
什么是机器学习?
机器学习是人工智能在近期最重要的发展之一 。机器学习的理念是,不将智能看作是给机器传授东西,而是机器会自己学习东西。这样一来,机器就可以直接从经验 (或数据)中 学习如何处理复杂的任务。

-
即使是相对简单的机器学习算法也可以学习如何区分猫和狗的图片。
随着计算速度和用于编程的算法的巨大进步与发展,机器学习成长迅速。由此产生的算法对我们的生活开始产生重大影响,而且它们的表现往往胜过人类。那么,机器学习是如何工作的呢?
从经验中学习
在机器学习系统中,计算机通常是通过在相同任务的大型数据库中进行训练,然后自己编写代码去执行一项任务。其中很大一部分涉及到识别这些任务中的 模式 ,然后根据这些模式做出决策。
举个例子,假设一家公司正要招聘一名新员工,在招聘广告登出之后有1000个人申请,每个人都投了简历。如果要亲自一个个筛选,这实在太多了,所以你想训练一台机器来完成这项任务。
为了做到这一点,你需要把公司过往的许多应聘者的简历都记录下来。对于每一份简历,你都有记录表明这个人是否最终被聘用了。为了训练机器,你拿出一半的简历,让机器通过学习这些简历最终是否成功地申请到了一份工作来找出其中的模式。
这样一来,当机器收收到一份简历时,它就可以对这个人是否适合被雇佣做出判断。训练完毕,就可以接着用另一半简历来对机器进行测试。如果它的成功率足够高,也就是机器做出正确判断的概率够高,那么你就可以安心地让机器根据一个人的简历来判断他是否适合被聘用。在任何阶段都不需要人的判断。
具体细节
为了更清楚地理解机器学习的过程,我们将以开发能够识别手写数字的机器为具体例子来考虑模式识别的问题。这样的机器应该能够准确识别一个字符所代表的数字,而无论它的书写格式如何变化。
数字识别的过程分为两个阶段。首先,我们必须能够将手写数字的图像扫描到机器中,并从这张 (数字)图像 中提取出有意义的数据。这通常是通过 主成分分析 (PCA)的 统计方法实现的,这种方法会自动提取图像中的主要特征,例如图像的长度、宽度、线条的交点等。这个过程与求解矩阵的本征值和本征向量的过程密切相关,也与谷歌用来在万维网上搜索信息的过程非常相似。
然后,我们想训练机器从这些提取的特征中识别数字。一种非常主流的用来训练机器的方法是 神经网络 。神经网络算法的最初灵感来源是我们认为的人类大脑的工作方式,但并不严格地建立在我们认为的人类大脑的工作方式之上。
首先要创建一组“ 神经元 ”,并将它们连接起来,它们可以相互发送消息。接下来,让神经网络去解决大量已经知道结果的问题,这样做能让算法“学习”到应该如何确定神经元之间的连接,以便能成功地识别出数据中的哪些模式导致了正确的结果。
这种神经网络的一个早期例子是一种叫做 感知机 的单层系统,人们用它来模拟单个神经元。感知机的概念是由Frank Rosenblatt在1962年提出的,它的典型结构如下图所示:
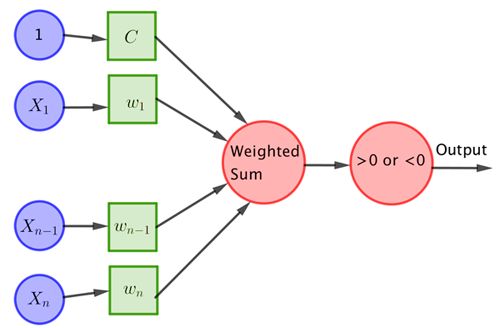
向感知机输入n个数字X 1 、 X 2 ...... X n 。然后将每个 X i 乘以一个加权w i ,并将所有这些乘积相加,得到它们的和
w₁X 1 + w₂ X 2 +...+ w n X n
如果这个和大于某个阈值C,则返回1,其他情况则返回0。也就是说,如果
w₁ X 1 + w₂ X 2 + ... + w n X n -C > 0,
那么,感知机返回1;如果
w₁ X 1 + w₂ X 2 + ... + w n X n - C ≤ 0,
那么感知机返回0。
对于数字识别问题,数字图像的提取特征就是输入 X i ,感知机的判断是,这个数字是3还是4。训练感知机的过程包括要找到合适的加权 w i 和阈值C,使得感知机能够始终如一地识别出正确的数字。要做到这一点,需要谨慎使用基于统计的数学优化算法。
举例:数字识别
例如,假设我们仅从图像中提取两个特性: X 1 和 X 2 ,其中 X 1 可能计算图像中直线的数量, X 2 能计算图像中线条交叉的次数。
现在,每个手写数 字(比如3或4)的图像都有两个数字来描述,因而可以定位在一个坐标系中。由于数字3通常没有直线段,也没有交叉线,它的图像很可能对应于坐标系中接近 (0,0) 的点。数字4有三条直线段和1个交叉点,它的图像可能在点 (3,1) 附近。
对于给定的w₁、w₂和C,感知机中的和是
w₁X 1 +w₂X 2 -C,
让这个式子等于0就定义了一条直线。 如果感知机能用训练的图像找到 w₁ 、 w₂ 和C的值,使得这条直线将所有对应于数字3的点与所有对应于数字4的点分隔开来,那么,它也就有很大的概率能够正确识别出新的数字图像。如果存在这样一条直线,则称数据是线性可分的。
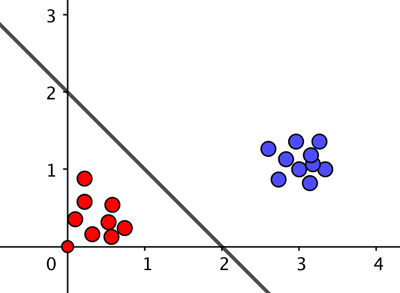
-
假设图中红色的点来自代表数字3的图像,蓝色的点来自代表数字4的图像。如果算法使用C=2, X 1 = X 2 =1,则加权后的和等于0对应于图中的直线( w₁ + w ₂ -2=0)。对于蓝色的数据点,加权和大于零,对于红色的数据点,加权和小于零,所以算法总是会给出这个数据集的正确答案。
如果数据点不能被一条直线分割,也就是说,数据不是线性可分的,那么可以把这些点扩展到一个更高的维度,并寄希望于在更高维空间它们是线性可分的。一个非常简单的例子是,你可以将图中的点拖拽出屏幕到第三个维度,拖拽的距离对应于它们到点 (0,0) 的初始距离。但是,通常会使用的是更复杂的方法。当然,如果从原始数据中提取的特征是两个以上,那么就可以在更高维度上使用类似的方法。
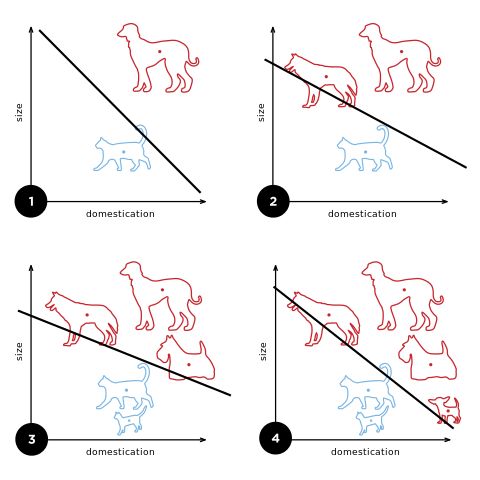
感知机方法也可以用于对猫和狗的图像进行分类:
-
随着训练数据的增加,算法会更新其选择的直线,也就是会改变常数C和加权 w₁ 、 w ₂ 的数值。
神经网络和深度学习
简单的感知机可以被训练来完成许多简单的任务,但很快就会达到极限。显然,将许多感知机耦合在一起就可以进行更多的计算,但这一发展必须等待更强大的计算机的出现。当多层感知机耦合起来形成一个神经网络时,这一重大突破就出现了。这种神经网络的典型结构如下图所示,它包括输入层、隐藏层和输出层。在这种情况下,输入会组合起来以触发感知机的第一层神经元,由此产生的输出也会组合起来以触发下一层神经元,最后,这些组合起来给出最终的输出。
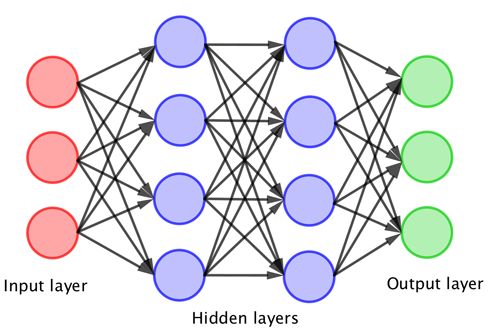
层数越多,神经网络就越“深”。然后,这样一个神经网络就会通过为上面的神经元之间的每个连接分配加权而得到训练。这个过程是为了模仿大脑神经通路强化或衰减的方式。深度学习描述了训练这样一个神经网络的过程。
事实上,神经网络算法之所以可能实现,是由新的数学优化算法的发展与强大的计算能力结合的结果。在为神经网络寻找合适的加权w i 的过程结束之时,我们得到了一个黑箱,它可以非常快速地运行并做出“决策”。
不同的机器学习方法
神经网络学习的过程有多种形式。
在监督学习中,用户会事先提供一组成对的实例,也就是输入和输出。然后,学习的目标是找到一个给出的输出能与实例匹配的神经网络。通常,用来比较神经网络的输出与实例的输出的方法是计算两者的均方误差;然后对网络进行训练,让这一误差对所有训练数据集最小化。这种方法的一个非常标准的应用是在统计学中使用的曲线拟合,它对手写数字和其他的模式识别问题都有很好的效果。
在强化学习中,数据不会由用户事先给出,而是由神经网络控制的机器与环境交互作用时生成的。机器会在每个时间点上对环境执行一个操作,由此生成一个观察结果,以及这个操作的成本。然后训练这个神经网络去选择那些将总体成本降至最低的操作。在许多方面,这个过程类似于人类 (尤其是小孩子)学习的方式。
近年来,机器学习的数学算法有了很大的发展。 卷积神经网络 (CNNs) 就是一种令人兴奋的、重要的新发展,它是对那些将图像处理技术与深度神经网络结合的方法的扩展,可以应用于人脸识别,甚至可以用来检测情绪,现在还被用于包括医学诊断在内的许多其他领域。
为了更好地学习下国际象棋,AlphaZero使用了深度卷积神经网络。它的训练是通过强化学习的方法,让机器在24小时内与自己对弈70万局。过程中采用一种通用的 蒙特卡罗树搜索 (MCTS)算法来分配加权。在学习下围棋和日本将棋时采用的也是类似的方法,而且 在每种情况下都达到了相似的水平。这是非常了不起的!
机器学习进展迅速,在更快的训练算法和越来越多的数据的驱动下,发展更复杂、更深层神经网络的趋势越来越明显。但或许我们需要思考的问题是,把可能改变生命的决定 (如医学诊断)留给机器,这样做安全且合乎道德吗?


©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号