Arm服务器芯片重磅玩家:深度揭秘Marvell ThunderX3
2020-08-20
14:00:40
来源: 半导体行业观察
来源:内容由半导体行业观察(ID:icbank)编译自「anandtech」,谢谢。
在日前的hotchips 2020上,Marvell终于揭示了有关其新ThunderX3服务器CPU和核心微体系结构的的一些细节。该公司早在三月份就发了了新服务器和基础架构处理器,知道现在,他们终于就其内部CPU设计团队如何将自己与迅速增长的Arm服务器市场竞争区分开来做了更多的分享。
我们早在2018年就对ThunderX2进行了评估 ,当时的他们才被Marvell收购几个月,产品还是Cavium时代的产品。但从那时起,Arm的Neoverse N1 CPU内核和合作伙伴设计(例如来自Amazon(Graviton2)和Ampere(Altra)的合作伙伴设计)就启动了Arm服务器生态系统计划,现在这是完全不同的情况,AMD也在市场上获得了成功的回报。
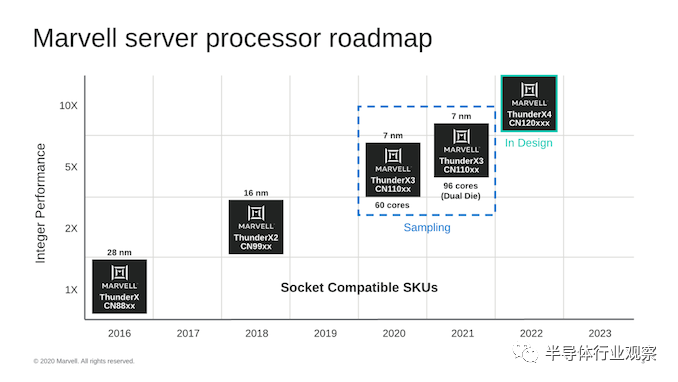
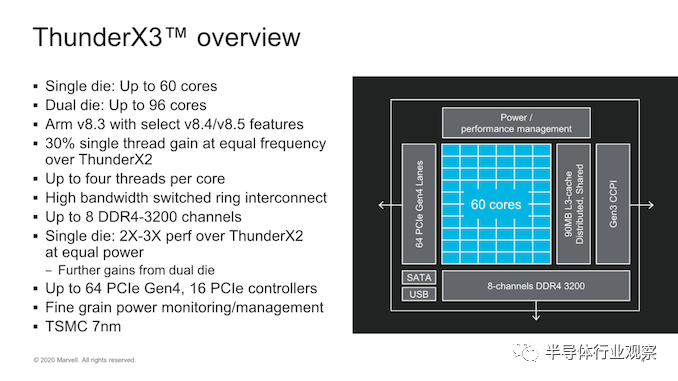
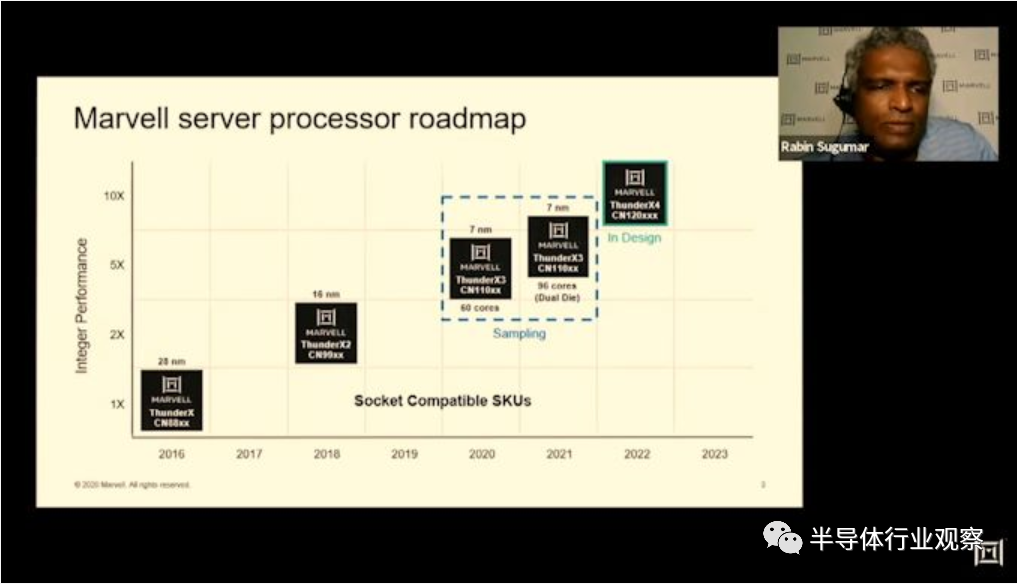
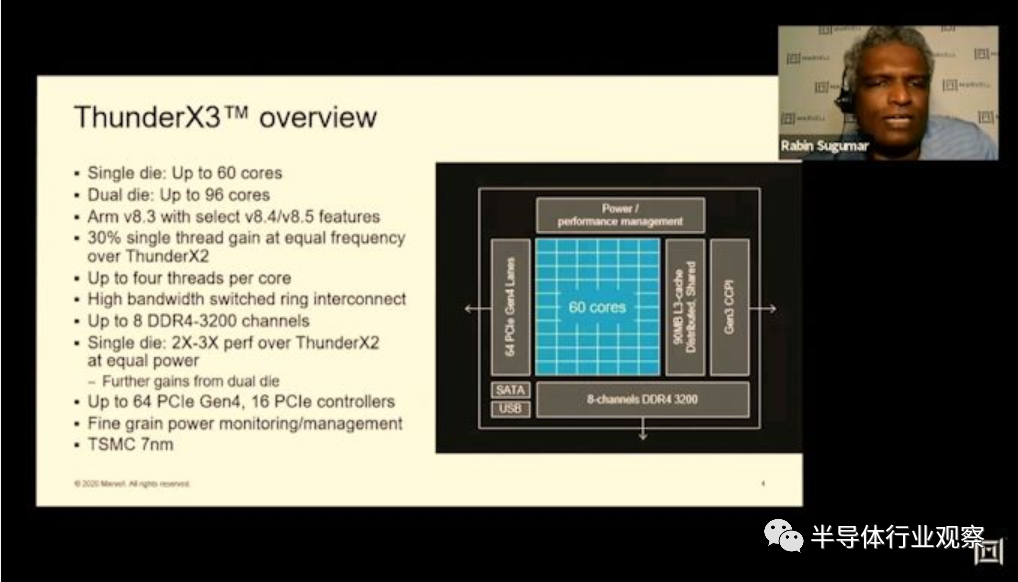
Marvell从其产品路线图开始其在HotChips上的演示,他们详细介绍了ThunderX3,指出这并不仅仅是单一设计,而是代表了使用多个die的灵活设计方法,他们2020年推出的第一代的60核CN110xx SKU使用单个die的整体设计,明年将发布旨在提高性能的96核心双die变体。
像这样的双die方法的使用非常有趣,因为它代表了完全单片设计与AMD等供应商的小芯片方法之间的中间点。每个die在意义上都是相同的,因为它们可以独立用作独立产品。
从SoC的角度来看,ThunderX3芯片可扩展至60个内核,而2个die的变体最多可扩展到96。看到这些数字时,首先想到的问题是为什么2的die的变体无法扩展到完整的120核。Marvell在演讲中没有涉及到这一点,但演示中有一些线索。
Marvell表示,在相同的功率水平下,新芯片的性能比ThunderX2高出2-3倍。后者的TDP为180W,如果TX3保持此散热水平,则意味着双die设计必须将TDP增长至360W,这远远超出了典型服务器设计的散热能力和机架的功率密度。假设线性缩减至广告宣传的96个核心,则最终功耗将约为288W,这与当前没有水冷的高端服务器CPU部署更加一致。当然这是我们自己对此事的分析和考虑。
一个die支持8个通道的DDR4-3200,这是此代服务器产品的标准配置,基本上与市场上的其他产品一致。在I / O方面,我们看到了64条PCIe 4.0通道,这与竞争对手一致,但仅相当于Ampere或AMD的高端替代产品可以实现的一半。
现在一个未知数是其爽die产品如何分割I / O和内存控制器,如果这两个芯片之间的资源分配将达到50-50,或者我们是否会看到不平衡的情况设置,平台是否可以实际处理每个骰子的全部资源并将其自身转变为16通道128通道野兽?
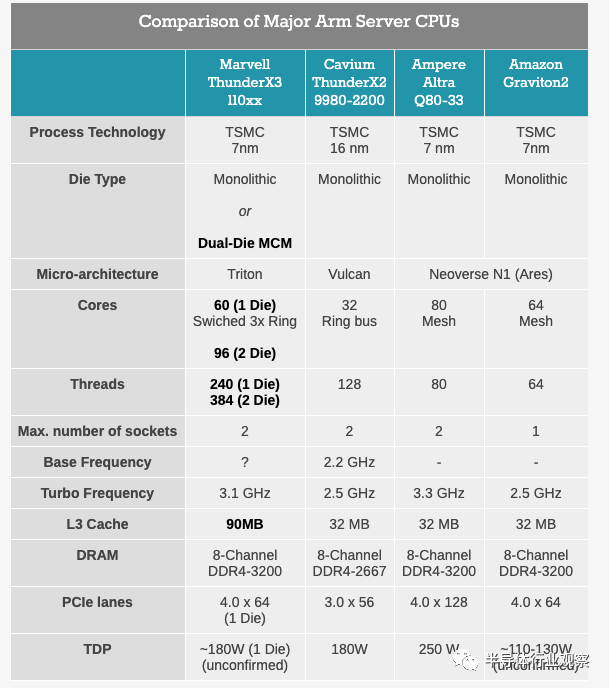
至少在纸面上,ThunderX3看起来与亚马逊的Graviton2非常相似,因为它们都共享相似数量的CPU内核以及相似的内存和IO配置。一个人可以立即指出的更大的区别是,ThunderX3在其CPU内核中采用了SMT4,因此每个die最多支持240个线程。TDP也存在差异,但我将其归因于Graviton2的时钟频率比较保守,而Ampere的SKU更符合ThunderX3,特别是规格最接近的64核3.0GHz 180W Q64-30。
ThunderX3的另一件引人注目的是其90MB的L3缓存,这使上一代的32MB以及Ampere和Amazon的32MB配置相形见绌。
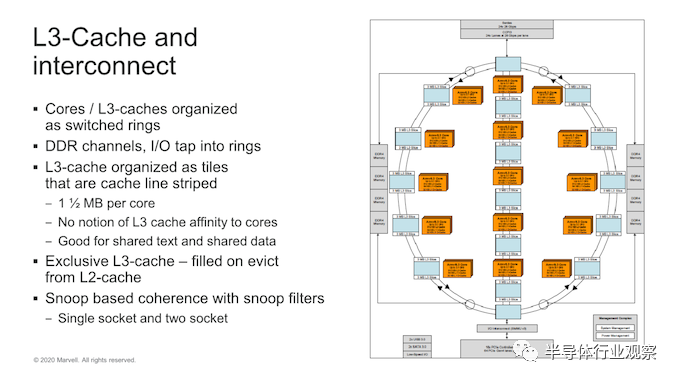
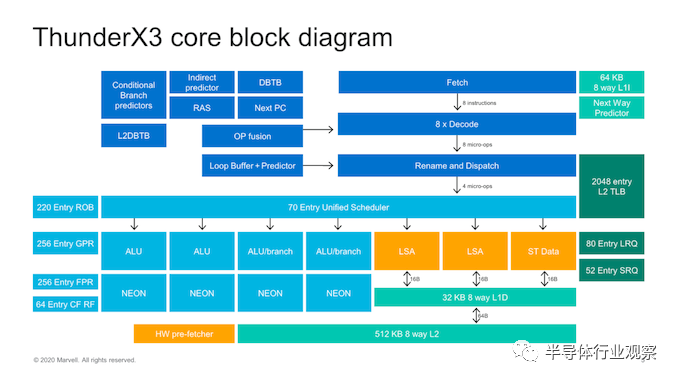
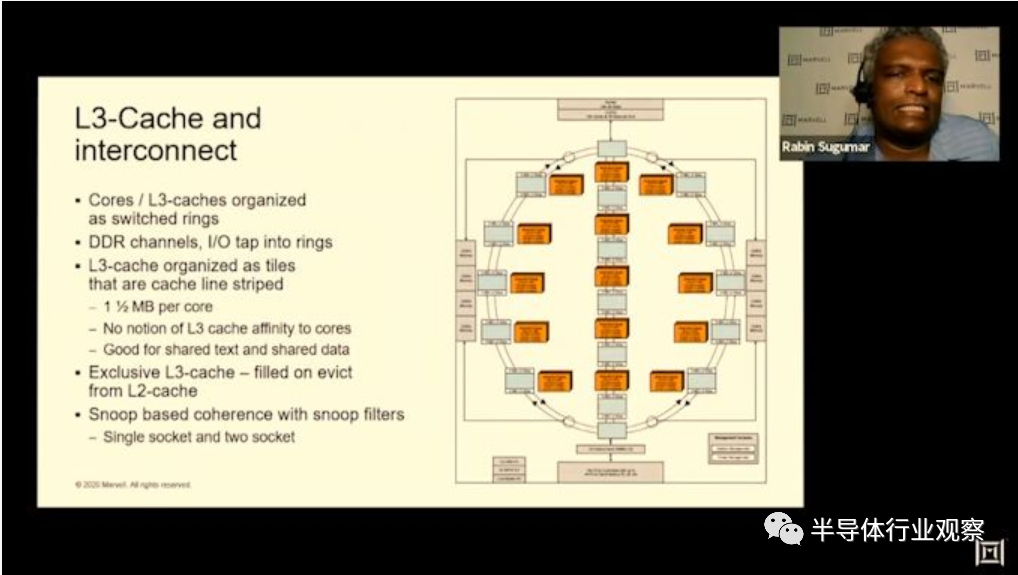
Marvell在这里选择发展自己的互连微体系结构,该体系结构现在已经从简单的环设计演变为具有三个子环或列(sub-rings, or columns)的交换环(switched ring)。Ring stops 具有4个核心的CPU块和两个具有3MB缓存的L3切片组成。这提供了具有15个ring stops(3x5列)的完整die,以及完整的60核90MB的总L3高速缓存,这是一个相当可观的数量。
在问答环节中,Marvell透露,他们采用交换环(switched ring )拓扑而不是单环或网状设计的理由是,单核无法在更高内核数下提高性能和带宽。网格设计将是一个很大的变化,并且将需要减少核心数量。交换环代表了两种架构之间的良好折衷。确实,如果这使Marvell能够提供比其最接近的竞争对手高3倍的缓存,那似乎是一个不错的选择。
我注意到的一件奇怪的事是,该系统仍在使用基于侦听的一致性算法(snoop-based coherency algorithm),这与业界其他基于目录的系统形成了鲜明对比。这可能会降低实现的复杂性和面积,但在功率效率和芯片的一致性流量方面可能会落后。
内存控制器进入环网(rings),Marvell的插槽间/芯片间CCPI3接口可提供高达84GB / s的带宽。
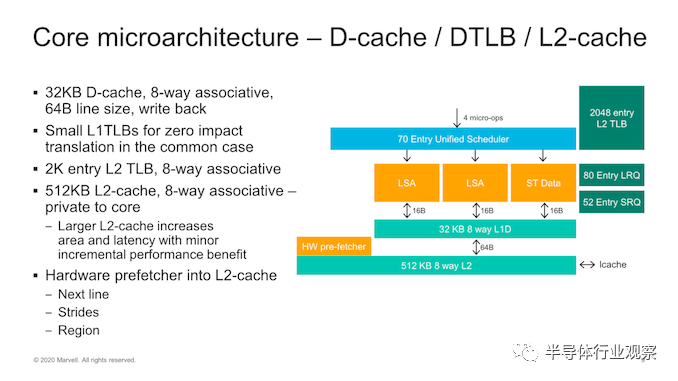
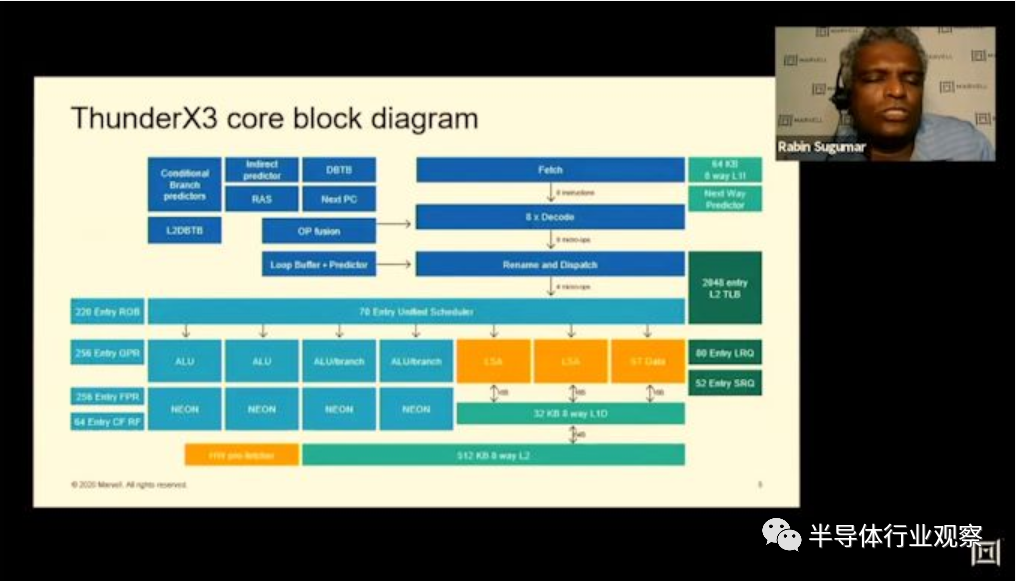
进入核心级别,我们看到了Marvell的新Triton CPU微体系结构的首次公开。该设计是ThunderX2 Vulcan内核的改进,该公司在前端和后端都扩展了内核的许多方面。
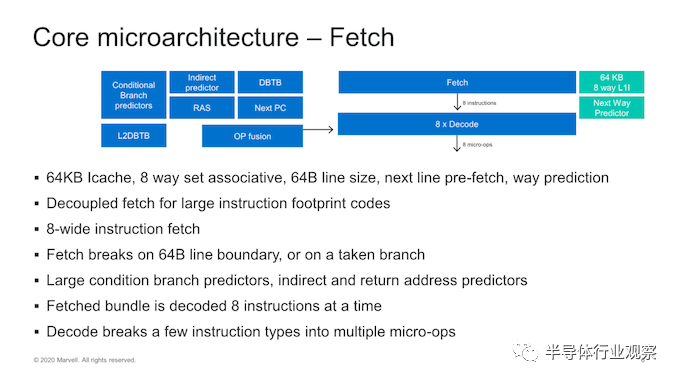
从核心的前端开始,我们看到了一些非常重大的变化,因为几乎可以看到核心中大多数结构和带宽的字面翻倍。指令高速缓存已从32KB增加到64KB,现已增加到8-wife fetch unit,这也是上一代的两倍。
就像Arm最近的微体系结构一样,这是一个新的去耦读取单元,可以节省更多功耗。解码单元与8条指令宽度的提取带宽相匹配,实际上,它与IBM的Power10内核一起代表了目前业界最广泛的解码器,这非常令人惊讶。
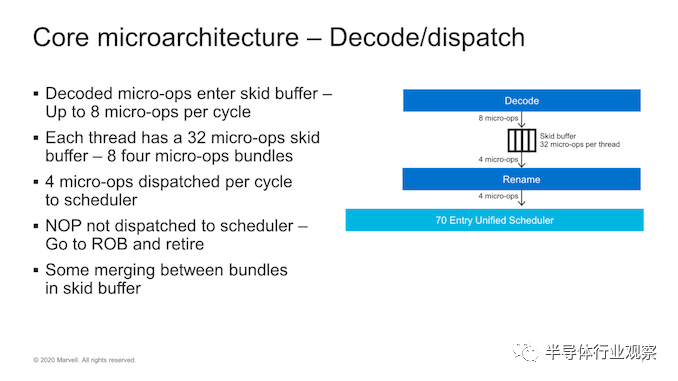
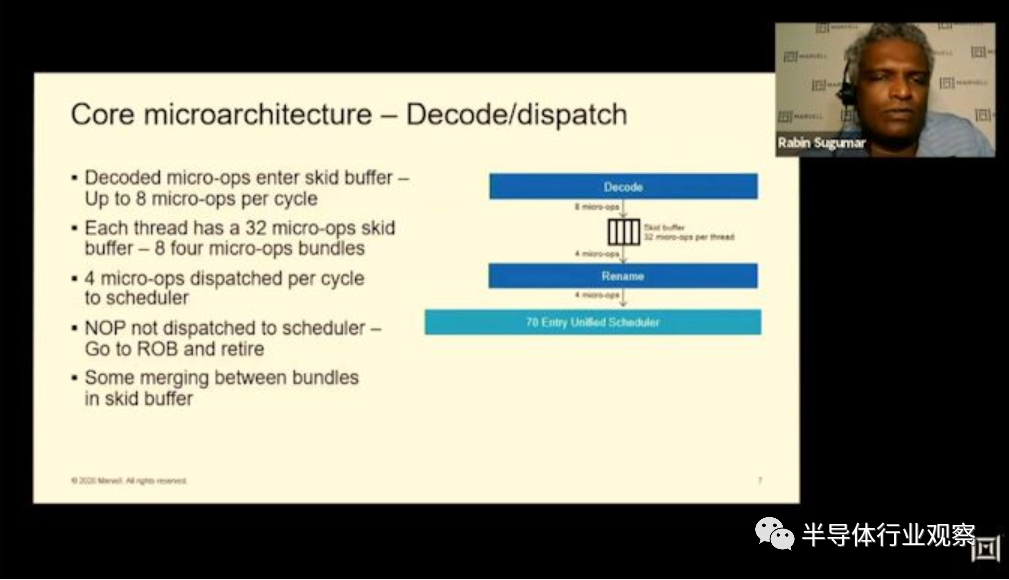
在中核中,我们看到解码单元送入Marvell所谓的“ Skid buffer”,该缓冲区本质上是一个循环缓冲区,每个线程分为32个微操作,进一步分为八个四宽微操作束。它是内核中在线程之间静态分配的稀有结构之一,它代表了微体系结构的前端和中间内核之间的边界。
Trition微体系结构中最有趣和最令人困惑的部分是内核的这一部分,即使内核的获取和解码单元为8宽,微操作也会从Skid-buffer进入重命名单元并进行调度。但到内核的后端,每个时钟仅发生4微操作。因此,这里似乎正在发生的事情是,Marvell正在利用非常广泛的前端设计,而不是大型后端,他们似乎在隐藏什么。
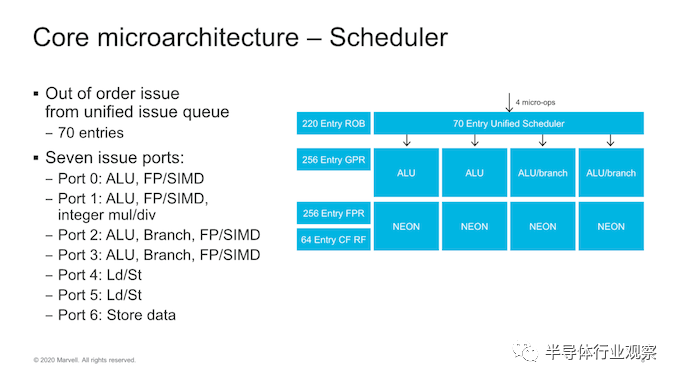
到内核的后端,我们看到继续使用馈入7个执行端口的全局统一调度程序。在调度程序级别,我们看到条目从60增加到70。
内核的无序窗口有所增加,例如重排序缓冲区(ROB)从180个增加到220个条目。
在执行端口上,最大的变化是增加了能够执行ALU指令的第四个执行pipeline和第二个分支端口,这意味着我们看到简单整数ALU执行吞吐量提高了33%,并且分支转发量增加了一倍。除了这些改进之外,所有四个执行pipeline都已通过FP / SIMD功能进行了扩展,这意味着这些指令的吞吐量现在已成倍增长,使Triton内核成为其中罕见的4x128b机器之一。
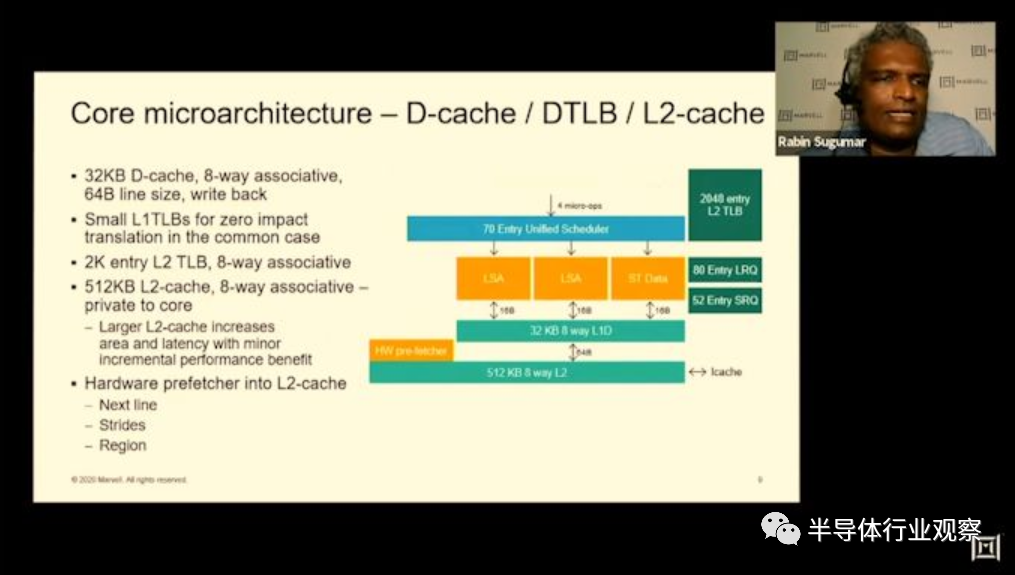
在核心的内存子系统部分,改进相对较小,因为我们似乎没有对微体系结构进行重大的高级更改。我们仍然看到两个负载存储单元和一个存储数据单元,每个单元的带宽为16字节/周期,从32KB L1数据高速缓存中馈送和提取数据。加载和存储队列的深度已增加,加载的条目分别从64个增加到80个,存储的条目增加了36个到48个。
内核的L2也从256KB增加到512KB,但Marvell在此更改时的措辞很有趣,因为他们说它仅以“较小的增量性能优势”增加了面积和延迟,这听起来令人失望。我们将在下一张幻灯片中看到2.5%。
硬件预取器非常简单,传统的下一行,跨步和基于区域的设计将数据提取到L2中。
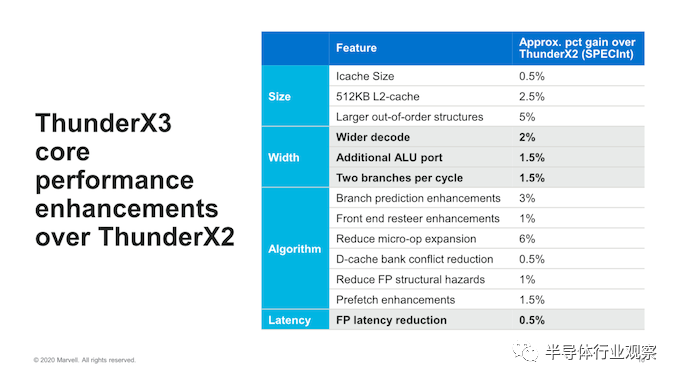
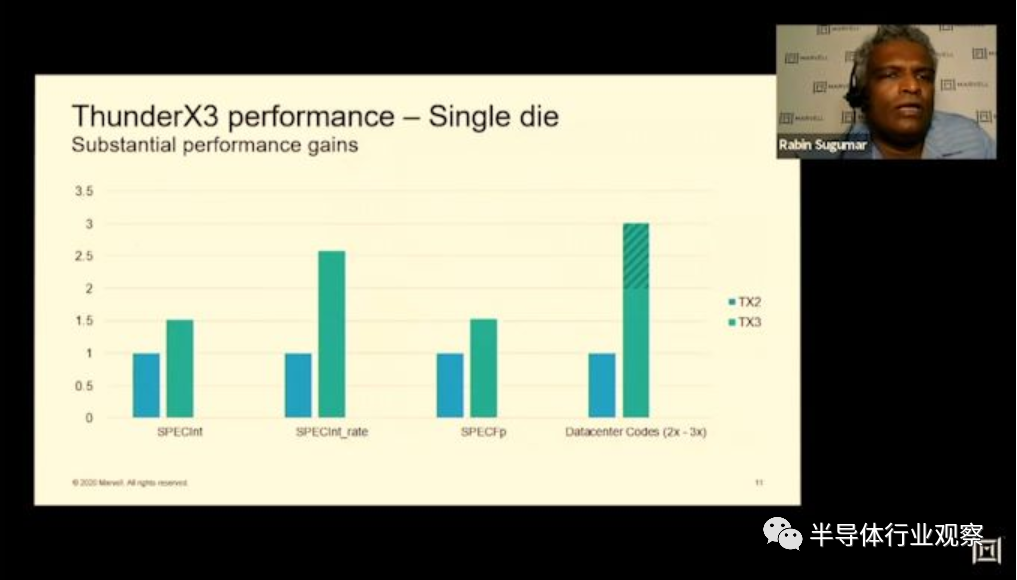
总体而言,新内核的世代IPC改进在SPECint中总计提高了30%,Marvell足够慷慨地向我们提供了新内核功能的概述,以及每个功能如何占总改进:
从结构方面来看,最大的改进是由于中核的OoO增长更大,尽管增长并不大,但IPC却提高了5%。与其他一些将L1I和L2缓存增加的结构加倍相比,这似乎是一个很好的折衷,这只会带来0.5%和2.5%的收益。
前端的加倍和从4到8的更宽解码仅带来性能2%的提高,这是非常温和的,但由于中核范围狭窄的dispatch和后端执行相对较窄,这可能会成为瓶颈。
IPC的最大改进是由于减少了解码器的微操作扩展。Marvell在此表示,他们在ThunderX2 Vulcan内核上就此方面过于积极,无法将指令扩展为多个微操作,因此他们已大大降低了这一点,这可能减轻了中核的瓶颈,并使每个实际指令的后端利用率更高。
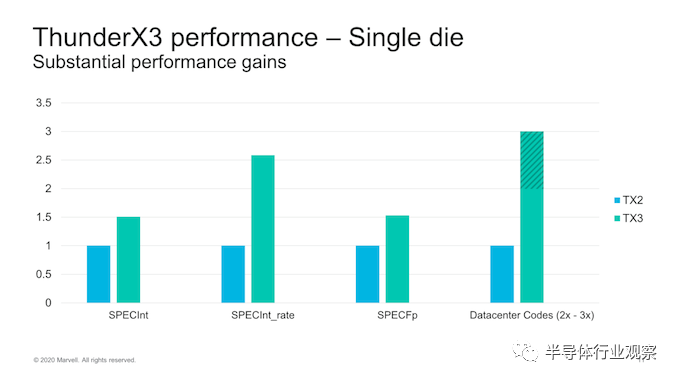
IPC增益和频率增益的代代性能改进,我们预计SPECint将获得1.5倍的增益。考虑到我们在TX2上的历史数据,通过这些预测,我们应该期望TX3的性能比Graviton2好10%左右。
由于新设计具有更高的核心数量,进一步扩大了微体系结构的改进,因此SPECrate增益自然会更高,约为性能的2.5倍。
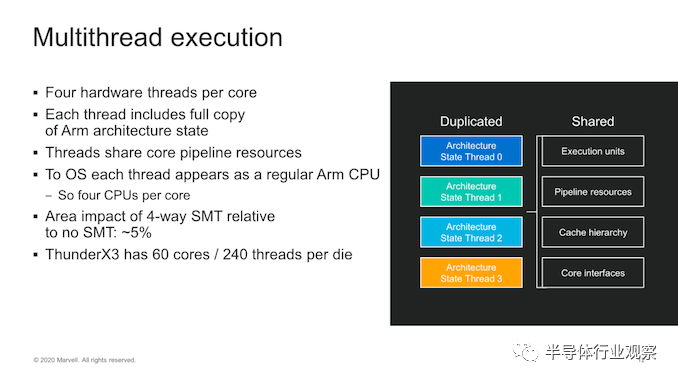
使Thunder系列在竞争中脱颖而出的原因之一是它包含4路SMT,这意味着每个内核最多可以执行4个线程。
从OS来看,每个线程都被视为完全独立的CPU,每个线程都有其自己独立的Arm架构状态,在绝大多数内核资源中共享了极少数例外,例如上述的Skid Buffer。
微体系结构一直是多线程的,但是Marvell继续重新考虑了SMT的区域影响,并透露它仅占用5%的内核。
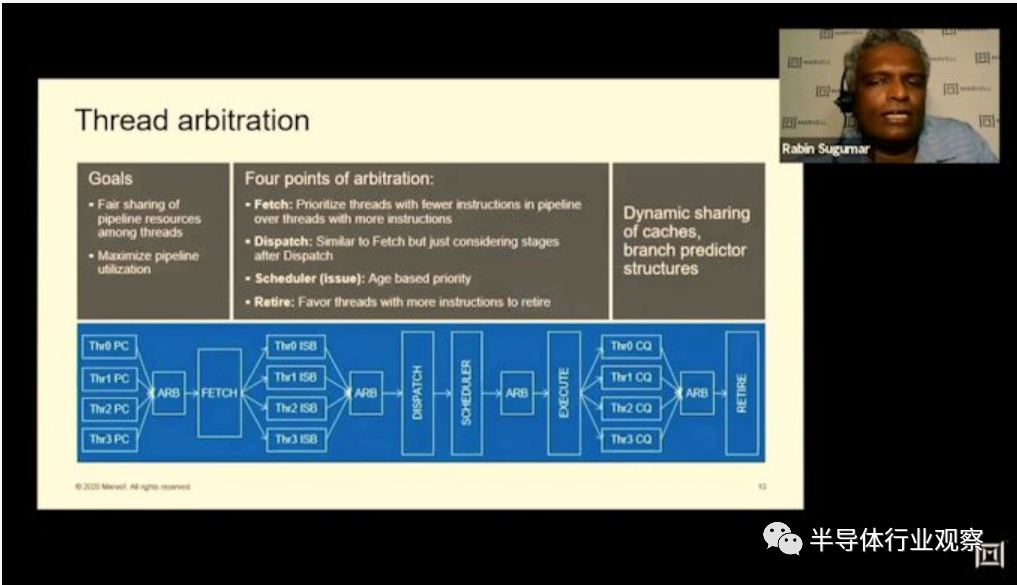
该公司进一步详细介绍了SMT的一些机制,例如线程之间的仲裁机制。例如,在获取阶段,内核将选择当前在内核pipeline中使用的指令量最少的线程,以确保在线程之间平衡微操作和指令的数量。我们在调度阶段看到了类似的逻辑,流水线中下游指令最少的线程是从Skid Buffer中挑选出来的。
后端没有线程的概念,仅执行最早的微操作。对于具有最多备份说明的线程,优先考虑退出。
Marvell说,该线程仲裁( thread arbitrations )在大多数代码上都可以很好地工作,线程之间的执行延迟非常统一。
SMT可以带来的加速与给定工作负载的IPC成反比,这意味着低IPC工作负载将带来SMT的最大改进。描述这种情况的另一种方式是以数据平面为中心的工作负载,这些数据对于执行执行的数据提取具有较高的延迟,因此更适合于通过SMT隐藏内核的这些瓶颈和空闲周期。
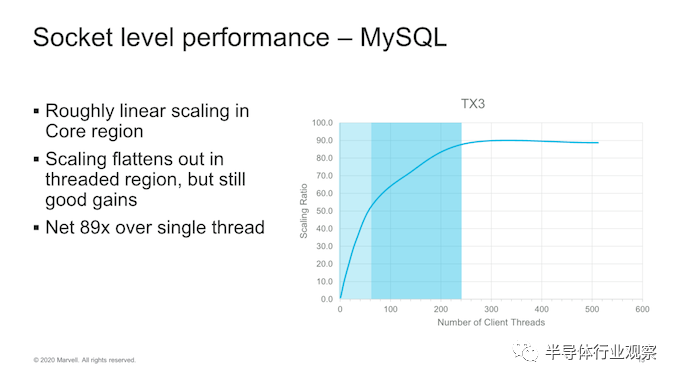
将其转换为 socket-level的性能,我们可以看到最多可扩展到60个内核,这实际上是处理器的物理内核数量,而次线性的却可以扩展到240个线程,但仍然相当可观。从SMT4到Marvell内核的面积影响很小,从60线程到240线程的性能提高了大约60%,这是一个不错的收益。
当被问及其ThudnerX3在竞争中的地位如何时,Marvell说,与基于Intel的产品相比,该公司在单线程性能方面将稍有落后,但将提供更大的多线程吞吐量。与AMD(假设罗马)相比,TX3在单线程性能上表现更好,而AMD在数据共享率低的工作负载方面处于领先地位,尽管TX3在数据共享更多的工作负载(例如数据库应用程序)中表现更好。Graviton2被认为是非常好的芯片,尽管它提供了低频且不提供线程支持,因此TX3会在这些方面更好。
总体而言,TX3似乎是当前服务器领域的可靠选择,但是尽管他提供SMT支持,但我并不认为它有多与众不同。我觉得CPU的微体系结构仍然很狭窄,尽管IPC的改进在世代上都是不错的,但Marvell的发布间隔也比Arm更长。在这方面,仅稍微击败Graviton2似乎还不够,我确实希望基于Altra的设计会更快。
我们必须看看ThunderX3如何在性能和功率效率方面达到最终目标,但是除了可以充分利用SMT的数据平面繁重的工作负载之外,我觉得对于Marvell来说,舒适性竞赛可能太接近了。对于消费者和企业而言,这两种方式都令人兴奋,因为这意味着我们将在不久的将来拥有大量可行的选择。
Hot Chips 2020:Marvell ThunderX3
在日前举办的Hot Chips 2020会议上,Marvell从其产品路线图开始演示,详细介绍了ThunderX3代不仅是单一设计,而且实际上代表了使用多个die的灵活方法,其中今年发布的第一代60核CN110xx SKU将使用单个die,明年将发布旨在提高性能的96核dual-die 版本。
从SoC的角度来看,ThunderX3芯片可扩展至60核,而dual-die 版本最多可扩展到96核。Marvell宣称在相同的功率水平下,ThunderX3性能比ThunderX2高出2-3倍。在问答环节中,Marvell透露,他们采用交换环拓扑而不是单环或网状设计的理由是,单核无法在更高内核数下提高性能和带宽。网格设计将是一个很大的变化,并且将需要减少核心数量。交换环代表了两种架构之间的良好折衷。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2407期内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
模拟芯片|蓝牙|
5G|GaN|台积电|英特尔|封装|晶圆
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!
责任编辑:Sophie