。)
这样的带宽实际上可能会保留像 Nvidia Hopper GPU 这样的计算设备,或者未来的谷歌 TPU5 机器学习矩阵引擎,或者选择你梦想中的设备来提供充足的数据。不过,我们对瓦数和成本感到不寒而栗。但同样,如果带宽是瓶颈,也许在那里投入更多资金并对一切进行液体冷却是有意义的。
我们期待有人建造这样一个野兽,这样我们就可以看到它的表现并分析它的经济性。
★ 点击文末 【阅读原文】 ,可查看本篇原文链接!
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第3003内容,欢迎关注。
推荐阅读
半导体行业观察

『 半导体第一垂直媒体 』
实时 专业 原创 深度
识别二维码 ,回复下方关键词,阅读更多
晶圆|集成电路|设备 |汽车芯片|存储|台积电|AI|封装
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复 搜索 ,还能轻松找到其他你感兴趣的文章!

-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 研发收关:进迭时空高性能处理器核X100产品发布会震撼来袭
- 2 MediaTek天玑汽车平台推动汽车产业加速迈入AI时代,3nm旗舰座舱平台亮相
- 3 广东场效应半导体,二十多年坚持做一件事
- 4 Mentor线上讲堂 | 如何使用 HLS 来优化 AI/ML、视觉和智能 IoT 应用的性能和功耗/能耗
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号