国产化IP创新之路 需求篇:数据量激增驱动计算架构革新
2022-02-28
11:54:24
来源: 互联网
点击

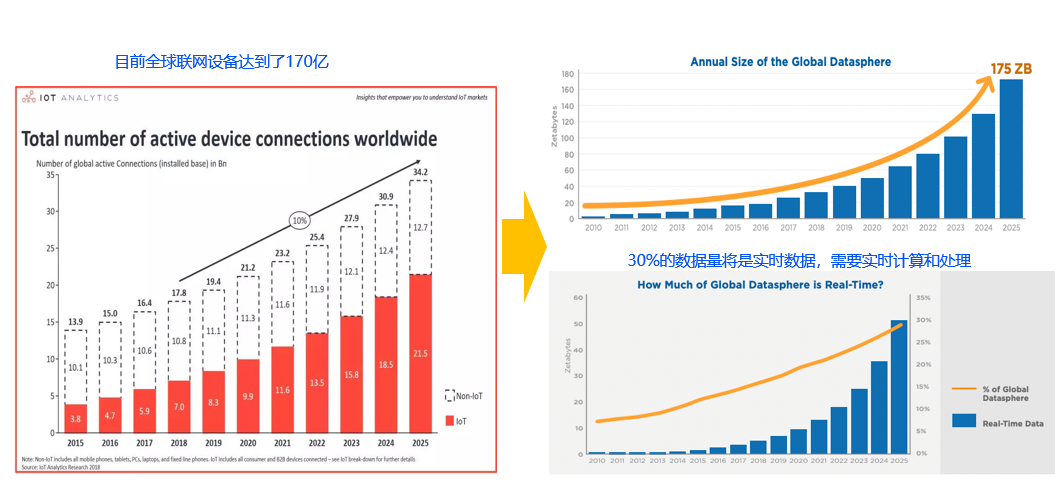
近年来随着5G,人工智能等新兴产业的发展,全球联网设备数高速增长。据IDC和Statista数据显示,2021年全球联网设备已达到170亿,大量设备的联网带来了数据量的爆发,预计到2025年全球数据量将高达175ZB(1ZB约等于1万亿GB),其中30%的数据需要实时的计算和处理,所以我们正面临数据增长给处理器计算能力带来的巨大挑战。奎芯科技将会用两篇文章来详细介绍处理器计算性能提升遇到的挑战和后摩尔时代解决性能提升瓶颈的方法及相关IP的突破和创新,特别是以奎芯为代表的国产化的IP创新。
挑战一:登纳德缩放定律失效,摩尔定律放缓
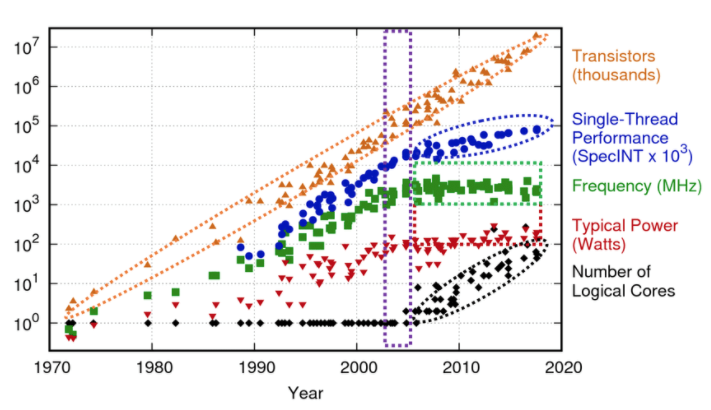
自2015年起,通用CPU的发展遇到了一系列技术瓶颈,其单核性能提升比例由上世纪80年代的每年22%降低至现在的3%,处理器性能提升速度逐年放缓,摩尔定律放缓已经成为事实。另外,Denard Scaling定律也在2005年左右就已失效。单核性能的增加很大程度上并不是由过去所简单依赖的频率提升带来的,而是通过架构和编译器的优化以实现指令自动并行化,数据向量化等方式实现。(同时Amdahl’s Law提示多核架构的速度提升取决于程序中有多少部分无法并行,多核架构目前的性能提升也会变得越来越慢)。即便如此,目前通过指令并行方式来榨取处理器性能的增加也达到了瓶颈。
挑战二:内存和IO带宽发展跟不上处理器核数增长
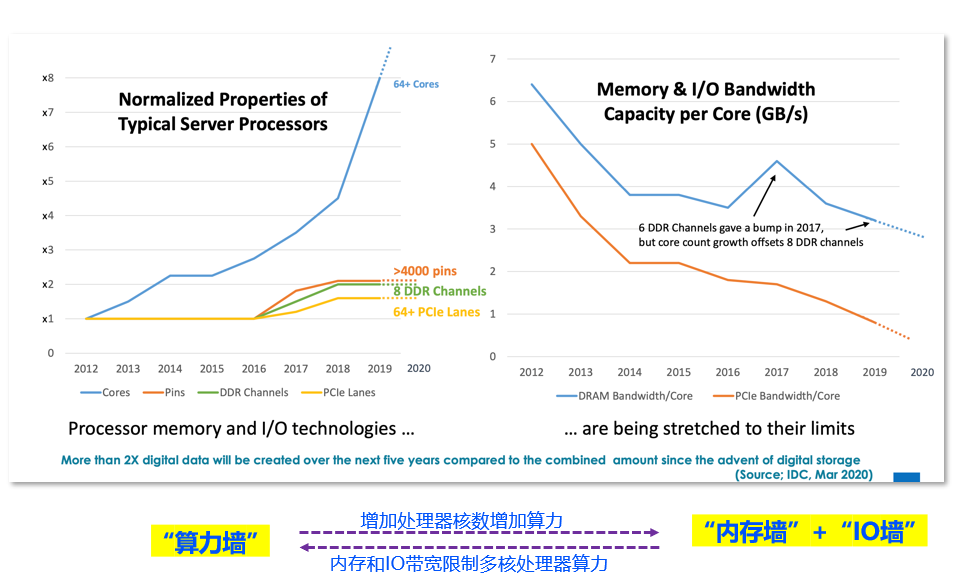
由于单核性能限制(算力墙+功耗墙),目前通用的做法是增加处理器核数来增加数据处理能力,但问题是我们在增加处理器核心数的同时,又面临着内存容量和带宽的不足,以及IO的带宽瓶颈(内存墙+IO墙)。从上图可以看到,左边显示从2012-2019年服务器CPU核数(从8核到64核)增长了8倍,而Pin针脚数量(从LGA-2011到4094/4189)和内存通道数(从4到8)仅增长了2倍,PCIe lane 数增加(从40到64,如果是AMD则按照双路中每CPU支持来算)甚至还不到2倍,可以看出内存和I/O带宽跟不上计算密度的增长。同时,通过计算得出,平均每核心DRAM内存带宽,以及每核心PCIe带宽,都是呈不断下降趋势。
所以,未来算力的持续增长需要通过多元化的方式来实现,在底层材料技术没有实质性突破、纵向扩展到达极限的情况下,需要上层的架构革新来采用更大规模的并行或异构计算等方式去横向扩展来满足需求。未来的计算领域将逐渐从以计算为中心转向为以数据为中心,因此如何高效的传输数据将成为关键。
现在,我们有机会通过一系列的技术创新,打破能效墙、散热墙、优化墙、内存墙和高速IO墙,进一步释放计算潜能,计算产业已进入架构创新的黄金时代!
下一篇我们将会给大家带来后摩尔时代解决性能提升瓶颈的方法及相关IP的突破与创新,特别是以奎芯为代表的国产化IP创新,敬请大家期待。
关于奎芯科技(MSQUARE):
奎芯科技(M SQUARE)于2021年在上海注册成立,是一家专业的集成电路IP供应商。作为芯片产业链上游关键技术环节的企业,公司推出的高速接口IP,涵盖USB、PCIe、SATA、SerDes、MIPI、DDR、HDMI、DP、HBM等产品,聚焦高性能计算、人工智能、消费类电子、汽车电子、物联网等领域,致力于通过先进半导体IP研发与定制服务,打造市场急需的IP组合,积极响应中国快速发展的芯片和应用需求﹐全面赋能芯片设计产业。
责任编辑:sophie




-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 英特尔重磅发布OPS 2.0,智能教育时代加速到来
- 2 研发收关:进迭时空高性能处理器核X100产品发布会震撼来袭
- 3 MediaTek天玑汽车平台推动汽车产业加速迈入AI时代,3nm旗舰座舱平台亮相
- 4 广东场效应半导体,二十多年坚持做一件事
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号