来源:内容
编译自semiengineering
,谢谢。
基于机器学习 (ML) 的系统开发方法采用了与计算机科学历史上使用的完全不同的编程风格。这种方法使用示例数据来训练模型,使机器能够学习如何执行任务。ML 训练是高度迭代的,每一条新的训练数据都会产生数万亿次操作。训练过程的迭代性质与实现高精度所需的非常大的训练数据集相结合,推动了对极高性能浮点处理的需求。大多数新模型根据使用的 GPU 加速卡数量和所需的处理周数来描述他们的训练要求。典型视觉模型的训练设备价格从数十万美元到数百万美元不等,并且还需要以千瓦为单位的功率才能运行。这些通常是机架规模的系统。ML 培训最好作为数据中心基础设施实施,可以在许多不同的客户之间进行摊销,以证明高资本和运营费用是合理的。
另一方面,推理是使用经过训练的模型为新数据与模型所训练的所有数据产生可能匹配的过程。在大多数应用程序中,推理寻找可以在几毫秒内得出的快速答案。推理的示例包括语音识别、实时语言翻译、机器视觉和广告插入优化决策。与训练相比,推理只需要一小部分处理能力。然而,这仍然远远超出了传统的基于 CPU 的系统所提供的处理能力。因此,即使进行推理,也需要加速(在 SoC 上作为 IP 或作为系统内加速器)以实现合理的执行速度。
一些真实的例子将有助于说明我们在这里谈论的计算规模。在上表中,我们看到编译 Linux 内核所需的计算大约为 5.4 TeraOps。在使用 Intel i5-12600K CPU 且配置良好的新 PC 上,此计算大约需要一分钟。蛮快!然而,在视觉系统中花费一分钟甚至几秒钟来处理图像并不是很有用。工业视觉系统正在寻找亚秒级处理速度。在本例中,我们使用 40 毫秒作为推理的目标速度,相当于每秒 25 帧。这导致 TeraOps/second 要求大大高于 i5 可以提供的要求。事实上,在这个指标上,用于此工作负载的 X1 加速器的性能将比 i5 CPU 高出约 500 倍。应该重申的是,i5 CPU 和 X1 加速器正在解决截然不同的问题。X1 加速器无法用于编译 Linux,虽然 i5 的通用处理能力使其能够处理推理工作负载,但在性能和效率方面将显着落后于 X1。
模型推理在边缘执行得更好,在那里它更接近那些寻求从推理决策结果中受益的人。一个完美的例子是自动驾驶汽车,其中推理处理不能依赖于某些数据中心的链接,这些链接容易出现高延迟和间歇性连接。
上表还提供了模型训练的示例。这是基于报告的 10 天训练时间,使用 COCO 数据集在 GTX 1080 Ti GPU 的 4 个实例上构建 Yolov3 模型。这个工作负载,如果我们假设 GPU 提供 11.3 TeraFlops 并且其中四个运行 10 天,那么需要大约 40 ExaOps 才能完成。这比单个推理所需的计算量多 4000 万倍。
鉴于极高的处理要求,更不用说训练的数据存储和通信要求,数据中心基础设施显然是进行训练处理的最佳场所。
有了训练和推理之间明确的二分法,我们必须考虑对两种应用程序使用相同的技术是否有意义。
在最近的白皮书 [4] 中,Omdia 的 Alexander Harrowell 指出:“AI 模型训练是高度计算密集型的,还需要完全通用的可编程性。因此,它是高性能图形处理单元 (GPU) 的领域,与高带宽内存和强大的 CPU 相结合。这表明,部署用于训练推理工作负载的相同硬件可能意味着为推理机过度配置加速器和 CPU 硬件。”
在同一份报告中,Harrowell 先生估计,到 2026 年,边缘和数据中心解决方案技术方法将出现非常明显的差异,基于 GPU 的解决方案将继续在数据中心领先,而定制 AI ASIC 则在边缘占据主导地位。
随着用于解决方案开发的 ML 方法的激增,开发人员必须认识到,过去十年中不断发展以创建 ML 技术的工具和技术,主要是基于 GPU 的解决方案,将不是部署的最佳解决方案,这一点非常重要。批量 ML 推理技术。过去几十年推动半导体技术极端专业化的压力,将推动边缘应用的高效高性能推理处理。
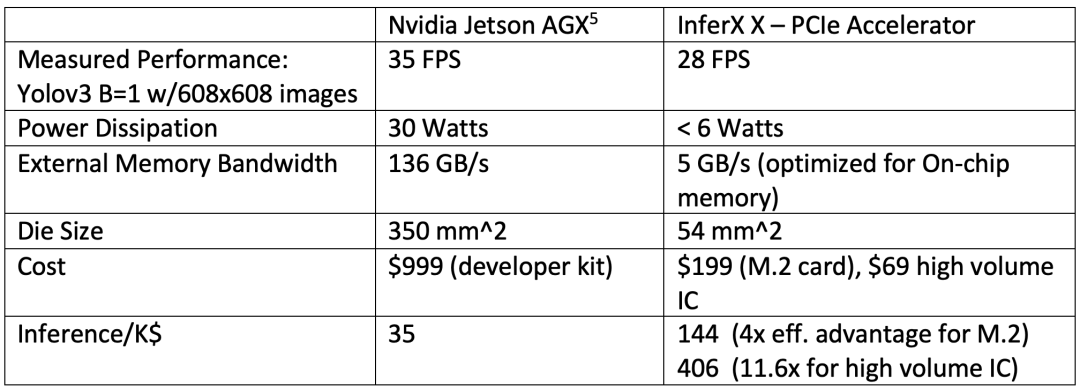
边缘推理加速器与专为训练和模型开发而设计的 GPU 解决方案截然不同的原因有很多。下表将经常用于边缘推理应用的 NVIDIA Jetson AGX 与 Flex Logix X1 推理加速器进行了比较。很明显,与基于 GPU 的 AGX 解决方案相比,X1 能够提供更低的功耗、更低的成本和更高的效率,同时仍然为推理应用程序提供令人信服的性能水平。
ML 训练和推理之间的最后一个重要区别点与软件环境有关。在模型开发培训和测试中,当今使用了许多方法。其中包括流行的库(例如用于 NVIDIA GPU 的 CUDA、机器学习框架(例如 TensorFlow 和 PyTorch)、优化的跨平台模型库(例如 Keras)等等。这些工具集对于 ML 模型的开发和训练至关重要,但在推理应用程序方面,需要的软件工具集大为不同且规模较小。推理工具集专注于在目标平台上运行模型。推理工具支持将经过训练的模型移植到平台。这可能包括一些运算符转换、量化和主机集成服务,
推理工具受益于从模型的标准表示开始。开放神经网络交换 (ONNX) 是表示 ML 模型的标准格式。顾名思义,它是一个开放标准,并作为 Linux 基金会项目进行管理。ONNX 等技术允许将训练和推理系统解耦,并为开发人员提供选择最佳训练和推理平台的自由。
随着机器学习方法在边缘和嵌入式系统中得到更广泛的采用,边缘 AI ASIC 技术的使用将会越来越多,这些技术比基于 GPU 的解决方案提供更高效和更具成本效益的性能。ONNX 等技术的出现使得采用特定于推理的模型解决方案变得更加容易,因为它们提供了一条将 ML 训练和测试任务与 ML 推理任务完全分开的途径。
希望部署 AI 技术的公司应该评估推理的最佳解决方案,而不是假设所有 AI 解决方案都最好在 GPU 设备上实施。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2915内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|集成电路|设备
|汽车芯片|存储|台积电|AI|封装
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!