来源:内容由半导体行业观察(ID:icbank)转载
自公众号
软硬件融合
,作者:
Chaobowx
,谢谢。
2019年,Intel收购Barefoot,价格未知(估计50亿美金左右)。Barefoot是P4网络编程语言的发明者,也是使用该语言的Tofino系列以太网交换机芯片的创造者。Intel的IPU(芯片代号Mount Evans)已经集成了P4可编程引擎。
2022年,AMD收购Pensando,价格19亿美金。Pensando的高性能、高可扩展的DPU包括可编程的数据包处理器,可以从CPU中卸载工作负载并提高整体系统性能。
2022年,Intel SVP兼网络与边缘事业部总经理Nick McKeown(Barefoot创始人,收购后全职加盟Intel)提出,英特尔旨在为客户提供业界绝佳
的可编程平台,并将全球网络和企业运营系统转变为软件定义和可编程形式。
1、从可编程网络处理引擎RMT到Intel Tofino
2013年的SIGCOMM大会,当时由Nick McKeown领导的斯坦福大学的研究团队发表论文:Forwarding Metamorphosis: Fast Programmable Match-Action Processing in Hardware for SDN,
提出了RMT可编程网络包处理架构模型。
2014年,Nick团队在SIGCOMM Computer Communication Review上进一步发表了论文,P4: Programming Protocol-Independent Packet Processors,
提出了P4网络编程语言。
P4语言如今已经成为了行业标准语言。
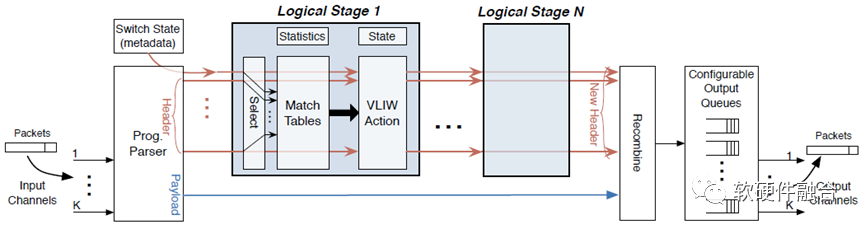
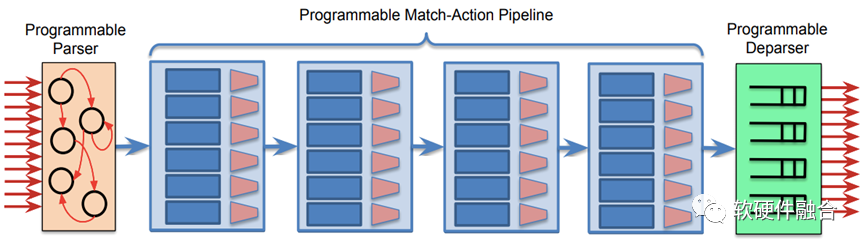
之后在Nick的带领下,成立了Barefoot公司,实现了基于RMT模型的可编程交换机架构PISA(Protocol Independent Switch Architecture,协议无关的交换架构),以及基于此架构的Tofino系列可编程交换机芯片。
2019年Intel收购Barefoot,用于加强其数据中心芯片的网络通信能力,
Intel希望解决数据激增问题,这些数据对更高的计算能力提出巨大需求。同时,还需要提供必要的网络基础设施,以便信息能够在不同数据中心之间进行传输。
而Barefoot在云网络架构、P4可编程高速数据路径、交换机芯片开发和各种其他网络组件方面具有非常强的能力,这有助于Intel实现其网络愿景。
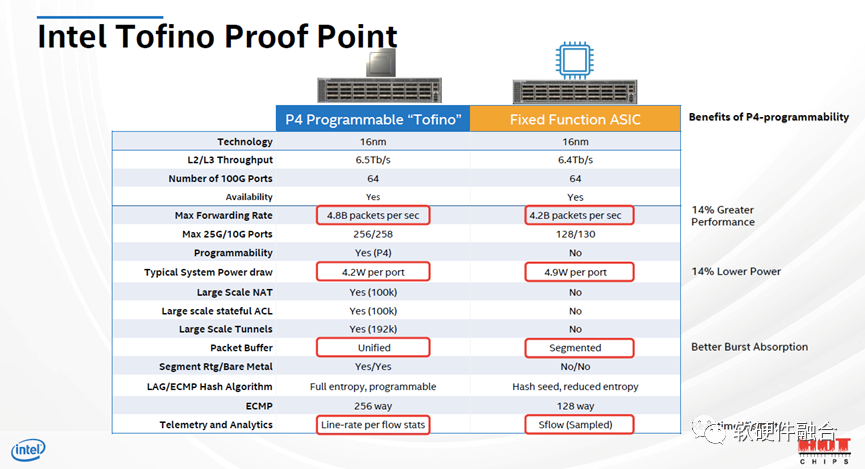
从上图中,我们可以看到Tofino交换芯片,优势不仅仅是完全的协议可编程能力,并且性能和单位能耗均要比ASIC芯片好。ASIC是理论上的最高性能,但因为功能超集的原因,其资源利用率较低。
Tofino的PISA架构,是网络领域的可编程DSA,其资源利用率要高,整体的资源效率反而是高于ASIC的。
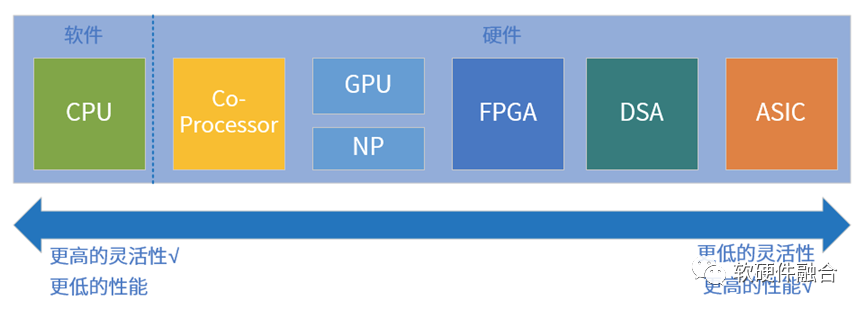
2、基于CPU、NP、FPGA、DSA的P4有什么区别?
指令是软件和硬件的媒介,指令的复杂度(单位计算密度)决定了系统的软硬件解耦程度。按照指令的复杂度,
典型的处理器平台大致分为CPU、协处理器、GPU、FPGA、DSA、ASIC。指令越简单,编程灵活性越高,但性能相对越低;指令越复杂,性能相对越高,但软件灵活性越差。
因此,基于不同处理器平台实现的P4可编程主要区别是在性能方面,
进行定性分析:
-
基于CPU的P4,性能为单位1。
也既是通过软件模拟的方式支持P4编程,其性能局限于CPU的性能。
-
基于NP的P4,性能为10。
有一些公司把P4程序翻译成NP可以识别的程序。NP和GPU在同一个性能层次,其性能比CPU要好一些。
-
基于FPGA的P4,性能为20。
基于FPGA的P4其实是把P4程序翻译成ASIC架构的Verilog层次的代码。基于FPGA实现硬件可编程,但架构上属于ASIC。
-
基于DSA的P4,性能100。
基于DSA实现P4编程,能够实现ASIC层次的性能,并且是完全软件可编程的。
3、第一家商用的网卡侧P4加速引擎:Pensando DSC
站在业务的角度,在网卡侧实现P4的可编程平台的意义比交换机侧更加重大。
在网卡侧可以实现非常多的更高层的协议甚至自定义协议支持,不仅仅是网络2-3层的协议支持。
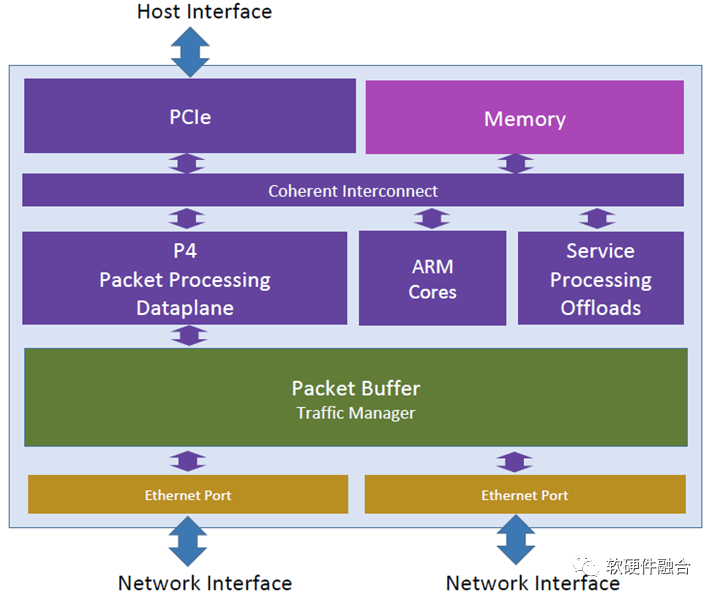
Pensando的DSC芯片,是已知的全球第一家商用的网卡/边缘侧的P4数据面编程DSA引擎。
上图是Pensando DSC(Distributed Services Card)的架构图,首先这是一个Host适配器。一端通过PCIe连接Host,一端通过Ethernet连接到网络。网络一般连接到TOR交换机。
最核心是一个支持P4数据面可编程的包处理器引擎。
在包处理引擎进行处理之后,发送的数据会转发到Packet Buffer用于发送;接收的数据则转发到主机。
此外,集成的高性能ARM Core也可以在必要的时候进行数据处理。例如,有些复杂的处理用ARM Core要更合适一些。以及其他一些卸载功能,如加解密等安全类这些数据处理密集型任务的加速,则是在Service处理卸载模块里进行处理。
就在上周,也就是2022年四月初,AMD宣布,已同初创企业Pensando达成了收购协议,这一收购将花费约19亿美元。
Pensando的相关技术和产品,将作为AMD数据中心解决方案的一部分,与AMD已有的CPU、GPU、FPGA(Xilinx)等产品线更深入协同。
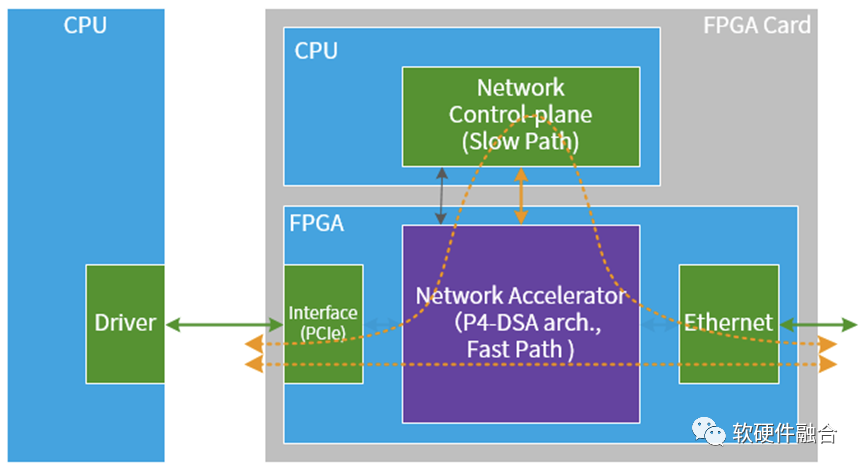
4、Intel IPU,集成Barefoot的P4网络可编程引擎
在2021年的Intel架构日大会上,芯片版本的IPU Mount Evans正式发布。Intel从为灵活性和可编程性而设计的创新性能硬件开始。
Intel还利用收购Barefoot时获得的专业知识,推动P4语言在业内的使用,作为将网络数据平面编程集成到IPU上的标准框架。
可编程包处理器为vSwitch卸载、防火墙、遥测功能等用例提供领先支持,同时在现实世界实现中支持高达每秒2亿个包的性能。
例如,
支持P4网络可编程的智能网卡,既可以实现包处理的极致性能,又可以实现软件编程实现(由用户自己决策)不同的网络转发功能。
-
如VPC虚拟私有网、4/7层负载均衡、接入网关、跨域网关、应用网关、防火墙、DDoS防护等。
-
如果通过纯CPU软件实现,
可能需要10-20台服务器实现的性能,通过支持P4加速的智能网卡,一台服务器可以胜任。
-
如果通过定制ASIC实现,
则可能需要很多不同功能的硬件设备,而支持P4加速的智能网卡则只需要一种硬件设备。
在SDN发展之前,网络芯片是一个紧耦合的ASIC芯片设计:
-
随着支持的网络协议越来越多,其复杂度急剧上升,使用门槛也越来越高。
-
此外,网络芯片提供了很多的协议支持,每个用户却只用到一小部分,这反而是一种资源浪费。
-
并且,完全硬件ASIC实现,上层的用户对网络没有太多的话语权,云计算厂家有一些网络的创新都非常困难。
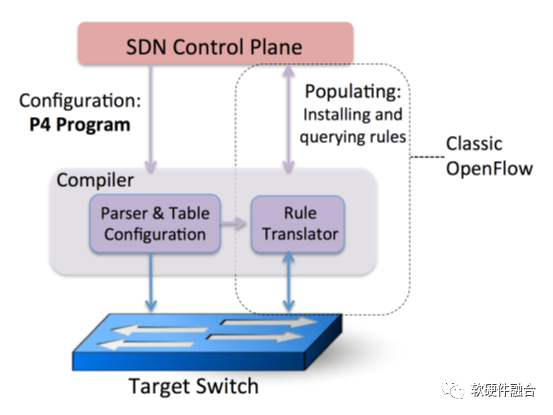
SDN最开始推出了控制面和数据面分离的Openflow标准协议,通过集中决策,再分发到分布式的支持SDN功能的交换机中。控制面可编程的Openflow并没有本质的解决网络的功能定制问题,更进一步的,支持数据面编程的P4语言以及网络包处理器/引擎,能够在达到ASIC级别性能的基础上仍然具有非常好的编程能力。
随着网络越来越复杂,网络协议越来越多,网络功能演进越来越快,ASIC层次的网络芯片,不但约束用户的功能创新,而且随着系统越来越冗杂性能效率也不是最高,越来越难以满足用户的需要。更合适的做法,就是“授人以鱼不如授人以渔”,把决策权交给开发者(用户)。
算力网络,是指在计算能力不断泛在化发展的基础上,通过网络手段将计算、存储等基础资源在云-边-端之间进行有效调配的方式,以此提升业务服务质量和用户的服务体验。随着边缘计算的发展和部署,用户不再是仅仅访问中心云,有的业务需要访问边缘云,甚至可能某个业务需要多云协同计算。
网络是用户去往算力资源的必经之路,也是用户发起业务需求的入口。由网络去调配算力,是个不错的方式,可以实现跨云访问。
算力网络要想在
性能极致的基础上,还能做到协议和策略可编程,则基于P4的可编程网络DSA技术是必由之路。
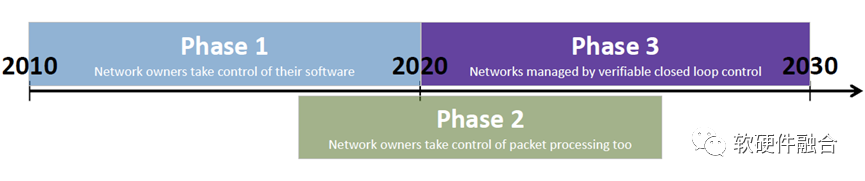
Nick McKeown 在 ONF Connect 2019演讲中第一次定义了SDN发展的三个阶段:
-
第一阶段(2010–2020年):通过Openflow将控制面和数据面分离,用户可以通过集中的控制端去控制每个交换机的行为;
-
第二阶段(2015–2025年):通过P4编程语言以及可编程FPGA或ASIC实现数据面可编程,这样,在包处理流水线加入一个新协议的支持,开发周期从数年降低到数周;
-
第三阶段(2020–2030年):展望未来,网卡、交换机以及协议栈均可编程,整个网络成为一个可编程平台。
这预示着,
未来不管是交换机侧还是网卡侧,均需要实现类似CPU通用程序设计的完全可编程的网络处理引擎,并且要基于此平台实现一整套的软件堆栈。
把一个完全可编程的网络交给用户,支撑用户更快速的网络创新。
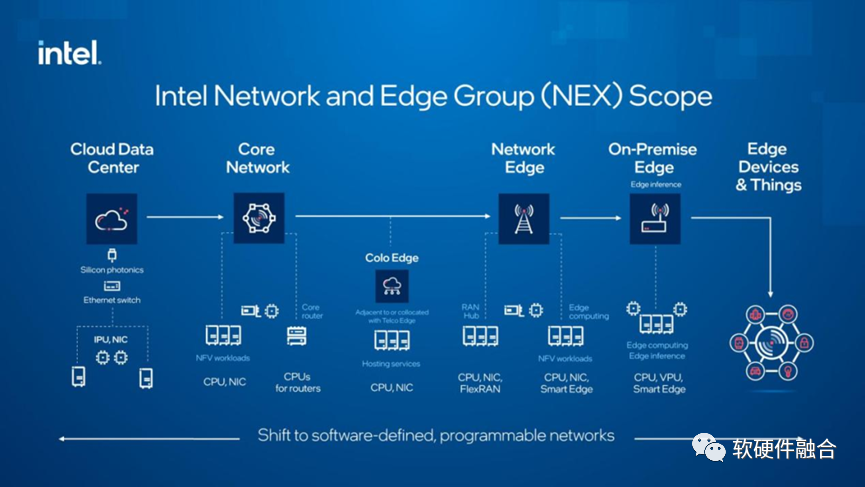
上图是Intel对整个未来网络演进趋势的看法:从云数据中心、核心网、接入网、边缘计算甚至终端设备,都会演化成完全“软件定义的可编程网络”。
网络可编程,本质上是聚焦在网络协议处理。而在更广阔的各类复杂计算场景,如云计算,
除了网络以外,其他的领域,包括存储、虚拟化、安全以及AI等,都需要极致性能基础上的可编程。
这些领域的系统,面临跟网络类似的问题:系统越来越复杂,性能要求越来越高,业务逻辑迭代越来越快。
随着CPU性能瓶颈,就需要为这些领域的任务进行加速。而不同用户业务的差异性,以及用户业务逻辑的快速迭代,以及越来越高的场景性能要求,诸多场景,都需要在完全ASIC极致性能的基础上,实现可编程能力。
这样,
整个系统,构成一个性能极致的、完全可编程的全领域处理(平台)。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第3007内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|集成电路|设备
|汽车芯片|存储|台积电|AI|封装
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!