[原创] AI下凡MCU的世界,Arm中国携手NXP碰撞出哪些火花?
2019-09-11
14:00:17
来源: 半导体行业观察
MCU是嵌入式系统的核心,而随着全球“AI+IoT”融合类应用市场的风起云涌,AIoT创新应用大潮正给MCU在“控制”能力之外添加强大的“智联”属性加成,AIoT时代的MCU,将不再只是负责控制,推理和运算等AI能力也将成为MCU的标配。
在9月3日召开的Arm TECH DAY研讨会上,Arm中国和NXP一起,携各种基于神经网络的人工智能和物联网参考方案,向嵌入式系统开发人员详细介绍基于这些强大Arm内核MCU及其软硬件平台。以NXP eIQ和开源算法的应用实例,演示在基于Arm Cortex-M内核的平台上部署人工智能模型的全过程,以及如何围绕CMSIS-NN充分发挥Cortex-M平台上扩展的潜力。
NXP MCU系统工程师宋岩首先介绍到,传统的机器学习主要靠人工提取和提炼特征,传统机器学习与深度学习最根本的改变是将人工提取的过程改为模型自动找出特征的过程。嵌入式系统作为主体,而人工智能则是属性,以一个人工智能模块来呈现提供新功能,亦可改进现有功能。
目前可以在MCU级平台上部署一些“轻型智能”,如模型尺寸和算力要求低的小规模智能应用,和一些可独立运行的AI模块,无需云端连接就可以实现,再就是一些对重点应用量身定制的应用,还有一些优化高、功耗低、响应稳的应用,这些都是适合在MCU风格的平台上使用。
在MCU上应用AI的特点:
降低功耗、降低成本、快速上市、实时响应、行业广泛、体量庞大、前级处理。
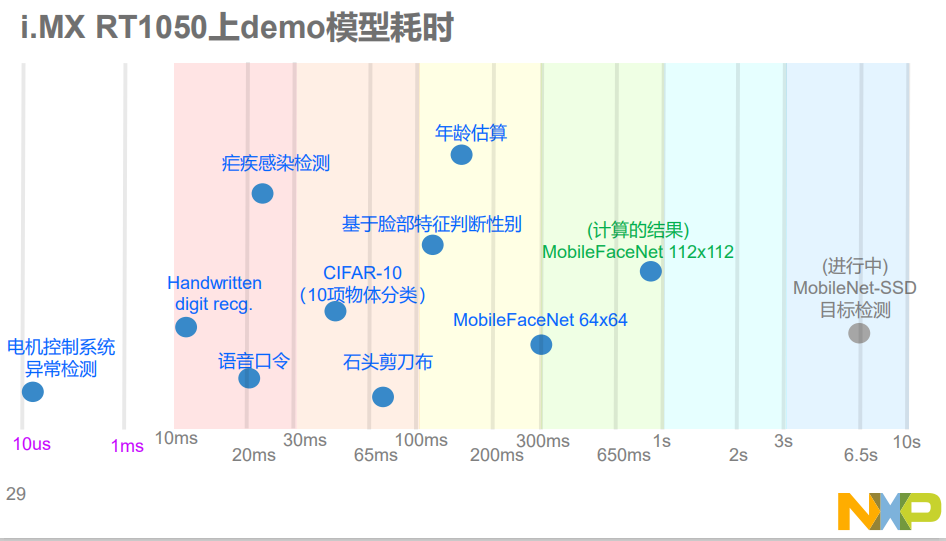
虽然MCU上应用AI的优势颇多,但是难度也非常大,具体来说主要有三点,第一个就是算力弱,即使是目前性能最高的MCU,i.MX RT1050/60,int16算力也只有1.2GMAC/s,可以使用较少位数量化模型、合理精简模型规模、高度优化底层代码、充分利用异构多计算单元;第二个是缺少建模与训练工具,可通过借助PC/Sever来建模与训练;第三是缺少集成工具,对此MXP提供eIQ(边缘智能)工具。
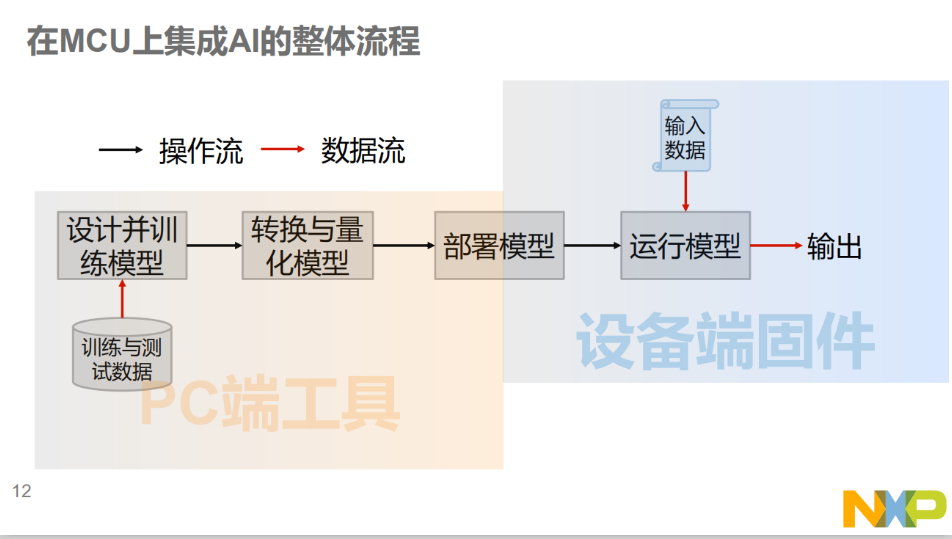
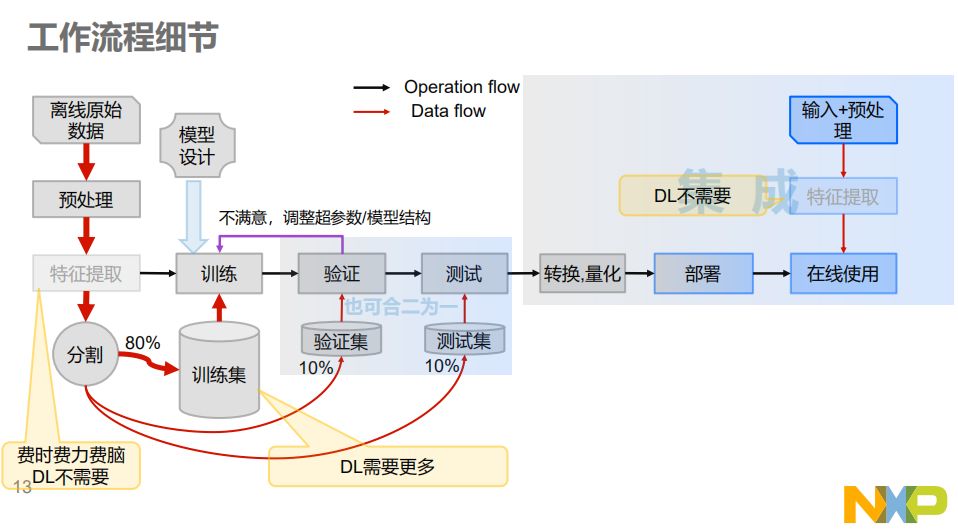
如何在MCU上实现AI边缘计算,这是每个嵌入式工程师都必须关心的话题。在MCU上集成AI的整体流程分为PC端工具和设备端固件两大块。在PC端收集数据集,使用AI建模软件来训练模型,它们通常称为框架,著名的有TensorFlow、Keras、Caffe等。训练之外,还有工具集用来转换、量化、生成。而在MCU固件与数据部分,NXP的I.MX RT Kinetis,LPC MCUs和神经网络底层库(如用于Cortex-M的CMSIS-NN)是用来运行AI模型的基础环境。
NXP有全套的MCU、MPU产品线,从低端的MCU一直到高端的四核、八核高端处理器,所有这些芯片都可以用在机器学习、边缘计算上。
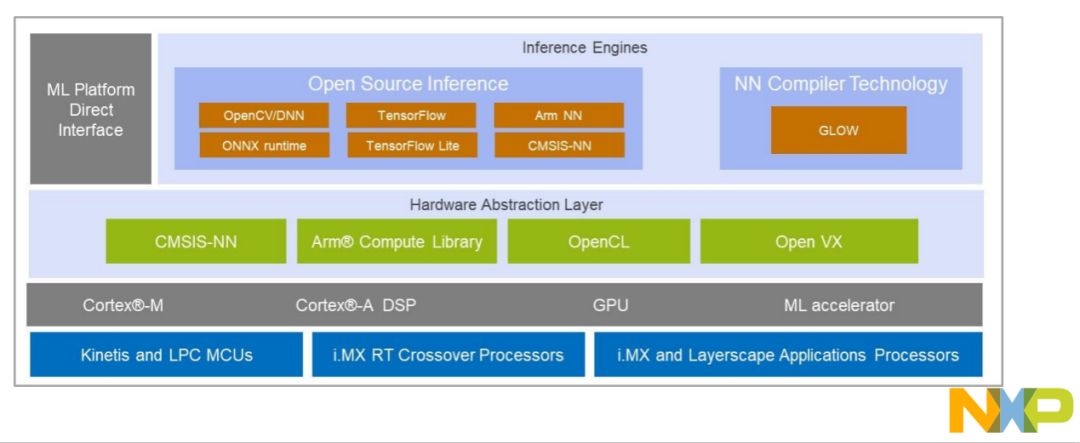
NXP的eI机器学习软件开发环境支持在NXP MCU、i.MX RT跨界处理器和i.MX系列SoC上使用机器学习算法。eIQ软件包括推理引擎、神经网络编译器和优化库。该软件不仅利用开源技术,还完全集成到NXP的MCUXpresso软件开发套件和Yocto开发环境中。
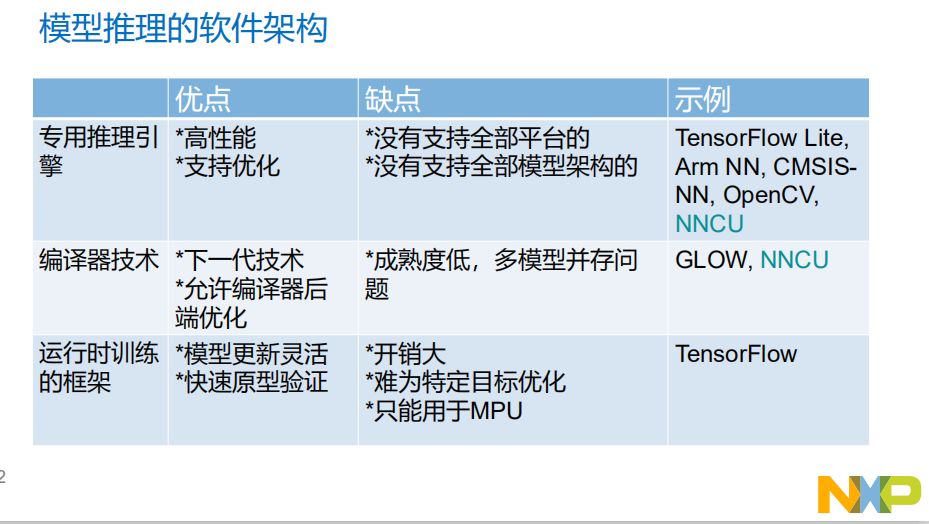
在硬件平台中运算的部分是各种内核和硬件加速器,eIQ框架中包含Cortex-M、A核以及DSP、GPU和ML加速器,其中ML加速器可以跨平台、跨处理器和MCU。芯片之上是硬件抽象层,如CMSIS-NN、Arm计算库、OpenCL和OpenVX。在eIQ中有几种不同类型的推理引擎:Arm NN, OpenCV, Arm CMSIS-NN, TensorFlow Lite,等。不同的模型推理软件各有优缺点。
物联网终端产品正具备更多的AI,为此,恩智浦推出了eIQ开发环境,并在新产品中赋予了更多机器学习和安全性。AI/ML在嵌入式系统上应用大领域主要有生物识别、(非实时)现场监控、可穿戴设备、自学习/自改进设备、异常检测&事故检测、AI教育、智能控制模块等等。在TECHDAY现场,NXP也展示了AI的诸多应用方案。
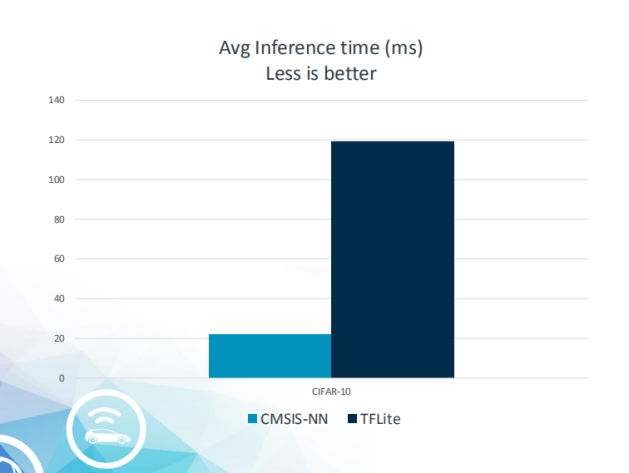
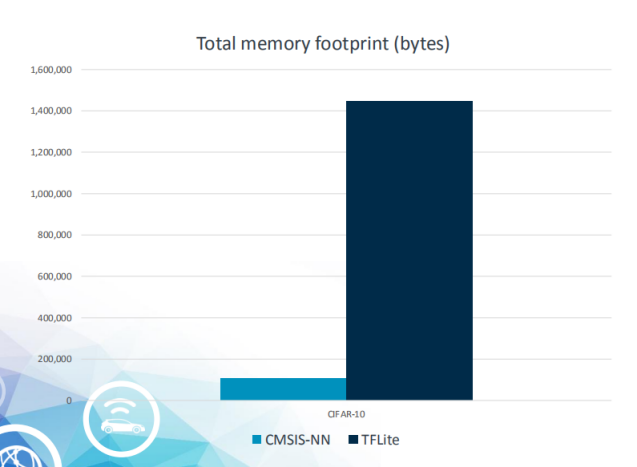
NXP I.MX RT1050上demo模型耗时一览
展望未来,机器学习将用于智能车自动驾驶,第1阶段主要是离线训练,在线使用;第2阶段是离线+在线强化学习。智能车自动驾驶的推荐平台有i.MX RT与i.MX 8M。
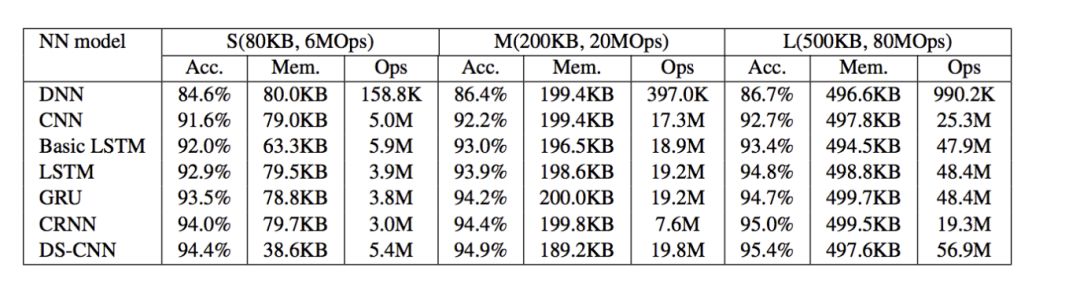
常见的神经网络主要有CNN、DNN、RNN和LSTM。卷积神经网络(CNN)是最常用的视觉图像分析方法,深度神经网络(DNN)是一种在音频应用的输入层和输出层之间具有多层结构的神经网络,递归神经网络(RNN)是一类人工神经网络,节点间的连接按时间序列形成有向图,长短时记忆(LSTM)是一种人工递归神经网络结构。
Arm嵌入式市场高级经理Eric Yang讲到,在这几种神经网络的模型中,DSCNN的精度最高,精度渐近达到95%。
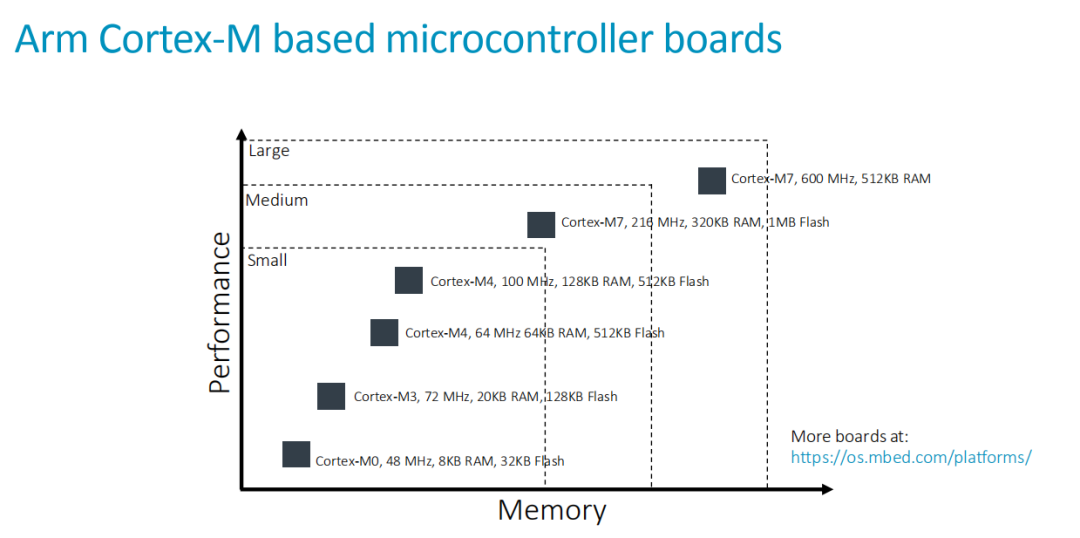
Eric Yang也讲到,Arm可以从软硬件上都可以提供AI的支持。在硬件上,Arm-Cortex从M0-M7都可以做AI训练。
软件上,Arm在去年1月份发布了开源的CMSIS-NN的。
CMSIS-NN
高效地实现了常用的神经网络算子,旨在最大限度地提高性能并最大限度地减少针对智能
物联网
边缘设备的
Arm Cortex-M
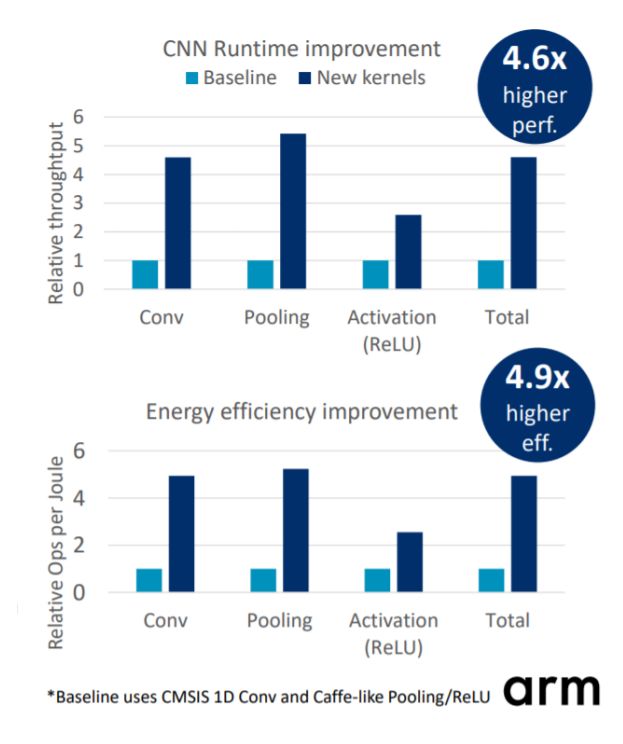
处理器内核上的神经网络的内存占用。CMSIS-NN采用整数运算,比纯C能有4.6倍性能提升和4.9倍能效提升,但是不能单独使用,需配合上层工具集使用,如NXP为之配套的”NNCU”工具集。CMSIS-NN能为Cortex-M DSP提供扩展优化的NN基础库,也可以提供标准C参考实现。
正所谓“鱼与熊掌不可兼得”,对比TensorFlow Lite,Cortex MCU运行CMSIS-NN时,仅是底层NN库,需另行生产上层代码或提供执行引擎,TensorFlow则自带执行引擎和底层NN;但TensorFlow的性能远不如CMSIS-NN,尤其是在int8上性能只有CMSIS-NN的20%!CMSIS-NN对算子的支持稍有薄弱,对此NXP补全了一些算子。CMSIS-NN尚未支持不常用的并联结构(如Inception),但是有更加高效的量化机制。在推理引擎延迟和内存占用方面,CMSIS—NN的表现都较好。
高效的神经网络内核是实现基于Arm Cortex-M的CPU推理的关键。CMSIS-NN提供了优化的功能,以加速关键的神经网络层,如卷积,池化和激活。此外,CMSIS-NN还有助于减少内存占用,这是内存受限微控制器的关键。
会上Eric Yang也表明,受摩尔定律的影响,未来轻量级M系列的MCU会越来越得到大家的关注。
除此之外,Arm的KEIL MDK也将助力Arm MCU系统更好的发展。Arm中国高级工具市场经理Hope Zhao讲到,集成电路的设计复杂度和成本并没有降低,在5nm制程下,软件成本占总成本的35%-40%。
不过在全行业的努力下,Arm和合作伙伴创造了一个令人敬畏的生态系统,Arm专注于关键的构建块,接近架构,合作伙伴通过特定于应用程序的贡献来增加价值。
总之,MCU现已踏上了适应AIoT场景的智能化改造之路,通过越来越多的智能互联应用场景的充分验证后,真正能顺应市场需求的智能MCU方案也必将脱颖而出。如今Arm与NXP强强联合,下一步,只需要推动市场的爆发,最终重新描绘未来万物智能互联的美好景像。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2064期内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
AI|台积电|
华为
|封测
|晶圆|
SIC
|
存储
|IC
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!
责任编辑:Sophie