不同类型的硬件加速器几乎与通用CPU同时被提出和开发。沿着摩尔定律的半导体增长的终结,引发了人们对加速器的极大兴趣。实际上,Amazon和Microsoft Azure云都为用户提供了定制加速器的能力,它们为云服务器提供了FPGA和GPU以供一般使用。
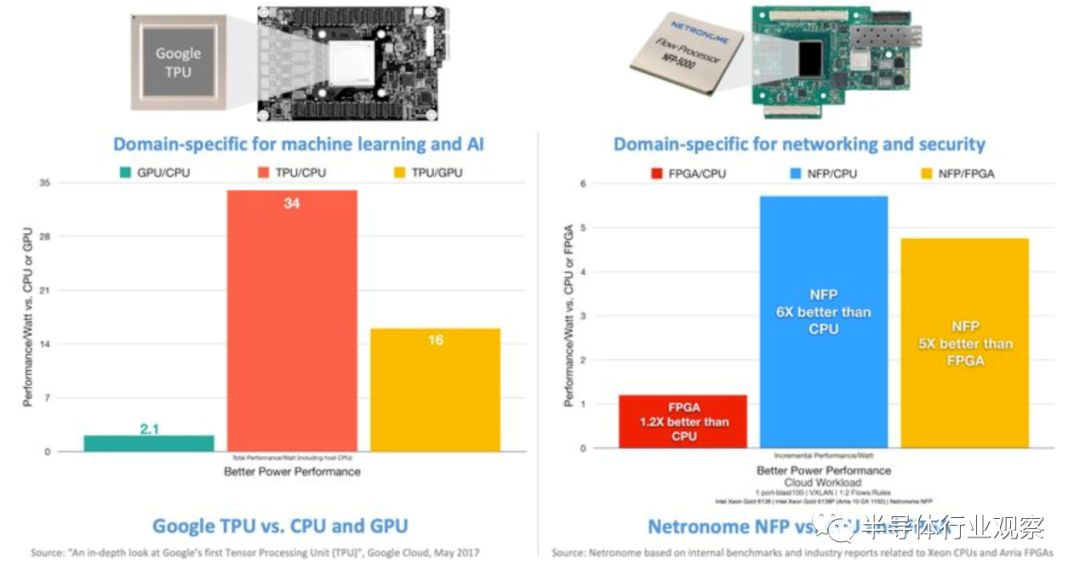
顾名思义,特定领域的体系结构是为共享一个共同特性的一类工作负载而定制的。这些设备是可编程的,不像传统的ASIC那样是硬接线的。它们的特点是集成应用程序和部署感知设备、固件、系统和软件的开发,并支持特定领域的语言以便于使用。领域特定体系结构的关键属性是并行数据处理、功能特定逻辑、应用感知数据管理和控制。如图1所示,与CPU和FPGA相比,其性能/瓦显著提高。这里展示了两个著名的、基于领域的硅的示例,即用于机器学习的Google的TPU(张量处理单元)和AI,以及用于网络和安全的Netronome的NFP。
本节调查了有关加速器的最新商业工作和学术工作。我们将加速器广义上定义为专用于运行特定于域的工作负载的任何非CPU硬件。根据此定义,基于GPU,FPGA和ASIC的系统都是DSA。我们还包括神经网络加速器。神经网络不能用微代码编程,而是通过调整网络中神经元之间连接的权重来编程。
机器学习,特别是基于神经网络的机器学习,已经成为商业应用中最流行的用例。最初,大多数加速工作都集中在扩展加速上,通过将工作负载分布到不断增长的服务器池中来减少计算时间。随着能源成本在更大的数据速率下变得难以维持,加速器开始受到更多的商业关注。数据中心运营商采用了不同的方法来加速学习(建立模型的行为)和推断(使用模型进行预测的行为)的工作负载(ML.He等)。请参阅具有加速硬件和专用网络的服务器系统,以将加速作为可人工智能服务器,并提供所有大型数据中心运营商可人工智能服务器的全面概述[8]。
许多学习系统都基于NVIDIA GPU构建。NVIDIA具有学习参考设计(DGX-1)。Facebook开发了一个开放计算平台Big Basin,用于学习数据中心的任务。许多公司也在开发专门针对学习的加速器。Tang维护了针对ML 68的硅/ IP解决方案列表。在大型商业供应商中,NVIDIA Volta芯片和Intel Nervana(正在开发中)和Movidius芯片是用于学习的DSA的示例。尽管NVIDIA努力将所有ML活动都集中在基于GPU的体系结构上,但英特尔提倡一种跨多种类型的计算元素的异构方法。英特尔还提供了将x86 CPU与FPGA结合在一起的平台。类似地,Xilinx也有一个异构的学习加速产品Everest,该产品结合了FPGA,通用CPU和针对神经网络处理进行了优化的网络。与任何新兴领域一样,机器学习初创公司也吸引了大量的风险投资。Wave Computing和Graphcore 是具有特定领域的定制化硅片公司的范例。
虽然学习通常是一种离线活动,但是推断工作负载需要对生产环境中实时数据不断进行的。因此,它发生在从网络数据中心到网络边缘和终端设备的多个物理位置上。今天,与学习相比,推理具有更多的性能、吞吐量和延迟约束。推理也可以在降低精度的情况下执行,例如用8位、4位甚至1位精度代替32位,用整数精度代替浮点数。因此,学术界和工业界都开发了许多以推理为目标的加速器。Sze等人提供了一个全面的调查学术和商业的努力,以加速推论与领域特定的硬件。NVDLA是NVIDIA开发的一个用于加速推断的开源框架,能够支持多种类型的硬件加速器。Tensorflow是谷歌在生产数据中心广泛使用的最著名的推理加速器。Cambricon的加速器针对稀疏神经网络中推理时减少的数据流进行了优化,在不牺牲性能的前提下,通过学习后修剪(或减少)神经网络来构建加速器。
比特币挖掘和加密货币挖掘通常是一项计算密集型活动。在其发展的早期,比特币挖掘是在CPU上执行的。早期的加速工作集中在GPU和FPGA的开采上。用于挖掘加密货币(主要是比特币)的专用集成电路获得了大量投资,主要是因为它们提供了比FPGA和GPU更好的电源性能。这些ASIC加速了加密货币中的散列操作。Taylor很好地概述了加密货币挖掘的最新发展。Bitcoin Wiki还提供了加密货币ASIC的良好概述。货币矿工的一个独特的方面是,它们几乎总是部署为具有多个加速器的阵列。
除了ML和加密货币挖掘之外,许多公司还生产了DSA。Netronome已生产出了几代用于网络功能的DSA,用于智能网卡和网络设备的NFP。ThinCI最近为物联网应用引入了一种图形流处理器,用于处理多个并行数据流。Memcached是一个分布式内存缓存系统,旨在降低磁盘访问的成本。LegUp computing开发了一个memcached加速器,部署在连接了FPGA的Amazon服务器上。来自HPE的作者提出了用于Memcached的SoC加速器,该加速器将在SmartNICs上实现。最近受到广泛关注的一个新领域是用于近内存计算的加速器。这些加速器旨在通过将处理元素移动到外部/内部内存接口附近来减少系统总线上的内存流量。IBM讨论了在超级计算应用程序中使用近内存处理,HPE讨论了在“机器”体系结构中使用近内存处理。
与行业一样,ML在学术界也进行了大量研究。对于神经网络加速研究,FPGA尤其是沃土。Guo等人提供了对加速FPGA的多个主要学术研究的综述。学术研究也集中在加速神经网络的特定特性上,例如稀疏性。神经网络的类型,例如HMM ;开发新方法以在加速器的神经网络中存储权重矩阵。上面提到的调查文件还对用于推理的学术硬件加速器进行了很好的概述。在将数据从内存传输到执行逻辑时,神经网络加速器会花费大量时间(和硅片面积)。研究人员已经研究了如何通过将执行逻辑直接合并到内存中或内存接口来降低这些成本。通常,在内存中执行需要降低神经网络的复杂性。
近内存/内存内加速可能带来的性能改进受到了学术界的高度关注。加速器的重点是减少内存密集型应用程序中涉及的数据传输。例如,减少了在内存中遍历树的时间,降低了散列的成本,对数据库所需的连接操作进行排序,以及将可重新配置的逻辑直接放在DRAM接口上。
不出所料,DSA在学术界的应用范围比商业应用更广。Lindsey等人研究了领域特定的语言和Monte Carlo模拟的加速器。Ng等人的综述了二十年来用于遗传序列比对的FPGA加速器的发展。Wu等人提出了Q100数据库加速器。来自韩国的研究人员最近提出了一种LZ压缩的加速器。
研究人员还研究了许多与构建加速器有关的有趣话题。这些努力旨在降低FPGA或ASIC中实现的加速器的开发成本。Lindsey等人表明,如果可以减少开发加速器的成本(例如,通过在较早的硅工艺节点上开发加速器),则可以通过在数据中心中部署自定义ASIC云来降低应用程序的总拥有成本。有趣的学术焦点一直集中在开发加速器的框架上。Cong等讨论了实现主机和加速器内存之间的内存一致性的框架。Celerity 和Basejump 是基于多核体系结构的开源加速器框架,其中内核是基于开源RISC-V ISA的轻量级内核。Gray还演示了在FPGA上基于多核RISC-V的实现。通常,加速器需要硬件和软件的协调开发。COSMIC是一个试图在横向扩展框架中共同合成神经网络加速器的硬件和软件的框架。LSSD是一个用于从多个内核自动组成架构的框架。Moorthy和Gopalakrishnan 提出了一种针对FPGA的服务框架,其中定制逻辑可以放入一个框架,该框架提供任何加速器所需的I / O和内存访问。他们估计这将大大减少开发工作。ST-Accel是一款专注于流媒体应用的加速器合成工具。
研究人员还将重点放在创建特定领域的语言作为一种机制来表达和抽象用于加速的原语。DSL也成为一种无需大量开发工作即可跨多个实现移植应用程序工作负载的机制。P4是学术界提出的一种特定领域的语言,用于描述已经受到学术和商业关注的网络数据平面。最初,P4中的工作重点是描述网络交换机中的流量。最近的研究表明,P4作为加速器的抽象层和网络端点的可移植性也具有重要的价值。
一项值得注意的新工作是,基于Google的Tensorflow语言创建一个VM环境,以在软件中执行神经网络工作负载[56]。这种方法与eBPF VM相似,eBPF VM用于在Linux内核中启用自定义网络。Netronome最近展示了将eBPF执行透明地移植到加速器的能力,而无需开发人员专门为加速而做任何工作。Tensor虚拟机在将神经网络工作负载透明地移植到加速器中也可以提供类似的好处。
除了应用意识,有效的DSA设计是垂直集成的。硅设计需要理解DSA本身的固件开发人员所需的编程模型,以及DSA如何集成到系统级应用程序数据流和控制管理中。
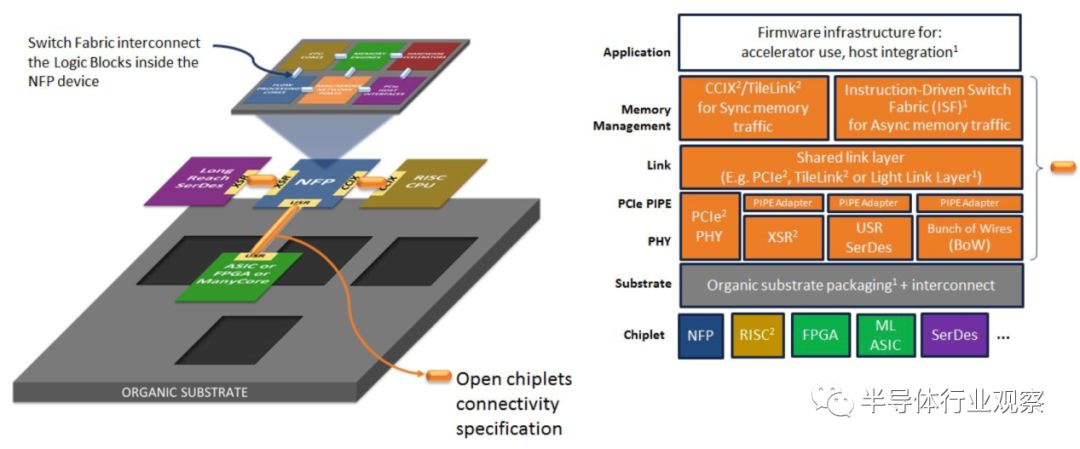
ODSA基于一个参考的多裸片体系结构,该体系结构认识到支持集成开发的必要性。它源于一个参考的单片加速器设计,而单片加速器设计又基于广泛应用的加速器中常见的元素。多裸片参考设计的目的是保护软件模型不受单片加速器的影响。这是通过新的跨裸片链接层实现的,该层在多裸片加速器中抽象出了新的片间连接。参考多裸片结构基于参考单片加速器结构,该结构包含了广泛的商业和学术加速器中的元素。
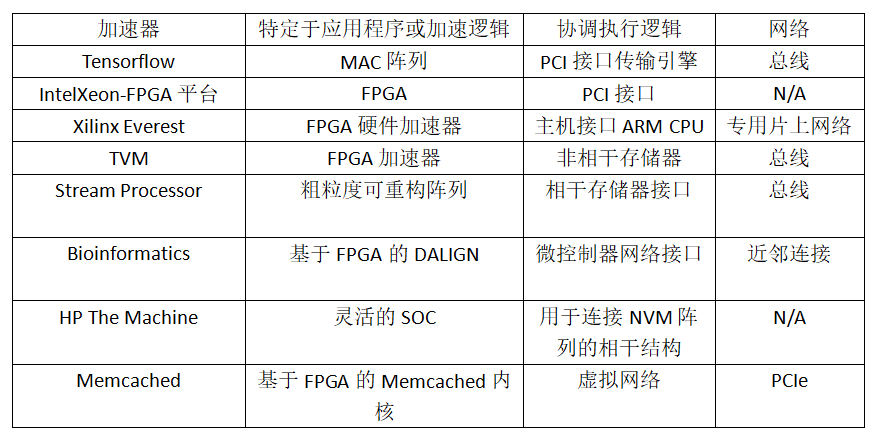
研究人员的目标是明确DSA的结构特征,开发自动合成DSA的方法。以下特征列表基于中的列表。
通用CPU设计的核心是处理具有不同并行度和不可预测的控制流的不同应用程序。相比之下,几乎所有的加速器都旨在利用并行性和确定性控制流,这些控制流存在于特定的算法或应用程序的一系列算法中。特别是基于轻线程的算法。例如,在神经网络中,与单个神经元相关的计算相对简单,但每个网络却需要由数千个神经元组成。
1. 特定于算法的逻辑,针对基于特定控制流的并发性:
a、硬件并发性:大量的功能单元,每一个单元通常都有一个简单的数据路径来利用加速算法中典型的巨大并行性。GPU和神经网络加速器是常见的例子。
b.特定于应用的逻辑:功能单元本身包含用于计算的特定于问题的功能单元。例如,NPU可能包含位操作逻辑。
c、硬接线控制流:可预测的控制流反映在一个网络中,该网络实现了单元之间的显式数据通信。例如,许多神经网络加速器具有近邻阵列结构。
2. 协调执行逻辑:可编程加速器中的软件通常不单独运行。
相反,可编程加速器通常是与在通用CPU上运行软件协同执行的。大多数加速器包含额外的硬件,以协调特定应用程序的逻辑与在主机上软件和内存:
b.大量的内部内存。外部存储器接口。这不是特别协调的逻辑。由于内存实现在很大程度上独立于应用程序,所以我们将它包括在本节中。
c、对数据结构和重用的硬件支持。批量数据传输引擎和/或代理以支持与通用CPU的内存一致性。
d.通用测试和调试硬件,以支持制造和操作(在商业加速器)
片上的网络,以一条网络在芯片上的形式或一条或多条总线连接到依赖于应用程序和独立于应用程序的逻辑。
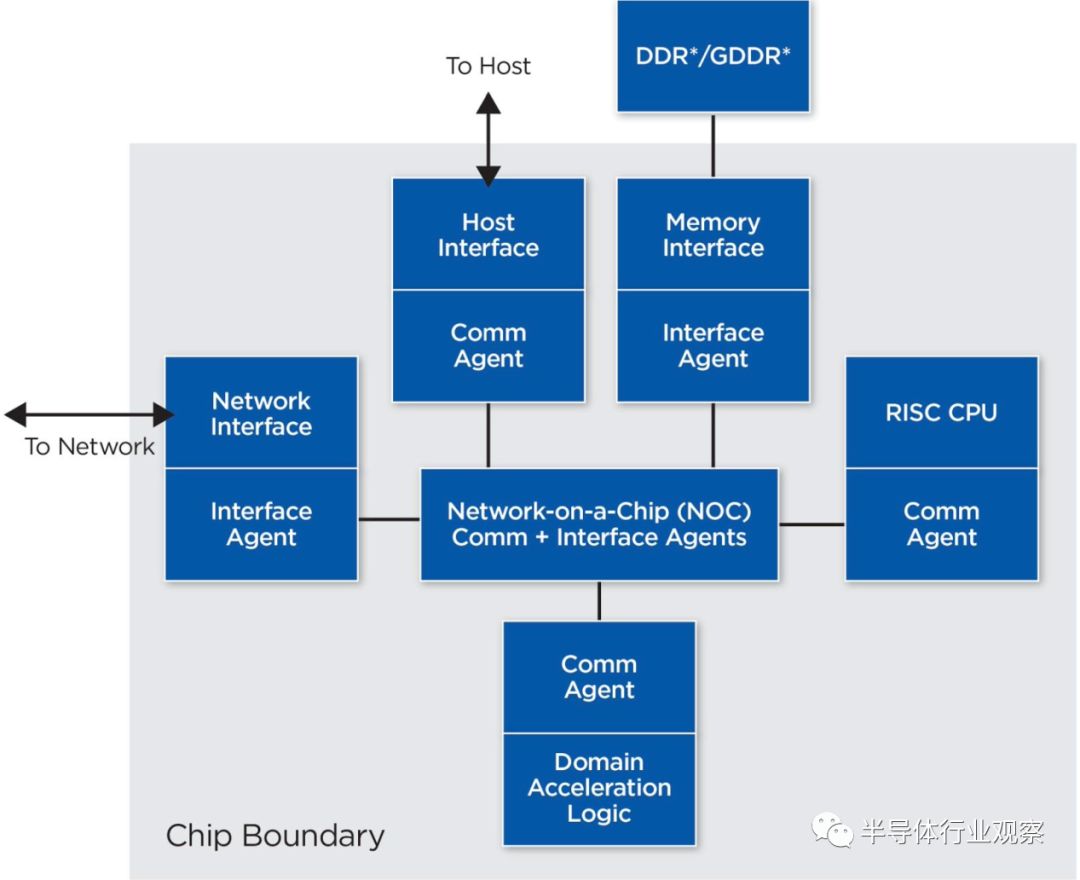
下面提出的参考设计由四个部分组成,它包含了加速器的主要部分。重要组成部分包括:
互连网络可以是片上网络或一组一个或多个总线。通信代理的范围可以从简单的引擎(用于接收和传输数据)到更复杂的逻辑,以维持芯片上各种逻辑元素之间的存储器一致性。应用程序本身通常被分解为运行在域加速逻辑,互连网络(用于数据传输),RISC CPU和主机上的固件和软件。
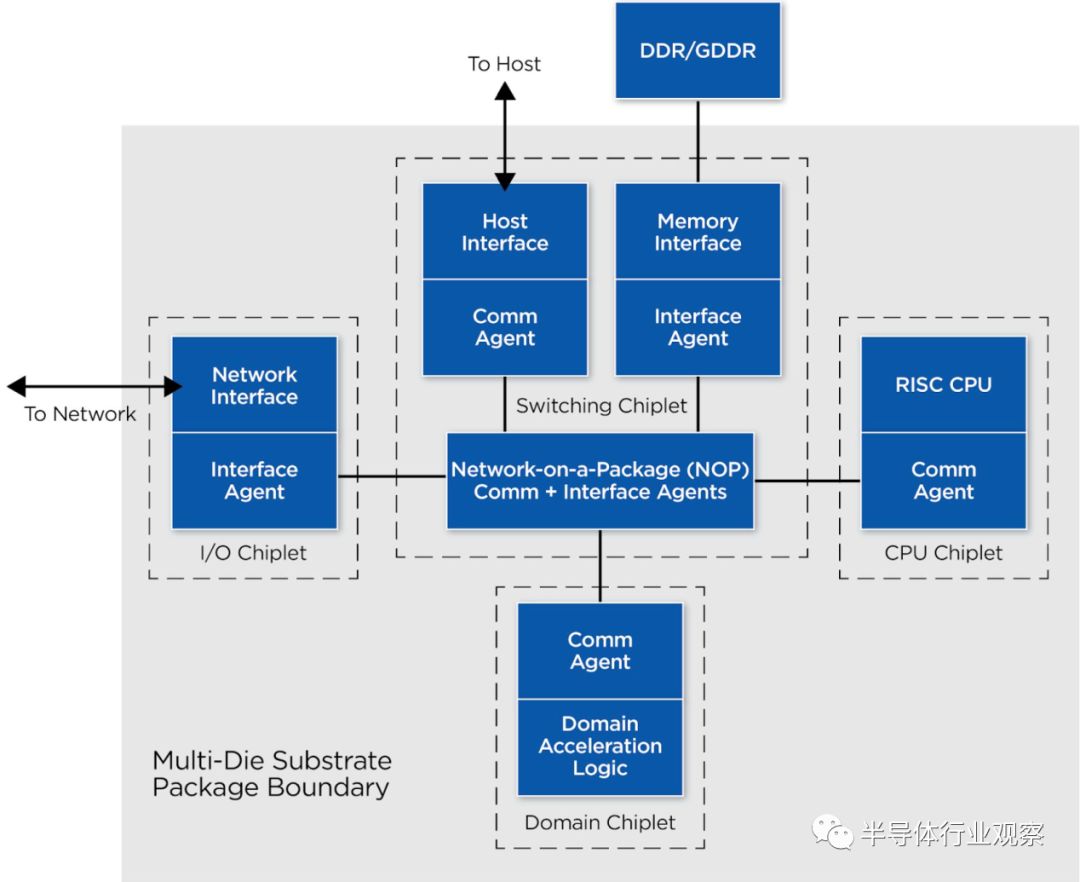
我们在参考单片结构的基础上,提出了一种适用于DSA的多裸片结构。
整体设计被分解成独立的chiplet如下:
d.与所有其他chiplet相连的交换和接口chiplet
这些chiple现在被封装在一个共同的基板上。这些chiplet必须实现通信代理,以支持片间网络。
其目的是使应用程序能够在参考多裸片架构上开发和执行,类似于它们在单片体系架构上的开发方式。一个额外的复杂性是,不像单片IC,裸片实际上可以由不同的厂商生产。
为了呈现一个类似于单片IC的开发环境,多裸片架构必须提供一个与单片IC架构相当的内存模型和性能。内存模型需要在一个开放的事务层上实现,以支持来自不同供应商的轻松互操作性。最后,必须使用PHY连接技术来实现性能,该技术使体系结构能够使用具有成本效益的有机基质封装技术来实现。
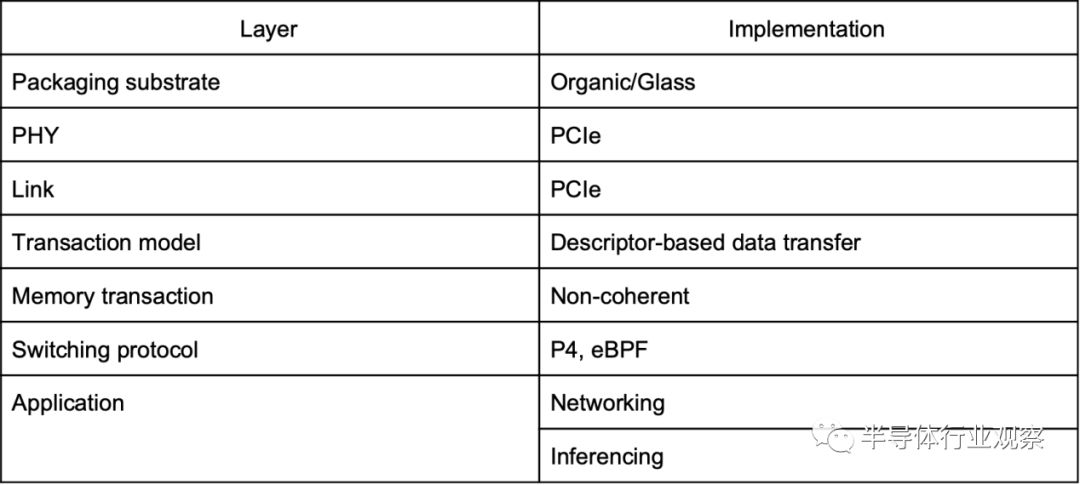
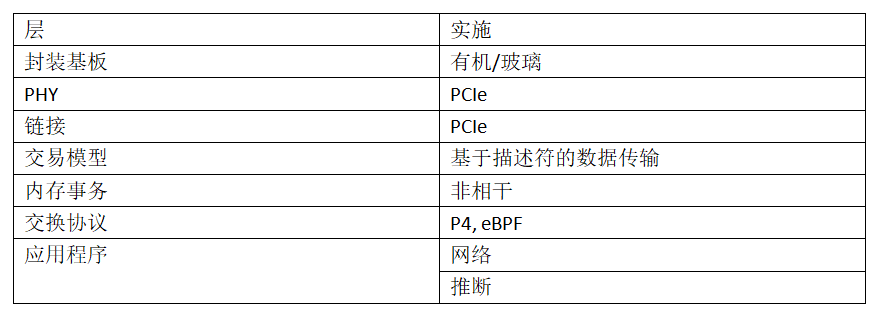
总之,为了弥补单片实现和异构实现之间的差异,参考体系架构必须开发一个完整的协议栈,解决以下问题:
a.事务层:用于在处理元素之间移动数据的通用事务模型
使用这种方法,即使在设计发展的过程中,也可以保留更高的层。本节的其余部分将开发参考多裸片架构的组件。
存储层充当ODSA中计算进程之间所有通信的基础结构。主机加速器通信通过内存以及逻辑元素之间的任何通信进行。ODSA通过存储事务的通用模型支持内存储管理。
在现有系统中,片外通信的过程不同于片内通信的过程。在多芯片封装中,跨chiplet通信需要在功能上与芯片内通信的过程相同,尽管其性能可能较低。通用事务模型是PHY和存储管理协议之间的接口。通用事务模型从加速器应用程序和支持应用程序的存储事务协议中抽象出物理通信的细节。本节概述了通用事务模型的要求以及可能满足这些要求的当前协议。
加速器应用程序需要为不同的应用程序支持大范围的数据传输大小,每个应用程序都有不同的延迟需求:
1.ML应用程序需要为加速器处理的每个对象传输数GB的数据。
2.在网络应用中,对象大小可能在64-1500B范围内,每个对象可能需要大约1-2KB的控制数据。
3.在所有应用程序中,缓存一致性协议可能需要与缓存行一样小的极低延迟的传输。
预期ODSA实现将通过组合来自多个供应商的chiplet来组装。在这样的系统中,并不是所有具有通信代理的设备都具有相同的功能。其次,片间物理连接的数量是一个重要的资源。规模上的异构性产生了特定的需求。
1.在具有多个交换机的大型系统中,可能需要路由事务。即使在链路上有缓冲区,在交换机上进行简单的路由也是可取的。
2.跨越chiplet边界的读取和写入内存事务不应停止并阻止chiplet间链接的使用。即,应该保证完成。
3.启用设备发现或注册系统,列举每个chiplet的特定功能。
基于消息的拆分事务信用协议支持突发数据和大小受限的写操作,可以满足这些要求。议定书的具体内容仍有待制定。建议是直接使用现有协议,或者作为开发的起点。具体来说,使用PCI Express和新的开放式磁贴链接事务模型作为起点。PCI-Express具有广泛应用于当前设备的优点。重用PCI Express将使ODSA能够重用大量的遗留裸片。PCI Express具有面向设备到根传输的约束。在主机上插入PCI Express系统时,可能需要与基于主机的PCI Express系统共存,增加了复杂性。需要进一步的研究来完全指定通用事务模型。
ODSA将在公共事务模型上运行多种类型的内存管理协议,以支持一组不同的加速器应用程序。ODSA设想在内存中支持两种类型的内存读写流。
相干流:
具有相干代理的所有处理元素保持一致的硬件支持的相干存储空间视图。任何读取都将生成最新的值。任何写操作都会使物理分发的副本失效。一致性协议消耗延迟(对软件开发人员隐藏)来维护一致性状态。因此,当必须保持一致性的物理区域受到限制时,性能最好。与CTM层一样,ODSA将重用现有的内存同步协议,如CCIX或Tyelink。
非相干流:许多加速器应用程序需要可预测的大数据块传输。例如,ML的推论流需要传输大量的权重数据。非相干流可能更适合许多应用程序所需的大规模数据传输。Netronome使用一种新的ISF(指令驱动的开关结构)协议来进行非相干的芯片内数据传输。该协议在分布式近邻连接上使用基于信任的链路层。ODSA将支持在通用事务模型上使用ISF协议。
ODSA需要提供网络基础结构以启用通用事务处理模型。
多裸片封装中的chiplet之间的物理通信协议技术仍在不断发展。系统特定的Phy协议的选择是由性能需求和成本约束的组合驱动的。例如,对于没有显著性能要求的部件,重用具有PCI Express连接性的现有裸片可能比开发具有短程SerDes连接性的新产品更经济。类似地,某些功能可能演化为特定协议唯一支持的功能。例如,XSR协议可能是最终光连接到系统的chiplet的标准。
如前所述,ODSA建议所有Phy层协议都向更高层提供PIPE接口。
与TileLink一样,ODSA中的所有消息路由都是按地址进行的。ODSA希望同时支持静态和动态路由算法。
ODSA还将支持多种类型的外部接口。这些接口通常涉及大量的模拟电路,这些电路无法像数字逻辑那样从流程节点特征尺寸缩减中获益。因此,它们最好作为单独的chiplet实现。
外部接口上的数据将在不支持通用事务模型的接口代理上传递。每个接口的Phy层将特定于接口类型。此外,这些接口的数据I/O预计将通过交换chiplet来实现,从而使它们成为系统其余部分的共用资源。
1.网络接口:
网络接口将作为一个独立的chiplet实现,因此网络I/O带宽可以独立于系统的其余部分进行更改。网络接口可以是光接口,也可以是电接口。来自接口的数据通过标准OIF接口(如XSR)定向到开关芯片。此接口上的数据预计不会在通用事务模型上交付。
2.主机接口:
主机接口将是下一代PCI接口。一些应用程序可能要求加速器中的内存也与主机的内存一致。因此,与网络接口不同,主机接口还需要支持通用事务模型。我们期望主机接口与交换chiplet集成。
3.内存接口:
预计开关chiplet将支持外部内存接口。为了满足延迟和/或吞吐量需求,RISC CPU和加速器chiplet可以有各自的接口。对于某些应用程序,具有高带宽内存接口和高带宽USR物理层的交换chiplet可能同时满足RISC CPU和加速器逻辑的吞吐量和延迟要求。也就是说,外部内存可以是通过交换chiplet访问的共享资源。
有效的DSA需要集成开发硅、系统、固件和软件。与DSA开发相关的两个软件问题最近受到了很多关注:领域特定语言和卸载模型。
有两种广泛的模型可用于将功能从主机卸载到DSA,即透明和定向卸载。两种型号还需要主机上的驱动程序,用于从主机管理DSA。
尽管DSA是可编程的而不是固定功能的ASIC,但是几乎所有的DSA都包含应用程序域特有的可编程功能。DSA的一个业务问题是需要为特定的DSA创建自定义代码,而该代码不能移植到实现类似功能的其他设备上。例如,一个机器学习IC的代码不可在另一机器学习IC上执行。
领域特定语言解决了这个问题。这些语言指定域通用的加速原语。DSA通过将程序编译到硬件来执行DSL中的代码。通过支持语言原语的高性能实现来实现性能。DSL中编写的代码可移植到任何具有DSL编译器的加速器。DSL使性能与跨多个设备的代码可移植性结合起来。商业上,谷歌用于机器学习的TensorFlow是最著名的DSL。TensorFlow是用于编程TensorFlow ASIC的DSL。TensorFlow还用于对基于VM的便携式神经加速器进行编程。P4和eBPF这两种DSL,在网络应用中得到了越来越多的应用。P4最初设计用于核心交换应用程序,然后扩展到服务器数据中心应用程序。例如,P4被用来实现Gen-Z内存聚合交换协议。eBPF被设计用来在Linux内核中定义自定义网络,最近它被看作是一个简单的卸载模型。
ODSA将支持DSL的使用。例如,网络应用程序的P4和eBPF。ODSA将利用Netronome在这些领域的开源贡献。
在大多数加速应用中,DSA上运行的数据路径与通用CPU上的数据路径耦合。在ODSA中,这可能是ODSA中的RISC CPU或ODSA所连接的主机。ODSA将支持两种主机交互模型:
显式卸载数据路径编程:
加速器数据路径在功能上与主机数据路径分开。加速器上的数据路径由开发人员单独编程。主机通过API控制数据路径。使用主机上的显式函数调用将数据从主机发送到加速器数据路径。该模型的两个示例是Google的第一代TensorFlow ASIC和Netronome的Agilio SmartNIC上的P4编程数据路径。这种方法将需要从主机处理器到卸载数据路径的开源接口。P4 Runtime是此类接口的一个示例。
隐式卸载数据路径编程:
在该模型中,加速器没有在数据路径内被调用或显式编程。外部控制将执行从主机切换到加速器。大多数情况下,这是由程序员在VM中开发目标功能来实现的。这种方法需要主机操作系统提供更大的开源支持。主机和加速逻辑都需要支持应用程序使用的任何DSL。通过将VM从主机移动到加速器来加速应用程序。这个模型的两个例子是Netronome的eBPF卸载和华盛顿大学的TensorFlow VM。
为了证明ODSA的好处,建议实现一个既支持一致性存储事务又支持非一致性存储事务的原型。为了展示开放架构的好处,ODSA将使用这些chiplet的最新版本实施PoC。
ODSA建议在低成本的有机或玻璃基板上实现图4中的参考架构,其中Kandou USR作为片间连接协议。在USR中,我们将实现一个相干内存协议,并将ISF扩展到片间非相干事务。链路层将实现内存事务的通用模型。
图4:USR SerDes和玻璃基板的ODSA参考架构实现
我们简要回顾了用于开发PoC和最终ODSA原型的chiplet。
片间的交换和主机接口将由Netronome NFP提供。PoC将使用NFP-6000并使用它的四个PCIe接口来提供与其他处理元素和主机的连接。原型和PoC还将使用广泛的开源驱动程序集、卸载固件和NFP家族可用的主机软件。
当开发完成后,我们将使用光纤来封装在第3节中讨论的光学解决方案。
FPGA提供了可重新配置的硬件,可以在其上动态实现包括DSA在内的自定义硬件。当需要大量相同的加速器时,自定义逻辑通常会更高效。在许多情况下,FPGA可能是首选的解决方案,包括何时可以针对特定实例优化数据路径,或者何时数据量较小,或者您想在不同时间将同一芯片重用于多个DSA。对于在加速阶段之间进行数据编码的简单转换,FPGA也是非常有效的,以使其他不兼容的加速器能够流在一起。
原型的候选者是Achronix Speedster22i HD1000 FPGA。HD1000提供700,000个LUT,700,000个寄存器和10MBytes可重配置RAM块,用于实现自定义逻辑。它还提供了一个100千兆以太网MAC和PHY,DDR3控制器。HD1000将通过PCI Express Gen 3连接进行连接,因为该传统设备不支持CCIX。
PoC和prototype将使用基于SiFive的U7系列RISC-V核心的应用程序处理器。
我们的目标是开发第一个ODSA PoC,主要是目前在生产或开发的裸片,即不需要新的流片。PoC的目标是演示ODSA提供的抽象的价值,并作为应用程序和协议开发的平台。具体来说,PoC将演示网络和推理方面的应用。

由于NFP裸片和其他裸片之间的互连总数小于100,因此很容易在有机基板上实现,然后将多裸片封装在MCM封装中。利用微带线和带状线对高速信号和其他低速I/o进行布线,6层(2+2+2)基板就可以完成布线任务。今天,一个14层(6+2+6)的封装提供多达四个高速路由层是很容易做到的。即使是20层(9+2+9)的包装也可以投入生产。
注:本文摘译自ODSA工作组,由半导体行业观察翻译,电子科技大学黄乐天副教授参与校正,特此感谢!
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2243期内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
“芯”系疫情
|ISSCC 2020
|国产芯片
|半导体股价
|
存储
|
Chiplet|氮化镓|高通|华为
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!