基于忆阻器的神经网络应用研究
2020-08-23
14:00:09
来源: 半导体行业观察
来源:文章转载自期刊《微纳电子与智能制造》,作者:陈 佳,潘文谦,秦一凡,王 峰,李灏阳,李 祎,缪向水。
 基于忆阻突触器件的硬件神经网络是神经形态计算的重要发展方向,是后摩尔时代突破传统冯·诺依曼计算架构的有力技术候选。综述了国内外忆阻硬件神经网络的近期发展现状,从器件发展和神经网络两个方面,详细阐述了忆阻器这一新兴信息器件在神经形态计算中所发挥的角色作用,讨论了依然存在的关键问题和技术挑战。忆阻器为实现存算一体化架构和超越摩尔定律提供了技术障碍突破的可行方案。
基于忆阻突触器件的硬件神经网络是神经形态计算的重要发展方向,是后摩尔时代突破传统冯·诺依曼计算架构的有力技术候选。综述了国内外忆阻硬件神经网络的近期发展现状,从器件发展和神经网络两个方面,详细阐述了忆阻器这一新兴信息器件在神经形态计算中所发挥的角色作用,讨论了依然存在的关键问题和技术挑战。忆阻器为实现存算一体化架构和超越摩尔定律提供了技术障碍突破的可行方案。
在当今数据量爆炸式增长的背景下,传统计算架构遭遇冯·诺依曼瓶颈,晶体管微缩,摩尔定律已难以延续,这已成为继续提升计算系统性能过程中难以克服的技术障碍
[1-4]
。神经形态计算概念的提出无疑是可以实现技术突破的一大曙光,人脑信息处理系统的复杂程度是最先进的超级计算机也无法媲美的。在已报道的神经形态计算架构芯片中,其计算能力显著提高,并且体积和能耗远小得多。因此,神经形态计算架构的发展在软件和硬件领域都被极度重视,有望替换当前计算系统架构。
而在众多用于实现神经形态计算的硬件元件中,忆阻器以其高集成度、低功耗、可模拟突触可塑性等特点成为一大有力备选。忆阻器早在1971年就由蔡少棠教授
[5]
以第4种无源基本电路元件的概念提出,2008年由惠普实验室首次在 Pt/TiO
2
/Pt三明治叠层结构中通过实验验证
[6]
。忆阻器首先因其电阻转变效应而被提出用作阻变存储器并被广泛研究。2010年密歇根大学卢伟教授团队
[7]
提出可以通过操控忆阻器件中离子迁移过程而精细调控器件电导值,率先在Si:Ag忆阻器中实验模拟实现了突触权重调节行为和脉冲时序依赖突触可塑性,从而掀起了忆阻人工神经突触和神经网络的研究热潮。
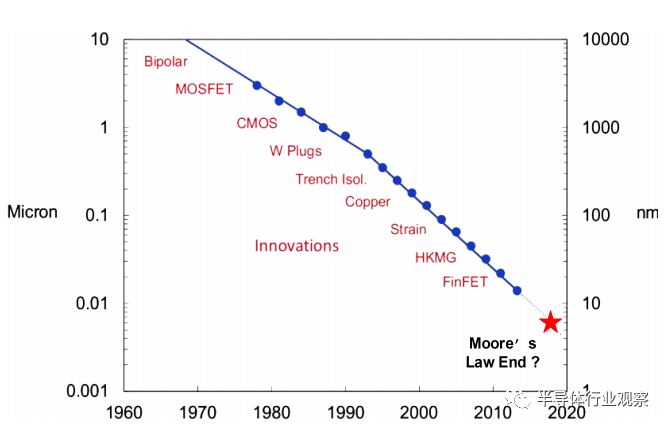
自1965年由英特尔(Intel)创始人之一GordonMoore提出摩尔定律以来,半导体行业的技术发展已经遵循这一定律超过了半个世纪,晶体管技术节点已经微缩到5nm以下,如图1所示
[2]
。但近年来,由于硅技术的物理极限,摩尔定律的发展被预言面临终结,芯片上的电子元器件不可能无限制地缩小。因此以密度驱动发展的晶体管技术也逐渐达到物理极限,超越摩尔定律的多功能新兴信息器件可能成为后摩尔时代信息技术中不可或缺的基石。
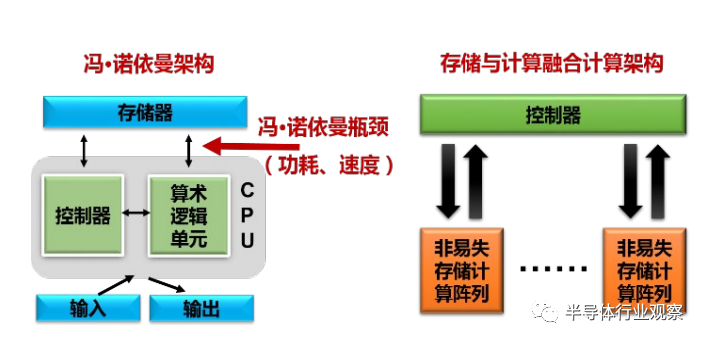
在大数据时代背景下,传统数据处理方法中存储器与处理器相分离的架构带来了冯·诺依曼瓶颈问题,即存储器和处理器的运行速度均能达到相当水平,但连接这两部分的总线传输速度远远达不到要求,频繁的数据通信消耗了大部分信息处理的时间和功耗。这种处理方法已经无法满足物联网、边缘计算等新应用需求。相比之下,人脑神经系统的信息活动具有大规模并行、分布式存储与处理、自组织、自适应和自学习等特征,数据存储与处理没有明显的界限,在处理非结构化数据等情况下具有非凡的优势。人工智能就是研究、开发用于模拟、延伸和扩展人的智能的系统,对人的意识、思维的信息过程进行模拟,在当今时代背景下具有巨大潜力。所以,未来的计算机体系结构可能需要改变传统的把计算和存储分开的冯·诺依曼架构,利用非易失存储器件,打破“存储墙”,模拟人脑处理机制,构建存储与计算相融合的存算一体计算架构,如图2所示。
图2.传统冯·诺依曼计算架构与基于非易失存储器的存算一体化架构
神经形态计算的研究与发展是通向未来人工智能时代,构建新型存算一体架构的赛道之一。在神经形态计算的研究领域,类神经网络与新型神经形态硬件是两大基础研究,在此研究基础上,结合对生物大脑机制的愈加深入了解,最终实现人工智能。
在类神经网络方面,以深度学习为基础的神经网络研究已经普遍存在于人工智能领域。神经网络,即以数学模型来模拟人脑神经元及突触的结构,并结合多层次传导来模拟神经元的互联结构,现如今已大量应用于人工智能。神经网络的发展一方面是基于对生物大脑的理解更贴切地去模拟其工作机制,如第三代人工神经网络——脉冲神经网络的提出与发展;另一方面是以片上网络配合软硬件以数学建模的方式来模拟脑内神经传导系统,目标侧重于理解脑部信号传导的方式,以从计算仿真角度反向助于了解大脑的运作方式。
在新型神经形态硬件方面,器件、电路以及整体架构设计都是极其重要的研究方向。在器件方面,基于新兴非易失性存储器的神经形态计算近来引起人们极大的关注,其中包括忆阻器
[8]
、相变存储器
[9]
、铁电存储器
[10]
、自旋电子器件
[11]
等,它们可用于模拟生物神经元和突触的特性,更重要的是它们都可能成为模拟存算一体计算的基础技术。在电路设计方面,主要是实现仿生信号的产生与处理,以及模拟-数字混合信号的高效处理。在整体架构设计方面,实现存算一体化是核心目标,有助于大幅减少数据迁移开销,提高处理效率,克服冯·诺依曼瓶颈和存储墙问题。
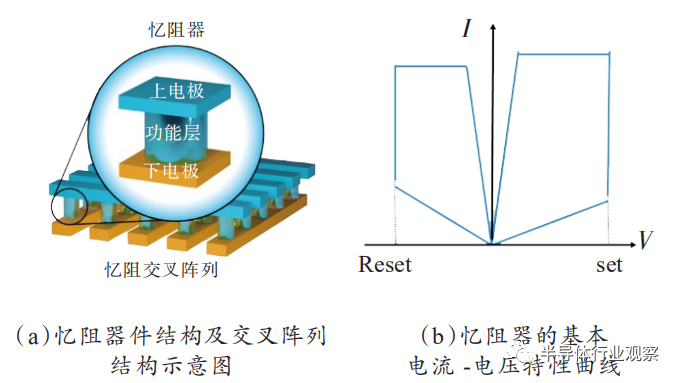
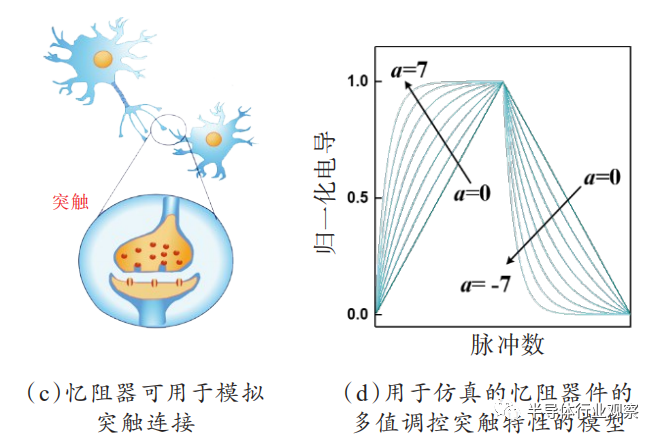
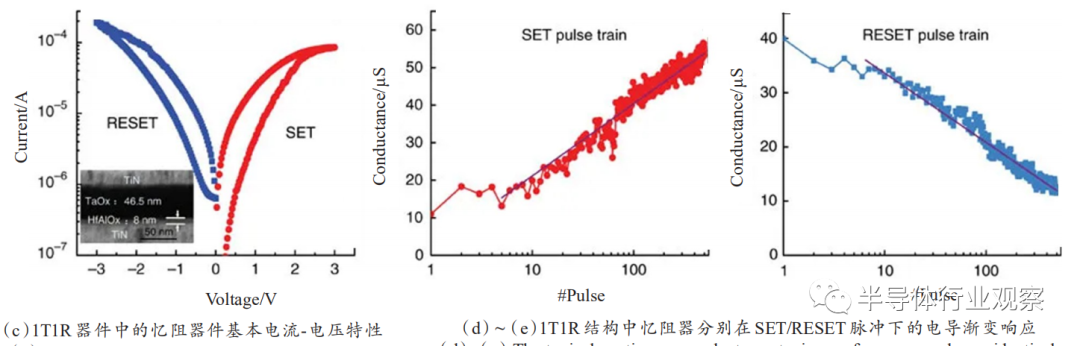
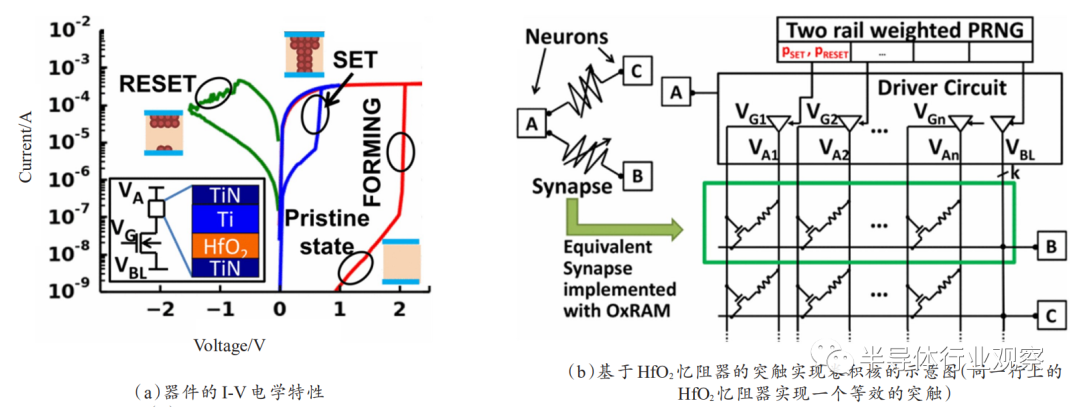
忆阻器是一个简单的金属-绝缘体-金属(MIM)三明治结构,在电压操作下能实现阻态翻转,如图3(a)、(b)所示。对于双极性忆阻器来说,施加正电压能将器件从高阻态转变为低阻态,称为SET过程,反之施加负电压能将器件从低阻态重新转变为高阻态,称为RESET过程。因此,忆阻器在初期被广泛作为阻变存储器开展研究,在器件结构、材料等方面得到广泛研究并不断提出其优化设计方案。2011年,美国密歇根大学卢伟教授团队以忆阻器的导电丝生长与断裂的阻变机制为出发点,验证了器件的电导可以在电压脉冲激励下逐渐变化,即导电丝可以在外部激励下逐渐生长和断裂,从而贴切地模拟了生物突触权重在外界刺激下的逐渐增强或减弱,如图3(c)、(d),并通过实验验证了器件对生物突触可塑性—脉冲时序依赖可塑性(STDP)的可模拟性。自此,忆阻突触器件成为神经形态计算中新型电子突触器件的有力候选者之一。
(1)具有良好的生物突触特性模拟性。作为突触器件必须具备基本的生物突触特性,如长时程增强(long-term potentiation,LTP)和长时程抑制(longterm depression,LTD),脉冲时序依赖可塑性(spiketiming dependent plasticity,STDP),脉冲频率依赖可塑性(spike-rate dependent plasticity,SRDP)等
[
12]
;
(2)突触单元在特征尺寸、功耗、速度等方面具有优于传统晶体管突触电路的明显优势;
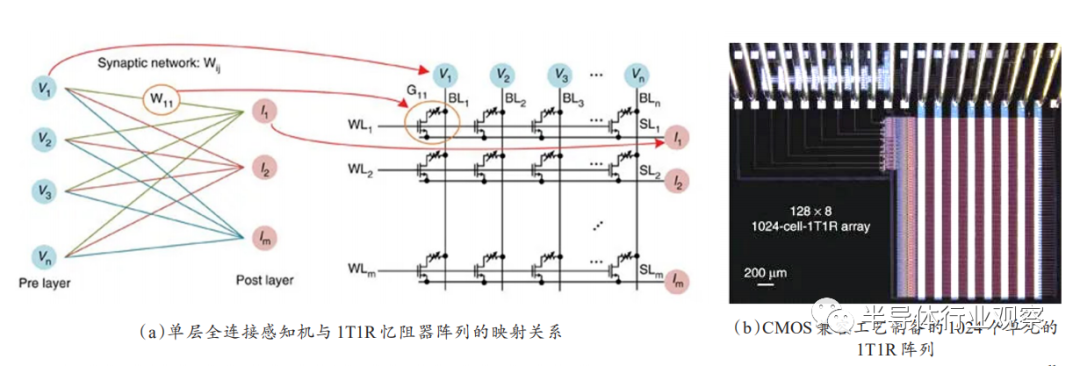
(3)忆阻突触器件具备可扩展性,包括在材料方面能被广泛应用,同时在集成度上也能大规模扩展。单个突触器件的功能是基本需求,而大规模扩展和应用是必要考虑的路线,忆阻器与晶体管进行集成的1T1R阵列就是一个研究瞩目的规模扩展应用方向。
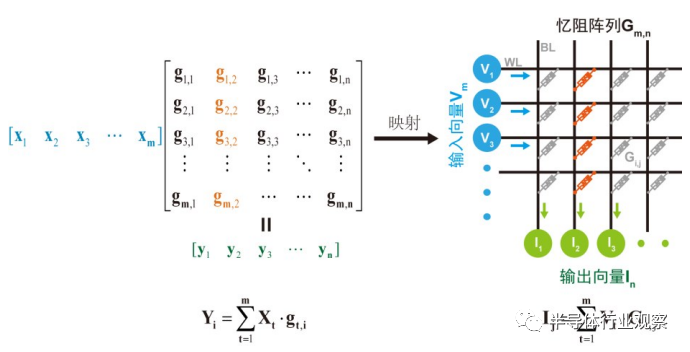
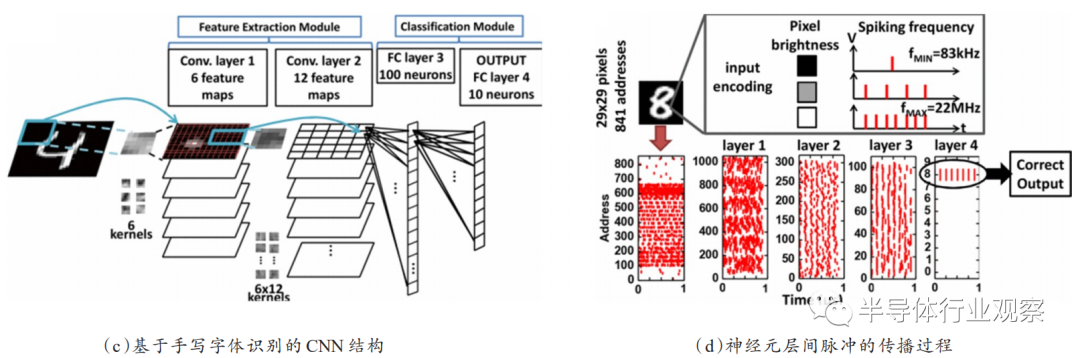
近年来,基于忆阻器的神经网络存算一体加速器倍受学术界和工业界的关注。研究表明,数据在CPU和片外存储之间的传输消耗的能量比一个浮点运算所消耗的能量高2个数量级。一方面,基于忆阻器的内存加速器将计算与存储紧密结合,从而省去传统的冯·诺依曼体系结构的中心处理器和内存之间的数据传输,进而提升整体系统的性能并节省大部分的系统能耗。另一方面,通过在忆阻器阵列外部加入一些功能单元,阵列能在几乎一个读操作的延迟内完成一次矩阵乘加计算(multiplication andaccumulation,MAC),如图4所示,且不随着输入维度的增加而增加,而MAC运算在神经网络计算中被非常频繁地使用,是其主要耗能来源之一。因此,基于忆阻突触器件的神经网络应用是神经形态计算研究中的热门方向
[13-23]
。
目前,神经形态计算的具体实现包括软件和硬件两个方面。对于神经形态计算的软件实现方面,即类神经网络,由于现有计算机系统的冯·诺伊曼瓶颈问题,即使神经网络本身具有分布式、并行式等计算特点,但依托于传统计算机架构在大数据计算时仍然会被限制其运算速度,且功耗极大。因而神经网络的硬件化实现是当前从根本上解决冯·诺依曼瓶颈问题的重要路线。如美国DARPA资助 IBM、HP、HRL公司联合密歇根大学、斯坦福大学等研究机构开展的“突触计划”(SYNAPSE Project,神经形态可扩展的自适应可塑性电子系统)等都展现了国际上对于神经网络硬件化实现的关注与投入。以IBM的TrueNorth芯片
[24]
、寒武纪的DaDianNao芯片
[25]
,清华大学的天机芯片
[26]
等为例,目前很多神经形态芯片的实现都是基于传统金属-氧化物-半导体(metal-oxide-semiconductor,CMOS)晶体管。而在神经系统中,突触数量远远超过神经元数目,基于传统CMOS晶体管的突触电路会消耗大量面积和功耗。
因此近年来,基于新型电子突触器件的神经形态计算芯片研究火热,在目前的IoT时代发展潮流下,是边缘计算的强有力载体。美国密歇根大学卢伟教授团队
[27]
第一款基于忆阻器交叉阵列的通用存算一体化芯片,同时实现了3种人工智能的算法,包括多层感知机、稀疏编码以及无监督学习算法。中国台湾清华大学的张孟凡教授研究组
[28]
利用1T1R器件阵列和65nm CMOS工艺的控制和读出电路的集成实现了一个1Mb的忆阻存算一体处理器,可同时实现神经网络的模拟计算和可重构逻辑的数字计算,同时利用了忆阻器件的多值突触特性和二值阻变特性,充分展示了忆阻突触器件在神经形态计算应用中的优势。
人工网络的发展源自于1943年McCulloch和Pitts
[29]
提出的首个用建模描述大脑信息处理过程的M-P神经元模型,进而于1949年,Hebb
[30]
提出了一种突触是联系可变的假设,促进了神经网络的学习算法的研究,直到1957年 Rosenblat
[31]
提出了感知机模型,它被称为是首个比较完整的人工神经网络,并且首次把神经网络的研究应用在实际工程中。至此,关于人工神经网络的相关研究进入了热潮。
自忆阻器被用作电子突触器件以来,由于忆阻器中离子的迁移十分类似于神经突触中神经递质的扩散过程,于是利用忆阻器来模拟神经网络中的突触成为一大趋势,被广泛运用在神经网络中存储突触权值。大量的实验证明,用忆阻器来模拟神经网络中的突触将会有很大的前景优势。具体地,忆阻器作为一种基本的无源器件,所具有的纳米级尺寸及非易失性,不仅能够在模拟神经突触时实现突触权值的不断变化,实现存算一体化,还可以构建集成度比较高的神经网络结构,这使得人工神经网络不仅具有学习记忆的能力,同时其功能也变得更加多样化
[32-39]
。
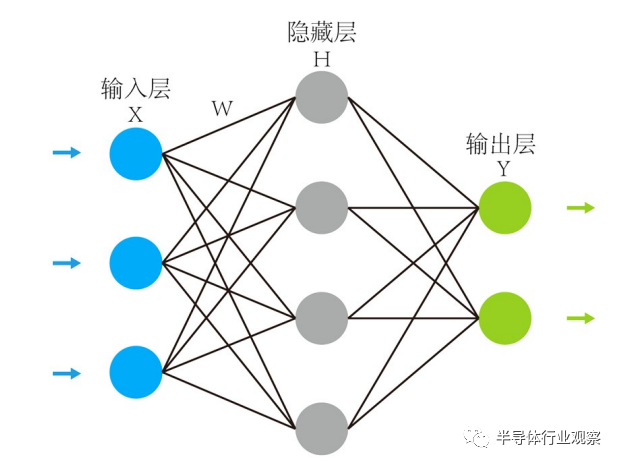
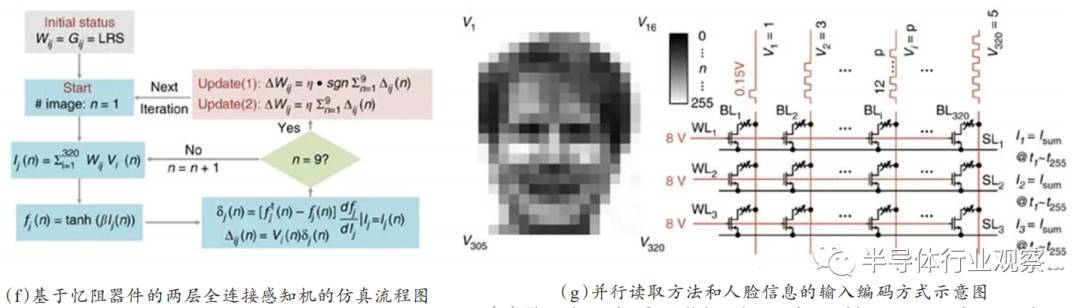
多层感知机模型,网络结构如图5所示,普遍被称为人工神经网络,是基于第一代神经网络——感知机模型的应用扩展。由于单层感知机只能解决基本逻辑线性问题,其表示用一条直线分割的空间,因此为解决非线性问题,通过在输入层与输出层之间加入隐藏层,用以实现异或问题的解决,最简单的多层感知机只有一个隐藏层,层与层之间是全连接的。以简单的3层结构为例,从输入层输入向量X,输入层与隐藏层的神经元以全连接方式互连,从而产生突触连接权重矩阵 W,将输入向量X与权重矩阵W进行矩阵向量乘法运算,即可以得到隐藏层的输出向量H,以此类推,输入信息可以在全连接的层之间通过权重矩阵向前传播,得到输出结果Y。在多层感知机中,最常采用的权重更新算法是反向传播算法,通过理想的输出结果Z与实际输出结果Y产生误差值,将误差值通过全连接多层网络反向传递,以误差函数梯度下降的方法,更新各层之间的权重矩阵值,以将最终输出的误差值收敛到最小。
不难看出,在多层感知机神经网络的计算过程中,输入信息向量与权重矩阵之间的矩阵向量乘法运算消耗了大量计算资源,因而利用忆阻交叉阵列并行一步实现矩阵向量乘法计算,可以大大减少硬件化神经网络的能耗。在基于忆阻突触器件的多层感知机应用中,忆阻交叉阵列被用来存储突触权重矩阵,每一个交叉点处的忆阻器的电导值被用来表示一个突触连接的权重值
[40-42]
。
清华大学吴华强教授团队
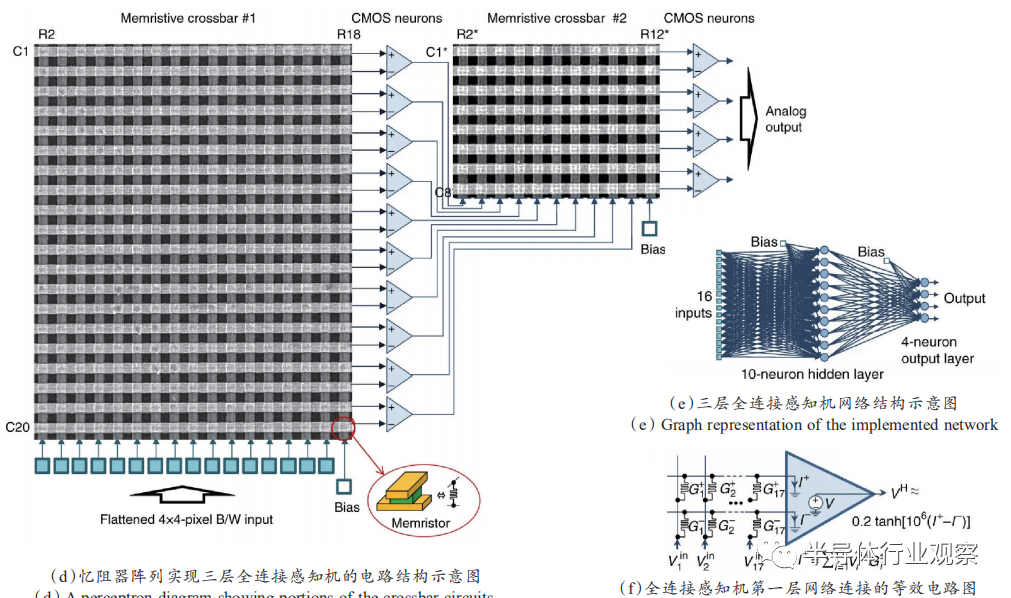
[41]
2017年在NatureCommunication上发表研究成果,如图6所示,利用1T1R器件单元模拟突触特性,实现双向的器件电导调制,并在1K的1T1R阵列中实现了3层全连接多层感知机,并通过在线学习的方式实现了耶鲁人脸数据库的灰度人脸图像识别,对9000个加入噪声影响的测试图片识别率可达到88.08%。与基于常规计算平台的Intel Xeon Phi处理器的神经网络计算对比,基于1T1R阵列的神经网络在片上计算方式上能耗相比低1 000倍,在片外计算方式上能耗相比低20倍。
 图6.在1T1R阵列中实现人脸识别任务
美国加利福尼亚大学圣芭芭拉分校Strukov教授团队
[42]
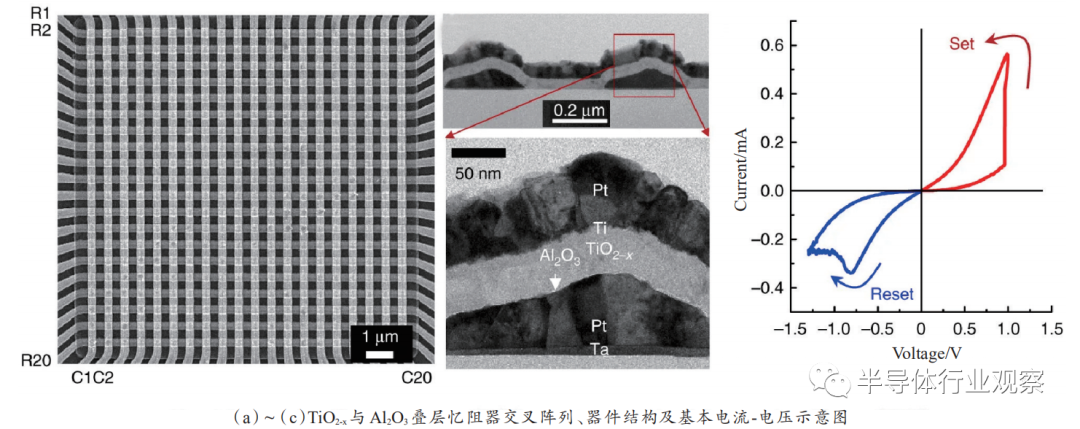
设计制备了20×20的金属氧化物交叉阵列,如图7所示,在器件方面,该忆阻器的中间功能层采用TiO
2-x
与Al
2
O
3
叠层,Al
2
O
3
叠层作为阻挡层的引入使得器件的基本I-V特性变得更加非线性,这种非线性的引入有助于忆阻器的0T1R阵列中漏电流问题的抑制。同时根据器件截面图,器件制备过程中底电极沉积成三角形形状,这样的设计一方面可以让功能层更好地覆盖下电极,另一方面也可以以此降低顶电极的接触电阻。在此研究成果基础上,该团队进一步地将忆阻器交叉阵列与传统 CMOS外围电路进行互联,设计实现了单隐藏层的多层感知机用于分类功能,硬件设计复杂度提高了10倍以上,离线学习的分类准确度高达97%以上。
图7.利用Pt/Al
2
O
3
/TiO
2
−x/Ti/Pt忆阻阵列实现三层全连接感知机网络
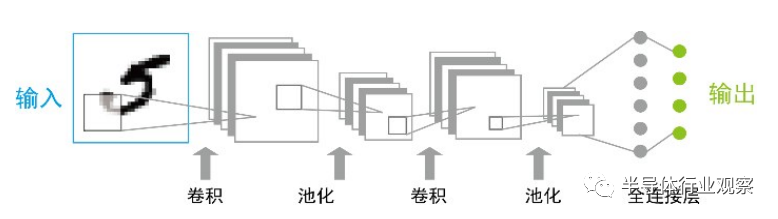
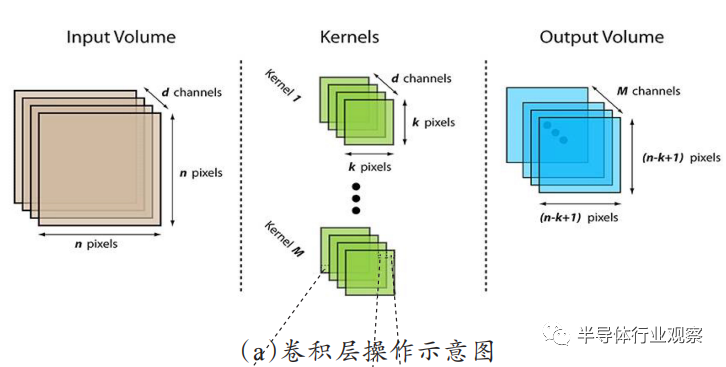
卷积神经网络(convolutional neural network,CNN)的出现解决了图像对于神经网络来说的难点:大量的图像处理数据导致成本高、效率低;在数字化的过程中很难保留原有的图像特征,导致图像处理的准确率不高。CNN通过卷积运算降维,减小参数复杂度,将复杂问题简化后再做处理,并且用类似视觉的方式保留了图像的特征,当图像做翻转、旋转或者变换位置时,它也能有效地进行识别。典型的CNN由3部分构成:卷积层、池化层和全连接层,如图8所示,简单来描述:卷积层通过卷积操作提取图像中的局部特征;池化层通过平均池化或最大池化操作(特殊的卷积操作)来大幅降低参数量级(降维);全连接层类似传统神经网络的部分,用来实现分类功能输出分类识别结果。因此,卷积神经网络相较于多层感知机应用更广泛,泛化能力更强大。
基于忆阻器交叉阵列实现卷积神经网络主要包括两个部分:卷积操作部分和全连接层部分。一方面,忆阻器阵列可以存储卷积核值,实现一步完成输入信息与卷积核的矩阵向量乘法计算,大大提高计算效率;另一方面,卷积神经网络的全连接层部分即为一个多层感知机,如前所述也可以利用忆阻器交叉阵列并行实现
[43-46]
。
法国的Garbin等
[45]
首次展示了基于多个并联二值HfO
2
忆阻器实现一个突触功能来搭建脉冲CNN,如图9所示,基于对器件编程条件的影响进行实验和理论研究,发现即使在器件变化较大的情况下,也可以实现具有高保真度的视觉模式识别(模式识别率>94%)。该工作证实了将忆阻器用作CNN中突触器件的可行性,并且基于氧化物的忆阻器件具有低开关能耗和高操作耐久性。
IBM团队Gokmen等
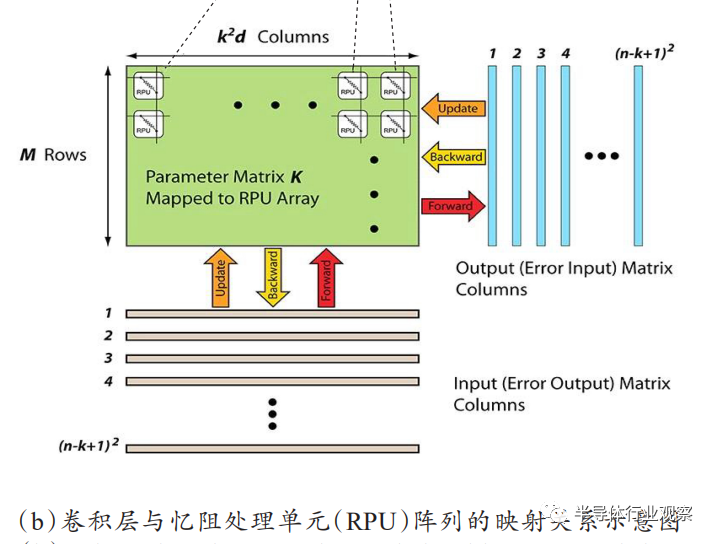
[46]
提出了利用硬件的并行性将卷积层映射到忆阻阵列的方法,以及具体研究了如何在忆阻器上进行CNN训练,如图10所示,提出了噪声和边界管理技术以解决在阵列上执行的计算施加的噪声和边界限制影响CNN的训练准确性的问题,并且讨论了器件随机可变性对网络的影响以及解决的方法,进一步探讨基于忆阻器的卷积神经网络可行性。
图6.在1T1R阵列中实现人脸识别任务
美国加利福尼亚大学圣芭芭拉分校Strukov教授团队
[42]
设计制备了20×20的金属氧化物交叉阵列,如图7所示,在器件方面,该忆阻器的中间功能层采用TiO
2-x
与Al
2
O
3
叠层,Al
2
O
3
叠层作为阻挡层的引入使得器件的基本I-V特性变得更加非线性,这种非线性的引入有助于忆阻器的0T1R阵列中漏电流问题的抑制。同时根据器件截面图,器件制备过程中底电极沉积成三角形形状,这样的设计一方面可以让功能层更好地覆盖下电极,另一方面也可以以此降低顶电极的接触电阻。在此研究成果基础上,该团队进一步地将忆阻器交叉阵列与传统 CMOS外围电路进行互联,设计实现了单隐藏层的多层感知机用于分类功能,硬件设计复杂度提高了10倍以上,离线学习的分类准确度高达97%以上。
图7.利用Pt/Al
2
O
3
/TiO
2
−x/Ti/Pt忆阻阵列实现三层全连接感知机网络
卷积神经网络(convolutional neural network,CNN)的出现解决了图像对于神经网络来说的难点:大量的图像处理数据导致成本高、效率低;在数字化的过程中很难保留原有的图像特征,导致图像处理的准确率不高。CNN通过卷积运算降维,减小参数复杂度,将复杂问题简化后再做处理,并且用类似视觉的方式保留了图像的特征,当图像做翻转、旋转或者变换位置时,它也能有效地进行识别。典型的CNN由3部分构成:卷积层、池化层和全连接层,如图8所示,简单来描述:卷积层通过卷积操作提取图像中的局部特征;池化层通过平均池化或最大池化操作(特殊的卷积操作)来大幅降低参数量级(降维);全连接层类似传统神经网络的部分,用来实现分类功能输出分类识别结果。因此,卷积神经网络相较于多层感知机应用更广泛,泛化能力更强大。
基于忆阻器交叉阵列实现卷积神经网络主要包括两个部分:卷积操作部分和全连接层部分。一方面,忆阻器阵列可以存储卷积核值,实现一步完成输入信息与卷积核的矩阵向量乘法计算,大大提高计算效率;另一方面,卷积神经网络的全连接层部分即为一个多层感知机,如前所述也可以利用忆阻器交叉阵列并行实现
[43-46]
。
法国的Garbin等
[45]
首次展示了基于多个并联二值HfO
2
忆阻器实现一个突触功能来搭建脉冲CNN,如图9所示,基于对器件编程条件的影响进行实验和理论研究,发现即使在器件变化较大的情况下,也可以实现具有高保真度的视觉模式识别(模式识别率>94%)。该工作证实了将忆阻器用作CNN中突触器件的可行性,并且基于氧化物的忆阻器件具有低开关能耗和高操作耐久性。
IBM团队Gokmen等
[46]
提出了利用硬件的并行性将卷积层映射到忆阻阵列的方法,以及具体研究了如何在忆阻器上进行CNN训练,如图10所示,提出了噪声和边界管理技术以解决在阵列上执行的计算施加的噪声和边界限制影响CNN的训练准确性的问题,并且讨论了器件随机可变性对网络的影响以及解决的方法,进一步探讨基于忆阻器的卷积神经网络可行性。
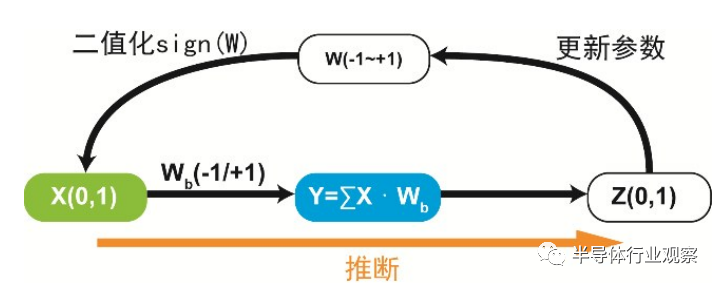
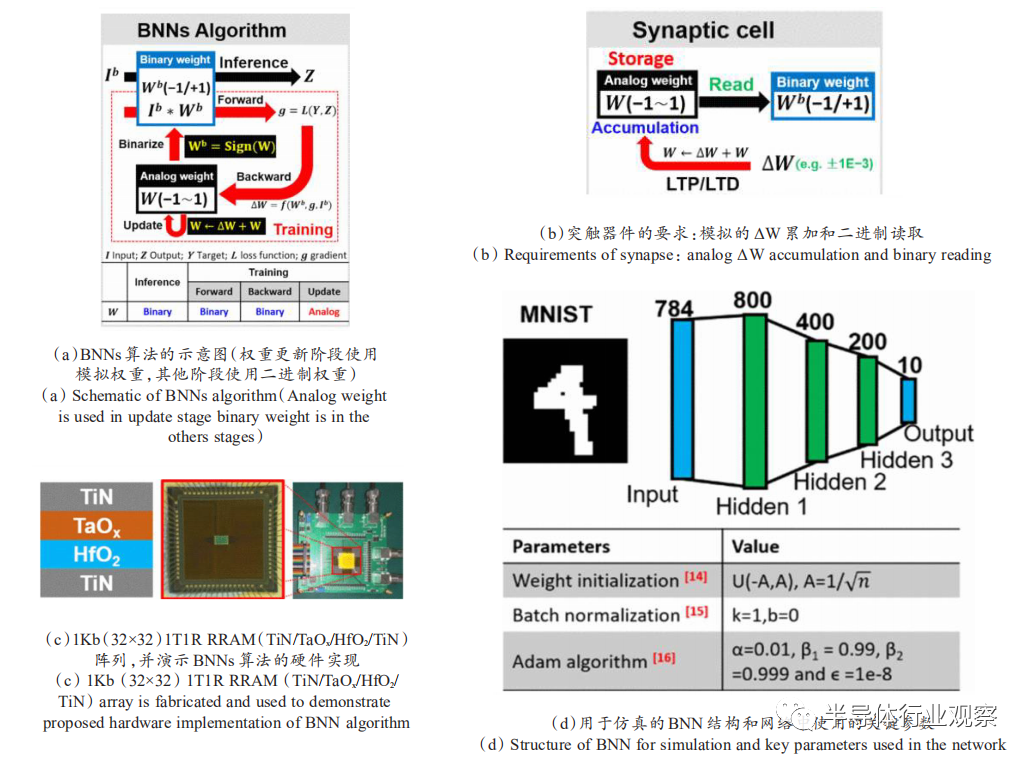
二值神经网络(binarized neural network,BNN)是神经网络“小型化”探索中一个重要的方向。神经网络中有两个部分可以被二值化,一是网络的权重,二是网络的中间结果。通过把浮点单精度的权重变成+1或-1,存储空间大小变为原来的1/32,计算量变为原来的1/58。其中,权值参数W,必须包含实数型的参数,然后将实数型权值参数二值化得到二值型权值参数,即Binarize操作,如图11所示。具体二值化方法为:大于等于0,取+1;否则,取-1。因此,仅用+1/-1构成权值矩阵和网络传播参数,压缩芯片体积并加速了计算过程,大大减少了存储大小和访问操作,并以逐位操作取代大多数算术操作,这将大大提高能耗效率,更适合应用于设备端的边缘计算。而忆阻器件最基本的高低阻态的二值转变特性非常完美地满足了二值神经网络对于突触器件的需求,特别地,相较于忆阻器件的多值突触特性,其二值特性更稳定,从器件工程方面来说也更容易实现。因此,基于忆阻器件的二值神经网络从硬件实现方面来说极具挖掘性。
北京大学康晋锋教授团队
[47]
在基于忆阻器件的二值神经网络实现上,首次提出了一种新的硬件实现方法,如图12所示,利用非线性突触单元来构建用于在线训练的BNN。通过忆阻器阵列设计和演示基于2T2R的突触单元,以实现BNN 中突触的基本功能:二进制权重(sign(W))读取和模拟权重更新(W +ΔW)。通过MNIST对基于2T2R突触单元的BNN的性能进行了评估,识别准确率达到97.4%。
亚利桑那州立大学Yu课题组
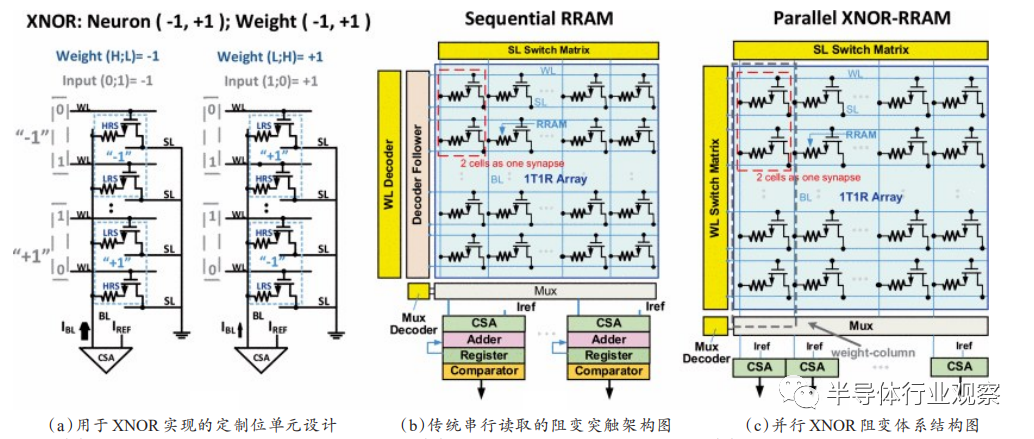
[48]
用忆阻器交叉阵列实现二值神经网络计算加速,具体地采用XNOR同或逻辑加速和bit-counting并行操作来代替复杂的乘法累加操作,如图13所示,并且在基于手写字体数据集的多层感知机上实现98.43%识别准确率,在基于CIFAR-10数据集的卷积神经网络上实现86.08%的准确率,分别比理想情况下降0.34%和2.39%的识别精度,该工作能耗为141.18TOPS/W,相较于顺序逐行读取的忆阻神经网络,能耗效率提高约33倍,验证了二值神经网络的在速度和能耗上的潜在优势。
图13.忆阻器交叉阵列实现二值神经网络计算加速方法
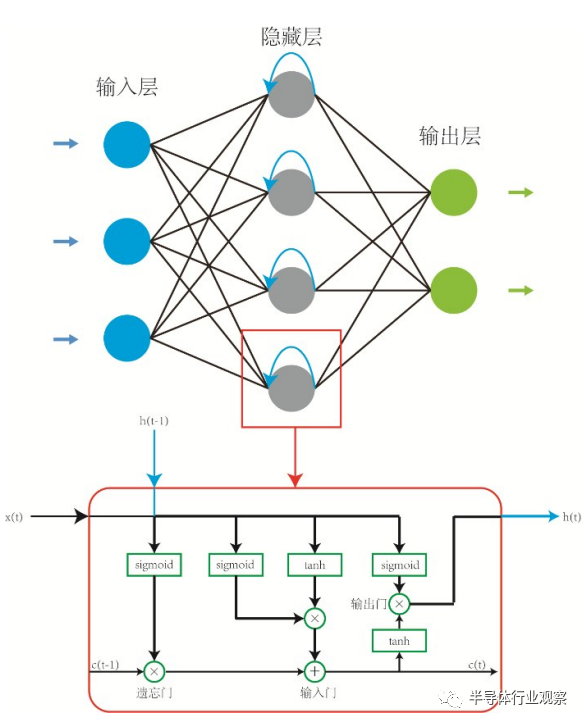
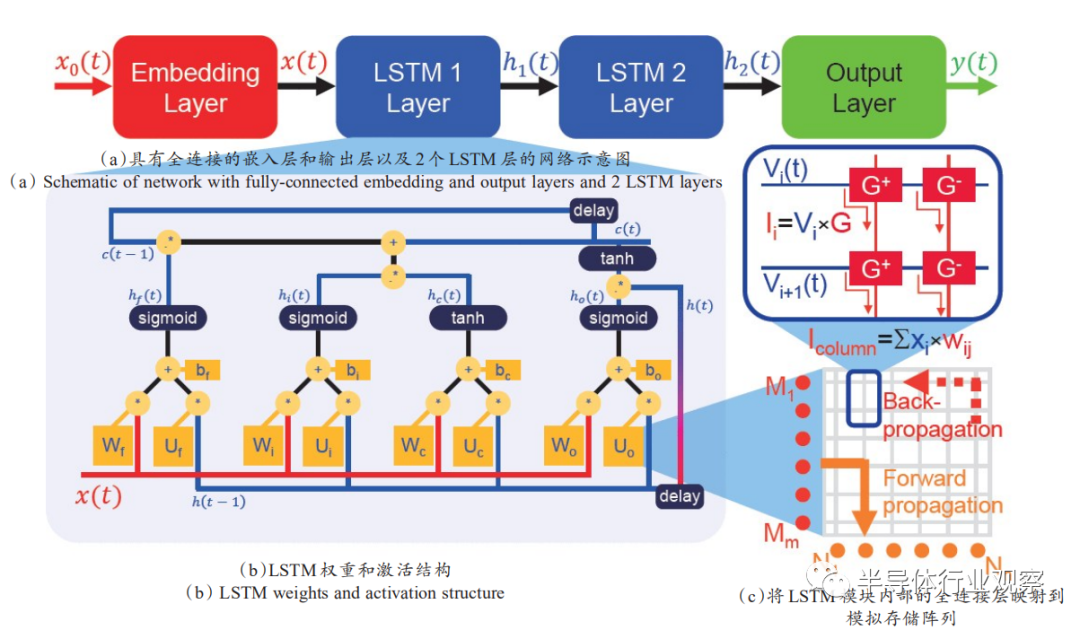
长短期记忆网络(long short- term memory,LSTM),是一种时间递归神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的事件。LSTM是一种特殊的循环神经网络,为解决循环神经网络(recurrent neural network,RNN)结构中存在的“梯度消失”问题而提出,网络结构如图14所示。LSTM在设计上明确避免了长期依赖的问题,主要归功于LSTM精心设计的“门”结构(输入门、遗忘门和输出门)消除或者增加信息到单元状态的能力,使得LSTM能够记住长期的信息。在LSTM中,第一阶段是遗忘门,遗忘层决定哪些信息需要从单元状态中被遗忘,下一阶段是输入门,输入门确定哪些新信息能够被存放到单元状态中,最后一个阶段是输出门,输出门确定输出什么值。同样,利用忆阻阵列实现突触功能以及存算一体,在LSTM这种循环网络有很大优势,可以实现高度并行的高速低功耗操作,是基于忆阻器件的又一神经网络功能实现。
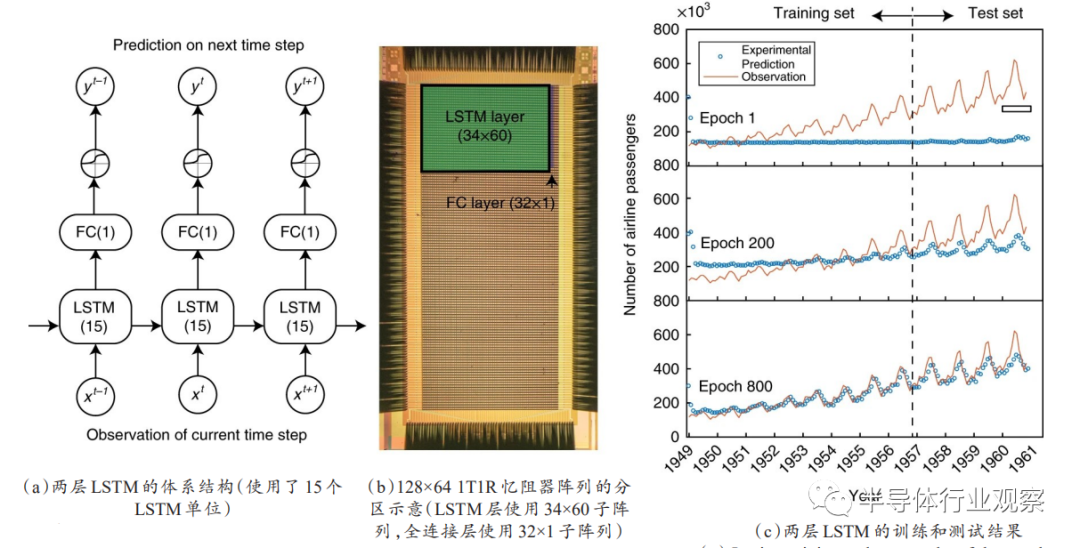
美国马萨诸塞大学杨建华团队
[49]
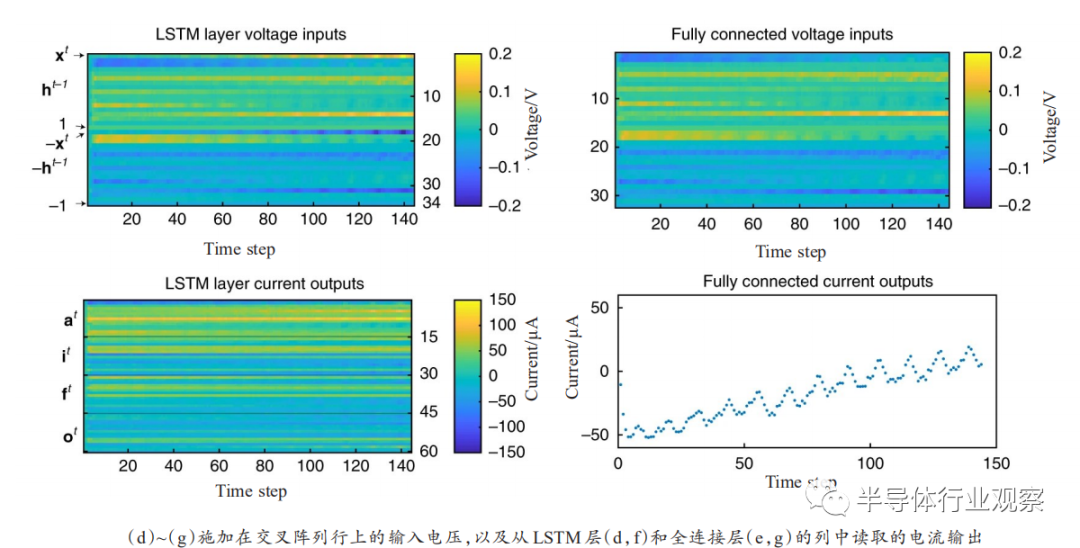
首先在128×64的1T1R阵列上实现了LSTM神经网络,如图15所示,利用忆阻器交叉阵列来存储LSTM在不同时间步长中共享的突触权重,并执行了全球航空旅客人数预测任务和人类步态识别任务,分别验证了忆阻LSTM执行线性回归预测类任务和模式识别类任务的可行性,验证了忆阻阵列作为低延时、低功耗的边缘推断平台运行LSTM神经网络的可行性,有助于规避“冯·诺依曼瓶颈”问题。
图15.基于忆阻突触阵列的LSTM网络以预测下个月的航空公司乘客人数
IBM公司的Burr团队
[50]
在器件非一致性较高的情况下将权重参数映射和编码到相变存储器(phasechange memory, PCM)电导中,采用了两对器件分别表示高低位权重、权重裁切、单向电导调节等方法,网络设计如图16所示,实现了LSTM的前向推断,并且首次在2.5M大小的阵列中实现了近似软件的文本预测准确率,同时对比了多种不同方法对权重映射准确度和预测准确度的影响。
图16.基于相变存储器件单元的长短期记忆网络实现方法
总的来说,基于忆阻器的神经网络应用是神经形态计算不可或缺的研究方向。忆阻器以自身的突触可塑性、低功耗、高效率、可集成等优势在神经网络应用中被大量研究,实现了多样化的忆阻神经网络,包括多层感知机、卷积神经网络、长短期记忆网络等。忆阻器主要被用作神经网络中的突触器件,其在脉冲下的多值调控特性完美地实现突触权重硬件化映射,能够存储突触权重矩阵并实现原位计算。忆阻器交叉阵列的并行矩阵乘加运算能力实现了神经网络计算的加速神经网络计算。因此,基于忆阻器的神经网络是其硬件化的有效实现方案,为构建存算一体化的新型计算架构提供解决办法。
但在神经网络的硬件化实现方面,仍然存在许多亟待解决的问题,以及需要深入思考的困惑。主要包括以下几个方面:
(1)忆阻器件的突触特性仍需进一步提高,如忆阻器的多值电导调控特性,在当前研究中只考虑了脉冲连续施加情况下电导的连续改变,但对于实际应用来说,稳定且非易失的每一个电导状态是必要的。因此,如何定义忆阻器的电导连续变化过程中的多值,以及如何从器件工程层面改善器件的稳定多值特性,是目前忆阻突触器件在实际硬件实现过程中的一大难题。
(2)忆阻器的导电丝阻变机理造成了器件本征的不可消除的噪声问题。由于导电丝在形成和断裂过程中都不可能完全受外部施加的激励所控制,其随机性不可消除,因此使得忆阻器的本征噪声问题无法解决。而在神经网络应用中,这一本征噪声问题的影响是否会对系统造成损耗还不可获知,需要更进一步的研究和实验验证。
(3)在当前的研究成果中,忆阻阵列具有传统CMOS逻辑电路不可比拟的并行计算能力和存储与计算相融合的特点,但忆阻突触器件的模拟计算特性与外围CMOS数字电路无法完全兼容,数模/模数转换成为忆阻阵列与CMOS集成的电路设计的难点。过于复杂的外围电路会提高系统的整体功耗,与忆阻阵列的引入初衷相悖。
[1] MOORE G. Moore’s law[J]. Cramming more components onto integrated circuits[J]. Electronics, 1965, 38(8): 114-117.
[2] HOLT W M. 1.1 Moore’s law: a path going forward[C]//2016 IEEE International Solid-State Circuits Conference(ISSCC). IEEE, 2016: 8-13.
[3] JONES V F R. A polynomial invariant for knots via vonNeumann algebras[M]. New Developments in The Theory of Knots, 1985.
[4] BACKUS J W. Can programming be liberated from thevon Neumann style? A functional style and its algebra ofprograms[J]. Communications of the ACM, 1978, 21(8):613-641.
[5] CHUA L. Memristor-the missing circuit element[J].IEEE Transactions on Circuit Theory, 1971, 18(5): 507-519.
[6] STRUKOV D B, SNIDER G S, STEWART D R, et al.The missing memristor found[J]. Nature, 2008, 453(7191): 80-83.
[7] JO S H, CHANG T, EBONG I, et al. Nanoscale mersister device as synapse in neuromorphic systems[J]. NanoLetters, 2010, 10(4): 1297-1301.
[8] CHEN J, LIN C Y, LI Y, et al. LiSiOx- based analogmemristive synapse for neuromorphic computing[J].IEEE Electron Device Letters, 2019, 40(4): 542-545.
[9] AMBROGIO S, NARAYANAN P, TASI H, et al. Equivalent- accuracy accelerated neural- network training usinganalogue memory[J]. Nature, 2018, 558(7708): 60-67.
[10] JERRY M, CHEN P Y, ZHANG J, et al. FerroelectricFET analog synapse for acceleration of deep neural network training[C]// 2017 IEEE International Electron Devices Meeting (IEDM). IEEE, 2017: 6.2.1-6.2.4.
[11] WU M H, HONG M C, CHANG C C, et al. Extremelycompact integrate-and-fire STT-MRAM neuron: A pathway toward all- spin artificial deep neural network[C]//2019 Symposium on VLSI Technology. IEEE, 2019: T34-T35.
[12] LI Y, ZHONG Y, ZHANG J, et al. Activity- dependentsynaptic plasticity of a chalcogenide electronic synapsefor neuromorphic systems[J]. Scientific Reports, 2014, 4 (6184): 4906.
[13] CHEN P Y, PENG X, YU S. NeuroSim: A circuit-levelmacro model for benchmarking neuro-inspired architectures in online learning[J]. IEEE Transactions on Computer- Aided Design of Integrated Circuits and Systems,2018, 37(12): 3067-3080.
[14] DEGUCHI Y, MAEDA K, SUZUKI S, et al. Error-reduction controller techniques of TaOx- based ReRAM fordeep neural networks to extend data- retention lifetimeby over 1700x[C]// 2018 IEEE International MemoryWorkshop (IMW). IEEE, 2018: 1-4.
[15] DIEHL P U, COOK M. Unsupervised learning of digitrecognition using spike- timing- dependent plasticity[J].Frontiers in Computational Neuroscience, 2015, 9(429):99.
[16] GOKMEN T, ONEN M, WILFRIED H. Training deepconvolutional neural networks with resistive cross- pointdevices[J]. Frontiers in Neuroscience, 2017, 11: 538.
[17] GOKMEN T, VLASOV Y. Acceleration of deep neuralnetwork training with resistive cross- point devices: design considerations[J]. Frontiers in Neuroscience, 2016,10(51): 333.
[18] ESSER S K, MEROLLA P A, ARTHUR J V, et al. Convolutional networks for fast energy- efficient neuromorphic computing[J]. Proceedings of the National Academy of Sciences, 2016, 113(41): 11441-11446.
[19] CHEN L, LI J, CHEN Y, et al. Accelerator-friendly neural- network training: learning variations and defects inRRAM crossbar[C]// 2017 Design, Automation & Testin Europe Conference & Exhibition (DATE). IEEE,2017: 19-24.
[20] CHANG C C, LIU J C, SHEN Y L, et al. Challengesand opportunities toward online training acceleration using RRAM- based hardware neural network[C]// 2017IEEE International Electron Devices Meeting (IEDM).IEEE, 2017: 11.6.1-11.6.4.
[21] TRUONG S N, MIN K S. New memristor-based crossbar array architecture with 50-% area reduction and48-% power saving for matrix- vector multiplication ofanalog neuromorphic computing[J]. Journal of Semiconductor Technology and Science, 2014, 14(3): 356-363.
[22] CHOI S, SHIN J H, LEE J, et al. Experimental demonstration of feature extraction and dimensionality reduction using memristor networks[J]. Nano Letters, 2017, 17(5): 3113-3118.
[23] HU M, GRAVES C E, LI C, et al. Memristor‐based analog computation and neural network classification with adot product engine[J]. Advanced Materials, 2018, 30(9):1705914.
[24] NURSE E, MASHFORD B S, YEPES A J, et al. Decoding EEG and LFP signals using deep learning: headingTrueNorth[C]// Proceedings of the ACM InternationalConference on Computing Frontiers. ACM, 2016: 259-266.
[25] LUO T, LIU S, LI L, et al. Dadiannao: A neural networksupercomputer[J]. IEEE Transactions on Computers,2016, 66(1): 73-88.
[26] PEI J, DENG L, SONG S, et al. Towards artificial general intelligence with hybrid Tianjic chip architecture[J].Nature, 2019, 572: 106-111.
[27] CAI F, CORRELL J, LEE S H, et al. A fully integratedreprogrammable memristor – CMOS system for efficientmultiply – accumulate operations[J]. Nature Electronics,2019, 2(7): 290-299.
[28] CHEN W H, DOU C, LI K X, et al. CMOS-integratedmemristive non- volatile computing- in- memory for AIedge processors[J]. Nature Electronics, 2019, 2: 1-9.
[29] MCCULLOCH W S, PITTS W. A logical calculus of theideas immanent in nervous activity[J]. The Bulletin ofMathematical Biophysics, 1943, 5(4): 115-133.
[30] HEBB D O. The organization of behavior: a neuropsychological theory[J]. American Journal of Physical Medicine & Rehabilitation, 2013, 30(1): 74-76.
[31] ROSENBLATT F. The perceptron: a probabilistic modelfor information storage and organization in the brain[J].Psychological Review, 1958, 65(6): 386-408.
[32] WANG Z R, JOSHI S, SAVEL’EV S, et al. Fully memristive neural networks for pattern classification with unsupervised learning[J]. Nature Electronics, 2018, 1(2):137-145.
[33] CAI F, CORRELL J, LEE S H, et al. A fully integratedreprogrammable memristor – CMOS system for efficientmultiply – accumulate operations[J]. Nature Electronics,2019, 2(7): 290-299.
[34] IELMINI D, AMBROGIO S, MILO V, et al. Neuromorphic computing with hybrid memristive/CMOS synapsesfor real-time learning[C]// 2016 IEEE International Symposium on Circuits and Systems (ISCAS). IEEE, 2016:1386-1389.
[35] CHEN P Y, YU S. Partition SRAM and RRAM basedsynaptic arrays for neuro- inspired computing[C]// 2016IEEE International Symposium on Circuits and Systems(ISCAS). IEEE, 2016: 2310-2313.
[36] KIM S G, HAN J S, KIM H, et al. Recent advances inmemristive materials for artificial synapses[J]. AdvancedMaterials Technologies, 2018, 3(12): 1800457.
[37] TSAI H, AMBROGIO S, NARAYANAN P, et al. Recentprogress in analog memory- based accelerators for deeplearning[J]. Journal of Physics D: Applied Physics,2018, 51(28): 283001.
[38] SUNG C, HWANG H, YOO I K. Perspective: a reviewon memristive hardware for neuromorphic computation[J]. Journal of Applied Physics, 2018, 124(15): 151903.
[39] CRISTIANO G, GIORDANO M, AMBROGIO S, et al.Perspective on training fully connected networks with resistive memories: device requirements for multiple conductances of varying significance[J]. Journal of AppliedPhysics, 2018, 124(15): 151901.
[40] LI C, BELKIN D, LI Y, et al. Efficient and self-adaptivein-situ learning in multilayer memristor neural networks[J]. Nature Communications, 2018, 9(1): 2385.
[41] YAO P, WU H, GAO B, et al. Face classification usingelectronic synapses[J]. Nature Communications, 2017, 8:15199.
[42] BAYAT F M, PREZIOSO M, CHAKRABARTI B, et al.Implementation of multilayer perceptron network withhighly uniform passive memristive crossbar circuits[J].Nature Communications, 2018, 9(1): 2331.
[43] KWAK M, PARK J, WOO J, et al. Implementation ofconvolutional kernel function using 3- D TiOx resistiveswitching devices for image processing[J]. IEEE Transactions on Electron Devices, 2018, 65(10): 4716-4718.
[44] YAKOPCIC C, ALOM M Z, TAHA T M. Memristorcrossbar deep network implementation based on a convolutional neural network[C]// 2016 International JointConference on Neural Networks (IJCNN). IEEE, 2016:963-970.
[45] GARBIN D, VIANELLO E, BICHLER O, et al. HfO2-based OxRAM devices as synapses for convolutionalneural networks[J]. IEEE Transactions on Electron Devices, 2015, 62(8): 2494-2501.
[46] GOKMEN T, ONEN M, HAENSCH W, et al. Trainingdeep convolutional neural networks with resistive crosspoint devices[J]. Frontiers in Neuroscience, 2017, 11:538.
[47] ZHOU Z, HUANG P, XIANG Y C, et al. A new hardware implementation approach of BNNs based on nonlinear 2T2R synaptic cell[C]// 2018 IEEE InternationalElectron Devices Meeting (IEDM). IEEE, 2018: 20.7.1-20.7.4.
[48] SUN X, YIN S, PENG X, et al. XNOR-RRAM: a scalable and parallel resistive synaptic architecture for binary neural networks[C]// 2018 Design, Automation &Test in Europe Conference & Exhibition (DATE). IEEE,2018: 1423-1428.
[49] LI C, WANG Z, RAO M, et al. Long short-term memory networks in memristor crossbar arrays[J]. Nature Machine Intelligence, 2019, 1(1): 49-57.
[50] TSAI H, AMBROGIO S, MACKIN C, et al. Inferenceof long-short term memory networks at software-equivalent accuracy using 2.5M analog phase change memorydevices[C]// 2019 Symposium on VLSI Technology.IEEE, 2019: T82-T83.
陈佳,潘文谦,秦一凡,等. 基于忆阻器的神经网络应用研究[J]. 微纳电子与智能制造, 2019, 1(4): 24-38.
CHEN Jia, PANWenqian, QIN Yifan, et al. Research of neural network based on memristor[J]. Micro/nano Electronics and Intelligent Manufacturing, 2019, 1(4): 24-38.
《微纳电子与智能制造》刊号:CN10-1594/TN
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2410期内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
模拟芯片|蓝牙
|
5G|GaN|台积电|英特尔|封装|晶圆
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!
责任编辑:Sophie