
FPGA在微软数据中心的前世今生
2014年,微软在计算机架构领域的顶会ISCA上发表了一篇名为“A Reconfigurable Fabric for Accelerating Large-Scale Datacenter Services”的论文, 详细介绍了微软Catapult项目团队如何在其数据中心里的1632台服务器中部署了英特尔Stratix V FPGA,并用FPGA对必应(Bing)搜索引擎的文件排名运算进行了硬件加速, 得到了高达95%的吞吐量提升 。

这篇文章一经发表,立刻轰动了整个业界。它是第一篇真正意义上详述由互联网/软件巨头开发并部署FPGA的专业论文, 标志着FPGA第一次在互联网/软件公司的大型数据中心里得到实质性应用 。
这篇文章正式将微软Catapult项目引入大众的视野,并向人们传达着一个重要的信息,那就是FPGA已不再仅仅是硬件公司的专属产品,而是可以有效的应用于像微软这样的互联网公司,并有机会部署在谷歌、亚马逊、脸书、阿里、百度、腾讯等其他互联网巨头遍布全球的成千上万台服务器中。
Catapult项目的产生背景
微软对FPGA在数据中心里应用的研究起源于2010年底,当时微软正希望从一个基于PC软件的公司,逐步转型为提供各类互联网服务的企业。Catapult项目的负责人Doug Burger认识到, 像微软这种体量的互联网巨头不能只提供软件层面的互联网服务,还要从根本上掌控最高效的网络硬件设备 。
随着大数据时代的到来,包括人工智能在内的各类新应用不断涌现,网络带宽也由1Gbps不断增长为10Gbps、40Gbps直至100Gbps甚至更高。此时,传统的基于CPU的服务器和网络设备已无法满足日益增长的对计算量和网络带宽的需求。因此,寻找合适的网络加速设备势在必行。
虽然在很多微软高管看来,微软自研网络硬件设备就好比“可口可乐宣布要做鱼翅”,但Doug Burger还是得到了当时担任必应(Bing)搜索引擎负责人陆奇的鼎力支持,并最终向时任微软CEO鲍尔默及其继任者纳德拉展示了FPGA在加速数据中心实际应用时的巨大潜力。

Catapult团队
Catapult项目的三个阶段
时间来到2016年,微软在计算机体系架构顶会MICRO上发表了名为“A Cloud-Scale Acceleration Architecture”的论文,系统介绍了Catapult的新一代架构和工作。至此,Catapult项目已经历三个阶段。
第一阶段:单板多FPGA
在Catapult项目最初期,微软采用了单板多FPGA的方案,即每块加速卡上集成6片Xilinx Virtix-6 FPGA,各FPGA之间通过自身的通用I/O端口相连和通信,如下图所示。

然而,这种大型加速卡在实际部署时遇到了很多问题,最主要的有以下三点:
1、灵活性极差 。如果某种大型应用需要多于6片FPGA,则无法用该方案实现。同样的,如果一个应用只需要少量FPGA,甚至只需要单一FPGA的一部分,板卡的FPGA资源就相当于被浪费掉了。另外,这个加速卡除PCIe接口外,没有任何网络接口,因此板卡之间的通信带宽势必会受到很大限制。这样基本无法将单一应用应设在多块板卡上。
2、同构性极差 。由于功耗、供电和尺寸限制,这种大型板卡很难直接部署在数据中心的高密度服务器上。因此需要采购和配置额外的服务器,以适配该板卡,或者重新设计整个数据中心服务器集群的硬件架构。这显然是本末倒置、不切实际的。
3、稳定性不足 。在这种大型板卡中,任何元件发生故障都有可能造成整个板卡的失效,继而可能导致相关服务器和应用的错误。这是数据中心运行过程中不允许出现的。
鉴于这些主要问题,项目进行了较大的架构改动,并进入到下一个阶段。
第二阶段:单板单FPGA
这个阶段的工作是Catapult项目第一个代表性成果。与前一阶段相比,加速卡架构从单板多FPGA,变成了单板单FPGA的结构,如下图所示。

每个第二代加速卡都采用了一块Intel/Altera Straix V FPGA。在板卡上有着8GB DDR3内存,一个PCIe Gen3x8接口,以及两个SFF-8088 SAS端口,可以实现FPGA之间高达20Gbps的通信带宽。网络拓扑方面,第二代架构将48个加速卡通过SFF-8088 SAS端口组成了一个6x8的二维Torus网络。其中,每台服务器安装一块加速卡,并通过PCIe对加速卡供电,也并没有安装额外的制冷系统,如下图所示(红圈处即为加速卡位置)。

第二代FPGA架构的主要特点是使用了Shell&Role结构,如下图所示, 老石在之前的文章 《FPGA虚拟化:打破次元壁的技术》 中进行过详细解读 。其中,Shell包含了通用的系统基础架构和IP,比如内存控制器、PCIe和DMA模块、各种I/O接口和控制器等等。Role本质为可重构区域,提供了和Shell的接口,用来实现各类用户应用。
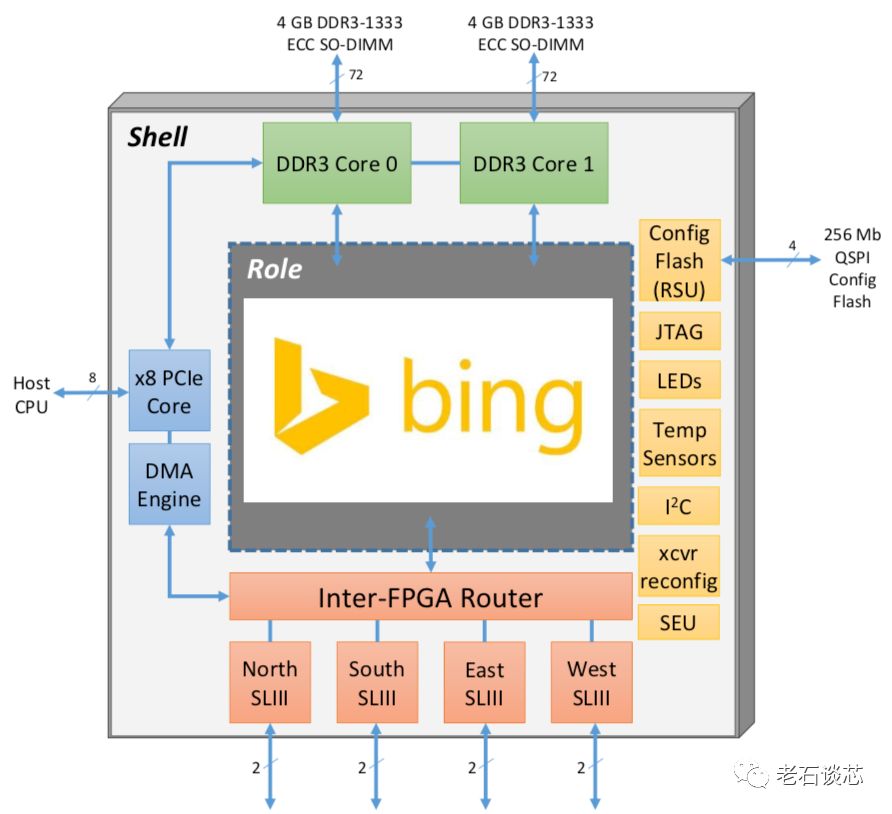
在软件方面,Catapult对数据中心软件和服务器软件分别进行了修改,加入了Mapping Manager和Health Manager,前者用来根据给定的应用对FPGA进行配置,后者用来管理和监测FPGA和其他服务的正常运行。
Catapult项目第二阶段的最主要工作之一,是将Bing搜索引擎中原先超过3万行C++代码的文件排名运算,卸载到了FPGA上进行硬件加速,并得到了惊人的结果 。由于单个FPGA上的资源限制,整个文件排名运算算法被映射到8块FPGA上分别实现,并且总共部署了1632台服务器进行并行运算。

下图总结了这项工作最具代表性的结果,即使用FPGA后与纯软件方案的对比。其中,坐标横轴代表系统延时,纵轴代表吞吐量。 由于纯软件方案已经经过了深度优化,因此这个比较结果具有极高的说服力 。
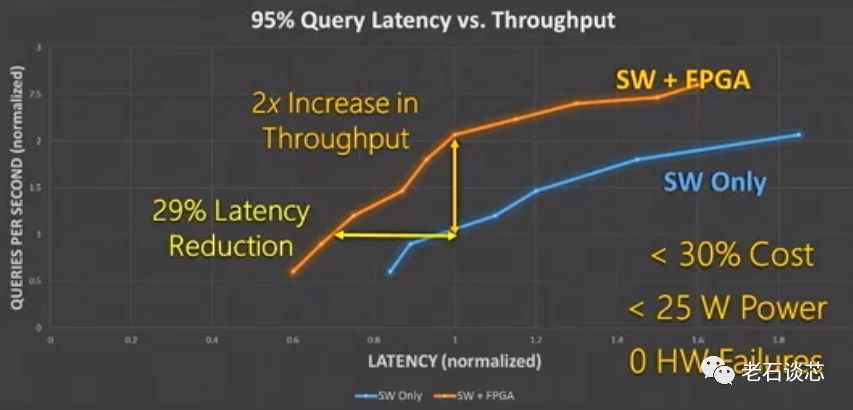
这个结果可以从两个方面解读:
-
当系统延时相同的情况下,采用FPGA进行硬件加速后吞吐量提升了接近一倍;
-
对于相同的吞吐量要求,采用FPGA后系统延时会下降29%。
由此可见采用FPGA后,系统整体性能得到了大幅度提升。此外,每个FPGA带来的额外功耗小于25W,相比原系统而言增加了不到10%,且总体成本的增加不超过30%。整个系统只有在部署初期发现了7块板卡发生了硬件故障,占总板卡数量的0.4%。在之后几个月的运行中,所有板卡都稳定运转,足以证明FPGA系统的稳定性。
第三阶段: FPGA资源池化
第二阶段的工作最主要的问题是,为了实现FPGA之间的低延时通信,引入了一个6x8的二维Torus网络。相比于传统数据中心网络TOR交换机直连CPU的结构,这个Torus网络相当于在当前数据中心网络里额外增加了一个二层网络,而这个二层网络在扩展性和同构性方面带来了很多问题。
第一,在这个Torus网络里,FPGA的互联需要通过两类特殊定制的线缆,如下图中所示,其中,左边的线缆连接8个FPGA,右边的线缆连接6个FPGA。这种连接方式不但成本高昂,而且需要知道FPGA的物理位置,以实现正确的拓扑连接。

第二,虽然在Torus网络内的48个FPGA彼此通信时具有很高的速度,但不同的Torus网络里的FPGA如果需要相互通信,则需要复杂的路由,并随之带来相当大的通信延时和性能损失。这对于某些应用来说是不可接受的。
此外,还应注意的是,这个方案中FPGA加速器只能用来作为特定应用的硬件加速器,而对于数据中心的常用网络功能,如数据包加解密、流量控制、虚拟化等基础设施结构和应用来说,FPGA并没有任何帮助和补强的作用。
为了解决上述问题,微软在2016年发表了Catapult新一阶段的工作,最主要的贡献是取消了FPGA互连的第二级网络,直接将FPGA与数据中心网络进行互连,如下图所示。FPGA加速卡的实物图如下图所示。
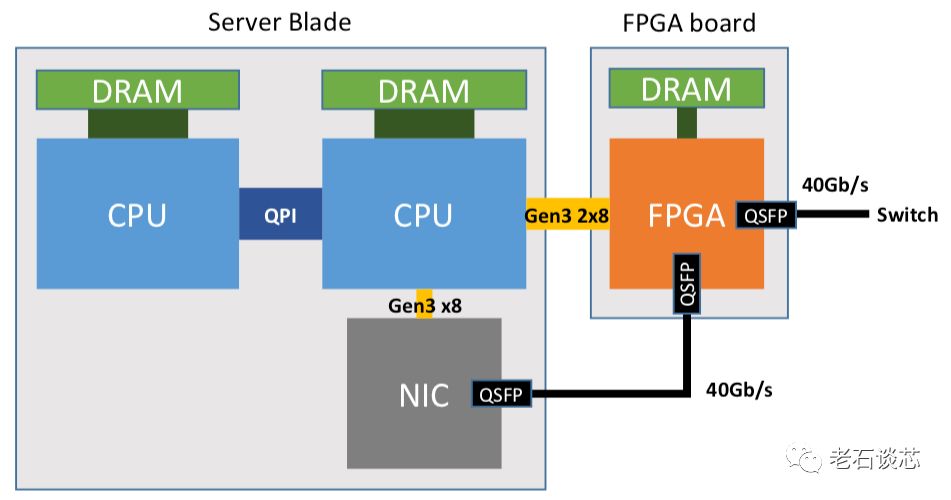

新一代的FPGA加速卡仍然采用Intel Straix V系列FPGA,板上的网络接口升级为两个40Gbps的QSFP端口。FPGA加速卡位于服务器和数据中心网络之间,一个网口连接TOR交换机,另外一个网口与服务器的网卡相连。此外,FPGA还通过PCIe Gen3x8与CPU互连。
和上一个版本相同,CPU可以通过PCIe访问FPGA,并使用FPGA为各类计算任务进行加速运算。除此之外,新版本的硬件布局还带来了以下几点好处:
第一,FPGA可以被用来加速数据中心的各类网络和存储功能 。由于FPGA直接与数据中心网络相连,因此FPGA可以作为智能网卡使用。这样一来,很多网络流量就不再需要经过CPU进行处理,一方面提高了网络流量的处理速度和效率,另一方面解放了宝贵的CPU资源,用以实现其他用户应用。
第二,FPGA不再与CPU在地理位置上紧密耦合 。由于FPGA之间可以通过网络互联,使得CPU可以控制和使用“远程”的FPGA。换句话说,如果CPU不需要服务器内的FPGA进行硬件加速,闲置的FPGA可以组成资源池,供有需要的CPU调用,打破了FPGA部署的地域限制。在这个阶段的工作中, 微软在自家数据中心的5670个服务器里部署了新一代的FPGA加速卡,遍布全球五大洲的15个国家 。
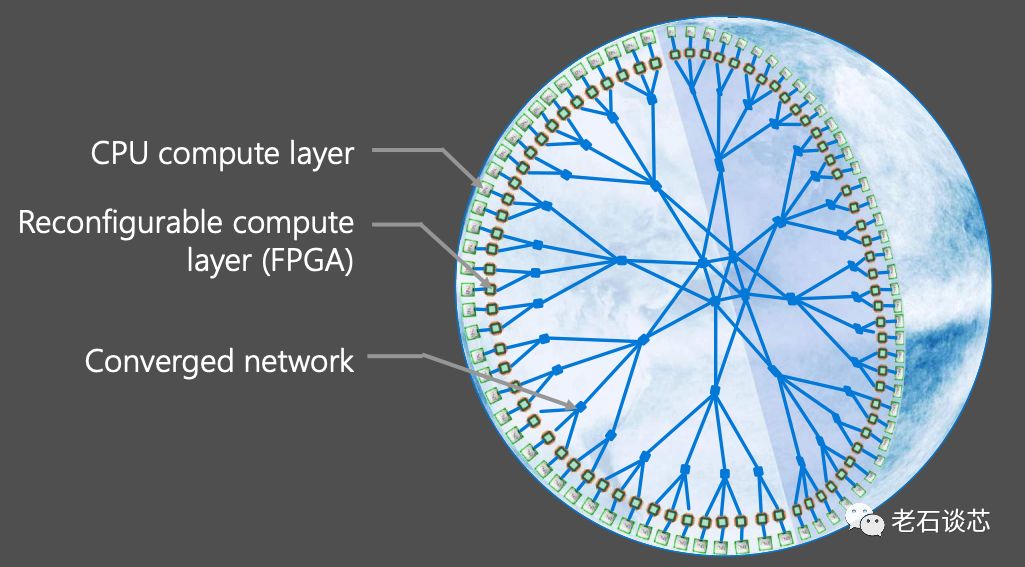
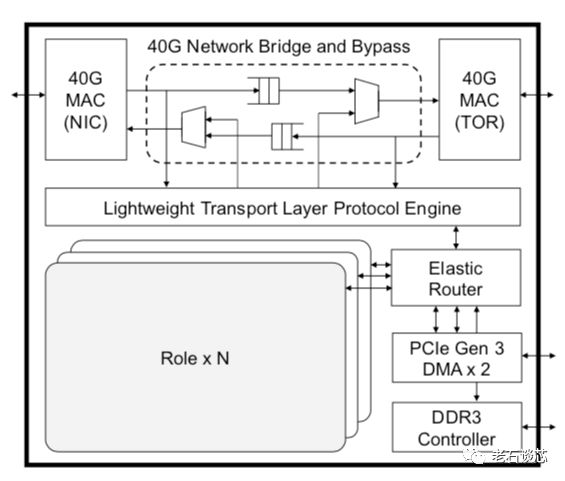
第三代Catapult FPGA架构延续了前一代的Shell&Role结构,并增加了一些新的功能,如下图所示。首先,增加了40G网络数据处理流水线,包括两个40G MAC/PHY以及数据包处理逻辑。另外,微软提出并实现了用于FPGA互联通信的LTL(Lightweight Transport Layer)协议,用来完成FPGA之间的通信。第三,引入了名为Elastic Router的模块,主要用来控制多个用户可配置区域(Role)与外界网络的通信。
为了实现对池化FPGA资源的统一管理和分配,微软提出了一种硬件即服务(Hardware-as-a-Service)”的使用模型,如下图所示。这个模型 在之前的文章里 也已经详细介绍过,这里不再赘述。

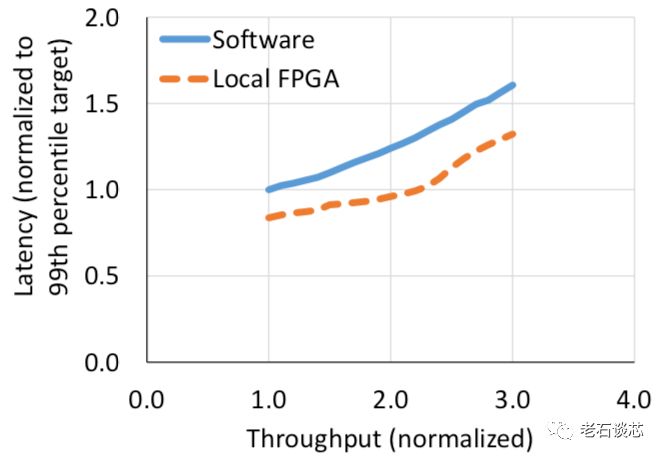
性能方面,Catapult被正式部署在微软的Azure云数据中心,并将必应搜索引擎的页面排序算法进行了FPGA加速,如下图所示。对于给定的延时要求,相比于深度优化后的软件实现,FPGA可以轻松达到2.25倍的吞吐量提升。
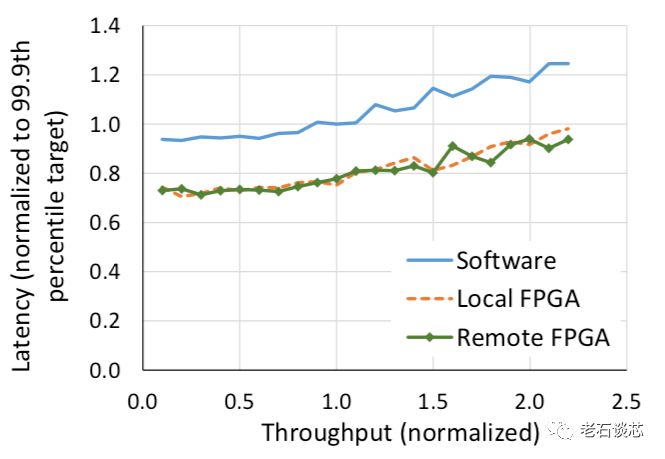
同时,微软还对比测试了使用远程FPGA获得的结果,如下图。可以看到,使用远程FPGA与使用本地FPGA相比,并没有明显的性能差异。这证明了LTL协议与HaaS使用模型的有效性。
由此,Catapult第三阶段的工作很好的解决了FPGA在大型数据中心里部署的灵活性和扩展性问题,为今后FPGA的大规模部署打下了坚实的基础。在2017年,微软推出了一款基于FPGA的深度学习加速平台,名为“脑波(brainwave)”项目。 脑波项目代表着FPGA在数据中心里的应用正式扩展到人工智能领域 。关于脑波项目的具体技术细节,老石将在今后的文章中详细介绍。
结语
微软的Catapult项目可以称作是FPGA在大型商业数据中心里进行大规模部署和使用的开山之作,直至目前仍然也是这个领域最具代表性的工作。Catapult兼顾了学术创新和工程的实用性,这样对于业界其他公司更具有直接的借鉴意义。在结果方面,微软使用了自家已经深度优化的纯软件方案作为对比,使得FPGA取得的显著性能提升更具可信度和说服力。
有趣的是,除了项目初期的原型验证外,微软均采用了Intel/Altera的FPGA芯片,微软也一跃成为英特尔FPGA的最大客户之一。有人曾断言,那些年叱咤风云的“Wintel”联盟,在后PC时代终将土崩瓦解。然而,在风起云涌的大数据和AI时代,伴随着两家公司的一步步华丽转型,Wintel组合正通过FPGA再一次获得新生。


©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号