
ISSCC 2019论文解析(一)高速接口
ISSCC2019论文解析目录:
1、Session 6 Ultra-High-Speed Wireline
ISSCC会议在集成电路设计的地位无容置疑。ISSCC2019刚刚结束,接下来我将在公众号开启一个新的系列,跟大家一起来读今年的ISSCC论文。今天先来看看第6个session Ultra-High-Speed Wireline都讲了些什么。
(此文有4500字,干货满满,可分多次阅读)
▼
在今年的ISSCC上, 高速接口(wireline)方向受到了极大的关注 。除了有两个session的论文,在傍晚的现场展示环节,据我目测除了AI相关的芯片之外,最多的就是高速接口了,同时第一天的tutorial和最后一天的forum,也各有一个与高速串口相关。
我觉得这种火爆状态会持续好几年。 预测是否能保持火爆可以看两方面:一是需求是否在持续增长。这点无容置疑,现在的5G、AI芯片、数据中心、大型交换机都需要传输大量的数据,有数据传输的地方就需要高速串口。 高速接口芯片作为基本的数据接口,在一个大系统里必不可少,且不与5G、AI等热点技术构成竞争关系,反而受到这些技术发展的带动。 二是现有的技术是否已经能够满足多年内的需求。目前来看, 现在的高速接口芯片还没有达到这一点,在能耗和最高的数据率上还有不少提高空间。
从这个session的论文,我们可以看到几点整体发展趋势:
1) 尽管56G的市场出货量还没有起来,但业界已经开始了单通道112G的高速接口收发机设计。 这是竞争带来的结果,每个公司都尽力往前冲,不进则退,目前并没有看到谁有不可超越的技术优势,那出货时间就显得很重要了。当初我在设计56G的时候觉得,112G速度直接翻了一倍,做起来得有多难,真正做起112G时又觉得难归难,但设计出来还可以。
2)高速接口这个方向非常非常非常吃先进工艺。 这个session八篇论文,除了最后两篇学校的论文,均采用16/14nm或者7nm的FinFET工艺。一方面,高速接口电路优化到最后,速度的天花板由工艺的极限决定,不采用先进工艺没有办法跟别人竞争。另一方面,高速接口的很多应用场景都是作为IP集成在一个更大的芯片之间,选择工艺时需要考虑主流客户会使用什么工艺,否则别人没法用你的IP。
3)由于太吃先进工艺,成本实在太高,学校已经很难在高速串口方面做出太多成果,主要的论文都是来自于工业界。 业界玩家主要有博通、英特尔、inphi、xilinx、Nvidia等等,还有就是像我所在公司这样的初创公司。博通大概是做的最好的,但是价格也贵。xilinx和Nvidia主要给自家做,不卖IP。市场上的IP供应选择并不太多。
4)从技术上来说,56G的高速接口架构已经较为稳定 ,主流选择是:RX基于DSP,Time Interleaved ADC,一般先4到8的Track/Hold,每个Track/Hold带若干个ADC的Slice,TX采用Half Rate。均衡方面差不多都是CTLE、1-TAP DFE、若干TAP的FIR,以及TX-FFE。那56G接下来的技术挑战就是低功耗、以及更强大的Adaptive功能。 对于112G的高速接口,我觉得现在大家追求的目标是先做出来再说 ,功耗什么的留给以后再优化,在架构选择上可以看到一些趋势,但还没有稳定下来。
这个Session一共八篇论文,其中三篇56G,四篇112G。下面我们来看看每篇论文具体做了些什么。
1) 100Gb/s 1.1pJ/b RX from IBM Zurich
这是我看到的第二篇超过单通道100Gb/s的RX论文,上一篇是Xilinx发在2018年的VLSI上,但这篇的能量效率比上一篇要小不少。
除了速度快之外, 这篇最主要的亮点在于做了1-TAP Speculation的DFE。 Speculation是常见的提高DFE速度的方案,对于NRZ信号来说还好,代价不算特别大。但对于PAM4,直接做Speculation的话需要12个比较器,额外的硬件代价比较大,所以PAM4 DFE speculation一直是个难点。这篇通过1+0.5D的脉冲响应,将比较器的数目从12个降低到了8个,起到节省功耗的目的。 但这样做的局限在于,需要预先通过CTLE将channel的响应将将好调到1+0.5D,一般CTLE的可调范围都有限,这点在实际的使用环境下可能做不到。 现场有人问这个问题,如果channel loss很小,怎么实现1+0.5D的响应。作者回答说假如channel loss很小,他们可以把DFE关掉,不用DFE。
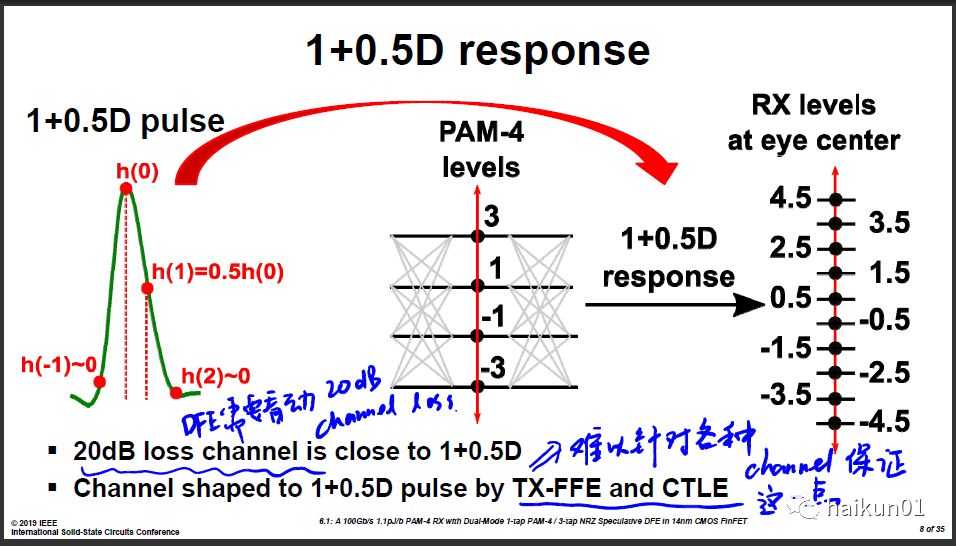
我不确定产品中是否会喜欢这种方法。我觉得工程设计中存在这样的准则: 假如一个较简单的方案已经能够达到可接受的效果,那就不要使用更复杂的方案,因为复杂本身就是成本。
整个接收机的系统框图如下。整体来看,采用了quad rate方案,降低时钟分布功耗。VGA直接驱动32个比较器,没有用Track/Hold,这里负载会稍微大一点,估计会成为带宽的瓶颈,因此这里加了一个电感拓展带宽。SR出来之后还是4UI(25G)的高速数据,DSP是处理不了,通过DMUX降速到32UI再给DSP处理。CTLE里没有使用电感,这点很厉害,但是论文里没有给出CTLE单独的测试结果。芯片的完成度还不太高,最终采用探针台进行测试。
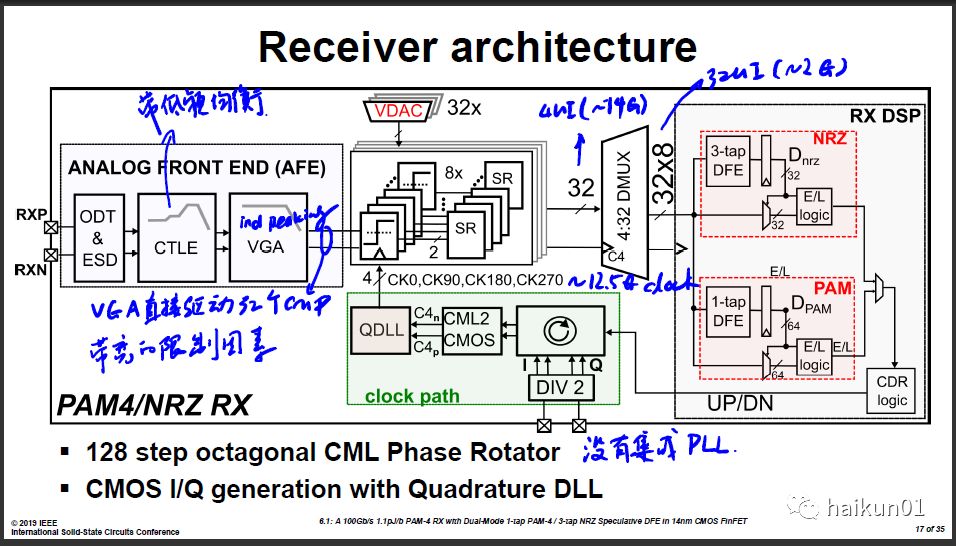
2)60Gb/s DSP Based TRX from Huawei Canada
这是一篇来自华为加拿大研究所的文章。
整体采用了较为通用的结构,接收端CTLE接4-路Time Interleaved的ADC,每路Track Hold驱动8个SAR ADC(2-7b可调),这差不多是基于DSP的56Gb/s RX的标准做法了。发射端采用Half Rate,带Phase Interpolator,3个Tap的FFE,这些都是业界常用。
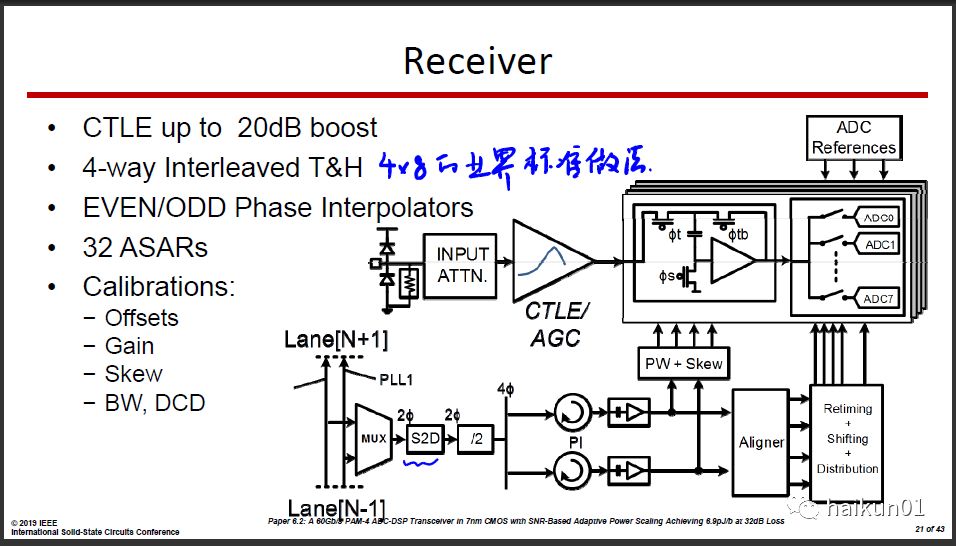
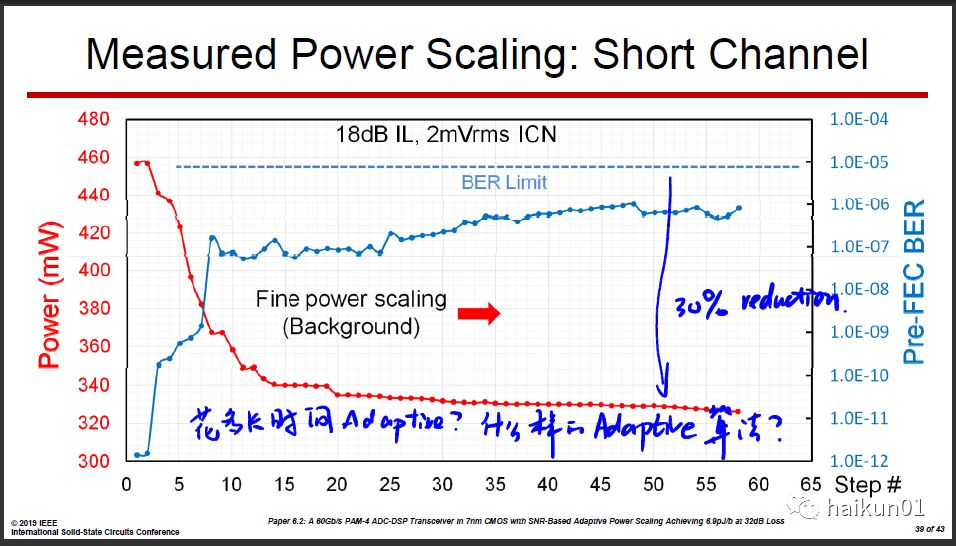
这篇文章的亮点在于芯片上集成了巨多的传感器(温度、工艺、阈值电压等等)、可调电路,理论上可以针对不同的channel、环境和BER要求去优化功耗。 去年的ISSCC也有一篇类似的思路,通过改变Flash ADC的位数来调整Power/BER trade-off,感兴趣可以去看看。华为的这篇可调的位置更多,完成度也更高, 最后给的测试结果表明通过Adaptive大约可以降低30%的功耗。
但我有两点疑问。 一是成本问题。 在模拟电路里,尤其是高速电路,每一个可调都是有成本的,晶体管开关总会引入额外的寄生电容寄生电阻,在这颗芯片里这个成本有多大?相比带来的好处值不值?论文里没有给出具体的数值,因此光看论文很难得出结论。 二是Adaptive算法问题。 这里面的调节点位实在太多了,而且很多是不相关的,需要处理工艺、温度、channel损耗、BER等等,怎么做Adaptive?这么大的扫描空间,如果暴力扫描,那握手时间太长了,肯定没法用。如果用一些策略,那会不会困在某个局部坏点出不来?如果不能很鲁棒的Adaptive,那实用价值就少了很多。可惜这些数据同样不可能从论文中看到。
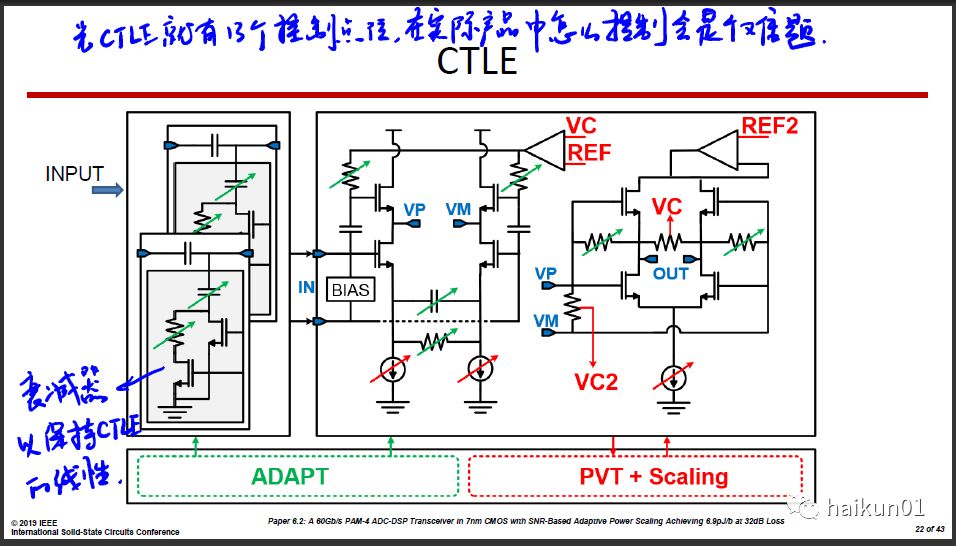
还有一点,这篇的全局时钟采用单端反相器来传,应该可以省一些功耗。但似乎这样用的很少,一般都是两根线传差分时钟,理论上对电源地噪声较好,而且对Return Path要求也较低。
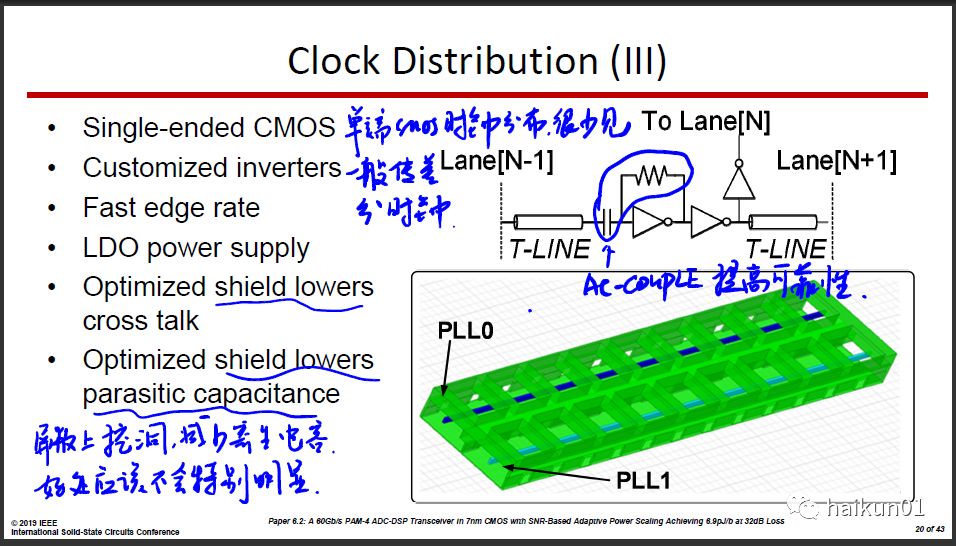
3-4)56Gb/s DSP Based TRX from eSilicon and MediaTek
这两篇论文较为类似,都是采用7nm的DSP Based 56Gb/s Transceiver。 他们的结构也是很常用的结构 ,从论文上来看没有太多可说的。假如现在让我来做一个新的56G系统规划,我也会选这两种结构中的一种。 但他们的功耗都做得极为出色,eSilicon的单通道功耗才243mW,MediaTek的只给出了模拟部分的功耗,才180mW,充分展示了这两个公司的设计优化能力。
有一点有趣的地方是:MediaTek在RX端使用了4x8(4个Track/Hold,每个驱动8个SAR ADC Slice)的结构,这种是最常见的选择。而eSilicon选择了8x5(8个Track/Hold,每个驱动5个SAR ADC Slice),这样他需要8个相位的8UI时钟,在时钟校准稍微复杂一点,一共8个Track/Hold,对前面CTLE引入的负载电容可能稍大,但每个Track/Hold的尺寸可以较小,每个Track/Hold有较长的时间来充放电。
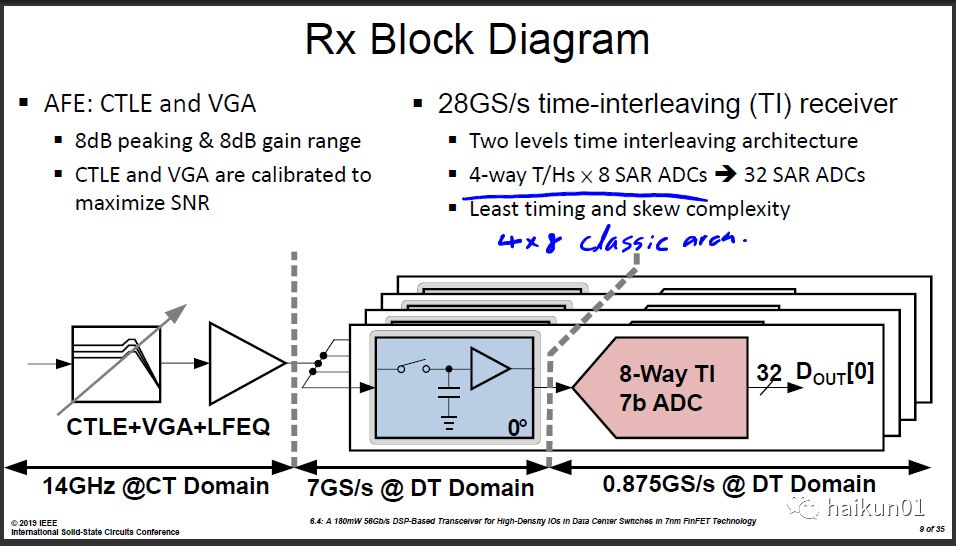
最终哪一种结构较好?我可能倾向于4x8。 但类似这种问题,似乎很难得到直接的证明。架构的比较取决于太多因素了。 我们很少有机会把两种架构都做成芯片,去测他们的性能直接对比。 即使一种架构的测试结果稍好,那也有可能是这一组人的优化能力较强,不能直接证明架构的优势。 最终只能从架构的演化趋势看出一点端倪。
5)100Gb/s PAM4 TRX from Inphi
又是一篇超过单通道100Gb/s的TRX,而且采用了DSP Based。
DSP based的100Gb/s的RX难点之一是ADC怎么选。 56Gb/s常用的是4x8的结构,这样一个Slice的速度差不多875MHz。到了112G,Slice本身的速度很难翻一倍,那只能采用 空间换时间 的策略,用更多路的time interleaved ADC来达到整体更高的速度。那么总共需要64个slice,这64个slice怎么分配呢,8x8还是16x4?这么大的寄生电容怎么来驱动?是一个超大的Buffer一起驱动这8个Track/Hold,还是分两级?去年xilinx的112G RX论文就是一个大buffer驱动4个第二级buffer,然后每一个在驱动两个Track/Hold。最终哪一种结构会胜出成为主流,现在还很难讲。因为现在能做出112G的还太少了。
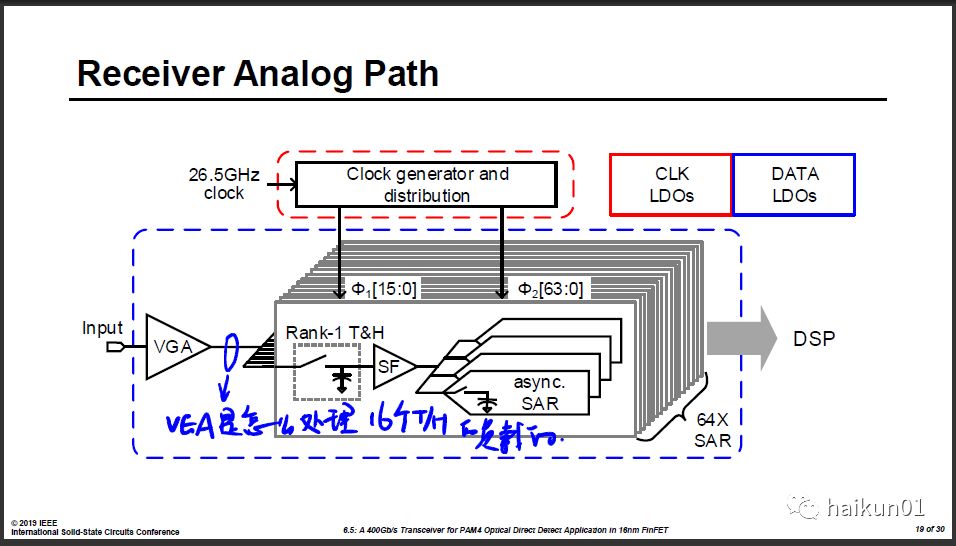
这篇inphi的论文在RX端选择了16x4的结构,这样VGA需要推动16个Track/Hold ,而且从他的图中VGA还没有用电感拓展带宽,我不知道他是怎么神奇的做出这么宽带宽的。
100G的RX另一个难点是CTLE,又要宽带、又要Peaking可调、又要保持线性度,设计难度很高。这篇里面没有集成CTLE。
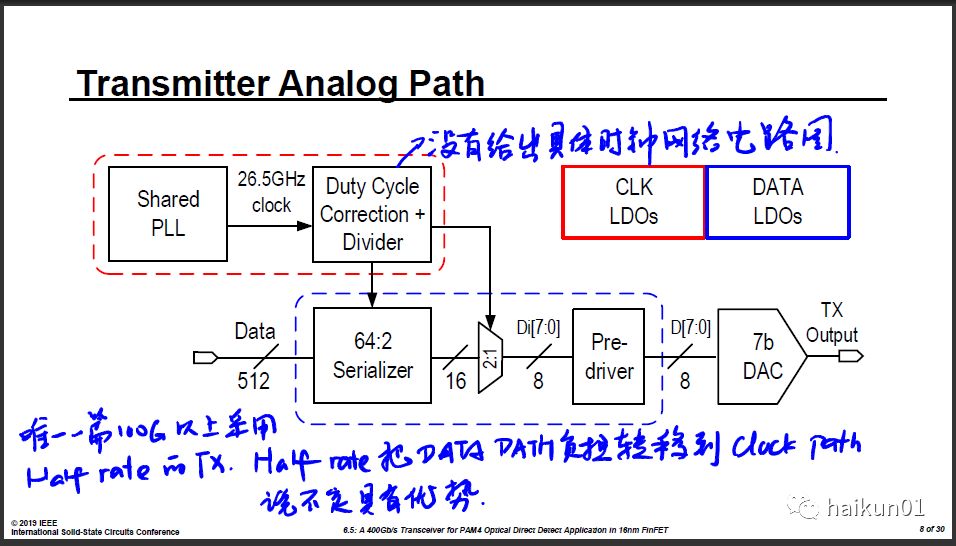
TX方面这篇选择了Half Rate结构,这是在超过100G的TX里唯一一篇Half Rate的结构。 Half Rate和Quad Rate相比,时钟的频率更高,因此更难传输。但是它简化了MUX的设计,最后一级MUX是只需要2:1即可,这是TX里速度最高的节点,2:1相比于4:1可以减小很多寄生电容。尽管大部分100G TX选择了Quad Rate,但我觉得不一定就比Half Rate有优势。 毕竟时钟通路只需要单频(窄带)即可,而数据通路是宽带的。窄带电路比宽带电路容易设计多了。这样Half Rate实际上是把宽带通路上的负担转移到窄带上来,应该带来优势才对。 一般说传25GHz的时钟太费电,但如果可以加电感和传输线做谐振的话,其实时钟传输网络耗电量不会特别大。可惜这篇没有给出时钟和MUX电路的具体实现。
TX里还用到了一个小技术,通过正反馈来提高反相器的速度,使上升下降沿更陡峭,其实有点类似均衡的概念。去年ISSCC有两篇采用了类似做法。我仿过这样的结构,应该是有效的,但要消耗更多功耗。
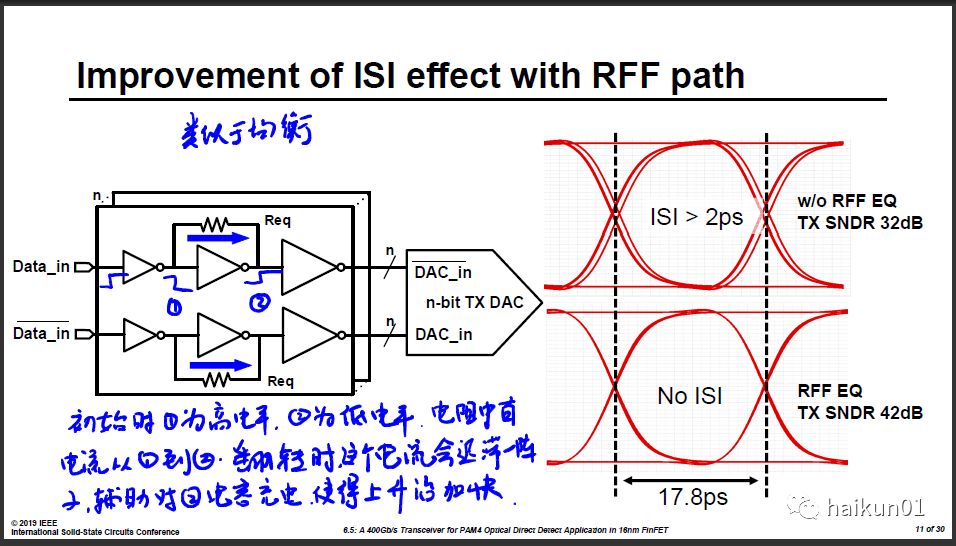
6)128Gb/s TX from IBM
这篇的亮点在于对4:1 MUX的优化。TX的结构和去年Intel的112G比较接近,也是采用CML的Driver。提一句,在56G采用SST作为TX Driver的居多。
高速串口的TX基本上就是一个Serilizer再加一个Driver。越往前速度越低,所以我们应该尽量简化后级,把负担推往前级速度比较低比较好处理的地方。这篇大致是这个思路。在MUX这一级去掉了Stack的时钟晶体管,而在前级添加一些逻辑产生1UI的脉冲信号。
很多时候电路的优化都是在一个个trade-off之间做取舍。宏观的指导思想就是把负担留给更容易解决的地方去解决。这篇是把负担推向前级速度较慢的电路,上一篇是把负担推向窄带的时钟路径。
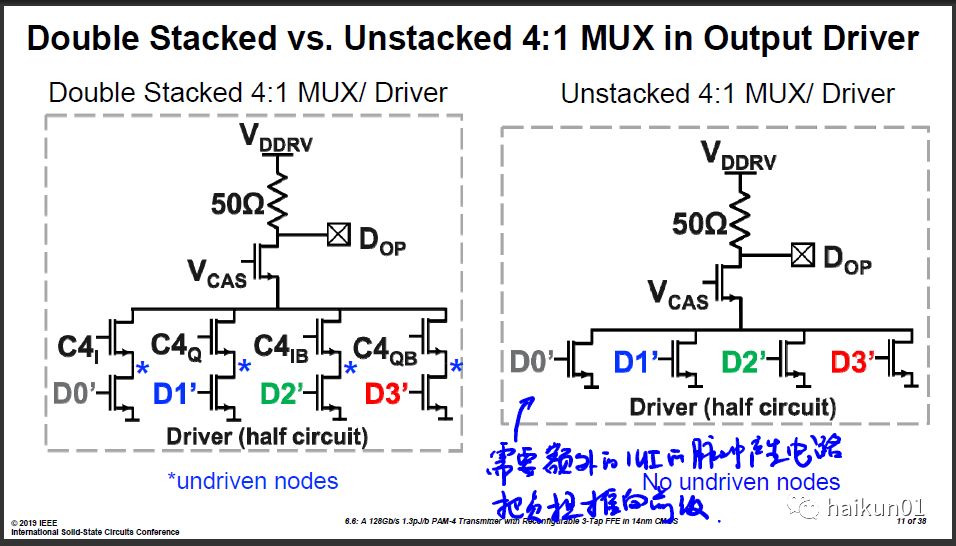
7)112G TX in 40nm CMOS from Yuan Ze University
这是来自台湾学术界的一篇论文,用40nm做出了112G的TX,非常令人印象深刻。话说我跟此文作者之前认识,碰过几次面,还一起流过一次片。 这篇论文即反映了学术界的无奈也反映了学术界应该选的方向。无奈在于拿不到/负担不起最先进的工艺,只能在落后工艺下进行竞争;方向在于学术界还是应该追求极致优化,以展现技术为主。
凭空想一想,假如让我在学校设计112G的TX的话:第一,FFE是必须的,否则眼睛打不开,没法展现效果;第二,不要在乎可靠性,选择金属走线宽度时只考虑性能因素,宁愿线被烧断也要减小寄生电容;第三,不要选择TX-DAC的结构,或者不要使用thermal code结构,将小cell合并成大cell,牺牲匹配换取速度;第四,适当的提高电源电压;第五,只在低速点位设置可调,如偏置电压等等,我们负担不起在高速路径上可调的成本。有了这些,应该勉强可以用落后工艺去拼一拼速度吧……
8)36Gb/s Adaptive CDR from University of Toronto
这篇略过……
写到这里,相信大家也看出来了,我之前本来是做射频毫米波的,现在对高速接口也有了不少了解。这不得不感谢 我现在所在的公司—— eTopus Technology Inc. ,我在这里面学到了很多高速接口的电路设计经验。



©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号