为何都盯上了NPU?
2024-03-15
10:29:53
来源: 李寿鹏
点击
NPU,一个并不算新的概念,却在最近翻红。


例如,PC芯片大厂Intel和AMD在去年年底纷纷发布集成了NPU的处理器。按照英特尔的说法,到2028年,AI PC将占据PC市场的80%,而他们的处理器代表了公司在PC实现人工智能的规模和速度无与伦比;GPU大厂英伟达在今年二月底发布的全新笔记本电脑GPU中也集成了NPU,可以帮助卸载轻型AI任务;在更早之前,芯片供应商高通也强调,其发布的骁龙8gen3平台集成了性能更强的Hexagon NPU。
由此可见,几乎所有全球领先的处理器厂商都入局了NPU。究其背后原因,按照高通所说,这其实是人工智能产业发展的大势所趋。
人工智能需要NPU
因为ChatGPT和大模型的火热,每每谈到人工智能,我们首先想到的可能是英伟达这样的GPU厂商,或者是类似谷歌TPU这样的芯片。这些广为人知的芯片大多都是围绕着云端进行的。但其实在人工智能市场中,还有一大部分机会属于边缘端(或终端)。
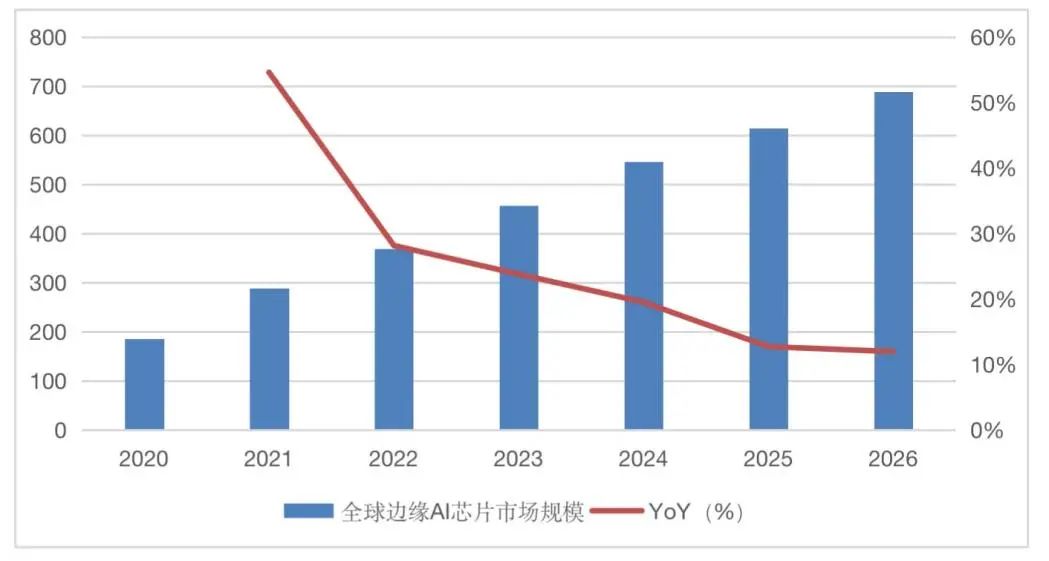
根据Gartner预测,2026年全球边缘AI芯片市场规模将达到688亿美元,2022-2026年CAGR将达到16.9%,这足以证明其市场潜力。然而,和云端AI不同,因为使用场景有限,边缘端AI在成本和功耗等方面也受到严格的限制。
在此背景下,高通提出的“混合AI”将成为AI的未来。
所谓混合AI,按照高通在《混合AI是AI的未来》白皮书中的定义,是指终端和云端协同工作,在适当的场景和时间下分配AI计算的工作负载,以提供更好的体验,并高效利用资源。在一些场景下,计算将主要以终端为中心,在必要时向云端分流任务。而在以云为中心的场景下,终端将根据自身能力,在可能的情况下从云端分担一些AI工作负载。
高通同时指出,随着生成式AI正以前所未有的速度发展以及计算需求的日益增长,AI处理必须分布在云端和终端进行,才能实现AI的规模化扩展并发挥其最大潜能——正如传统计算从大型主机和瘦客户端演变为当前云端和边缘终端相结合的模式。“与仅在云端进行处理不同,混合AI架构在云端和边缘终端之间分配并协调AI工作负载。云端和边缘终端如智能手机、汽车、个人电脑和物联网终端协同工作,能够实现更强大、更高效且高度优化的AI”,高通强调。
在高通看来,之所以需要“混合AI”,是因为AI推理的规模远高于AI训练,模型的推理成本将随着日活用户数量及使用频率的增加而增加。但在云端进行推理的成本极高,这将导致规模化扩展难以持续,而“混合AI”能够解决上述问题。除了具备上述的成本和功耗优势外,“混合AI”还拥有性能、隐私、安全和个性化等方面的优势。
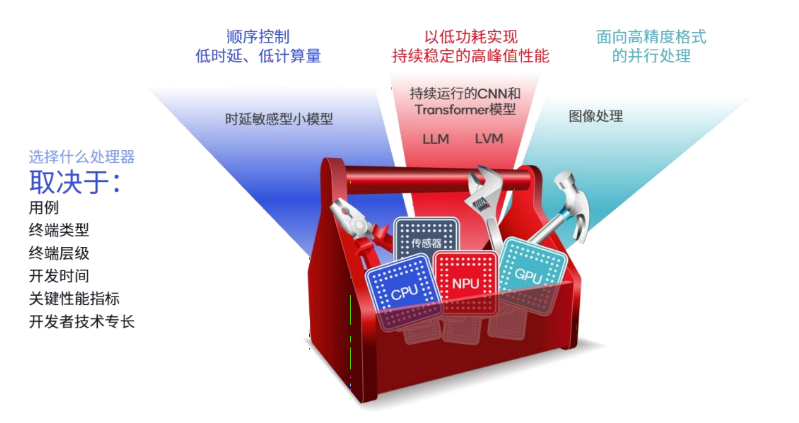
为了实现上述目标,高通提出需要一个专为边缘端AI设计的全新计算架构。这首先需要一个面向生成式AI全新设计的神经网络处理器(NPU),同时利用异构处理器组合(比如CPU和GPU)。通过结合NPU使用合适的处理器,异构计算能够实现最佳应用性能、能效和电池续航,赋能全新增强的生成式AI体验。
熟悉处理器的读者可能会知道,因为本身设计的不同,不同类型的处理器在实际的工作负载中能够扮演不同的角色。例如CPU擅长顺序控制和即时性,GPU适合并行数据流处理,NPU则擅长标量、向量和张量数学运算,可用于核心AI工作负载。
CPU和GPU大家耳熟能详,在这里就不再深入赘述。对于什么是NPU,不同厂商可能有不同的定义,但在高通看来,NPU是专为实现以低功耗加速AI推理而全新打造,其架构随着新AI算法、模型和用例的发展不断演进。Al工作负载主要包括由标量、向量和张量数学组成的神经网络层计算以及非线性激活函数。优秀的NPU设计能够为处理这些AI工作负载做出正确的设计选择,与AI行业方向保持高度一致。
NPU扮演重要角色
在谈论NPU的作用之前,我们首先还是需要对人工智能进行一些科普。
卷积网络之父Yann LeCun曾经在一篇科普文章中写道,AI是一门严谨的科学,专注于设计智能系统和智能机器,其中使用的算法技术在某些程度上借鉴了我们对大脑的了解。许多现代AI系统使用人工神经网络和计算机代码,模拟非常简单的、通过互相连接的单元组成的网络,有点像大脑中的神经元。这些网络可以通过修改单元之间的连接来学习经验,有点像人类和动物的大脑通过修改神经元之间的连接进行学习。
简而言之,人工智能大体上可以分为训练和推理两部分,本质在于对算法的执行。在其中的训练阶段因为需要大量的计算能力和内存,目前这部分主要是GPU的活,所以包括英伟达、英特尔和AMD等都是围绕着这类处理器展开争夺,其他类似Cerebra、Graphcore、和Habana(已经被Intel收购)等ASIC厂商也都在试图瓜分这个市场。
来到推理方面,涉及到云端推理和终端推理,NPU主要面向的是终端推理市场。
据高通在《通过NPU和异构计算开启终端侧生成式AI》白皮书(以下简称“NPU白皮书”)中介绍,早在2015年,NPU主要面向音频和语音AI用例而设计,这些用例基于简单卷积神经网络(CNN)并且主要需要标量和向量数学运算。从2016年开始,拍照和视频AI用例大受欢迎,出现了基于Transformer、循环神经网络(RNN)、长短期记忆网络(LSTM)和更高维度的卷积神经网络(CNN)等更复杂的全新模型。这些工作负载需要大量张量数学运算,因此NPU增加了张量加速器和卷积加速,让处理效率大幅提升。有了面向张量乘法的大共享內存配置和专用硬件,不仅能够显著提高性能,而且可以降低内存带宽占用和能耗。
在2023年,大语言模型(如Llama 2-7B)和大视觉模型(如Stable Diffusion)赋能的生成式AI使得典型模型的大小提升超过了一个数量级。除计算需求之外,还需要重点考虑内存和系统设计,通过减少内存数据传输以提高性能和能效。
展望未来,预计将会出现对更大规模模型和多模态模型的需求。因此,伴随着AI的快速演进发展,就必须在性能、功耗、效率、可编程性和面积之间进行权衡。而一个专用的定制化设计的NPU就能够做出正确的选择。
看到这里,也许有读者就会问,我们为何不做一个单独的芯片来做推理,而是专注于把NPU集成到一个SoC里面呢?要回答这个问题其实也很简单——因为AI负载多样化,而集成NPU的SoC是峰值性能、能效、单位面积、芯片尺寸和成本的最优解。
在上文中,我们谈到了CPU和GPU的“本职工作”:前者擅长顺序控制和即时性,后者适合并行数据流处理。而NPU的“本职工作”则是AI,降低相关工作的部分易编程性以实现更高的峰值性能、能效和面积效率,从而运行机器学习所需的大量乘法、加法和其他运算。
但是,我们还是要澄清一下,虽然CPU、GPU和NPU有各自擅长的任务,但具体到AI方面,除了NPU以外,其他的处理器也是能处理一些AI任务的。如CPU也适用于相对较小的传统模型,如卷积神经网络模型(CNN),或一些特定的大语言模型(LLM)。如果模型变大(如数十亿参数时),GPU或者NPU会更适合。
这就进一步证明——针对不同负载,集成多个处理器的SoC拥有先天优势。而这正是高通所擅长的。
5G+AI,赋能未来
高通在芯片方面的实力不用多言,骁龙芯片在全球范围的影响力能够说明一切。在NPU领域,高通也有着多年积累。早在2007年,高通首款Hexagon DSP在骁龙平台上正式亮相——DSP控制和标量架构也成为了高通未来多代NPU的基础。
高通技术公司产品管理高级副总裁Ziad Asghar同时指出,在最初开始研究NPU时,高通关注的是一些简单用例,主要包括面向音频和语音处理的卷积神经网络模型(Convolutional Neural Network,CNN)和长短期记忆网络模型(Long Short-Term Memory,LSTM)。高通在2015年推出的第一代高通AI引擎,其Hexagon NPU集成了标量和向量运算扩展。他们率先开始了这个领域的研究并积累了丰富的技术专长,让其能够以非常高效的方式进行标量和向量运算。
2016-2022年之间,高通将研究方向拓展至AI影像和视频处理,以实现增强的影像能力。从2023年开始,Hexagon NPU实现了对LLM和LVM的支持,高通也在NPU中增加了Transformer支持,以更好地处理基于Transformer的模型。
“现在,Hexagon NPU能够在终端侧运行高达100亿参数的模型,无论是首个token的生成速度还是每秒生成token的速率都处在业界领先水平。我们还引入了微切片推理技术,增加了能够支持所有引擎组件的大共享内存,以实现领先的LLM处理能力。”Ziad Asghar表示。
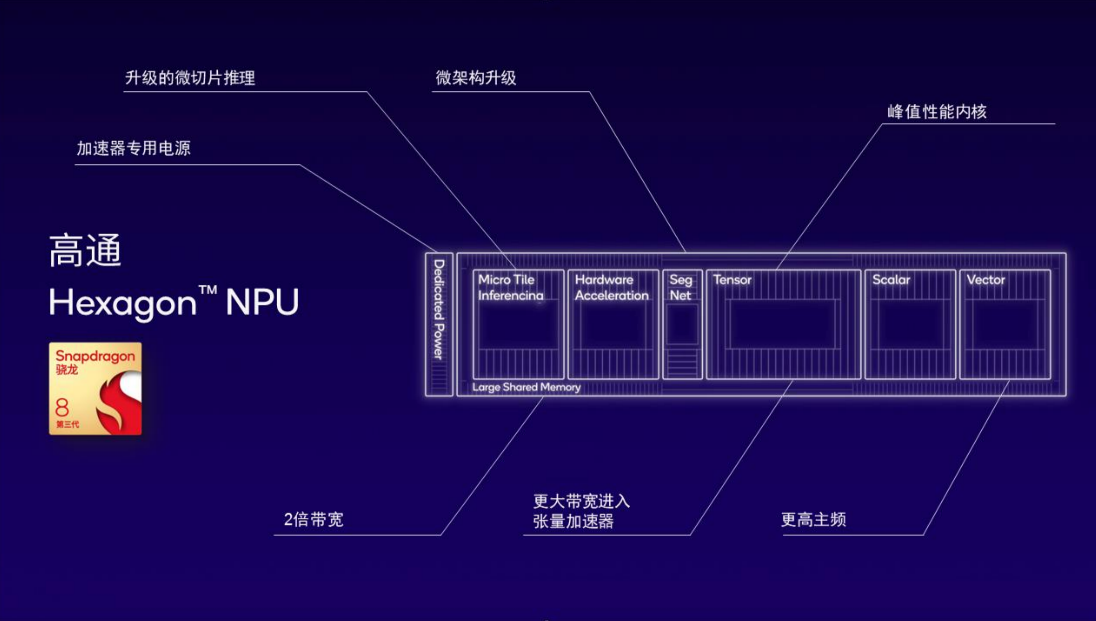
按照高通在“NPU白皮书”中所说,第三代骁龙8中的Hexagon NPU是高通面向生成式AI最新、也是目前最好的设计,为持续AI推理带来了98%的性能提升和40%的能效提升。它包括了跨整个NPU的微架构升级。微切片推理进一步升级,能够支持更高效的生成式AI处理,并降低内存带宽占用。此外,Hexagon张量加速器增加了独立的电源传输轨道,让需要不同标量、向量和张量处理规模的AI模型能够实现最高性能和效率。大共享内存的带宽也增加了一倍。基于以上提升和INT4硬件加速,Hexagon NPU成为面向终端侧生成式AI大模型推理的领先处理器。
“高通NPU的差异化优势在于系统级解决方案、定制设计和快速创新。通过定制设计NPU并控制指令集架构(ISA),高通能够快速进行设计演进和扩展,以解决瓶颈问题并优化性能。”高通总结说。
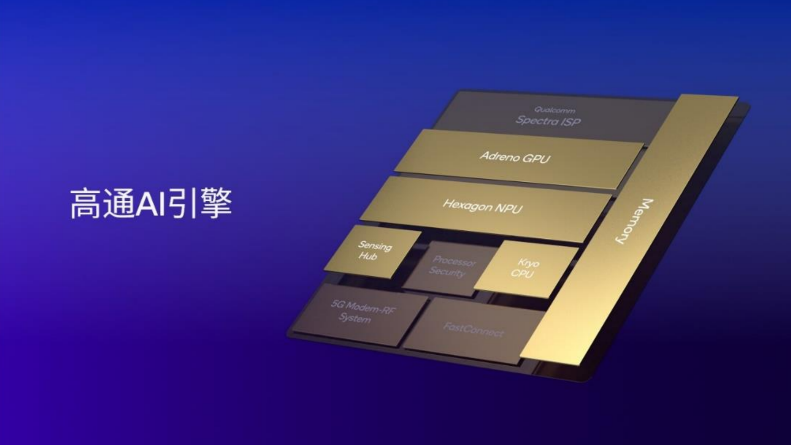
有了这个领先的NPU,加上高通本身在CPU和GPU上的积累,高通打造起了一个包括高通Hexagon NPU、高通Adreno GPU、高通Kryo或高通Oryon CPU、高通传感器中枢和内存子系统在内的高通AI引擎,这些处理器为实现协同工作而设计,能够在终端侧快速且高效地运行AI应用,使得在利用异构SoC执行AI任务方面如鱼得水。
于高通而言,除了这些领先的计算能力,公司本身在连接领域的积累,也让其在推动AI规模化扩展的时候,拥有其他竞争对手所不具备的优势。高通也曾强调,随着5G与终端侧AI的不断融合,企业数字化转型正在加速。高通也正在与众多合作伙伴一起,推动5G和AI与行业融合创新,加速迈向数字化未来。
在近期举办的MWC期间,高通带来了在终端侧AI、智能计算和无线连接领域的最新产品和里程碑,助力加速数字化转型、推动新一轮经济增长,并将AI和连接融合带入全新领域。其中,高通发布了公司第三代AI赋能的5G调制解调器骁龙X80,具备变革性的AI创新,能够助力提升数据传输速度,降低时延,扩大覆盖范围,提高服务质量(QoS)、定位精度、频谱效率、能效和多天线管理能力。高通还发布了首个支持AI优化的Wi-Fi 7系统FastConnect 7900,利用AI可适应特定用例和环境,有效优化能耗、网络时延和吞吐量。
为了更好地赋能开发者,高通在本届MWC上还带来了包含预优化AI模型库的全新高通AI Hub。按照高通所说,AI Hub支持在搭载骁龙和高通平台的终端上进行无缝部署。该模型库为开发者提供超过75个主流的AI和生成式AI模型,比如Whisper、ControlNet、Stable Diffusion和Baichuan-7B,可在不同执行环境(runtime)中打包,能够在不同形态终端中实现卓越的终端侧AI性能、降低内存占用并提升能效。
最后,需要强调的是,高通的这些计算能力和连接能力并不仅仅局限于手机端。高通在去年底也发布了专为AI PC打造的骁龙X Elite平台,能够支持在终端侧运行超过130亿参数的生成式AI模型,AI处理速度是竞品的4.5倍。多年的积累和坚实的技术底座也让高通能够跨公司所有不同产品线,将无线连接、终端侧AI和高性能低功耗计算规模化扩展到不同类型的终端,从智能手机到PC、物联网终端、汽车等等。
在高通看来,终端侧生成式AI正为用户带来强大、快速、个性化、高效、安全和高度优化的体验,改变人们的工作、娱乐和生活方式,并为各行各业带来广阔的发展机遇。在这一过程中,高通当仁不让地扮演着赋能者的角色。
责任编辑:sophie
相关文章


©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号